本文引用了“拍乐云Pano”的“深入浅出理解视频编解码技术”和“揭秘视频千倍压缩背后的技术原理之预测技术”文章部分内容,感谢原作者的分享。
1、引言
从 20 世纪 90 年代以来,数字音视频编解码技术迅速发展,一直是国内外研究的热点领域。随着5G的成熟和广泛商用,带宽已经越来越高,传输音视频变得更加容易。视频直播、视频聊天,已经完全融入了每个人的生活。
视频为何如此普及呢?是因为通过视频能方便快捷地获取到大量信息。但视频数据量非常巨大,视频的网络传输也面临着巨大的挑战。于是视频编解码技术就出场了。
具体到实时视频场景,不仅仅是数据量的问题,实时通信对时延要求、设备适配、带宽适应的要求也非常高,要解决这些问题,始终离不开视频编解码技术的范畴。
本文将从视频编解码技术的基础知识入手,引出视频编解码技术中非常基础且重要的预测技术,学习帧内预测和帧间预测的技术原理。
(本文已同步发布于:http://www.52im.net/thread-35...
2、相关文章
如果你是音视频技术初学者,以下3篇入门级干货非常推荐一读:
《零基础,史上最通俗视频编码技术入门》
《零基础入门:实时音视频技术基础知识全面盘点》
《实时音视频面视必备:快速掌握11个视频技术相关的基础概念》
3、为什么需要视频编解码
首先,来复习一下视频编解码方面的理论常识。
视频是由一系列图片按照时间顺序排列而成:
- 1)每一张图片为一帧;
- 2)每一帧可以理解为一个二维矩阵;
- 3)矩阵的每个元素为一个像素。
一个像素通常由三个颜色进行表达,例如用RGB颜色空间表示时,每一个像素由三个颜色分量组成。每一个颜色分量用1个字节来表达,其取值范围就是0~255。编码中常用的YUV格式与之类似,这里不作展开。
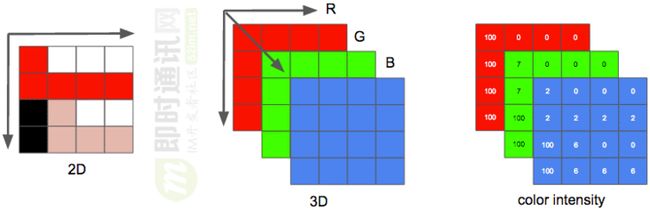
以1280x720@60fps的视频序列为例,十秒钟的视频有:128072036010 = 1.6GB。
如此大量的数据,无论是存储还是传输,都面临巨大的挑战。视频压缩或者编码的目的,也是为了保证视频质量的前提下,将视频减小,以利于传输和存储。同时,为了能正确还原视频,需要将其解码。
PS:限于篇幅,视频编解码方面的技术原理就不在此展开,有兴趣强烈推荐从这篇深入学习:《即时通讯音视频开发(十九):零基础,史上最通俗视频编码技术入门》。
总之,视频编解码技术的主要作用就是:在可用的计算资源内,追求尽可能高的视频重建质量和尽可能高的压缩比,以达到带宽和存储容量的要求。
为何突出“重建质量”?
