最近有一个项目要用到图像检测,所以现在系统的开始入手深度学习的知识。本来打算用 Google 的 TensorFlow 来实现,毕竟 TFBoy 近几年热度不减,但考虑到项目实施周期,打算前期用百度的 EasyDL 来实现,和百度 AI 的产品经理聊了几次,说是类似的项目,200张样本训练,识别能达到80%,应该算是一个不错的识别率了。
当然,一些基础知识还是要了解一下,这里面有不少的概念还挺不好理解的。深度学习,有专门的卷积神经网络,在图像领域取得了非常好的实际效果,已经把传统的图像处理的方法快干趴下了。看了很多关于卷积的解释,在这里整理一下。
关于卷积的一个血腥的讲解
网上流传的一个段子,非常形象。比如说你的老板命令你干活,你却到楼下打台球去了,后来被老板发现,他非常气愤,扇了你一巴掌(注意,这就是输入信号,脉冲),于是你的脸上会渐渐地鼓起来一个包,你的脸就是一个系统,而鼓起来的包就是你的脸对巴掌的响应,好,这样就和信号系统建立起来意义对应的联系。
下面还需要一些假设来保证论证的严谨:假定你的脸是线性时不变系统,也就是说,无论什么时候老板打你一巴掌,打在你脸的同一位置,你的脸上总是会在相同的时间间隔内鼓起来一个相同高度的包来,并且假定以鼓起来的包的大小作为系统输出。好了,那么,下面可以进入核心内容——卷积了!
如果你每天都到楼下去打台球,那么老板每天都要扇你一巴掌,不过当老板打你一巴掌后,你5分钟就消肿了,所以时间长了,你甚至就适应这种生活了……。如果有一天,老板忍无可忍,以0.5秒的间隔开始不间断的扇你,这样问题就来了,第一次扇你鼓起来的包还没消肿,第二个巴掌就来了,你脸上的包就可能鼓起来两倍高,老板不断扇你,脉冲不断作用在你脸上,效果不断叠加了,这样这些效果就可以求和了,结果就是你脸上的包的高度随时间变化的一个函数了(注意理解)。
如果老板再狠一点,频率越来越高,以至于你都辨别不清时间间隔了,那么,求和就变成积分了。可以这样理解,在这个过程中的某一固定的时刻,你的脸上的包的鼓起程度和什么有关呢?和之前每次打你都有关!但是各次的贡献是不一样的,越早打的巴掌,贡献越小,所以这就是说,某一时刻的输出是之前很多次输入乘以各自的衰减系数之后的叠加而形成某一点的输出,然后再把不同时刻的输出点放在一起,形成一个函数,这就是卷积,卷积之后的函数就是你脸上的包的大小随时间变化的函数。
本来你的包几分钟就可以消肿,可是如果连续打,几个小时也消不了肿了,这难道不是一种平滑过程么?反映到剑桥大学的公式上,f(a) 就是第 a 个巴掌,g(x-a)就是第 a 个巴掌在x时刻的作用程度,乘起来再叠加就 ok 了。
什么是卷积
从数学上讲,卷积就是一种运算。通俗易懂的说,卷积就是
** 输出 = 输入 * 系统**
虽然它看起来只是个简单的数学公式,但是却有着重要的物理意义,因为自然界这样的系统无处不在,计算一个系统的输出最好的方法就是运用卷积。更一般的,我们还有很多其他领域的应用:
统计学中,加权的滑动平均是一种卷积。
概率论中,两个统计独立变量X与Y的和的概率密度函数是X与Y的概率密度函数的卷积。
声学中,回声可以用源声与一个反映各种反射效应的函数的卷积表示。
电子工程与信号处理中,任一个线性系统的输出都可以通过将输入信号与系统函数(系统的冲激响应)做卷积获得。
物理学中,任何一个线性系统(符合叠加原理)都存在卷积。
计算机科学中,卷积神经网络(CNN)是深度学习算法中的一种,近年来被广泛用到模式识别、图像处理等领域中。
这6个领域中,卷积起到了至关重要的作用。在面对一些复杂情况时,作为一种强有力的处理方法,卷积给出了简单却有效的输出。对于机器学习领域,尤其是深度学习,最著名的CNN卷积神经网络(Convolutional Neural Network, CNN),在图像领域取得了非常好的实际效果,始一出现便横扫各类算法。
其定义如下:
我们称 (f * g)(n) 为 f,g 的卷积
其连续的定义为:

