很多人最近在我的文章下面问dlib人脸检测,关键点预测,face-embedding等问题,这里总结下Dlib的接口以及Dlib的常用功能,希望对其他读者有所裨益。这个总结完之后,后面会写几篇文章总结下腾讯的NCNN库在移动端的使用,主要分三个模块,分类,分割,图像风格化。欢迎关注。
API
人脸检测
Dlib 里面其实有两个人脸检测模块,但是很多人只知道基于HOG+SVM分类的那个。另一个是基于 Maximum-Margin Object Detector 的深度学习人脸检测方案。
先对它们做个对比吧。
- HOG 检测直接使用 dlib.get_frontal_face_detector()就可以获得
- MMOD 检测需要提供mmod模型, 可以在dlib model repo下载得到,然后使用dlib.cnn_face_detection_model_v1(model_path)加载模型,其他使用接口就是一样的了
- detector检测那块,后面的数字代表我们对图片进行上采样,然后检测,0不做处理,1上采样一倍。相对来说图片越大,检测到的可能性越大,但是速度会越慢。这里我做的处理是先直接检测,如果没有检测到对图片上采样两倍然后检测,这种工程处理和
try except思想比较类似faceRects = detector(img, 0) -
HOG 检测方法速度可以实时,但是MMOD速度非常慢,下图左边是MMOD, 右边是HOG, 基本是几十倍的差异
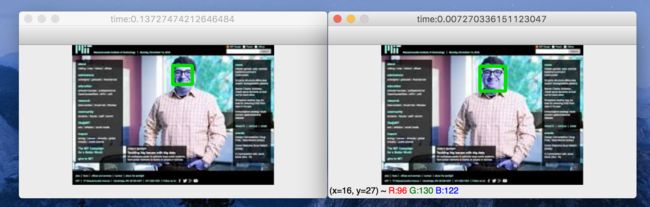 Screen Shot 2019-07-26 at 2.46.01 PM.png
Screen Shot 2019-07-26 at 2.46.01 PM.png - Dlib提供的这两个检测模型都只能检测脸部区域在70*70以上的图片,对于脸部区域太小的图片无法检测
- Dlib检测出的脸部区域对于下巴和额头区域会做过多的裁剪,这也是这两个模型的缺点。
import os
import time
import dlib
import cv2
data_path = "/Users/yuhua.cheng/Documents/dataset/UTKFace_ethnicity/0"
cnn_face_detector_model_path = '/Users/yuhua.cheng/PycharmProjects/model/mmod_human_face_detector.dat'
def detect_with_hog(detector, img, height=512, width=0):
w, h, c = img.shape
if not width:
width = int((height/h)*w)
img = cv2.resize(img, (height, width))
t0 = time.time()
faceRects = detector(img, 0)
t1 = time.time()
if len(faceRects) == 0:
faceRects = detector(img, 2)
for faceRect in faceRects:
cv2.rectangle(img, (faceRect.left(), faceRect.top()), (faceRect.right(), faceRect.bottom()), (0, 225, 0), 4, 4)
cv2.imshow("hog_detector", img)
cv2.setWindowTitle("hog_detector", "time:{}".format(t1 - t0))
def detect_with_cnn(detector, img, height=512, width=0):
w, h, c = img.shape
if not width:
width = int((height / h) * w)
img = cv2.resize(img, (height, width))
t0 = time.time()
faceRects = detector(img, 0)
t1 = time.time()
if len(faceRects) == 0:
faceRects = detector(img, 2)
for faceRect in faceRects:
cv2.rectangle(img, (faceRect.rect.left(), faceRect.rect.top()), (faceRect.rect.right(), faceRect.rect.bottom()), (0, 225, 0), 4 , 4)
cv2.imshow("cnn_detector", img)
cv2.setWindowTitle("cnn_detector", "time:{}".format(t1 - t0))
if __name__ == "__main__":
hog_detector = dlib.get_frontal_face_detector()
cnn_detector = dlib.cnn_face_detection_model_v1(cnn_face_detector_model_path)
imgs = [f for f in os.listdir(data_path) if not f.startswith('.')]