因为视频编码是个有损的过程,用户只能从收到的视频流中解析出“重建”画面,它与原始的画面已经不同,例如观看低质量视频时经常会碰到的“块”效应。
如何在一定的带宽占用下,尽可能地保持视频的质量,或者在保持质量情况下,尽可能地减少带宽利用率,是视频编码的基本目标。
用专业术语来说,即视频编解码标准的“率失真”性能:
- 1)“率”是指码率或者带宽占用;
- 2)“失真”是用来描述重建视频的质量。
与编码相对应的是解码或者解压缩过程,是将接收到的或者已经存储在介质上的压缩码流重建成视频信号,然后在各种设备上进行显示。
4、什么是视频编解码标准
视频编解码标准,通常只定义上述的解码过程。
例如 H.264 / AVC 标准,它定义了什么是符合标准的视频流,对每一个比特的顺序和意义都进行了严格地定义,对如何使用每个比特或者几个比特表达的信息也有精确的定义。
正是这样的严格和精确,保证了不同厂商的视频相关服务,可以很方便地兼容在一起,例如用 iPhone、Android Phone 或者 windows PC 都可以观看同一在线视频网站的同一视频。
世界上有多个组织进行视频编码标准的制定工作,国际标准组织 ISO 的 MPEG 小组、国际电信联盟 ITU-T 的 VCEG 小组、中国的 AVS 工作组、Google 及各大厂商组成的开放媒体联盟等。
视频编码标准及发展历史: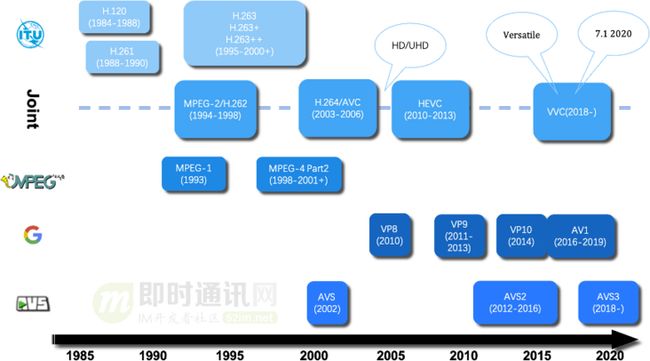
自 VCEG 制定 H.120标准开始,视频编码技术不断发展,先后成功地制定了一系列满足不同应用场景的视频编码标准。VCEG 组织先后制定了H.120、H.261、H.262(MPEG-2 Part 2)、H.263、H.263+、H.263++。
MPEG也先后制定了MPEG-1、MPEG-2、MPEG-4 Part 2。以及两个国际组织合作制定的H.264/AVC、H.265/HEVC、H.266/VVC。
中国自主知识产权的 AVS、AVS2、AVS3 视频编码标准;Google 制定的 VP8、VP9。
Google、思科、微软、苹果等公司组成的开放媒体联盟(AOM)制定的 AV1。
这里特别提一下H.264/AVC:H.264/AVC虽有近20年历史,但它优秀的压缩性能、适当的运算复杂度、优秀的开源社区支持、友好的专利政策、强大的生态圈等多个方面的因素,依旧让它保持着强大的生命力,特别是在实时通信领域。像 ZOOM、思科 Webex 等视频会议产品和基于 WebRTC SDK 的视频服务,大多数主流场景都采用 H.264/AVC。
有关视频编解码标准,这里就不深入展开。更多详细资料,可以读一下下面这些精选文章:
- 《即时通讯音视频开发(五):认识主流视频编码技术H.264》
- 《即时通讯音视频开发(十三):实时视频编码H.264的特点与优势》
- 《即时通讯音视频开发(十七):视频编码H.264、VP8的前世今生》
- 《爱奇艺技术分享:轻松诙谐,讲解视频编解码技术的过去、现在和将来》
5、混和编码框架
纵观视频编解码标准历史,每一代视频标准都在率失真性能上有着显著的提升,他们都有一个核心的框架,就是基于块的混合编码框架(如下图所示)。它是由J. R. Jain 和A. K. Jain在1979年的国际图像编码学会(PCS 1979)上提出了基于块运动补偿和变换编码的混合编码框架。

我们一起来对该框架进行拆解和分析。
从摄像头采集到的一帧视频:通常是 YUV 格式的原始数据,我们将它划分成多个方形的像素块依次进行处理(例如 H.264/AVC 中以16x16像素为基本单元),进行帧内/帧间预测、正变换、量化、反量化、反变换、环路滤波、熵编码,最后得到视频码流。从视频第一帧的第一个块开始进行空间预测,因当前正在进行编码处理的图像块和其周围的图像块有相似性,我们可以用周围的像素来预测当前的像素。我们将原始像素减去预测像素得到预测残差,再将预测残差进行变换、量化,得到变换系数,然后将其进行熵编码后得到视频码流。
接下来:为了可以使后续的图像块可以使用已经编码过的块进行预测,我们还要对变换系统进行反量化、反变换,得到重建残差,再与预测值进行求合,得到重建图像。最后我们对重建图像进行环路滤波、去除块效应等,这样得到的重建图像,就可以用来对后续图像块进行预测了。按照以上步骤,我们依次对后续图像块进行处理。
对于视频而言:视频帧与帧的间隔大约只有十到几十毫秒,通常拍摄的内容不会发生剧烈变化,它们之间存在非常强的相关性。
如下图所示,将视频图像分割成块,在时间相邻的图像之间进行匹配,然后将匹配之后的残差部分进行编码,这样可以较好地去除视频信号中的视频帧与帧之间的冗余,达到视频压缩的目的。这就是运动补偿技术,直到今天它仍然是视频编解码的核心技术之一。
