本文主要针对Protobuf进行介绍,主要针对版本proto2,给出demo来讲解proto语法,并对其中部分编解码原理进行讲解,最后进行总结和思考
介绍
官网 https://developers.google.com/protocol-buffers/docs/overview
Protocol buffers are a flexible, efficient, automated mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages. You can even update your data structure without breaking deployed programs that are compiled against the "old" format.
特点:
灵活高效,自动的序列化,反序列化机制,定义IDL,生成代码,支持跨语言,有很好的兼容性
适用场景
**Protocol buffers 很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式**。
历史背景
proto2 和 proto3 的名字看起来有点扑朔迷离,那是因为当我们最初开源的 protocol buffers 时,它实际上是 Google 的第二个版本了,所以被称为 proto2,这也是我们的开源版本号从 v2 开始的原因。初始版名为 proto1,从 2001 年初开始在谷歌开发的。
现实应用: grpc
Demo
proto文件
proto文件,类似idl定义,下面文件是a.proto
`syntax="proto2";`
`package main;`
`message Person {`
`required string name = 1;`
`required int32 age = 2;`
` }`
` message Person1 {`
`required string name = 1;`
`optional int32 age = 2;`
` }`
main.go
package main
import (
"fmt"
"io/ioutil"
"github.com/golang/protobuf/proto"
)
//go run *.go
//protoc --go_out . a.proto
/**
message Person {
required string name = 1;
required int32 age = 2;
}
*/
func main() {
//testPerson()
testPerson1()
}
func testPerson() {
// s 1
//[10 1 115 16 1]
// s 2
//[10 1 115 16 2]
// s 3
// [10 1 115 16 3]
// a 3
// [10 1 97 16 3]
// z 3
// [10 1 122 16 3]
// z 300
// [10 1 122 16 172 2]
// z 255
// [10 1 122 16 255 1]
// z 256
// [10 1 122 16 128 2]
// z 257
// [10 1 122 16 129 2]
// z 258
// [10 1 122 16 130 2]
// z 259
// [10 1 122 16 131 2]
// z 127
// [10 1 122 16 127]
// z 128
// [10 1 122 16 128 1]
// z 129
// [10 1 122 16 129 1]
// z 131
// [10 1 122 16 131 1]
/**
z 512
10 1 122 16 128 4
z 511
[10 1 122 16 255 3]
z 5110
[10 1 122 16 246 39]
zz 5100
[10 2 122 122 16 246 39]
*/
// tag << 3| wiretype
/**
10 = 1<<3 | string type = 8|2 = 10
1 = 字符串长度
字符串的ascii码
16 = 2<<3 | varint type = 16|0 = 16
127
0111 1111
128 = 2^8
1000000
低7位+前缀1 + 低0位 + 剩余位
= (1)000000 + (0)0000001
511
=1 1111 1111
1+低七位,补0+高2位
1 111111 000000 11
255 3
5110
0001 0011 1111 0110
100111 1110110
11110110 0100111
246 39
*/
name := "z"
age := int32(150)
person := &Person{
Name: &name,
Age: &age,
}
fmt.Println("person : ", person)
fname := "address.dat"
// 将person进行序列化
out, err := proto.Marshal(person)
fmt.Println(out)
if err != nil {
fmt.Println("Failed to encode address person:", err)
}
// 将序列化的内容写入文件
if err := ioutil.WriteFile(fname, out, 0644); err != nil {
fmt.Println("Failed to write address person:", err)
}
// 读取写入的二进制数据
in, err := ioutil.ReadFile(fname)
if err != nil {
fmt.Println("Error reading file:", err)
}
// 定义一个空的结构体
person2 := &Person{}
// 将从文件中读取的二进制进行反序列化
if err := proto.Unmarshal(in, person2); err != nil {
fmt.Println("Failed to parse address person:", err)
}
fmt.Println("person2: ", person2)
}
func testPerson1() {
name := "a"
age := int32(1)
person := &Person{
Name: &name,
Age: &age,
}
fmt.Println("person : ", person)
fname := "address.dat"
// 将person进行序列化
