介绍: 本次数据爬取只进行一些简单数据的爬取,如商品标题、价格、图片链接以及详情页中的销量、评价和送的天猫积分,相信看过这个博客后的小伙伴,一定可以把功能更加完善。
一、淘宝登录
有关登录这部分的话,不做讲解,想要知道的小伙伴可以参考我的另一篇博客Python爬虫:Selenium和动作链实现淘宝模拟登录,分析的很清楚。
二、准备
1.创建Scrapy的tTaobao项目
scrapy startproject Taobao
cd Taobao
scrapy genspider taobao "taobao.com"
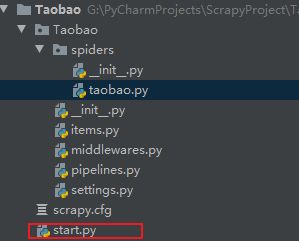
在这里插入图片描述
有个这个文件,整个scrapy项目可以直接右键start.py运行,不用到命令行输入命令启动。
start.py
from scrapy import cmdline
cmdline.execute("scrapy crawl taobao".split())
2.更改setting配置文件
在这里插入图片描述
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'

在这里插入图片描述

在这里插入图片描述
三、数据爬取、分析
分析以注释形式存在。
#数据爬取、分析
def parse(self, response):
#由于我的start_urls = ['https://s.taobao.com/search?q=java&s=0'],直接请求会被拦截需要登录,此时的response格式为 <200 xxx.com> ,而xxx.com就是淘宝登录的网址,把它提取出来就ok
response = str(response).split(" ")[1].replace(">","")
bro = self.login(response) #传入登陆网址进行模拟登录
# print(response.text)
num = 0
for i in range(2): #进行多页数据爬取
url = "https://s.taobao.com/search?q=java&s=" + str(num) #请求链接格式分析可参考上图1
num += 44
bro.get(url) #get方式进行请求
html = bro.page_source
soup = BeautifulSoup(html, 'lxml') #使用BeautifulSoup进行分析、爬取
data_list = soup.find_all(class_='item J_MouserOnverReq') #根据class拿到全部标签,参考图二
for data in data_list: #遍历
data_soup = BeautifulSoup(str(data), 'lxml')
# 图片链接
#参考图三,根据class找到图片拿到其中的data-src属性数据
#涉及到图片懒加载问题,data-src时真正存放图片地址的地方
img_url = "http:" + data_soup.find(class_='J_ItemPic img')['data-src']
# 图片价格,根据标签拿值,参考图四
# 拿到标签中的文本内容要在后面加上.string
price = data_soup.find('strong').string
# 图片标题
# 参考图五,根据class拿到img中的alt属性
title = data_soup.find(class_='J_ItemPic img')['alt']
# 详情页
#参考图六,根据class拿到data-href原因与拿data-src一样
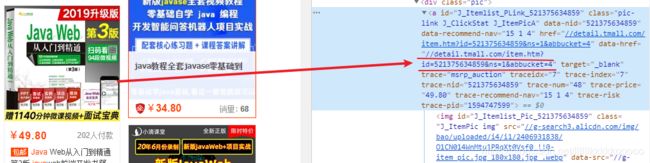
detail_url = "https:" + data_soup.find(class_="pic-link J_ClickStat J_ItemPicA")["data-href"]
bro.get(detail_url) #请求详情页
time.sleep(1)
html_second = bro.page_source
soup = BeautifulSoup(html_second, 'lxml')
#因为有的商品是有销量、评价数量、积分的,但有的商品缺一个两个的。
#由于find的特性,取不到值就会报异常,则我们使用try-except进行包裹,没有值时赋值为0
#参考图七
try:
#月销量
svolume = soup.find(class_="tm-ind-item tm-ind-sellCount").text.replace("月销量", "")
except:
svolume = 0
try:
#评价
evaluate = soup.find(class_="tm-ind-item tm-ind-reviewCount canClick tm-line3").text.replace("累计评价", "")
except:
evaluate = 0
try:
#赠送的积分
integral = soup.find(class_="tm-ind-item tm-ind-emPointCount").text.replace("送天猫积分", "")
except:
integral = 0
item = TaobaoItem(img_url=img_url, price=price, title=title, svolume=svolume, evaluate=evaluate,
integral=integral, detail_url=detail_url)
yield item
图一、

