这是第三篇关于前馈神经网络的笔记了,旨在查漏补缺。
第一篇是看西瓜书时记录的https://www.jianshu.com/p/7bbdbe55ffbd,比较简洁。
第二篇是看花书时记录的https://www.jianshu.com/p/d275d9039e14,内容较全。
神经网络是一种大规模的并行分布式处理器,天然具有存储并使用经验知识的能力。它从两个方面上模拟大脑:(1)网络获取的知识是通过学习来获取的;(2)内部神经元的连接强度,即突触权重,用于储存获取的知识。— Haykin [1994]
神经网络是由神经元构成的,典型的神经元结构如下:
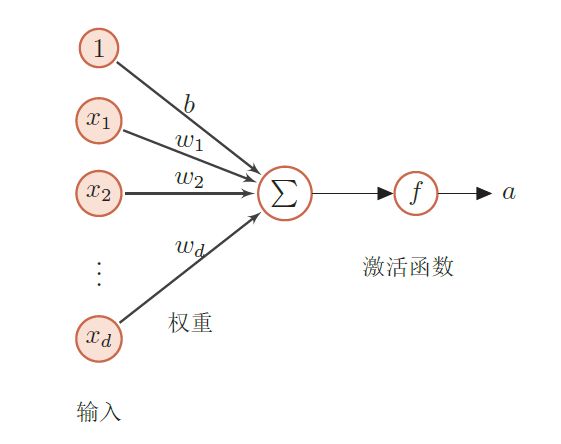
不难看出,这个之前提到的线性模型几乎一摸一样,结点计算的是判别函数,结点计算的是决策函数(这里称为激活函数)。
从这个角度来说,神经网络就是由一系列的线性模型组合而成的。
而神经网络之所以具有强大的表示能力,关键在于非线性的激活函数。
1、激活函数
激活函数在神经元中非常重要。为了增强网络的表示能力和学习能力,激活函数需要具备以下几点性质:
- 连续并可导(允许少数点上不可导)的非线性函数。可导的激活函数可以直接利用数值优化的方法来学习网络参数。
- 激活函数及其导函数要尽可能的简单,有利于提高网络计算效率。
- 激活函数的导函数的值域要在一个合适的区间内,不能太大也不能太小,否则会影响训练的效率和稳定性。
1.1、Sigmoid激活函数
Sigmoid型函数是指一类S型曲线函数,为两端饱和函数(对于函数,若时,其导数,则称其为左饱和。若时,其导数,则称其为右饱和。当同时满足左、右饱和时,就称为两端饱和)。
常用的Sigmoid型函数有Logistic函数和Tanh函数。
Logistic函数定义为:
Tanh 函数定义为:
两者图像如下:
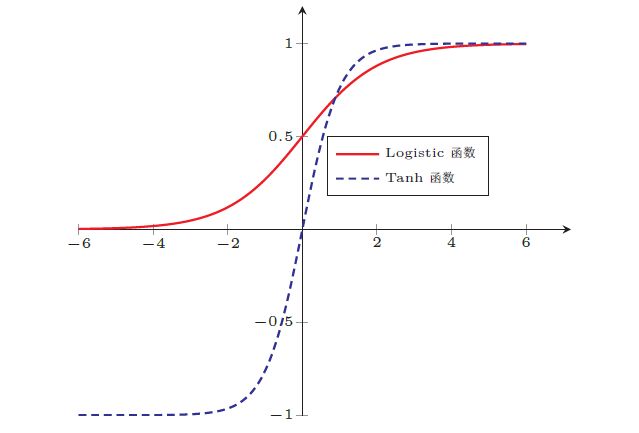
可以看到,Tanh函数的输出是零中心化的(Zero-Centered),而Logistic函数的输出恒大于0。非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(Bias Shift),并进一步使得梯度下降的收敛速度变慢。
1.2、修正线性单元
修正线性单元(Rectified Linear Unit,ReLU)也叫rectifier函数,是目前深层神经网络中经常使用的激活函数。ReLU实际上是一个斜坡(ramp)函数,定义为:
优点:
- 采用ReLU 的神经元只需要进行加、乘和比较的操作,计算上更加高效。
- ReLU 函数被认为有生物上的解释性,比如单侧抑制(把所有的负值都变为0,而正值不变)、宽兴奋边界(即兴奋程度也可以非常高)
- 有了单侧抑制,才使得神经网络中的神经元具有了稀疏激活性。实现稀疏后的模型能够更好地挖掘相关特征,拟合训练数据。
- 在优化方面,相比Sigmoid型函数的两端饱和,ReLU函数为左饱和,且在时导数为,一定程度上缓解了神经网络的梯度消失问题,加速梯度下降的收敛速度。
缺点:
- ReLU函数的输出是非零中心化的,给后一层的神经网络引入偏置偏移,会影响梯度下降的效率。
- ReLU神经元在训练时比较容易“死亡”。在训练ReLU 神经元指采用ReLU时,如果参数在一次不恰当的更新后,第一个隐藏层中的某个ReLU神经元在 作为激活函数的神经元。所有的训练数据上都不能被激活,那么这个神经元自身参数的梯度永远都会是0,在以后的训练过程中永远不能被激活。
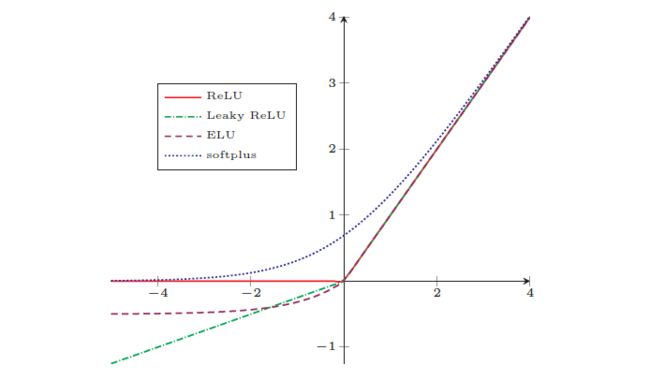
在实际使用中,为了避免上述情况,有几种ReLU的变种也会被广泛使用:
带泄露的ReLU(一定程度上解决神经元死亡问题)的定义为:
对于第个神经元,带参数的ReLU(一定程度上解决神经元死亡问题)的定义为:
指数线性单元(零中心化)的定义为:
Softplus函数(ReLU的平滑版本)的定义为:
1.3、Maxout单元
Maxout单元也是一种分段线性函数。Sigmoid型函数、ReLU等激活函数的输入是神经元的净输入z,是一个标量。而maxout单元的输入是上一层神经元的全部原始输入,是一个向量。
每个maxout单元有个权重向量和偏置。对于输入可以得到个净输入:
Maxout单元的非线性函数定义为:
Maxout激活函数可以看作任意凸函数的分段线性近似,且在有限的点上是不可微的。
下图直观展示了普通激活函数和Maxout激活函数的差别:
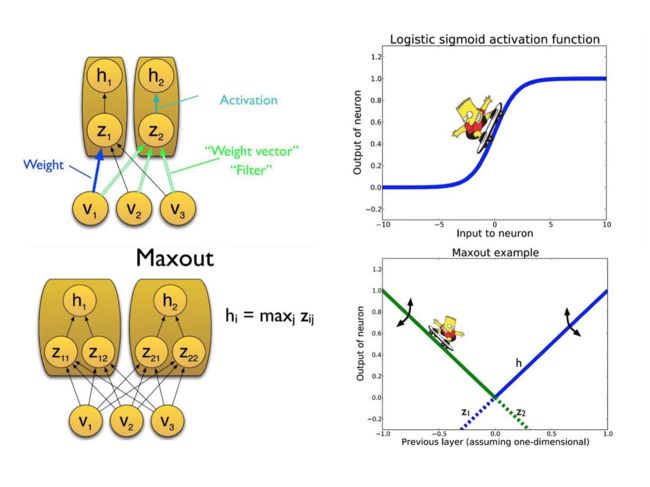
可以看到,对SIgmoid形式的激活函数来说,两端饱和会产生梯度消失问题,而Maxout激活函数则不会产生这样的问题,其各段的梯度都可以保持一个较大的值以便于学习。
2、网络结构
一个生物神经细胞的功能比较简单,而人工神经元只是生物神经细胞的理想化和简单实现,功能更加简单。要想模拟人脑的能力,单一的神经元是远远不够的,需要通过很多神经元一起协作来完成复杂的功能。这样通过一定的连接方式或信息传递方式进行协作的神经元可以看作是一个网络,就是神经网络。
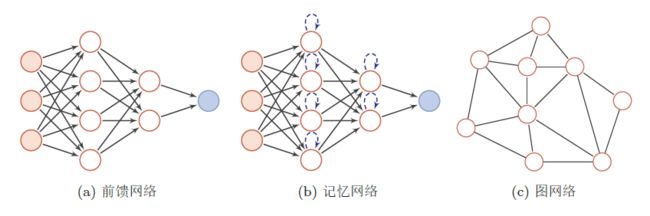
2.1、前馈网络
前馈网络中各个神经元按接受信息的先后分为不同的组。每一组可以看作一个神经层。每一层中的神经元接受前一层神经元的输出,并输出到下一层神经元。整个网络中的信息是朝一个方向传播,没有反向的信息传播,可以用一个有向无环路图表示。
