前言
对于Java开发者来说,Spring无疑是最常用也是最基础的框架之一。(此处省略1w字吹Spring)。相信很多同行跟我一样,只是停留在会用的阶段,比如用@Component写一个组件、用@Autowired注入其他组件等等,但是不知道为什么可以这么做,Spring是怎么实现的。为了了解这些,我阅读了《Spring源码深度解析》,这本书讲的很详细,但是因为步骤多而复杂容易记混,我就做了一下梳理,先呈现大致流程,但对每个步骤进行详细描述。
概念
概念上的东西还是要提一嘴的:
Spring用IoC容器来管理Bean。
BeanFactory和ApplicationContext是SpringIoC容器的两种表现形式。
BeanFactory定义了简单IoC容器的基本功能。
ApplicationContext实现了BeanFactory,且通过继承MessageSource、ResourceLoader、ApplicationEventPublisher接口,添加了许多高级容器的特性。
XmlBeanFactory
这里以XmlBeanFactory为代表,看容器是怎么工作的。
新建一个XmlBeanFactory很简单,只需要你有一个符合格式的xml文件,里面用
BeanFactory bf = new XmlBeanFactory(new ClassPathResource("test.xml"))
新建了一个ClassPathResource资源对象作为参数传入XmlBeanFactory的构造函数。
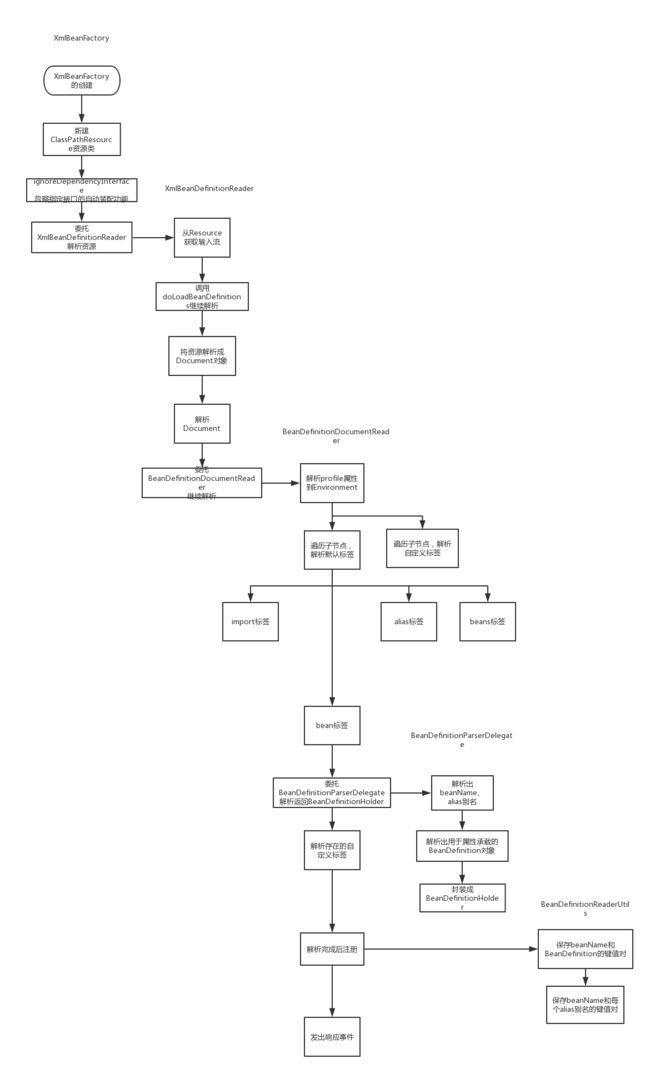
点进XmlBeanFactory类,XmlBeanFactory会先调用父类构造器,一直跟踪到AbstractAutowireCapableBeanFactory,会看到调用了三次ignoreDependencyInterface用来忽略给定接口的自动装配功能(后面会提到);再调用this.reader.loadBeanDefinitions(Resource),用自己持有的XmlBeanDefinitionReader解析传入的资源。所以最宏观的三个步骤:
1、新建了一个ClassPathResource资源。抽象出一个资源类来表示资源;
2、调用了ignoreDependencyInterface忽略指定接口的自动装配功能;
3、委托XmlBeanDefinitionReader解析资源。
重点肯定在第三步了,点进XmlBeanDefinitionReader,到loadBeanDefinitions(EncodedResource),先从
Resource获取InputStream构造成InputSource,作为参数调用doLoadBeanDefinitions(InputSource, Resource)开始真正的解析。所以第三步下面是两个小步骤:
3.1、从Resource获取输入流;
3.2、调用doLoadBeanDefinitions继续解析。
再看doLoadBeanDefinitions方法,主要是两个方法,doLoadDocument(inputSource, resource)解析输入流返回一个Document对象;registerBeanDefinitions(doc, resource)继续解析Document返回解析的Bean数量,所以3.2下面是两个步骤:
3.2.1、将资源解析成Document对象(这个步骤这边就不展开了,有兴自究);
3.2.2、解析Document,提取注册Bean。
来到registerBeanDefinitions方法,这里创建了一个BeanDefinitionDocumentReader对象负责具体解析(是不是觉得又冒出了不认识的类,框架就是这样,遵循单一职责的原则,把一个集中的逻辑放到其他类中处理),它调用doRegisterBeanDefinitions(doc.getDocumentElement()),提取Document的root作为参数继续解析,先查找解析profile属性,将表示环境的属性注册到Environment;然后遍历root每个子节点,如果是默认标签,调用parseDefaultElement进行解析;如果是自定义标签,就调用delegate.parseCustomElement。所以3.2.2下面是这几个步骤:
3.2.2.1、创建BeanDefinitionDocumentReader委托解析对象;
3.2.2.2、解析profile属性到Environment;
3.2.2.3、遍历子节点,继续解析默认标签和自定义标签。
我们这边主要分析默认标签的解析,自定义的有兴自究。首先根据标签类型选择不同的处理方法,类型分别是import、alias、bean和beans。重点肯定是对bean标签的解析,进入processBeanDefinition方法,我们看到里面先委托BeanDefinitionParserDelegate解析出一个持有bean信息的BeanDefinitionHolder;如果BeanDefinitionHolder不为空且子节点下存在自定义标签,再解析它们;然后对解析完成后的BeanDefinitionHolder进行注册,注册过程很简单就是将BeanDefinitionHolder持有的beanName和BeanDefinition的键值对、beanName和每个alias别名的键值对保存在容器中;最后发出bean已注册完成的事件通知,所以这里分为4步:
3.2.2.3.1、委托BeanDefinitionParserDelegate解析返回BeanDefinitionHolder;
3.2.2.3.2、解析存在的自定义标签;
3.2.2.3.3、解析完成后注册;
3.2.2.3.4、发出响应事件。
到了这里终于开始具体的解析,过程其实就是先解析出beanName、alias别名,然后把其余各种标签,如class、scope、lazy-init等属性解析成用于属性承载的BeanDefinition对象的成员变量,最后将beanName、alias数组和BeanDefinition封装成BeanDefinitionHolder对象返回。具体各种属性的功能和规则这边就不展开了,有兴自究。
对于import、alias和beans标签,简述一下:alias的解析和bean中的alias解析差不多,也是将每一个别名与beanName以map形式保存;impot可以导入其他配置文件,解析过程就是找到那个文件然后递归进行解析;beans就是把多个bean标签包起来,然后遍历解析每一个bean标签。
总结
画一个流程图作为总结: