关注公众号《云爬虫技术研究笔记》获取更多“了不起”的干货
Python3.8已经发布了将近一个月了,距离Python3.0第一个版本发布也将超过10年了。相信很多人还是依旧在使用Python2.7版本,想要迁移到最新版本却不知道怎么能够快速掌握其中最Amazing的方法。下面这篇文章,我会给大家推荐3.0版本依赖最最新潮的函数和语法,让你们能够在Review代码时候“脱颖而出”!
前言
首先我们先来讲几个时间点:
-
Python2.7正式停止维护时间 2020年1月1日,距今还有1个多月
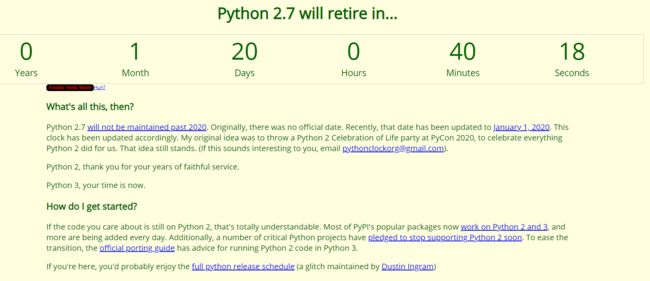 image
image -
Python3.8正式开始发布时间 2019年10月14日,距今将近1个多月
 image
image
从这两个数字我们可以看出,Python3这个大版本已经发展很长的时间了,而距离Python2.7的结束也越来越近了。在距离Python2.7停止维护的一年内,很多优秀开源项目都已经停止了对 2.7 的支持,例如到今年 1 月份,NumPy 将停止支持 Python 2;到今年年末,Ipython、Cython 和 Pandas 等等都将陆续停止支持 Python 2。
所以,为了响应号召,顺应趋势。我们慢慢的向Python3.X去迁移,那我们如何能够快速的掌握Python3.X版本的精髓呢?下面我们从几个有趣的新特性入手,这些特性或方法都是 Python 3 各个版本中新加的,它们相比传统的 Python 方法,更容易解决实践中的一些问题。
所有的示例都是在 Python 3.7 的环境下编写的,每个特性示例都给出了其正常工作所需的最低的 Python 版本。
潮流特性
- 格式化字符串 f-string(最低 Python 版本为 3.6)
“如何格式化字符串”这个话题我想是每个开发者在接触一门新语言的时候都会去学习的语法,而在Python中格式化语法的方式大家通常都会偏向于【Format】或者 【%S】这两种方法,操作如下:
print("My name is %s" % ('phithon', ))
print("My name is %(name)s" % {'name':'phithon'})
print("My name is {}".format("bob"))
print("My name is {name}".format(name="bob"))
而到了Python3.6版本,推出了新的格式化字符串的灵活方法【f-string】,使用【f-string】编写的与上面功能相同的代码是这样的
name="bob"
print(f"My name is {name}")
我们对比这几种格式化字符串的方法,可以发现相比于常见的字符串格式符【%S】 或 【Format】 方法,【f-string】 直接在占位符中插入变量显得更加方便,也更好理解,关于格式化速度方面可以参考这个博文看看详细的解释。
- 路径管理库 Pathlib(最低 Python 版本为 3.4)
从上个特性可以看出【f-string】 确实非常强大和美观,而在文件路径方面,Python遵循了他们的开发理念:万物皆是对象,所以他们把路径也单拎出来搞了一个路径对象库,也就是一个处理文件路径的抽象库【pathlib】。如果你不知道为什么应该使用 【pathlib】,请参阅下面这篇 Trey Hunner 编写的炒鸡棒的博文以及它的后续版本,下面我们对比同一案例的新旧两个版本Python的实现:
from glob import glob
file_contents = []
for filename in glob('**/*.py', recursive=True):
with open(filename) as python_file:
file_contents.append(python_file.read())
from pathlib import Path
file_contents = [
path.read_text()
for path in Path.cwd().rglob('*.py')
]s')
如上所示,您可以read_text对Path对象使用方法和列表理解,将文件内容全部读入一个新列表中,相比于使用旧版本Python的实现,在语法和美观上无疑是更加出色!