for _ in imgs:
bgr_img = cv2.imread(os.path.join(data_path, _), 1)
rgb_img = cv2.cvtColor(bgr_img, cv2.COLOR_BGR2RGB)
detect_with_hog(hog_detector, rgb_img, 300)
detect_with_cnn(cnn_detector, rgb_img, 300)
cv2.waitKey(0)
其实OpenCV和Dlib比较类似也提供了一个不是基于深度学习和一个基于深度学习的检测方法,和Dlib的两个方法各有千秋,有机会可以再提一下。
关键点预测
Dlib里面提供了两个关键点预测模型,从dlib-models repo也可以看出来,分别是5 face landmarks 和 68 face landmarks。
其中5点位是左右眼睛分别两个,鼻子下一个。
68点位我前面也大概介绍过:

【OPENCV/Dlib/Firebase】人脸关键点定位及配准 这篇文章有介绍
怎么使用直接看代码吧:
def show_landmarks(detector, landmarks_predictor, rgb_img, height=512, width=0):
faceRects = detector(rgb_img, 0)
faces = dlib.full_object_detections()
for faceRect in faceRects:
shape = landmarks_predictor(rgb_img, faceRect)
for i in range(shape.num_parts):
coords = shape.part(i).x, shape.part(i).y
cv2.circle(rgb_img, coords, 2, (255, 0, 0), 2)
cv2.imshow("lanmarks", rgb_img)
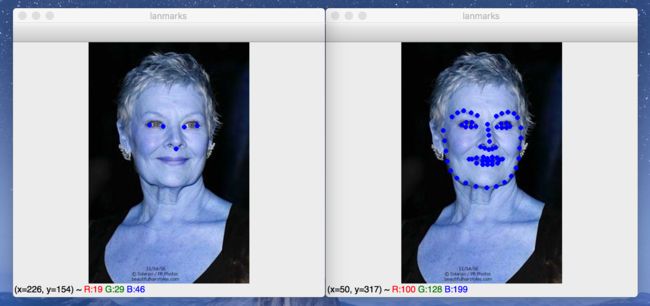
人脸配准
人脸配准是很多其他功能的前提,比如我们最近做的一个脸型预测功能,就必须对人脸进行配准之后才能得到更好的准确率,否则脸在水平平面和垂直水平平面进行旋转都会影响准确率的计算。
Dlib中人脸配准有两种方式一种是使用 get_face_chip()方法,使用5个关键点模型来进行配准,这种方法Dlib已经提供了完整的接口,另一种是自己使用68点关键点模型,根据关键点信息求解变换矩阵,然后把变换矩阵应用到整个图像上。
先看get_face_chip()方法:
- 先检测人脸
- 用得到的人脸位置信息来预测关键点
- 再使用get_face_chips方法返回配准好的人脸
这个get_face_chip()方法内部是怎么实现的,我现在还不知道
def align_face(detector, five_landmarks_predictor, img, height=512, width=0):
gray_img = cv2.cvtColor(rgb_img, cv2.COLOR_RGB2GRAY)
faceRects = detector(rgb_img, 0)
faces = dlib.full_object_detections()
for faceRect in faceRects:
faces.append(five_landmarks_predictor(img, faceRect))
if len(faces) != 0:
face = dlib.get_face_chip(rgb_img, faces[0], size=224, padding=0.25)
cv2.imshow("aligned_face", face)
第二种方法也是我从别处学习到的,先根据68点点位信息中的眼睛周围的点位置信息,求解出两只眼睛中间点的信息。详细介绍可以参考我另一篇关于Dlib的文章。文章最后会贴出所有的代码。
face-embedding
face-embedding简单来说就是将人脸简单编码成一个低维度的特征向量,然后可以使用这个低维的特征向量来代表人脸特征,可以用来进行人脸特征分类,性别识别,人脸识别等等功能。
Dlib里面也提供了一个将人脸编码为128维度向量的模型,传入landmarks和compute_face_descriptor接口就可以得到编码向量
def face_embedding(detector, landmarks_predictor, embedding_predictor, rgb_img, height=512, width=0):
faceRects = detector(rgb_img, 0)
faces = dlib.full_object_detections()
for faceRect in faceRects:
shape = landmarks_predictor(rgb_img, faceRect)
face_embedding = embedding_predictor.compute_face_descriptor(rgb_img, shape)
print("face embedding shape:", face_embedding.shape)
具体使用实例可以参考我前面的一篇文章Dlib人脸特征提取
所有例子的代码都可以在这找到dlib_usage
Have fun!
后面开始介绍NCNN了