运动估计和运动补偿: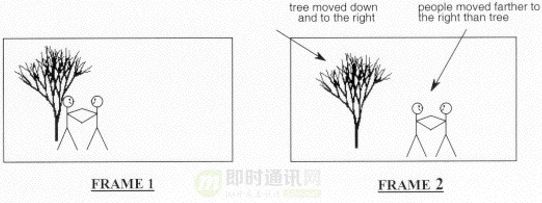
变换编码的核心思想:是把视频数据分割成块,利用正交变换将数据的能量集中到较少几个变换系数上。结合量化和熵编码,我们可以获得更有效的压缩。视频编码中信息的损失和压缩比的获得,很大程度上来源于量化模块,就是将源信号中的单一样本映射到某一固定值,形成多到少的映射,从而达到压缩的目的,当然在压缩的过程中就引入了损失。量化后的信号再进行无损的熵编码,消除信号中的统计冗余。熵编码的研究最早可以追溯到 20 世纪 50 年代,经过几十年的发展,熵编码在视频编码中的应用更加成熟、更加精巧,充分利用视频数据中的上下文信息,将概率模型估计得更加准确,从而提高了熵编码的效率。例如H.264/AVC中的Cavlc(基于上下文的变长编码)、Cabac(基于上下文的二进制算术编码)。算术编码技术在后续的视频编码标准,如AV1、HEVC/H.265、VVC/H.266 中也有应用。
视频编码发展至今,VVC/H.266 作为最新制定的标准,采纳了一系列先进的技术,对混合编码框架的各个部分都进行了优化和改进,使得其率失真性能相比前一代标准,又提高了一倍。
例如:VVC/H.266 采用了128x128大小的基本编码单元,并且可以继续进行四叉树划分,支持对一个划分进行二分、三分;色度分量独立于亮度分量,支持单独进行划分;更多更精细的帧内预测方向、帧间预测模式;支持多种尺寸和形式的变换、环内滤波等。
VVC/H.266 的制定,目标是对多种视频内容有更好支持,例如屏幕共享内容、游戏、动漫、虚拟现实内容(VR、AR)等。其中也有特定的技术被采纳进标准,例如调色板模式、帧内运动补偿、仿射变换、跳过变换、自适应颜色变换等。
回到本文的正题,接下来的内容,我们着重介绍视频编解码中的预测技术。
6、帧内预测技术
视频数据被划分成方块之后,相邻的方块的像素,以及方块内的像素,颜色往往是逐渐变化的,他们之间有比较强的有相似性。这种相似性,就是空间冗余。既然存在冗余,就可以用更少的数据量来表达这样的特征。
比如:先传输第一个像素的值,再传输第二个像素相对于第一个像素的变化值,这个变化值往往取值范围变小了许多,原来要8个bit来表达的像素值,可能只需要少于8个bit就足够了。
同样的道理,以像素块为基本单位,也可以进行类似的“差分”操作。我们从示例图中,来更加直观地感受一下这样的相似性。

如上图中所标出的两个8x8的块:其亮度分量(Y)沿着“左上到右下”的方向,具有连续性,变化不大。
假如:我们设计某种特定的“模式”,使其利用左边的块来“预测”右边的块,那么“原始像素”减去“预测像素”就可以减少传输所需要的数据量,同时将该“模式”写入最终的码流,解码器便可以利用左侧的块来“重建”右侧的块。
极端一点讲:假如左侧的块的像素值经过一定的运算可以完全和右侧的块相同,那么编码器只要用一个“模式”的代价,传输右侧的块。
当然,视频中的纹理多种多样,单一的模式很难对所有的纹理都适用,因此标准中也设计了多种多样的帧内预测模式,以充分利用像素间的相关性,达到压缩的目的。
例如下图所示的H.264中9种帧内预测方向:以模式0(竖直预测)为例,上方块的每个像素值(重建)各复制一列,得到帧内预测值。其它各种模式也采用类似的方法,不过,生成预测值的方式稍有不同。有这么多的模式,就产生了一个问题,对于一个块而言,我们应该采用哪种模式来进行编码呢?最佳的选择方式,就是遍历所有的模式进行尝试,计算其编码的所需的比特数和产生的质量损失,即率失真优化,这样明显非常复杂,因而也有很多种其它的方式来推断哪种模式更好,例如基于SATD或者边缘检测等。
从H.264的9种预测模式,到AV1的56种帧内方向预测模式,越来越多的模式也是为了更加精准地预测未编码的块,但是模式的增加,一方面增加了传输模式的码率开销,另一方面,从如此重多的模式中选一个最优的模式来编码,使其能达到更高的压缩比,这对编码器的设计和实现也提出了更高的要求。

7、帧间预测技术
以下5张图片是一段视频的前5帧:可以看出,图片中只有Mario和砖块在运动,其余的场景大多是相似的,这种相似性就称之为时间冗余。编码的时候,我们先将第一帧图片通过前文所述的帧内预测方式进行编码传输,再将后续帧的Mario、砖块的运动方向进行传输,解码的时候,就可以将运动信息和第一帧一起来合成后续的帧,这样就大大减少了传输所需的bit数。这种利用时间冗余来进行压缩的技术,就是运动补偿技术。该技术早在H.261标准中,就已经被采用。

细心地读者可能已经发现:Mario和砖块这样的物体怎么描述,才能让它仅凭运动信息就能完整地呈现出来?