在这里插入图片描述
图二、
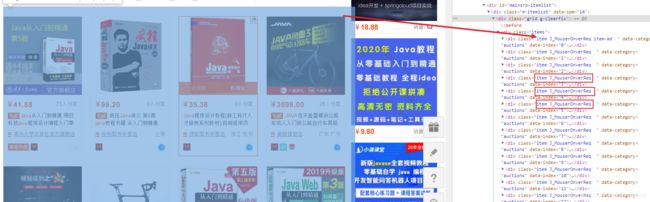
在这里插入图片描述
图三、

在这里插入图片描述
图四、
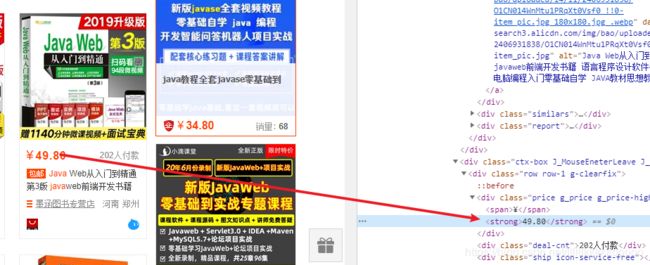
在这里插入图片描述
图五、
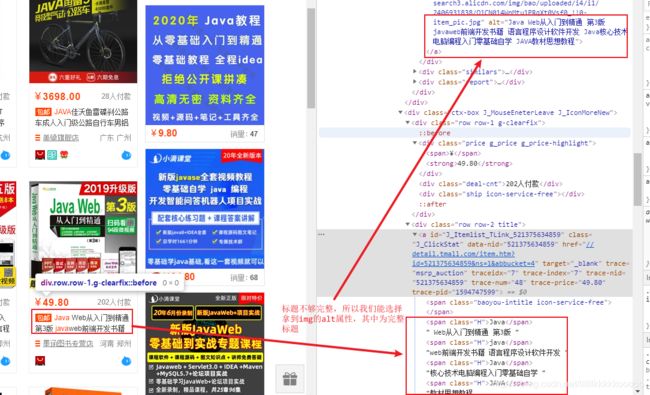
在这里插入图片描述
图六、
在这里插入图片描述
图七、