out, err := proto.Marshal(person)
fmt.Println(out)
if err != nil {
fmt.Println("Failed to encode address person:", err)
}
// 将序列化的内容写入文件
if err := ioutil.WriteFile(fname, out, 0644); err != nil {
fmt.Println("Failed to write address person:", err)
}
// 读取写入的二进制数据
in, err := ioutil.ReadFile(fname)
if err != nil {
fmt.Println("Error reading file:", err)
}
// 定义一个空的结构体
person2 := &Person1{}
// 将从文件中读取的二进制进行反序列化
if err := proto.Unmarshal(in, person2); err != nil {
fmt.Println("Failed to parse address person:", err)
}
fmt.Println("person2: ", person2)
}
proto语法
语法规则详见 https://developers.google.com/protocol-buffers/docs/proto
这里作出部分说明
在 proto 中,所有结构化的数据都被称为 message。
如果开头第一行不声明 syntax = "proto3";,则默认使用 proto2 进行解析。
分配字段编号
每个消息定义中的每个字段都有**唯一的编号**。这些字段编号用于标识消息二进制格式中的字段,并且在使用消息类型后不应更改。请注意,范围 1 到 15 中的字段编号需要一个字节进行编码,包括字段编号和字段类型。范围 16 至 2047 中的字段编号需要两个字节。所以你应该保留数字 1 到 15 作为非常频繁出现的消息元素。请记住为将来可能添加的频繁出现的元素留出一些空间。
字段规则
repeated 0-n
optional 0-1
required 1
保留字段
如果您通过完全删除某个字段或将其注释掉来更新消息类型,那么未来的用户可以在对该类型进行自己的更新时重新使用该字段号。如果稍后加载到了的旧版本 .proto 文件,则会导致服务器出现严重问题,例如数据混乱,隐私错误等等。确保这种情况不会发生的一种方法是指定删除字段的字段编号(或名称,这也可能会导致 JSON 序列化问题)为 reserved。如果将来的任何用户试图使用这些字段标识符,Protocol Buffers 编译器将会报错。
message Foo {
reserved 2, 15, 9 to 11;
reserved "foo", "bar";
}
各个语言标量类型对应关系
https://developers.google.com/protocol-buffers/docs/proto3#scalar
枚举,默认值,嵌套定义,MAP,定义service,
不展开
更新一个message
如果后面发现之前定义 message 需要增加字段了,这个时候就体现出 Protocol Buffer 的优势了,不需要改动之前的代码。不过需要满足以下 10 条规则
不要改动原有字段的数据结构。
如果您添加新字段,新字段应该用optional或者repeated,则任何由代码使用“旧”消息格式序列化的消息仍然可以通过新生成的代码进行分析。您应该记住这些元素的默认值,以便新代码可以正确地与旧代码生成的消息进行交互。同样,由新代码创建的消息可以由旧代码解析:旧的二进制文件在解析时会简单地忽略新字段。
只要字段号在更新的消息类型中不再使用,字段可以被删除。您可能需要重命名该字段,可能会添加前缀“OBSOLETE_”,或者标记成保留字段号 reserved,以便将来的 .proto 用户不会意外重复使用该号码。
int32,uint32,int64,uint64 和 bool 全都兼容。这意味着您可以将字段从这些类型之一更改为另一个字段而不破坏向前或向后兼容性。如果一个数字从不适合相应类型的线路中解析出来,则会得到与在 C++ 中将该数字转换为该类型相同的效果(例如,如果将 64 位数字读为 int32,它将被截断为 32 位)。
sint32 和 sint64 相互兼容,但与其他整数类型不兼容。
只要字节是有效的UTF-8,string 和 bytes 是兼容的。
嵌入式 message 与 bytes 兼容,如果 bytes 包含 message 的 encoded version。
fixed32与sfixed32兼容,而fixed64与sfixed64兼容。
enum 就数组而言,是可以与 int32,uint32,int64 和 uint64 兼容(请注意,如果它们不适合,值将被截断)。但是请注意,当消息反序列化时,客户端代码可能会以不同的方式对待它们:例如,未识别的 proto3 枚举类型将保留在消息中,但消息反序列化时如何表示是与语言相关的。(这点和语言相关,上面提到过了)Int 域始终只保留它们的值。
将单个值更改为新的成员是安全和二进制兼容的。如果您确定一次没有代码设置多个字段,则将多个字段移至新的字段可能是安全的。将任何字段移到现有字段中都是不安全的。(注意字段和值的区别,字段是 field,值是 value)
未知字段
未知数字段是 protocol buffers 序列化的数据,表示解析器无法识别的字段。例如,当一个旧的二进制文件解析由新的二进制文件发送的新数据的数据时,这些新的字段将成为旧的二进制文件中的未知字段。
Proto3 实现可以成功解析未知字段的消息,但是,实现可能会或可能不会支持保留这些未知字段。你不应该依赖保存或删除未知域。对于大多数 Google protocol buffers 实现,未知字段在 proto3 中无法通过相应的 proto 运行时访问,并且在反序列化时被丢弃和遗忘。这是与 proto2 的不同行为,其中未知字段总是与消息一起保存并序列化。
编码原理
https://developers.google.com/protocol-buffers/docs/encoding
Base 128 Varints 编码
Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
Varint 中的每个字节(最后一个字节除外)都设置了最高有效位(msb),这一位表示还会有更多字节出现。每个字节的低 7 位用于以 7 位组的形式存储数字的二进制补码表示
如果用不到 1 个字节,那么最高有效位设为 0 ,如下面这个例子,
1 用一个字节就可以表示,所以 msb 为 0.
