Redis5.0新特性
1.Stream 特性
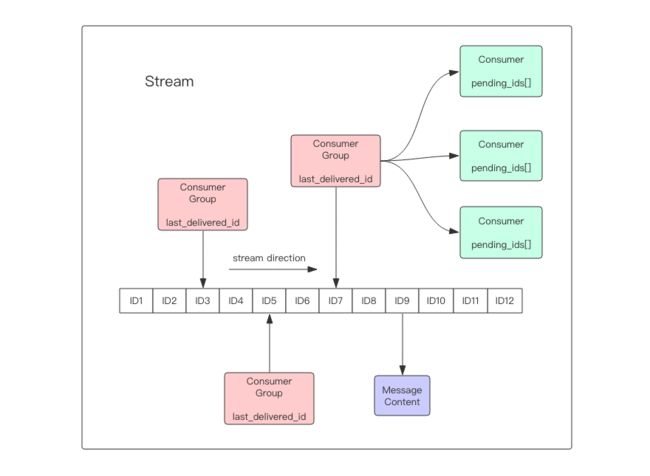
概念:是一个新的强大的支持多播的 可持久化的消息队列
组成:一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容。消息是持久化的,Redis 重启后,内容还在。
每个Stream可以挂多个消费组,每隔消费组都有一个last_delivered_id在Stream数组之上移动,表示消费者已经移动到那条信息了。
消息Id:timestampInMillis-sequence 是时间戳+随机数。可由服务器自己生产也可自己指定。
命令:xadd 增加消息 xdel:删除消息 xrange:获取消息列表,自动过滤已经删除的消息,xleng:获取消息长度,del:删除stream.
##one 是key *标识服务器自动产生Id(573786170148-0) 后边跟很多的key和value
172.31.123.211:9999> xadd one * name zhh v 20
"1573786170148-0"
172.31.123.211:9999> xadd one * name zhh v 21
"1573786212867-0"
172.31.123.211:9999> xadd one * name zhh v 22
"1573786223915-0"
172.31.123.211:9999> xlen one
(integer) 3
##- 标识最小值,+标识最大值 列出所有的消息
172.31.123.211:9999> XRANGE one - +
1) 1) "1573786170148-0"
2) 1) "name"
2) "zhh"
3) "v"
4) "20"
2) 1) "1573786212867-0"
2) 1) "name"
2) "zhh"
3) "v"
4) "21"
3) 1) "1573786223915-0"
2) 1) "name"
2) "zhh"
3) "v"
4) "22"
##根据队列中的Id删除 xdel key id
172.31.123.211:9999> XDEL one 1573786170148-0
(integer) 1
##获取队列长度 xlen key
172.31.123.211:9999> xlen one
(integer) 2
消费者独立消费:
##count 标识读取几条 而 streams one 0-0 标识 id要大于0-0
172.31.123.211:9999> xread count 1 streams one 0-0
1) 1) "one"
2) 1) 1) "1573786212867-0"
2) 1) "name"
2) "zhh"
3) "v"
4) "21"
##注意这个与上述不同 加入了bock 0 标识阻塞读取 返回最新的消息 并且加入了 $ 标识 意思告诉streams 已经存储的最大ID作为最后一个ID 相当于linux 中的tail -f
172.31.123.211:9999> xread count 1 block 0 streams one $
创建消费组
#xgroup create key groupName 0-0 表示Id大于0的消息
172.31.123.211:9999> XGROUP create one c1 0-0
OK
##获取消费者组信息
172.31.123.211:9999> xinfo groups one
1) 1) "name"
2) "c1"
3) "consumers"
4) (integer) 0
5) "pending"
6) (integer) 0
7) "last-delivered-id"
8) "0-0"
###消费者组读取信息 其中符号">" 标识获取最新的 msg,及没有返回给其他消费者的消息。
XREADGROUP group c1 c count 1 streams one >
##ack 一条信息
XACK codehole cg1 1527851486781-0
stream 在每个消费者结构中保存了正在消费的消息ID,每个消费者的ID组成了
PEL列表 ,如果消费者忘记确认消费,那么这个消费者的PEL内存会越来越大
stream如何保证消息不丢失
当客户端读取Stream消息时,Redis服务器返回给客户端时,如果客户端断开连接,消息就丢失了。但是消费者中的数据结构PEL列表保存了已经发送出去的消息ID,当客户端重新连接后,可以再次收到PEl中的消息ID。
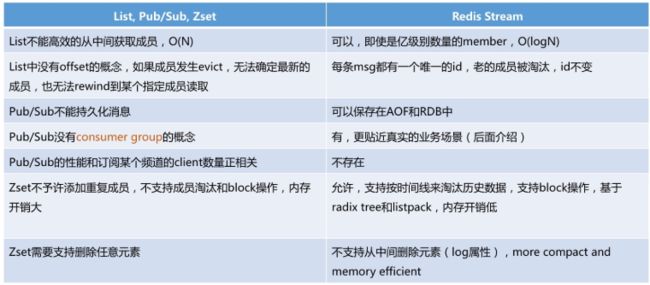
Stream和pub/sub有什么区别
Redis Stream 简介
Info指令
redis的info指令非常强大,可以显示的信息非常多,一般可以分为9大块
info server/clients/memory/persistence/stats/replication/cpu/cluster/KeySpace
1、Server 服务器运行的环境参数
2、Clients 客户端相关信息
3、Memory 服务器运行内存统计数据
4、Persistence 持久化信息
5、Stats 通用统计数据
6、Replication 主从复制相关信息
7、CPU CPU 使用情况
8、Cluster 集群信息
9、KeySpace 键值对统计数量信息
172.31.123.211:9999> info stats
# Stats
total_connections_received:2
total_commands_processed:47
instantaneous_ops_per_sec:0
total_net_input_bytes:3101
total_net_output_bytes:25863
instantaneous_input_kbps:0.00
instantaneous_output_kbps:0.00
