在文章开始之前,先解释下为什么从 “Yes&NoSQL”开始说起。不同于传统的关系型数据库,NoSQL 是 “not only SQL” 的缩写,特指不以 SQL 为中心的任何非关系型数据库。数易轩致力于图数据库标注技术。

比较常见的错误是,把 “NoSQL” 理解为 “NO SQL”,所以使用 “Yes&NoSQL” 代表关系型及非关系型数据库,关注所有数据库知识。
NoSQL 包含图数据库 (Graph DBMS),时间序列数据库(Time Series DBMS),宽列存储(Wide Column Stores,也称基于 Big Table 的存储)等等。典型的 NoSQL 数据库比如 Redis,MongoDB,HBase等等。

我们关注图数据库。图数据库,不是存储图片的数据库,而是存储节点与他们之间关系的数据库。根据DB-Engines数据显示,图数据库是近五年来成长最快的数据库分类。由于很早开始被Twitter,Facebook和Google在内的公司采用,图已经演变成当今各行各业所使用的主流技术。
什么是图
图广泛存在于现实世界之中,从社交网络到金融关系,都会涉及大量的高度关联数据。这些数据构成了庞大的图,图数据库就是呈现和查询这些关联的做好的方式。
图,形式上是节点 (vertex,或者 node) 和边 (edge) 的集合。在一张图中,一个节点代表一个实体,例如某个人,某个城市,某家公司等等。边,就是关联这些节点的关系 (relation) ,例如“王健林”是“王思聪”的父亲,“我”生活在“上海”。
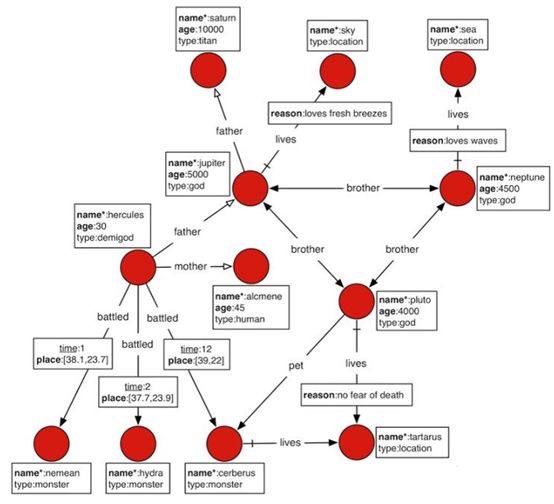
如图,JanusGraph官网教程中给了一个希腊神话的人物及罗马神殿关系图,是一个典型的带标签的属性图(Labeled-Property Graph)。
我们可以从图中容易发现:
· 赫拉克勒斯(Hercules)的父亲是丘比特(Jupiter,对应希腊神话中的宙斯),母亲是阿尔克墨涅(Alcmene);
· 阿尔克墨涅(Alcmene)是一个凡人(human),所以赫拉克勒斯(Hercules)是一个半神(demigod);
· 尼普顿(Neptune,海神)住在海洋中,因为喜欢海浪的声音。
· ……
然后我们就很容易理解以下概念:
· 节点拥有一个(也可以是多个)标签(label),例如神(god)、半神(demigod)、凡人(human)等等;
· 节点可以拥有很多属性(property),例如姓名、年龄等等,以键值对(key-value pair)的形式表示,并且属性值也可以是键值对;
· 边也有标签,标签可以是“住在”、“是他的父亲”等等;
· 边有方向,不同图数据库对方向的约束可能不一样,例如JanusGraph只接受单向边,如果需要表达双向关系,则需要再添加一条反向的边;
· 边也有属性,例如某人“住在”某地的关系上存在“原因”的属性;
当然,实际场景中的图要比上图复杂的多的多,图数据库就是处理这种数据的工具。
为什么需要图数据库
其实这个问题可以这么问:为什么传统关系型数据库不能很好处理图?
有人曾做过一个测试:在一个包含100w人,每人约有50个朋友的社交网络中找到最大深度为5的朋友的朋友。下图为图数据库Neo4J和关系型数据库在寻找扩展朋友时的性能对比。

从图中可以发现,当我们需要寻找朋友的朋友(深度为 2)时,关系型数据库(RDBMS)与 Neo4j 性能差距并不明显;深度为 4 时,关系型数据库需要近半个小时才能返回结果;当深度到达 5 时,关系型数据库已无法返回结果。从中我们可以很容易看出,对于图数据库来说,数据量越大,查询需要涉及的关系越复杂,图数据库的性能优势越大。
为什么关系型数据库不行
我们来复盘一下上面的实验。对于关系型数据库来说,朋友的朋友意味着两张表的 join,会很容易产生笛卡尔积的中间数据,数据量随着深度呈幂增长。这就是为什么性能随着查询深度,下降如此之快。
再举一个例子,假设刚才我们在寻找“ A 的朋友是谁”,我们的数据表针对此类查询进行了特殊表设计,查询一般会比较快。但是,如果我们需要查询“谁的朋友是 A ”,我们可能需要遍历整个关系表,查询效率就会瞬间降低。
同样的,在商品数据库中,我们查询某个客户买了哪些商品通常效率比较高,但是我们要查询”那些客户买了这个商品”甚至是“有哪些买了这个商品的客户也买了那个商品”的这种多层关系的时候,关系型数据库通常就显得力不从心了。实际上,关系型数据库在处理反向查询以及多层次关系查询的时候通常开销较大。
为什么图数据库可以
原理上的解释,看完下个章节,可能你就会有答案。这里,先介绍下图数据库的特点:
1. 使用图的方式表达现实世界很多事物更为直接、易于理解,自然也易于建模。你可以喜欢一部电影,也可以和好朋友建立密切的关系,也可以创作一些文章,均可以用节点和边的方式表达;
2. 图数据库可以高效插入大量数据。从应用的角度来说,知识图谱、社交关系、风控关系等,数据量在亿级别。图数据库在十亿级别的数据量时,能保持较好的性能;
3. 图数据库可以高效进行关联查询、数据插入,并且提供了针对图查询的语言。我们已在上一小结说明,关系型数据库针对关联查询效率下降严重。图数据库通过针对性的优化,在数据建模,存储形式上支持高效的关联查询。图模型提供了固有的索引数据结构,因此它不需要为给定条件的查询加载或接触不相关的数据。目前比较主流的图查询语言是 Gremlin 和 Cypher,都可以用模式匹配的方式,去寻找图上的路径。例如,使用 JanusGraph 寻找我的 2 度朋友关系:
g.V().has('name','gupeng').out('friend').out('friend')
使用 Cypher 寻找我和我的好朋友的共同好友:
MATCH (a:Person {name:'gupeng'}) -[:KNOWS]-> (b) -[:KNOWS]-> (c)
(a) -[:KNOWS]-> (c)
RETURN b,c
并且,在查询节点之间的关系通常可以做到常数级别。
4. 图数据库提供专业的分析算法或者工具。分析算法例如 PageRank、ShortestPath 等等。大部分图数据库也会提供可视化的图显示,使得查询和分析十分直观。
图数据库应用
图数据库拥有广泛的适用场景,因为实体和关系的建模方式能很好地抽象自然和社会的很多事物。下面举例最常使用的场景。
1. 社交网络在社交网络中使用图数据库可以方便得识别人/群组和他们交流的事物之间的直接或间接的联系,使用户能够高效地对其他人或事物进行打分、评论、发现彼此存在的关系和共同关系的事情。可以更加直观得了解社交网络中人与人之间如何互动、如何关联、如何以群组的形式来做事情或选择。
2. 实时推荐推荐算法通过用户的购买、生产、消费、打分或评论等行为,建立人和商品之间的联系。推荐算法可以识别出某些资源会吸引特定个人或群体,或者某些个人或群体可能对特定资源感兴趣。用图数据库存储和查询这些数据使得应用程序可以为最终用户呈现实时结果,反映数据最新的变化,进行实时的商品推荐。
3. 知识图谱最早起源于Google Knowledge Graph。知识图谱本质上是一种语义网络 。其结点代表实体(entity)或者概念(concept),边代表实体/概念之间的各种语义关系。所以知识图谱可以很好地用图来表达。建立知识图谱,可以为后续应用提供基础,例如问答系统,商品推荐,信息检索等等。
4. 反欺诈和风控例如,近年来的消费金融行业快速发展,相比于传统商业银行,拥有自己独特的优势:填写字段少、在线操作、审核速度快、放贷及时。这类申请人群通常因缺乏征信信息而给消费金融企业带来了巨大的信用和欺诈风险。而图分析结合传统机器学习算法,可以在有限信用记录甚至是“零”信用记录下进行更准确的风险控制和欺诈识别。
此外,图数据库产品还广泛用在地理空间和物流应用,路由计算,电商和社交类产品防机器人作弊,网络和数据中心管理,授权和访问控制等领域。
数据模型 & 图计算引擎
我们从使用图数据库的角度入手,一个完善的图数据系统至少应该包括图存储和查询,图处理和计算,数据导入导出,可能还有可视化,对于商业化产品还需要高可用及容灾备份。下面对主要部分进行介绍。
图存储 & 数据模型
图数据如何存储图,对存储效率和查询效率都至关重要。我们称数据库表达数据的方式为图模型(Data
Model),是一种对图的建模方式。
目前使用的图模型有3种,分别是属性图(Property
Graph)、资源描述框架(RDF,Resource
Description Framework)和超图(HyperGraph)。
1. 属性图(Property Graph):目前主流图数据库选择的数据模型,更确切的说是带标签的属性图(Labeled-Property Graph)。除了图所共有节点和边的概念,我们已经在上面介绍了属性和标签的概念。我们可以用一个属性图来表达属性图各元素的关系:

1. 资源描述框架(RDF,Resource Description Framework):在一个 RDF 中,增加的信息都以单独的节点表示。RDF由节点和边组成,节点表示实体/资源或者属性,边则表示了实体和实体之间的关系以及实体和属性的关系。相较于属性图,对属性的处理方式不一样。例如,如果要为某个”人“节点增加”name“属性,对于属性图来说,在这个”人“的”name“属性上设置名字,而在 RDF 中,直接通过一条”hasName“的边指向了设置名字。RDF 形式上表示为SPO(Subject
- Predicte - Object)三元组,有时候也称为一条语句(Statement)。RDF 比较多地被使用在知识图谱中,那我们也通常称一条语句为一条知识。许多图数据库是基于RDF实现的,包括:AllegroGraph,Virtuoso,Blazegraph和Stardog。
2. 超图(HyperGraph):不同于属性图和 RDF,超图的边可以连接任意数量(不能为 0)的节点,超图的边又称为超边(hyperedges)。如图是一个典型的超图:

主流的开源图数据库 Neo4j 和JanusGraph 都采用属性图的数据模型。不同的是,Neo4j 使用原生图存储,JanusGraph 使用非原生图存储,将图结构序列化存储到基于 BigTable
Model 的数据库(例如 Cassandra,HBase)中。原生图存储为存储和使用图做了更多的优化,遍历查询性能更高,但非遍历类的查询则不占优势,且为了全局搜索还会占用大量内存。
图查询和图计算 / OLTP 和OLAP
图查询和图计算都是对图的遍历。图数据库主要提供两种与遍历图的方式:OLTP (Online Transaction Processing)和 OLAP (Online Analytical Processing)。
· OLTP:实时返回,涉及少量数据,随机的数据访问,串行运行,用于查询,偏向深度优先的计算引擎,不需要太大的内存;
· OLAP:长时间运行,涉及几乎整个图,串行地访问数据,并行运行,批量处理,偏向广度优先的计算引擎,需要更大的内存。
图查询指支持对图数据模型的增、删、改、查(CRUD)方法,更关注 OLTP。有的图数据库也继承了少量的图计算能力,但真正的大型系统还是需要单独的计算框架。
图计算引擎技术,偏重于全局查询,通常都对与批处理大规模数据做过优化。只有一部分图计算引擎有自己的存储层,其他的都只关注与如果处理外部传入的数据,然后返回结果到其他地方保存。图计算引擎,或者说图的并行计算框架,包括 Google 的 Pregel,基于Spark 的 GraphX,Apache 下的 Giraph / HAMA 以及 GraphLab,其中Giraph 是 Pregel 的开源实现。
图数据库产品
Neo4j
Neo4j 是老牌的图数据代表(2007)。其功能强大,性能也不错,单节点的服务器可承载上亿级的节点和关系,单节点性能不够时也可进行分布式集群部署。
Neo4j有自己的后端存储,不必如同JanusGraph 等一样依赖另外的数据库存储。Neo4j 在每个节点中存储了每个边的指针,因而遍历时效率相当高。Neo4j分为社区版和企业版,社区版功能受限,另外其提供可视化的客户端感觉很不错。
据neo4j的中国合作方的社区中描述,主要区别如下:
1、容量:社区版最多支持 320 亿个节点、320 亿个关系和 640 亿个属性,而企业版没有这个限制;
2、并发:社区版只能部署成单实例,不能做集群。而企业版可以部署成高可用集群或因果集群,从而可以解决高并发量的问题;
3、容灾:由于企业版支持集群,部分实例出故障不会影响整个系统正常运行;
4、热备:社区版只支持冷备份,即需要停止服务后才能进行备份,而企业版支持热备,第一次是全量备份,后续是增量备份;
5、性能:社区版最多用到 4 个内核,而企业能用到全部内核,且对性能做了精心的优化;
6、支持:企业版客户能得到 5X10电话支持(Neo4j 美国电话、邮件,微云数聚电话、微信、邮件);
考虑到这些限制,要选开源免费大容量分布式的图数据库的可以跳过了,研究图论及小型应用或不差钱的项目则选其的支持服务则另当别论。另外 Neo4j 的协议为 GPLv3,这个也不适合选用。
JanusGraph
JanusGraph(2017) 基于 Titan(2012)发展而来,包含其所有功能,采用 Tikerpop 的 Gremlin 图查询语言,有单独的后端存储,支持 Cassandra / HBase 等做存储,支持 Solr /
ElasticSearch / Lucence 等做图索引。支持Spark GraphX / Giraph等图分析计算引擎及Hadoop分布式计算框架。原生支持集成了 Tinkerpop 系列组件:Gremlin 查询语言,Gremlin-Server 及 Gremlin applications。
采用很友好的 Apache2.0 协议,支持对接可视化组件如 Cytoscape,Gephi plugin for Apache TinkerPop,Graphexp,KeyLines by Cambridge Intelligence,Linkurious 等。
结语
总体来说,图数据和图分析还处在方兴未艾的阶段,很多现有的产品都相当的“实验室”,性能提升空间十分巨大。图数据库的价值,还需要更多的开发工程师、数据分析师来实现。
技术世界就是这样,封装封装再封装,重构重构造新轮。