0000 0001
如果需要多个字节表示,msb 就应该设置为 1 。
例如 300,如果用 Varint 表示的话:
二进制
0000 0001 0010 1100 =>
10 0101100 => 逆序,加msb
(1)0101100 (000000)10

即172 2
例如5110
*二进制* *0001**0011**1111**0110* *=>*
0100111 1110110 =》 逆序,加msb
11110110 00100111 =>
*结果* *246**39*
本来一个int32,要占4个字节长度的数字,这里只占了2个字节(246占8位 39占8位)
那 Varint 是怎么编码的呢?
下面代码是 Varint int 32 的编码计算方法。
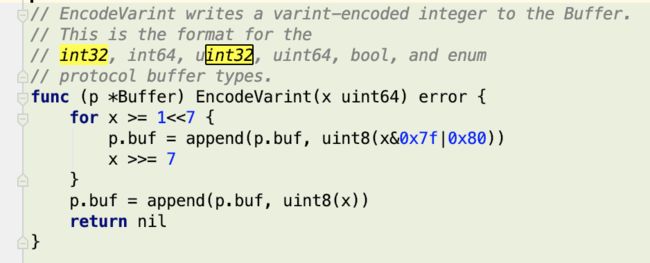
解码是可逆的过程
1.如果是多个字节,先去掉每个字节的 msb(通过逻辑或运算),每个字节只留下 7 位。
2.每7位给拼接起来
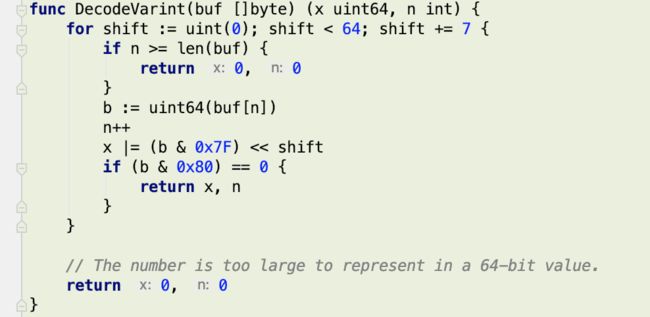
varint一定更压缩吗
读到这里可能有读者会问了,Varint 不是为了紧凑 int 的么?那 300 本来可以用 2 个字节表示,现在还是 2 个字节了,哪里紧凑了,花费的空间没有变啊?!
Varint 确实是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。比如对于 int32 类型的数字,一般需要 4 个 byte 来表示。但是采用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息。
300 如果用 int32 表示,需要 4 个字节,现在用 Varint 表示,只需要 2 个字节了。缩小了一半!