在这里插入图片描述
四、完整代码
taobao.py
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
import time
from PIL import Image
from selenium.webdriver import ActionChains
from bs4 import BeautifulSoup
from Taobao.items import TaobaoItem
class TaobaoSpider(scrapy.Spider):
name = 'taobao'
# allowed_domains = ['xxx.com']
start_urls = ['https://s.taobao.com/search?q=java&s=0']
#登录
def login(self,url):
bro = webdriver.Chrome()
bro.maximize_window()
time.sleep(1)
bro.get(url)
time.sleep(1)
bro.find_element_by_class_name("icon-qrcode").click()
time.sleep(3)
# bro.find_element_by_name("fm-login-id").send_keys("淘宝账号")
# time.sleep(1)
# bro.find_element_by_name("fm-login-password").send_keys("淘宝密码")
# time.sleep(1)
#
# # save_screenshot 就是将当前页面进行截图且保存
# bro.save_screenshot('taobao.png')
#
# code_img_ele = bro.find_element_by_xpath("//*[@id='nc_1__scale_text']/span")
# location = code_img_ele.location # 验证码图片左上角的坐标 x,y
# size = code_img_ele.size # 验证码的标签对应的长和宽
# # 左上角和右下角的坐标
# rangle = (
# int(location['x']), int(location['y']), int(location['x'] + size['width']),
# int(location['y'] + size['height'])
# )
#
# i = Image.open("./taobao.png")
# # crop裁剪
# frame = i.crop(rangle)
#
# # 动作链
# action = ActionChains(bro)
# # 长按且点击
# action.click_and_hold(code_img_ele)
#
# # move_by_offset(x,y) x水平方向,y竖直方向
# # perform()让动作链立即执行
# action.move_by_offset(270, 0).perform()
# time.sleep(0.5)
#
# # 释放动作链
# action.release()
# # 登录
# bro.find_element_by_xpath("//*[@id='login-form']/div[4]/button").click()
return bro
#数据爬取
def parse(self, response):
response = str(response).split(" ")[1].replace(">","")
bro = self.login(response)
# print(response.text)
num = 0
for i in range(2):
url = "https://s.taobao.com/search?q=java&s=" + str(num)
num += 44
bro.get(url)
html = bro.page_source
soup = BeautifulSoup(html, 'lxml')
data_list = soup.find_all(class_='item J_MouserOnverReq')
for data in data_list:
data_soup = BeautifulSoup(str(data), 'lxml')
# 图片链接
img_url = "http:" + data_soup.find(class_='J_ItemPic img')['data-src']
# 图片价格
price = data_soup.find('strong').string
# 图片标题
title = data_soup.find(class_='J_ItemPic img')['alt']
# 详情页
detail_url = "https:" + data_soup.find(class_="pic-link J_ClickStat J_ItemPicA")["data-href"]
bro.get(detail_url)
time.sleep(1)
html_second = bro.page_source
soup = BeautifulSoup(html_second, 'lxml')
try:
svolume = soup.find(class_="tm-ind-item tm-ind-sellCount").text.replace("月销量", "")
except:
svolume = 0
try:
evaluate = soup.find(class_="tm-ind-item tm-ind-reviewCount canClick tm-line3").text.replace("累计评价", "")
except:
evaluate = 0
try:
integral = soup.find(class_="tm-ind-item tm-ind-emPointCount").text.replace("送天猫积分", "")
except:
integral = 0
#处理获取的的数据,做数据清洗
item = TaobaoItem(img_url=img_url, price=price, title=title, svolume=svolume, evaluate=evaluate,
integral=integral, detail_url=detail_url)
yield item
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class TaobaoItem(scrapy.Item):
img_url = scrapy.Field()
price = scrapy.Field()
title = scrapy.Field()
svolume = scrapy.Field()
evaluate = scrapy.Field()
integral = scrapy.Field()
detail_url = scrapy.Field()
pipelines.py
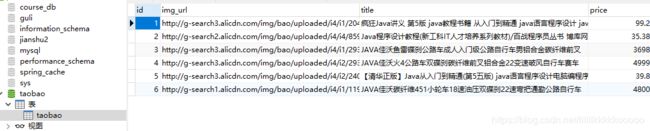
保存数据到mysql
在这里插入图片描述
数据库建表语句
CREATE TABLE `taobao` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`img_url` varchar(255) DEFAULT NULL,
`title` varchar(255) DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
`svolume` varchar(255) DEFAULT NULL,
`evaluate` varchar(255) DEFAULT NULL,
`integral` varchar(255) DEFAULT NULL,
`detail_url` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
class TaobaoPipeline:
def __init__(self):
dbparams = {
'host': '127.0.0.1',
'port': 3306,
'user': '账号',
'password': '密码',
'database': '数据库名',
'charset': 'utf8'
}
self.conn = pymysql.connect(**dbparams)
self.cursor = self.conn.cursor()
self._sql = None
def process_item(self, item, spider):
self.cursor.execute(self.sql,(item['img_url'],item['title'],item['price'],
item['svolume'],item['evaluate'],item['integral'],item['detail_url']))
self.conn.commit()
return item
@property
def sql(self):
if not self._sql:
self._sql = """
insert into taobao(id,img_url,title,price,svolume,evaluate,integral,detail_url)
values(null ,%s,%s,%s,%s,%s,%s,%s)
"""
return self._sql
return self._sql
此次博客到此结束,觉得不错的小伙伴可以收藏点赞哦。