其实视频编码中并不需要知道运动的物体的形状,而是将整帧图像划分成像素块,每个像素块使用一个运动信息。即基于块的运动补偿。
下图中红色圈出的白色箭头即编码砖块和Mario时的运动信息,它们都指向了前一帧中所在的位置。Mario和砖块都有两个箭头,说明它们都被划分在了两个块中,每一个块都有单独的运动信息。这些运动信息就是运动矢量。运动矢量有水平和竖直两个分量,代表是的一个块相对于其参考帧的位置变化。参考帧就是已经编码过的某一(多)个帧。

当然:传输运动矢量本身就要占用很多 bit。为了提高运动矢量的传输效率,主要有以下措施。
一方面:可以尽可能得将块划分变大,共用一个运动矢量,因为平坦区域或者较大的物体,他们的运动可能是比较一致的。从 H.264 开始,可变块大小的运动补偿技术被广泛采用。
另一方面:相邻的块之间的运动往往也有比较高的相似性,其运动矢量也有较高的相似性,运动矢量本身也可以根据相邻的块运动矢量来进行预测,即运动矢量预测技术;
最后:运动矢量在表达物体运动的时候,有精度的取舍。像素是离散化的表达,现实中物体的运动显然不是以像素为单位进行运动的,为了精确地表达物体的运动,需要选择合适的精度来定义运动矢量。各视频编解码标准都定义了运动矢量的精度,运动矢量精度越高,越能精确地表达运动,但是代价就是传输运动矢量需要花费更多的bit。
H.261中运动矢量是以整像素为精度的,H.264中运动矢量是以四分之一像素为精度的,AV1中还增加了八分之一精度。一般情况,时间上越近的帧,它们之间的相似性越高,也有例外,例如往复运动的场景等,可能相隔几帧,甚至更远的帧,会有更高的相似度。
为了充分利用已经编码过的帧来提高运动补偿的准确度,从H.264开始引入了多参考帧技术。
即:一个块可以从已经编码过的很多个参考帧中进行运动匹配,将匹配的帧索引和运动矢量信息都进行传输。
那么如何得到一个块的运动信息呢?最朴素的想法就是,将一个块,在其参考帧中,逐个位置进行匹配检查,匹配度最高的,就是最终的运动矢量。
匹配度:常用的有SAD(Sum of Absolute Difference)、SSD(Sum of Squared Difference)等。逐个位置进行匹配度检查,即常说的全搜索运动估计,其计算复杂度可想而知是非常高的。为了加快运动估计,我们可以减少搜索的位置数,类似的有很多算法,常用的如钻石搜索、六边形搜索、非对称十字型多层次六边形格点搜索算法等。
以钻石搜索为例,如下图所示,以起始的蓝色点为中心的9个匹配位置,分别计算这9个位置的SAD,如果SAD最小的是中心位置,下一步搜索中心点更近的周围4个绿色点的SAD,选择其中SAD最小的位置,继续缩小范围进行搜索;如果第一步中SAD最小的点不在中心,那么以该位置为中心,增加褐色的5或者3个点,继续计算SAD,如此迭代,直到找到最佳匹配位置。
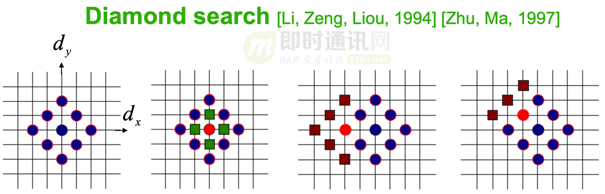
编码器在实现时,可根据实际的应用场景,对搜索算法进行选择。
例如:在实时音视频场景下,计算复杂度是相对有限的,运动估计模块要选择计算量较小的算法,以平衡复杂度和编码效率。当然,运动估计与运动补偿的复杂度还与块的大小,参考帧的个数,亚像素的计算等有关,在此不再深入展开。
更多预测技术方面的原理这里就不再赘述。如果你对上面所述的预测技术理解上感到力不从心,这里有篇入门级的文章,可以先读读这篇《即时通讯音视频开发(四):视频编解码之预测技术介绍》。
8、写在最后
音视频编解码技术,归根结底就是在有限的资源下(网络带宽、计算资源等),让音质更清晰、视频更高质。
这其中,对于视频来说,质量的提升仍然有很多可以深入研究的热点问题。
比如:基于人眼的主观质量优化,主要利用人眼的视觉特性,将掩蔽效应、对比度灵敏度、注意力模型等与编码相结合,合理分配码率、减少编码损失引起的视觉不适。
AI在视频编解码领域的应用:包括将多种人工智能算法,如分类器、支持向量机、CNN等对编码参数进行快速选择,也可以使用深度学习对视频进行编码环外与编码环内的处理,如视频超分辨率、去噪、去雾、自适应动态范围调整等编码环外处理,达到提升视频质量的目的。
此外还有打破传统混合编码框架的深度神经网络编码,如Nvidia的Maxine视频会议服务,利用深度学习来提取特征,然后对特征进行传输以节省带宽。
附录:更多精华文章
[1] 实时音视频开发的其它精华资料:
《即时通讯音视频开发(一):视频编解码之理论概述》
《即时通讯音视频开发(二):视频编解码之数字视频介绍》
《即时通讯音视频开发(三):视频编解码之编码基础》
《即时通讯音视频开发(四):视频编解码之预测技术介绍》
《即时通讯音视频开发(五):认识主流视频编码技术H.264》
《即时通讯音视频开发(六):如何开始音频编解码技术的学习》
《即时通讯音视频开发(七):音频基础及编码原理入门》
《即时通讯音视频开发(八):常见的实时语音通讯编码标准》
《即时通讯音视频开发(九):实时语音通讯的回音及回音消除概述》
《即时通讯音视频开发(十):实时语音通讯的回音消除技术详解》
《即时通讯音视频开发(十一):实时语音通讯丢包补偿技术详解》
《即时通讯音视频开发(十二):多人实时音视频聊天架构探讨》
《即时通讯音视频开发(十三):实时视频编码H.264的特点与优势》
《即时通讯音视频开发(十四):实时音视频数据传输协议介绍》
《即时通讯音视频开发(十五):聊聊P2P与实时音视频的应用情况》
《即时通讯音视频开发(十六):移动端实时音视频开发的几个建议》
《即时通讯音视频开发(十七):视频编码H.264、VP8的前世今生》
《即时通讯音视频开发(十八):详解音频编解码的原理、演进和应用选型》
《即时通讯音视频开发(十九):零基础,史上最通俗视频编码技术入门》
《实时语音聊天中的音频处理与编码压缩技术简述》
《网易视频云技术分享:音频处理与压缩技术快速入门》
《学习RFC3550:RTP/RTCP实时传输协议基础知识》
《基于RTMP数据传输协议的实时流媒体技术研究(论文全文)》
《声网架构师谈实时音视频云的实现难点(视频采访)》
《浅谈开发实时视频直播平台的技术要点》
《还在靠“喂喂喂”测试实时语音通话质量?本文教你科学的评测方法!》
《实现延迟低于500毫秒的1080P实时音视频直播的实践分享》
《移动端实时视频直播技术实践:如何做到实时秒开、流畅不卡》
《如何用最简单的方法测试你的实时音视频方案》
《技术揭秘:支持百万级粉丝互动的Facebook实时视频直播》
《简述实时音视频聊天中端到端加密(E2EE)的工作原理》
《移动端实时音视频直播技术详解(一):开篇》
《移动端实时音视频直播技术详解(二):采集》
《移动端实时音视频直播技术详解(三):处理》
《移动端实时音视频直播技术详解(四):编码和封装》
《移动端实时音视频直播技术详解(五):推流和传输》
《移动端实时音视频直播技术详解(六):延迟优化》
《理论联系实际:实现一个简单地基于HTML5的实时视频直播》
《IM实时音视频聊天时的回声消除技术详解》
《浅谈实时音视频直播中直接影响用户体验的几项关键技术指标》
《如何优化传输机制来实现实时音视频的超低延迟?》