其离散的定义为:

这两个式子有一个共同的特征:

这个特征有什么意义?
我们令 x = τ ,y = n − τ,那么 x + y = n 就是下面这些直线:

再通俗的说,看起来像把一张二维的地毯从角沿45度斜线卷起来。
以下是一张正方形地毯,上面保存着f和g在区间[a,\b]的张量积,即U(x,y)=f(x)g(y)。

把它从一角卷起来。

可以看出,它变成了一个一维的函数,而且每点的函数值等于卷起来后重合的点函数值之和。现在把地毯展开。

可以看出,刚才被画了道道的地方,正好就是x+y为定值的一条直线,所以卷起来后那点的函数值正好为这条直线上函数值的积分。
本质上卷积是将二元函数 U(x,y) = f(x)g(y) 卷成一元函数 V(t) ,俗称降维打击。
再看下面最简单的一个例子。
考虑到函数 f 和 g 应该地位平等,或者说变量 x 和 y 应该地位平等,一种可取的办法就是沿直线 x+y = t 卷起来:

卷了有什么用?可以用来做多位数乘法,比如:
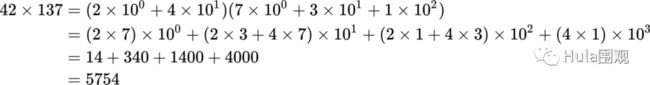
注意第二个等号右边每个括号里的系数构成的序列 (14,34,14,4),实际上就是序列 (2,4) 和 (7,3,1) 的卷积。
在乘数不大时这么干显得有点蛋疼,不过要计算很长很长的两个数乘积的话,这种处理方法就能派上用场了。
离散卷积的例子:丢骰子
要解决的问题是:有两枚骰子,把它们都抛出去,两枚骰子点数加起来为4的概率是多少?

分析一下,两枚骰子点数加起来为4的情况有三种情况:1+3=4, 2+2=4, 3+1=4
因此,两枚骰子点数加起来为4的概率为:

写成卷积的方式就是:

在这里我想进一步用上面的翻转滑动叠加的逻辑进行解释。
首先,因为两个骰子的点数和是4,为了满足这个约束条件,我们还是把函数 g 翻转一下,然后阴影区域上下对应的数相乘,然后累加,相当于求自变量为4的卷积值,如下图所示:

进一步,如此翻转以后,可以方便地进行推广去求两个骰子点数和为 n 时的概率,为f 和 g的卷积 f*g(n),如下图所示:
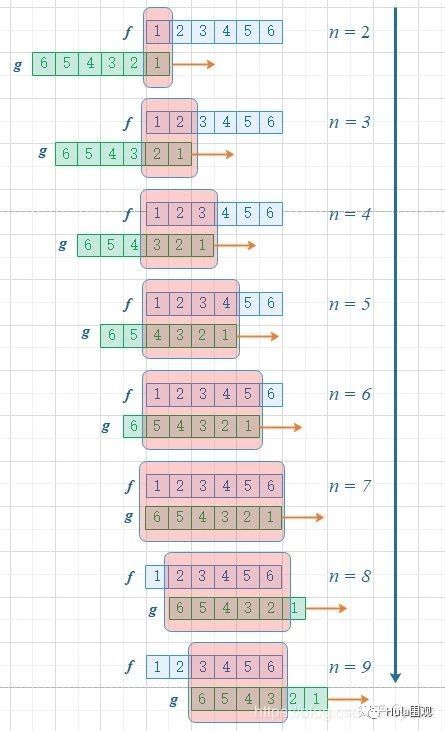
由上图可以看到,函数 g 的滑动,带来的是点数和的增大。这个例子中对f和g的约束条件就是点数和,它也是卷积函数的自变量。有兴趣还可以算算,如果骰子的每个点数出现的概率是均等的,那么两个骰子的点数和n=7的时候,概率最大。
连续卷积的例子:做馒头
楼下早点铺子生意太好了,供不应求,就买了一台机器,不断的生产馒头。
假设馒头的生产速度是 f(t),那么一天后生产出来的馒头总量为:

馒头生产出来之后,就会慢慢腐败,假设腐败函数为 g(t),比如,10个馒头,24小时会腐败:

想想就知道,第一个小时生产出来的馒头,一天后会经历24小时的腐败,第二个小时生产出来的馒头,一天后会经历23小时的腐败。
如此,我们可以知道,一天后,馒头总共腐败了:

卷积的应用
用一个模板和一幅图像进行卷积,对于图像上的一个点,让模板的原点和该点重合,然后模板上的点和图像上对应的点相乘,然后各点的积相加,就得到了该点的卷积值。对图像上的每个点都这样处理。由于大多数模板都是对称的,所以模板不旋转。卷积是一种积分运算,用来求两个曲线重叠区域面积。可以看作加权求和,可以用来消除噪声、特征增强。
把一个点的像素值用它周围的点的像素值的加权平均代替。
卷积是一种线性运算,图像处理中常见的mask运算都是卷积,广泛应用于图像滤波。
卷积关系最重要的一种情况,就是在信号与线性系统或数字信号处理中的卷积定理。利用该定理,可以将时间域或空间域中的卷积运算等价为频率域的相乘运算,从而利用FFT等快速算法,实现有效的计算,节省运算代价。
图像处理
有这么一副图像,可以看到,图像上有很多噪点:

高频信号,就好像平地耸立的山峰,看起来很显眼。
平滑这座山峰的办法之一就是,把山峰刨掉一些土,填到山峰周围去,用数学的话来说,就是把山峰周围的高度平均一下。
平滑后得到:

卷积可以帮助实现这个平滑算法。
有噪点的原图,可以把它转为一个矩阵:

然后用下面这个平均矩阵(说明下,原图的处理实际上用的是正态分布矩阵,这里为了简单,就用了算术平均矩阵)来平滑图像:

记得刚才说过的算法,把高频信号与周围的数值平均一下就可以平滑山峰。
比如我要平滑 a 1,1 点,就在矩阵中,取出 a 1,1 点附近的点组成矩阵 f, 和 g 进行卷积计算后,再填回去:
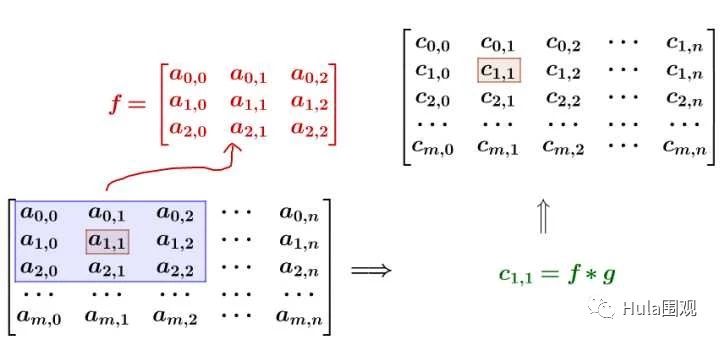
要注意一点,为了运用卷积,g 虽然和 f 同维度,但下标有点不一样:

用一个动图来说明下计算过程:

写成卷积公式就是:

要求C 4,5,一样可以套用上面的卷积公式:

这相当于实现了g 这个矩阵在原来图像上的滑动(准确来说下面这幅图把 g 矩阵旋转了180°):

卷积特征提取
自然图像有其固有特性,也就是说,图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
更恰当的解释是,当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8x8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
下面给出一个具体的例子:假设你已经从一个 96x96 的图像中学习到了它的一个 8x8 的样本所具有的特征,假设这是由有 100 个隐含单元的自编码完成的。为了得到卷积特征,需要对 96x96 的图像的每个 8x8 的小块图像区域都进行卷积运算。也就是说,抽取 8x8 的小块区域,并且从起始坐标开始依次标记为(1,1),(1,2),...,一直到(89,89),然后对抽取的区域逐个运行训练过的稀疏自编码来得到特征的激活值。在这个例子里,显然可以得到 100 个集合,每个集合含有 89x89 个卷积特征。

假设给定了r * c 的大尺寸图像,将其定义为 x large。首先通过从大尺寸图像中抽取的 a * b 的小尺寸图像样本 x small 训练稀疏自编码,计算 f = σ(W (1)x small + b (1))(σ 是一个 sigmoid 型函数)得到了 k 个特征, 其中 W (1) 和 b (1) 是可视层单元和隐含单元之间的权重和偏差值。对于每一个 a * b 大小的小图像 x s,计算出对应的值 f s = σ(W (1)x s + b (1)),对这些 fconvolved 值做卷积,就可以得到 k * (r - a + 1) * (c - b + 1) 个卷积后的特征的矩阵。
以上,未知来源出处无法一一注明。