- 类型提示 Type hinting(最低 Python 版本为 3.5)
编程语言有很多类型,静态编译型语言和动态解释型语言的对比是软件工程中一个热门的话题,几乎每个人对此有自己的看法。在静态语言中类型标注无疑是让人又爱又恨,爱的是编译速度加快,团队合作中准确了解函数方法的入参类型,恨的是Coding时极其繁琐的标注。不过,标注这种极其符合团队文化的操作还是在Python3中被引入,并且很快得到了人们的喜爱。
def print_yes_or_no(codition: str) -> bool:
pass
- 枚举(最低 Python 版本为 3.4)
大家在写Java或者C语言的时候都会接触到枚举这个特性,枚举也是帮我们节省了很多时间,也让我们的代码更加美观。旧版本Python中大家想要实现枚举的话实现方法五花八门,“八仙过海,各显神通”,充分发挥了Python的动态语言特性。我们下面举些例子:
#利用type自建类的骚操作
def enum(**enums):
return type('Enum', (), enums)
Numbers = enum(ONE=1, TWO=2, THREE='three')
# Numbers.ONE == 1, Numbers.TWO == 2 and Numbers.THREE == 'three'
#利用type自建类的骚操作升级版
def enum(*sequential, **named):
enums = dict(zip(sequential, range(len(sequential))), **named)
return type('Enum', (), enums)
Numbers = enum('ZERO', 'ONE', 'TWO')
# Numbers.ZERO == 0 and Numbers.ONE == 1
#有带值到名称映射的
def enum(*sequential, **named):
enums = dict(zip(sequential, range(len(sequential))), **named)
reverse = dict((value, key) for key, value in enums.iteritems())
enums['reverse_mapping'] = reverse
return type('Enum', (), enums)
# Numbers.reverse_mapping['three'] == 'THREE'
# 更有甚者,利用namedtuple实现的
from collections import namedtuple
def enum(*keys):
return namedtuple('Enum', keys)(*keys)
MyEnum = enum('FOO', 'BAR', 'BAZ')
# 带字符数字映射的,像C/C++
def enum(*keys):
return namedtuple('Enum', keys)(*range(len(keys)))
# 带字典映射的,可以映射出各种类型,不局限于数字
def enum(**kwargs):
return namedtuple('Enum', kwargs.keys())(*kwargs.values())
看过了以上这么多骚操作,现在Python3给你净化一下眼睛,Python3.4新推出通过「Enum」类编写枚举的简单方法。
from enum import Enum, auto
class Monster(Enum):
ZOMBIE = auto()
WARRIOR = auto()
BEAR = auto()
print(Monster.ZOMBIE)
for i in Monster:
print(i)
#Monster.ZOMBIE
#Monster.ZOMBIE
#Monster.WARRIOR
#Monster.BEAR
以上我们可以看出枚举是符号名称(成员)的集合,这些符号名称与唯一的常量值绑定在一起。在枚举中,可以通过标识对成员进行比较操作,枚举本身也可以被遍历。
- 原生 LRU 缓存(最低 Python 版本为 3.2)
缓存是大家在开发中都会用到的一个特性,如果我们准确的使用好它,它会节省我们很多时间和成本。相信很多人初学Python装饰器的时候都会去实现一个缓存的装饰器来节省斐波那契函数的计算时间。而Python 3 之后将 LRU(最近最少使用算法)缓存作为一个名为「lru_cache」的装饰器,使得对缓存的使用非常简单。
下面是一个简单的斐波那契函数,我们知道使用缓存将有助于该函数的计算,因为它会通过递归多次执行相同的工作。
import time
def fib(number: int) -> int:
if number == 0:
return 0
if number == 1:
return 1
return fib(number-1) + fib(number-2)
start = time.time()
fib(40)
print(f'Duration: {time.time() - start}s')
# Duration: 30.684099674224854s
我们看到,我们没用缓存装饰器的时候计算的时间是30秒左右,现在,我们可以使用「lru_cache」来优化它(这种优化技术被称为「memoization」)。通过这种优化,我们将执行时间从几秒降低到了几纳秒。
from functools import lru_cache
@lru_cache(maxsize=512)
def fib_memoization(number: int) -> int:
if number == 0:
return 0
if number == 1:
return 1
return fib_memoization(number-1) + fib_memoization(number-2)
start = time.time()
fib_memoization(40)
print(f'Duration: {time.time() - start}s')
# Duration: 6.866455078125e-05s
可以看出,我们在开发计算函数的时候使用缓存装饰器是多么提高成本的一种手段,另外,在新版本Python3.8之后,lru_cache现在可直接作为装饰器而不是作为返回装饰器的函数。 因此这两种写法现在都被支持:
@lru_cache
def f(x):
...
@lru_cache(maxsize=256)
def f(x):
...
- 扩展的可迭代对象解包(最低 Python 版本为 3.0)
Python解包相信在我们初学Python的时候都有所了解,如果我们很多地掌握这个特性,相信是一件非常酷的事情。那什么是扩展的解包呢?我们可以从pep3132中了解更多,举个例子:
# Python 3.4 中 print 函数 不允许多个 * 操作
>>> print(*[1,2,3], *[3,4])
File "", line 1
print(*[1,2,3], *[3,4])
^
SyntaxError: invalid syntax
>>>
# 再来看看 python3.5以上版本
# 可以使用任意多个解包操作
>>> print(*[1], *[2], 3)
1 2 3
>>> *range(4), 4
(0, 1, 2, 3, 4)
>>> [*range(4), 4]
[0, 1, 2, 3, 4]
>>> {*range(4), 4}
{0, 1, 2, 3, 4}
>>> {'x': 1, **{'y': 2}}
{'x': 1, 'y': 2}
我们可以看到,解包这个操作也算的上Python中极其潮流的玩法了,耍的一手好解包,真的会秀翻全场啊!