Message Structure 编码
protocol buffer 中 message 是一系列键值对。message 的二进制版本只是使用字段号(field's number 和 wire_type)作为 key。每个字段的名称和声明类型只能在解码端通过引用消息类型的定义(即 .proto 文件)来确定。这一点也是人们常常说的 protocol buffer 比 JSON,XML 安全一点的原因,如果没有数据结构描述 .proto 文件,拿到数据以后是无法解释成正常的数据的。
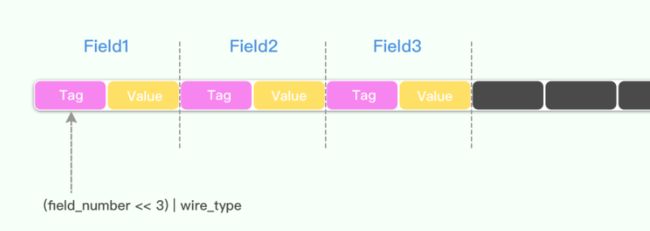
当消息编码时,键和值被连接成一个字节流。当消息被解码时,解析器需要能够跳过它无法识别的字段。这样,可以将新字段添加到消息中,而不会破坏不知道它们的旧程序。这就是所谓的 “向后”兼容性。
为此,线性的格式消息中每对的“key”实际上是两个值,其中一个是来自.proto文件的字段编号,加上提供正好足够的信息来查找下一个值的长度。在大多数语言实现中,这个 key 被称为 tag。
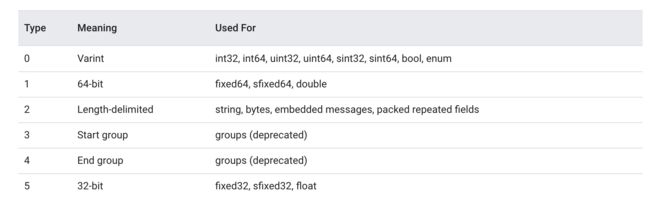
key 的计算方法
即(field_number << 3) | wire_type,换句话说,key 的最后 3 位表示的就是 wire_type。
假设遇到
required int32 a = 1;
对应key计算值即为
000 1000
即 1(field_num)<<3| 0 (varint)
Signed Integers 编码
Protobuf中采用Zigzag,正负数交叉的方式来表示有符号数。
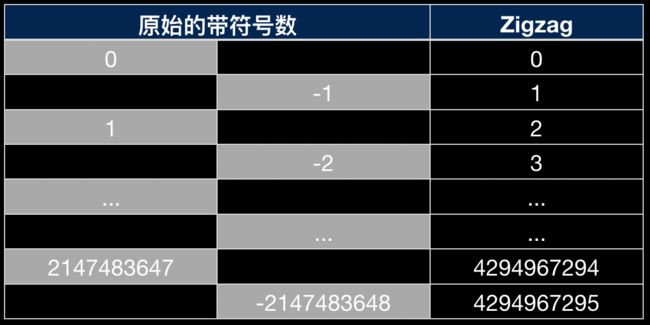
我们知道,计算机中采用补码的方式来表示有符号数,其最高位是符号位,正数的补码等于原码,负数的补码等于原码符号位不变,其余位取反再加1。所以如果我们使用int32表示1和-1,则-1需要表示成很大的正数,需要5个字节:
1(10进制) = 00000000_00000000_00000000_00000001(补码)
= 00000001(Varint int32)
-1(10进制) = 11111111_11111111_11111111_11111111(补码)
= 11111111_11111111_11111111_11111111_00001111(假如用Varint表示)
我们注意到绝对值很小的正负数其前面都是0或者1,如果我们能将重复的位压缩,则可以很大的节省空间。对于正数比较好处理,把前面无意义的0去掉就行。对于负数,则可以先把符号位移到最低位,再对数据位求反,就可以把前面的0都压缩了。-1和1的变换过程如下:

Non-varint Numbers
Non-varint 数字比较简单,double 、fixed64 的 wire_type 为 1,在解析时告诉解析器,该类型的数据需要一个 64 位大小的数据块即可。同理,float 和 fixed32 的 wire_type 为5,给其 32 位数据块即可。两种情况下,都是高位在后,低位在前。
说 Protocol Buffer 压缩数据没有到极限,原因就在这里,因为并没有压缩 float、double 这些浮点类型。
字符串
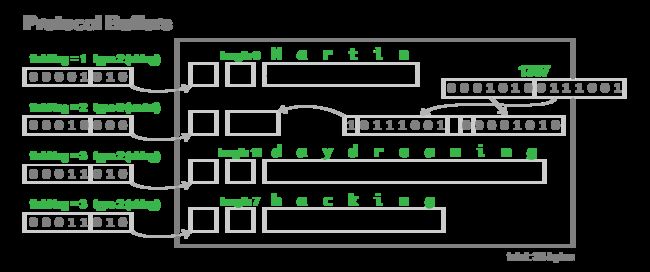
字符串对应wire_type=2,是一种指定长度的编码方式:key + length + content,key 的编码方式是统一的,length 采用 varints 编码方式,content 就是由 length 指定长度的 Bytes。
message Test2 {
optional string b = 2;
}
设置该值为"testing",二进制格式查看:
12 07 74 65 73 74 69 6e 67
12(16进制) = 18(10进制) = 2(field_num)<<3 | 2(wire_type)
07(16进制) = 7(10进制), testing长度为7
74(16) = 120(10) = 't' (比如 'a'=97)
性能:
参考referhttps://www.infoq.cn/article/json-is-5-times-faster-than-protobuf里面最后的图
总结,重点:
总结
Protocol Buffer 利用 varint 原理压缩数据以后,二进制数据非常紧凑,option 也算是压缩体积的一个举措。所以 pb 体积更小,如果选用它作为网络数据传输,势必相同数据,消耗的网络流量更少。但是并没有压缩到极限,float、double 浮点型都没有压缩。
Protocol Buffer 比 JSON 和 XML 少了 {、}、: 这些符号,体积也减少一些。
