数据库使用上的优化
1.查询原则
不查>少查>索引查询>普通查询
1.1不查询
没有必要进行查询的则不要进行查询。如第一次查询了客户列表信息,列表中查询显示了客户简单信息;则第二次查询详情时不要再去查询客户信息,能不查就不查


1.2少查询
少查询需要结合业务需求,业务上不经常更新的数据可以少查询,如论坛的日活跃量/在线人数等。或者如crm中角色的默认菜单等,前端可以存cookie且设置较长的有效期。
1.3索引查询
索引查询是优化查询的主体,任何查询都应该尽量向索引靠
1.4普通查询
应该给表建立简洁的索引树,尽量少进行普通查询
2. Explain的使用
explain是解释一个语句的执行计划。语句的优化可以在explain的结果中做出分析

2.1 select_type,语句结构
Simple,简单查询,即基础查询

Primary(主句),非简单查询中的主体语句
SubQuery(非From子查询)(5.7版本优化很多子查询,更能理解语句的执行意义)
Derived(派生From子查询)(5.7版本优化很多子查询,更能理解语句的执行意义)


Union(联合查询)、UnionResult;

2.2 table:真实表名、表的别名,表的派生名(子查询结果),null(没用到表);
2.3 patitions分区
2.4 type(关键因素):
system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>all

2.4.1 system:特殊的const,表中原本就只有一条数据,5.7已经没有该type
2.4.2 const:不变量,查询结果为单行如select * from student where id=1

2.4.3 eq_ref:查询中使用索引作为查询字段,这个索引是单一的,即主键或unique类型索引,多用在联合查询中
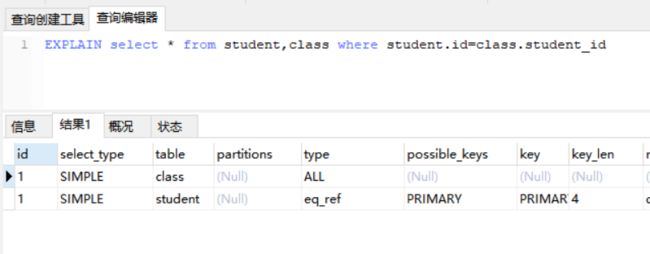
2.4.4 ref:查询中使用索引作为查询字段,这个索引是非单一的,即noraml类型索引,联合查询使用

2.4.5 fulltext:全文索引(很少用)
2.4.6 ref_or_null:ref情况下,索引值为null作为条件之一

2.4.7 index_merge:多个索引结果合并出最终结果,如or

2.4.8 unique_subquery:子查询中的eq_ref(5.7版本中没有找到合适结果,应该已经舍去)
2.4.9 index_subquery:子查询中的ref(5.7版本中没有找到合适结果,应该已经舍去)
2.4.10 range:索引有个范围的查询(主键专用)

2.4.11 index:全索引查询

2.4.12 all:全表查询

索引的使用过程中尽量不对对索引字段做函数处理,否则效果会变化
总结来说:const>[eq_ref>ref>index_merge>]range>index>all
1.查询中能确定单条的查询则先查出来

2.索引范围能确定的就确定掉
3.尽量使用索引查询,减少回行情况
4.联合查询中使用索引的性能顺序是Primar|Unique>Noraml>merge
5.尽量避免耗时操作,带有DISTINCT,UNION,ORDER BY的SQL语句,因为容易衍生子查询或union查询
6.避免在WHERE子句中使用in,not in,or 或者having,容易衍生子查询
7.使用union代替临时表,如果无需排除重复值或是操作集无重复则用UNION ALL, UNION很明显是需要比较重复性的
8. 尽量不要在建立的索引的数据列上进行操作,如:计算、IS NULL和IS NOT NULL、类型转换、函数使用,like操作等
9.避免建立索引的列中使用空值。
优化示例:
student表(大数据量表)

teacher表

student_teacher关系表(大数据量表)

1.查找id为1222学生的老师id
a. explain可以看到该语句查询关系表使用的是全表查询

b.未优化的执行效果,可以看到需要花费半秒多时间才能查出

c.优化
explain看出语句慢是慢在关系表的查询上,则需要对该表进行语句或结构优化。
优化手段1:因为该例中学生对老师的关系是一对多的,所以student与student_teacher的关系是一对一。可以根据需求情况认为找到student_id=1222的记录,这样全表查询就变为const查询


优化手段2:本着索引不宜多加的情况,手段1是行得通的,但人为干预去预知单条数据在业务开发中是不够现实的,这时就只能退而求其次,给关系表的student_id加索引


2.查询所有学生信息
a.explain查看,发现是全表查询,因为回行了

b.未优化结果

c.优化,手段就是避免回行,拿索引字段