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
expired_stale_perc:0.00
expired_time_cap_reached_count:0
evicted_keys:0
keyspace_hits:42
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:889
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
172.31.123.211:9999> info persistence
# Persistence
loading:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1573795747
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:4481024
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
主要介绍几个 比较重要的 操作:
1.查看复制积压缓冲区大小
127.0.0.1:6379[2]> info replication
# Replication
role:master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576 #这个就是复制缓冲区的大小
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
这个参数非常重要,当主从同步的时候,从库因为网络问题断开连接,主库修改的命令都会写入到这个缓冲区,当从库恢复的时候,从库可以从缓冲区恢复主库修改的命令。
缓冲区是环形的,上面有提到过,后面来的执行会覆盖前面的指令,如果从库断开时间过长,或者缓冲区设置的大小过小,都会导致数据丢失的情况。那么这个时候就需要全量同步了,全量同步是十分耗费网络资源和CPU的。
多个从库共享一个缓冲区。
2.查看redis占用多大内存
[hanghang.zhang@bogon bin]$ redis-cli -p 6379 -a 02903954-2df7-11e6-89f6-b7c698d5ea2d info memory|grep human
used_memory_human:509.97M 内存分配器从操作系统分配的内存
used_memory_rss_human:579.53M
used_memory_peak_human:550.11M
total_system_memory_human:31.03G 操作系统总内存大小
used_memory_lua_human:37.00K 脚本引擎占用的大小
maxmemory_human:0B
Redis做分布式锁所面临的问题。
我们介绍过redis分布式锁,一条指令就可以完成加锁操作,不过在集群的环境下,他是有缺陷的,并不是绝对安全。
比如在 Sentinel 集群中,主节点挂掉时,从节点会取而代之,客户端上却并没有明显感知。
原先第一个客户端在主节点中申请成功了一把锁,但是这把锁还没有来得及同步到从节点,主节点突然挂掉了。然后从节点变成了主节点,这个新的节点内部没有这个锁,所以当另一个客户端过来请求加锁时,立即就批准了。
这样就会导致系统中同样一把锁被两个客户端同时持有。
而且这种情况仅仅发生在主从failOver的情况下,才会产生。
解决这个问题,Redis出现了readLock算法,加锁时,他会想半数借点发送set(key,value,nx=True,ex=xxx)指令,只有过半节点才会成功。释放锁,需要向所有节点发送del指令。
Redis过期key
因为Redis是单线程的,在过期key删除的同时,也会占用线程的时间,如果删除的过多,会导致线上服务卡顿。
Redis将过期的key放在一个独立的字典里面,定时扫面这个数据字典,来删除到期的key。或者使用惰性策略来删除过期的 key,所谓惰性策略就是在客户端访问这个 key 的时候,redis 对 key 的过期时间进行检查,如果过期
了就立即删除。定时删除是集中处理,惰性删除是零散处理。
因为Redis是定时扫面过期key,如果有大批量key过期,会导致线上服务器卡顿,所以有大批量的 key 过期,要给过期时间设置一个随机范围,而不能全部在同一时间过期,
redis.expire(key,random.nexInt(86400)+exirpe);
在一些活动系统中,因为活动是一期一会,下一期活动举办时,前面几期的很多数据都可以丢弃了,所以需要给相关的活动数据设置一个过期时间,以减少不必要的 Redis 内存占用。
Redis惰性删除
如果一个key值过大,直接点用redis 的del指令 造成服务器卡顿,及为解决删除大key问题,redis在4.0版本以上加入了 unlink 指令
>unlink key
可以将整个 Redis 内存里面所有有效的数据想象成一棵大树。
当 unlink 指令发出时,它只是把大树中的一个树枝别断了,然后扔到旁边的火堆里焚烧 。树枝离开大树的一瞬间,它就再也无法被主线程中的其它指令访问到了,因为主线程只会沿着这颗大树来访问。
redis提供flushDb和flushAll 用来清空数据库,这也是极其缓慢的操作。也可以加入异步化,
>flushDb async / flushAll async
Redis4.0 为这些删除点也带来了异步删除机制,打开这些点需要额外的配置选项。
1、slave-lazy-flush 主从同步,快照同步时,从库接受完 rdb 文件后的 flush 操作
2、lazyfree-lazy-eviction 内存达到 maxmemory 时进行淘汰
3、lazyfree-lazy-expire key 过期的key进行删除时
4、lazyfree-lazy-server-del rename 指令删除 destKey