Protocol Buffer 另外一个核心价值在于提供了一套工具,一个编译工具,自动化生成 get/set 代码。简化了多语言交互的复杂度,使得编码解码工作有了生产力。
Protocol Buffer 不是自我描述的,离开了数据描述 .proto 文件,就无法理解二进制数据流。这点即是优点,使数据具有一定的“加密性”,也是缺点,数据可读性极差。所以 Protocol Buffer 非常适合内部服务之间 RPC 调用和传递数据。
Protocol Buffer 具有向后兼容的特性,更新数据结构以后,老版本依旧可以兼容,这也是 Protocol Buffer 诞生之初被寄予解决的问题。因为编译器对不识别的新增字段会跳过不处理。
重点和思考
总结
Protocol Buffer 利用 varint 原理压缩数据以后,二进制数据非常紧凑,option 也算是压缩体积的一个举措。所以 pb 体积更小,如果选用它作为网络数据传输,势必相同数据,消耗的网络流量更少。但是并没有压缩到极限,float、double 浮点型都没有压缩。
Protocol Buffer 比 JSON 和 XML 少了 {、}、: 这些符号,体积也减少一些。
Protocol Buffer 另外一个核心价值在于提供了一套工具,一个编译工具,自动化生成 get/set 代码。简化了多语言交互的复杂度,使得编码解码工作有了生产力。
Protocol Buffer 不是自我描述的,离开了数据描述 .proto 文件,就无法理解二进制数据流。这点即是优点,使数据具有一定的“加密性”,也是缺点,数据可读性极差。所以 Protocol Buffer 非常适合内部服务之间 RPC 调用和传递数据。
Protocol Buffer 具有向后兼容的特性,更新数据结构以后,老版本依旧可以兼容,这也是 Protocol Buffer 诞生之初被寄予解决的问题。因为编译器对不识别的新增字段会跳过不处理。
重点和思考
编解码:
varint编解码算法,以及优劣压缩是否到极致
tag计算方式,字段名的意义作用时机
zigzag处理有符号数
Tag - Length - Value处理string等
如何评价一个编解码算法,协议:
编解码时间,针对不同类型的支持
压缩空间
前后兼容性:
向后兼容性的保证:不认识的字段跳过
改动,加字段,删字段,字段改名字
可读性,安全性,自解释性
跨语言
生态和工具支持:
compiler和runtime
compiler类似代码生成器,根据proto生成代码
对比公司现有工具
runtime即序列化和反序列化
对比公司现有工具
思考题:
1.proto里面的字段名有什么意义,对于生成pb文件有什么作用
没用,client,server同类型同field_num哪怕字段名不一样,也可以顺利解析
` message Person {`
`required string name = 1;`
`required int32 age = 2;`
` }`
` message Person1 {`
` required string name = 1;`
` optional int32 age1 = 2;`
` }`
可以用Person{"zxc",-2}去序列化生成二进制文件,再用Person1的proto反序列化,得到name="zxc",age1=-2
2.repeated,optional这些在proto中是如何生效的
序列化和反序列化的时候会检查,但是并不会体现在二进制文件中,也就是同样一个proto,把required改成proto,进行一样的赋值,生成的二进制不会有任何差别
` message Person {`
`required string name = 1;`
`required int32 age = 2;`
` }`
`Person("a","1")序列化后是[10 1 97 16 1]`
`message Person1 { `
`optional string name = 1;`
`optional int32 age = 2;`
`}`
同样的Person1("a","1")序列化后也是[10 1 97 16 1]
refer
https://www.jianshu.com/p/c1723e5f6a46 安装配置和demo
https://developers.google.com/protocol-buffers 官网
https://halfrost.com/protobuf_encode/ https://halfrost.com/protobuf_decode/ 比较好的材料,官网翻译版 mainly refered
https://zhuanlan.zhihu.com/p/73549334 简单描述
https://izualzhy.cn/protobuf-encode-varint-and-zigzag 搞图
测评
https://www.infoq.cn/article/json-is-5-times-faster-than-protobuf