《首次披露:快手是如何做到百万观众同场看直播仍能秒开且不卡顿的?》
《Android直播入门实践:动手搭建一套简单的直播系统》
《网易云信实时视频直播在TCP数据传输层的一些优化思路》
《实时音视频聊天技术分享:面向不可靠网络的抗丢包编解码器》
《P2P技术如何将实时视频直播带宽降低75%?》
《专访微信视频技术负责人:微信实时视频聊天技术的演进》
《腾讯音视频实验室:使用AI黑科技实现超低码率的高清实时视频聊天》
《微信团队分享:微信每日亿次实时音视频聊天背后的技术解密》
《近期大热的实时直播答题系统的实现思路与技术难点分享》
《福利贴:最全实时音视频开发要用到的开源工程汇总》
《七牛云技术分享:使用QUIC协议实现实时视频直播0卡顿!》
《实时音视频聊天中超低延迟架构的思考与技术实践》
《理解实时音视频聊天中的延时问题一篇就够》
《实时视频直播客户端技术盘点:Native、HTML5、WebRTC、微信小程序》
《写给小白的实时音视频技术入门提纲》
《微信多媒体团队访谈:音视频开发的学习、微信的音视频技术和挑战等》
《腾讯技术分享:微信小程序音视频技术背后的故事》
《微信多媒体团队梁俊斌访谈:聊一聊我所了解的音视频技术》
《新浪微博技术分享:微博短视频服务的优化实践之路》
《实时音频的混音在视频直播应用中的技术原理和实践总结》
《以网游服务端的网络接入层设计为例,理解实时通信的技术挑战》
《腾讯技术分享:微信小程序音视频与WebRTC互通的技术思路和实践》
《新浪微博技术分享:微博实时直播答题的百万高并发架构实践》
《技术干货:实时视频直播首屏耗时400ms内的优化实践》
《爱奇艺技术分享:轻松诙谐,讲解视频编解码技术的过去、现在和将来》
《零基础入门:实时音视频技术基础知识全面盘点》
《实时音视频面视必备:快速掌握11个视频技术相关的基础概念》
《淘宝直播技术干货:高清、低延时的实时视频直播技术解密》
《实时音视频开发理论必备:如何省流量?视频高度压缩背后的预测技术》更多同类文章 ……
[2] 开源实时音视频技术WebRTC的文章:
《开源实时音视频技术WebRTC的现状》
《简述开源实时音视频技术WebRTC的优缺点》
《访谈WebRTC标准之父:WebRTC的过去、现在和未来》
《良心分享:WebRTC 零基础开发者教程(中文)[附件下载]》
《WebRTC实时音视频技术的整体架构介绍》
《新手入门:到底什么是WebRTC服务器,以及它是如何联接通话的?》
《WebRTC实时音视频技术基础:基本架构和协议栈》
《浅谈开发实时视频直播平台的技术要点》
《[观点] WebRTC应该选择H.264视频编码的四大理由》
《基于开源WebRTC开发实时音视频靠谱吗?第3方SDK有哪些?》
《开源实时音视频技术WebRTC中RTP/RTCP数据传输协议的应用》
《简述实时音视频聊天中端到端加密(E2EE)的工作原理》
《实时通信RTC技术栈之:视频编解码》
《开源实时音视频技术WebRTC在Windows下的简明编译教程》
《网页端实时音视频技术WebRTC:看起来很美,但离生产应用还有多少坑要填?》
《了不起的WebRTC:生态日趋完善,或将实时音视频技术白菜化》
《腾讯技术分享:微信小程序音视频与WebRTC互通的技术思路和实践》
《融云技术分享:基于WebRTC的实时音视频首帧显示时间优化实践》更多同类文章 ……本文已同步发布于“即时通讯技术圈”公众号。
▲ 本文在公众号上的链接是:点此进入。同步发布链接是:http://www.52im.net/thread-35...