前馈网络可以看作一个函数,通过简单非线性函数的多次复合,实现输入空间到输出空间的复杂映射。这种网络结构简单,易于实现。
前馈网络包括全连接前馈网络和卷积神经网络等。
2.2、记忆网络
记忆网络,也称为反馈网络,网络中的神经元不但可以接收其它神经元的信息,也可以接收自己的历史信息。和前馈网络相比,记忆网络中的神经元具有记忆功能,在不同的时刻具有不同的状态。记忆神经网络中的信息传播可以是单向或双向传递,因此可用一个有向循环图或无向图来表示。
记忆网络包括循环神经网络,Hopfield网络、玻尔兹曼机等。
2.3、图网络
前馈网络和记忆网络的输入都可以表示为向量或向量序列。但实际应用中很多数据是图结构的数据,比如知识图谱、社交网络、分子(Molecular )网络等。前馈网络和反馈网络很难处理图结构的数据。
图网络是定义在图结构数据上的神经网络。图中每个节点都由一个或一组神经元构成。节点之间的连接可以是有向的,也可以是无向的。每个节点可以收到来自相邻节点或自身的信息。
图网络是前馈网络和记忆网络的泛化,包括图卷积网络(Graph Convolutional Network,GCN)、消息传递网络(Message Passing Neural Network,MPNN)等。
以上三种网络结构如下图:
3、前馈神经网络
在前馈神经网络中,各神经元分别属于不同的层。每一层的神经元可以接收前一层神经元的信号,并产生信号输出到下一层。第0层叫输入层,最后一层叫输出层,其它中间层叫做隐藏层。
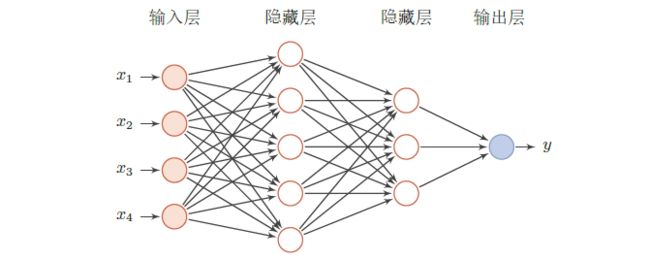
用下面的记号来描述一个前馈神经网络:
- :表示神经网络的层数;
- :表示第层神经元的个数;
- :表示层神经元的激活函数;
- :表示层到第层的权重矩阵;
- :表示层到第层的偏置;
- :表示层神经元的净输入(净活性值);
- :表示层神经元的输出(活性值)
前馈神经网络通过下面公式进行信息传播:
从而整个计算过程如下:
其中表示网络中所有层的连接权重和偏置。
3.1、通用近似定理
根据通用近似定理,对于具有线性输出层和至少一个使用“挤压”性质的激活函数的隐藏层组成的前馈神经网络,只要其隐藏层神经元的数量足够,它可以以任意的精度来近似任何一个定义在实数空间中的有界闭集函数。
通用近似定理只是说明了神经网络的计算能力可以去近似一个给定的连续函数,但并没有给出如何找到这样一个网络,以及是否是最优的。此外,当应用到机器学习时,真实的映射函数并不知道,一般是通过经验风险最小化和正则化来进行参数学习。因为神经网络的强大能力,反而容易在训练集上过拟合。
3.2、应用到机器学习
在机器学习中,输入样本的特征对分类器的影响很大。好的特征可以极大提高分类器的性能。因此,要取得好的分类效果,需要样本的原始特征向量转换到更有效的特征向量,这个过程叫做特征抽取。
多层前馈神经网络可以看作是一个非线性复合函数,将输入映射到输出。因此,多层前馈神经网络也可以看成一种特征转换方法,其输出作为分类器的输入进行分类。
给定一个训练样本,先利用多层前馈神经网络将映射到,然后再将输入到分类器:
其中为线性或非线性的分类器,为分类器的参数,为分类器的输出。
3.3、参数学习(反向传播算法)
假设采用随机梯度下降进行神经网络参数学习,给定一个样本,将其输入到神经网络模型中,得到网络输出为。假设损失函数为,要进行参数学习就需要计算损失函数关于每个参数的导数。
我们计算关于参数矩阵中每个元素的偏导:
这样我们只需要计算三个偏导数:
(1)计算偏导数
因:
其中为权重矩阵的第行,表示第个元素为,其余元素为0的行向量。
(2)计算偏导数
因:
(3)计算误差项
用来定义第层神经元的误差项
根据和有:
其中是向量的点积运算符,表示每个元素相乘。
可以看出,第层的误差项可以通过第层的误差项计算得到,这就是误差的反向传播。反向传播算法的含义是:第层的一个神经元的误差项(或敏感性)是所有与该神经元相连的第层的神经元的误差项的权重和再乘上该神经元激活函数的梯度。
计算出上面三个偏导数之后,公式可以写为:
因此,基于误差反向传播算法(Backpropagation,BP)的前馈神经网络训练过程可以分为以下三步:
- 前馈计算每一层的净输入和激活值,直到最后一层;
- 反向传播计算每一层的误差项;
- 计算每一层参数的偏导数,并更新参数。
4、优化问题
神经网络的参数学习比线性模型要更加困难,主要原因有两点:
- 非凸优化问题
- 梯度消失问题。
4.1、非凸优化问题
神经网络的优化问题是一个非凸优化问题。
以简单的2层神经网络为例:
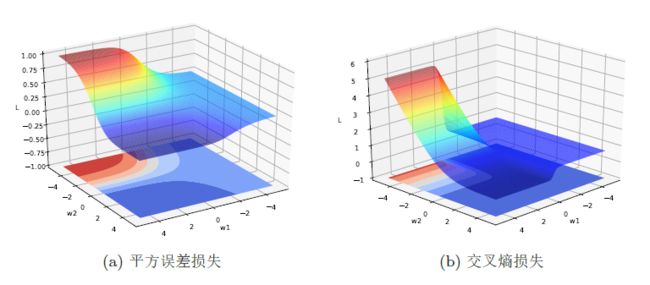
可以看出两种损失函数都是关于参数的非凸函数。
4.2、梯度消失问题
由于Sigmoid型函数的饱和性,饱和区的导数更是接近于0。这样,误差经过每一层传递都会不断衰减。当网络层数很深时,梯度就会不停的衰减,甚至消失,使得整个网络很难训练。这就是所谓的梯度消失问题(Vanishing gradient Problem),也叫梯度弥散问题。
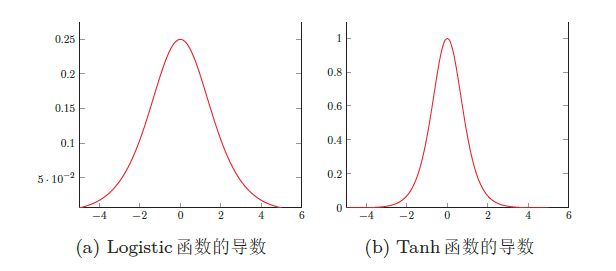
在深层神经网络中,减轻梯度消失问题的方法有很多种。一种简单有效的方式是使用导数比较大的激活函数,比如ReLU等。