- Data class 装饰器(最低 Python 版本为 3.7)
Python 3.7 引入了【data class】,新特性大大简化了定义类对象的代码量,代码简洁明晰。通过使用@dataclass装饰器来修饰类的设计,可以用来减少对样板代码的使用,因为装饰器会自动生成诸如「__init__()」和「__repr()__」这样的特殊方法。在官方的文档中,它们被描述为「带有缺省值的可变命名元组」。
from dataclasses import dataclass
@dataclass
class DataClassCard:
rank: str
suit: str
#生成实例
queen_of_hearts = DataClassCard('Q', 'Hearts')
print(queen_of_hearts.rank)
print(queen_of_hearts)
print(queen_of_hearts == DataClassCard('Q', 'Hearts'))
#Q
#DataClassCard(rank='Q', suit='Hearts')
#True
而常规的类,按照Python 3.7之前的语法类似于这样
class RegularCard
def __init__(self, rank, suit):
self.rank = rank
self.suit = suit
queen_of_hearts = RegularCard('Q', 'Hearts')
print(queen_of_hearts.rank)
print(queen_of_hearts)
print(queen_of_hearts == RegularCard('Q', 'Hearts'))
#'Q'
#<__main__.RegularCard object at 0x7fb6eee35d30>
#False
虽然这种写法并没有使用更多的代码量,但是我们很容易看到为了初始化,仅仅只是为了初始化一个对象,rank和suit已经重复了三次。此外,如果你试图使用这个RegularCard类,你会注意到对象的表示不是很具描述性,并且已有的类与新声明的类是无法比较是否相同的。因为每次声明都会使用一个新的内存地址,而“==”不止比较类存储的信息,还比较内存地址是否相同。
dataclass还在底层给我们做了更多的有用的封装。默认情况下dataclass实现了__repr__方法,可以很好的提供字符串表示;也是了__eq__方法,可以做基本的对象比较。而如果RegularCard想实现上面的功能需要写大量的声明,代码量多的吓人。
class RegularCard(object):
def __init__(self, rank, suit):
self.rank = rank
self.suit = suit
def __repr__(self):
#可以将类的信息打印出来
return (f'{self.__class__.__name__}'
f'(rank={self.rank!r}, suit={self.suit!r})')
#大家可以试着将“!r”去掉或者将其中的r改变为s或a,看看输出结果会有什么变化
#conversion character: expected 's', 'r', or 'a'
def __eq__(self, other):
#可以比较类是否相同(不考虑内存地址)
if other.__class__ is not self.__class__:
return NotImplemented
return (self.rank, self.suit) == (other.rank, other.suit)
- 隐式命名空间包(最低 Python 版本为 3.3)
一种组织 Python 代码文件的方式是将它们封装在程序包中(包含一个「init.py」的文件夹)。下面是官方文档提供的示例。
sound/ Top-level package
__init__.py Initialize the sound package
formats/ Subpackage for file format conversions
__init__.py
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py .
..
effects/ Subpackage for sound effects
__init__.py
echo.py
surround.py
reverse.py
...
filters/ Subpackage for filters
__init__.py
equalizer.py
vocoder.py
karaoke.py
...
在 Python 2 中,上面每个文件夹都必须包含将文件夹转化为 Python 程序包的「init.py」文件。在 Python 3 中,随着隐式命名空间包的引入,这些文件不再是必须的了。
sound/ Top-level package
__init__.py Initialize the sound package
formats/ Subpackage for file format conversions
wavread.py
wavwrite.py
aiffread.py
aiffwrite.py
auread.py
auwrite.py
...
effects/ Subpackage for sound effects
echo.py
surround.py
reverse.py
...
filters/ Subpackage for filters
equalizer.py
vocoder.py
karaoke.py
...
正如有些人说的那样,这项工作并没有像这篇文章说的那么简单,官方文档「PEP 420 Specification」指出,常规的程序包仍然需要「init.py」,把它从一个文件夹中删除会将该文件夹变成一个本地命名空间包,这会带来一些额外的限制。本地命名空间包的官方文档给出了一个很好的示例,并且明确指出了所有的限制。
总结
上面给出的几个很潮流的特性可能并不是很全,更多的还需要大家去探索符合自己和团队的玩法,这篇文章只是向大家展示一些比较好玩的Python新功能,掌握它可以帮助你写出更加Pythonic的代码。
号主介绍

前两年在二线大厂工作,目前在创业公司搬砖
接触方向是爬虫和云原生架构方面
有丰富的反爬攻克经验以及云原生二次开发经验
其他诸如数据分析、黑客增长也有所涉猎
做过百余人的商业分享以及多次开办培训课程
目前也是CSDN博客专家和华为云享专家

震惊 | 只需3分钟!极速部署个人Docker云平台
深入理解Python的TLS机制和Threading.local()
我为什么不建议你使用Python3.7.3?
下一代容器架构已出,Docker何去何处?看看这里的6问6答!!
公众号内回复“私藏资料”即可领取爬虫高级逆向教学视频以及多平台的中文数据集
