基于用户和项目协同过滤原理及实例
1. 基于用户的协同过滤
基于用户(User-Based)的协同过滤算法首先要根据用户历史行为信息,寻找与新用户相似的其他用户;同时,根据这些相似用户对其他项的评价信息预测当前新用户可能喜欢的项。给定用户评分数据矩阵R,基于用户的协同过滤算法需要定义相似度函数s:U×U→R,以计算用户之间的相似度,然后根据评分数据和相似矩阵计算推荐结果。
在协同过滤中,一个重要的环节就是如何选择合适的相似度计算方法,常用的两种相似度计算方法包括皮尔逊相关系数和余弦相似度等。皮尔逊相关系数的计算公式如下所示:
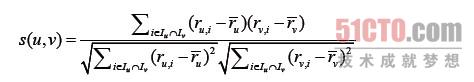
其中,i表示项,例如商品;Iu表示用户u评价的项集;Iv表示用户v评价的项集;ru,i表示用户u对项i的评分;rv,i表示用户v对项i的评分;表示用户u的平均评分;表示用户v的平均评分。
另外,余弦相似度的计算公式如下所示:
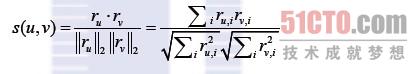
另一个重要的环节就是计算用户u对未评分商品的预测分值。首先根据上一步中的相似度计算,寻找用户u的邻居集N∈U, 其中N表示邻居集,U表示用户集。然后,结合用户评分数据集,预测用户u对项i的评分,计算公式如下所示:
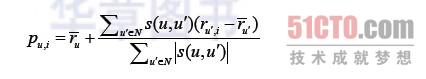
其中,s(u, u')表示用户u和用户u'的相似度。
假设有如下电子商务评分数据集,预测用户C对商品4的评分,见表3-6。
表3-6 电商网站用户评分数据集
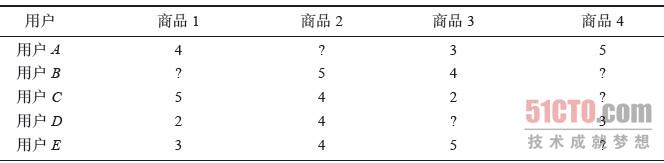
表中? 表示评分未知。根据基于用户的协同过滤算法步骤,计算用户C对商品4的评分,其步骤如下所示。
(1)寻找用户C的邻居
从数据集中可以发现,只有用户A和用户D对商品4评过分,因此候选邻居只有2个,分别为用户A和用户D。用户A的平均评分为4,用户C的平均评分为3.667,用户D的平均评分为3。根据皮尔逊相关系数公式来看,用户C和用户A的相似度为:
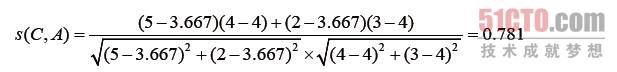
同理,s(C, D) =-0.515。
(2)预测用户C对商品4的评分
根据上述评分预测公式,计算用户C对商品4的评分,如下所示:

依此类推,可以计算出其他未知的评分。
2. 基于项目的协同过滤
基于项目(Item-Based)的协同过滤算法是常见的另一种算法。与User-Based协同过滤算法不一样的是,Item-Based 协同过滤算法计算Item之间的相似度,从而预测用户评分。也就是说该算法可以预先计算Item之间的相似度,这样就可提高性能。Item-Based协同过滤算法是通过用户评分数据和计算的Item相似度矩阵,从而对目标Item进行预测的。
和User-Based协同过滤算法类似,需要先计算Item之间的相似度。并且,计算相似度的方法也可以采用皮尔逊关系系数或者余弦相似度,这里给出一种电子商务系统常用的相似度计算方法,即基于条件概率计算Item之间的相似度,计算公式如下所示:
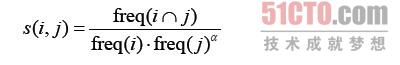
其中,s(i, j)表示项i和j之间的相似度;freq(ij)表示i和j共同出现的频率;freq(i)表示i出现的频率;freq(j)表示j出现的频率;表示阻力因子,主要用于平衡控制流行和热门的Item,譬如电子商务中的热销商品等。
接下来,根据上述计算的Item之间的相似度矩阵,结合用户的评分,预测未知评分。预测公式如下所示:

其中,pu, i表示用户u对项i的预测评分;S表示和项i相似的项集;s(i, j)表示项i和j之间的相似度;ru, j表示用户u对项j的评分。