上一篇讲了
产品经理也能动手实践的AI(三)- 深入图像识别,在线辨猫
,形象的说明了SGD的原理,就是如何将一个线性函数你和到我们预设的散点图上。今天主要讲2个案例,1个核心模块,分别是卫星图像的多标签识别,图片分割着色,数据块这个核心模块。
这也是图像识别的最后一课了,我承认到这里可能就有点枯燥了,因为有很多需要消化的东西,不过我觉得重点是大概理解这是怎么一回事儿,以及把自己关注的点研究明白,不见得每个细节都要在一开始搞明白。
接下来就会讲解NLP和协同过滤,而且这节课也没有什么特别全新的东西,都是细节上的提升或者更详细的讲解。而我印象最深的就是u-net这个模型,以及他的lr(指代Learning Rate学习率,下文都会直接用lr来代替)训练方式,是先增后降。
1.概览
本节课主要讲解的是多标签识别(用卫星图像预测天气),图像分割(用不同颜色区分行人、道路、房子等),还有支持这两种类型的核心模块 - data block。
这是卫星图片,以及对应的标签

这是如何将一副路边的图像,用无人驾驶的视角按类别变成色块

2.1核心流程
下载数据(这一节主要来源于公共数据库)
创建databunch(data block的核心流程)
准备输入的数据
划分训练组和验证组数据
给输入的数据打标签
「可选」变形
「可选」增加测试组
转化成databunch
创建learner
开始训练
调优
2.2核心数学概念
-
-

-

通用逼近定理:当有一组线性和非线性函数,你就可以做出一个无线接近任意函数的函数。
2.3核心机器学习概念
flip翻转:在transform的时候,可以随机水平翻转或者垂直翻转图像,来提高训练的准确度,默认是水平翻转,比如训练识别猫的AI,而识别卫星图像的就可以同时垂直旋转;
warp透视:和45度拍照显脸小是一个道理,就相当于对一个正面拍摄的照片做了一个透视处理,虽然都是你本人,但是在图像上呈现的效果不同,所以这样的处理可以提高识别准确度;
normailize规范化:后面会专门讲
threshold阈值:主要是多标签时用,因为识别时会有N个结果,不像单标签,选最大的那个就行(argmax),这里要选threshold值以上的;
DataSet:数据集,只有getitem和len属性
DataLoader:用于把DataSet中的数据,按要求抽取成一个个mini-batch
DataBunch:训练组DataLoader和验证组DataLoader的组合
Mixed Precision Training 混合精确训练:创建learner时用16bits代替32bits,需要GPU支持
2.4核心Python、FastAI、Jupyter等命令
!:是在Jupyter Notebook中执行命令行的操作,如:# ! conda install -y -c haasad eidl7zip
Pandas:处理表格数据和常用库,比如查看数据:df = pd.read_csv(path/'train_v2.csv')
partial:Python3的特性,可以非常方便的生成一个具备固定参数的函数,这样代码看起来就更好懂,比如:acc_02 = partial(accuracy_thresh, thresh=0.2)
.shape:Image.shape 会给出这个tensor的大小,主要是包含channels,类似于维度,这个之后会讲 (channels x height x width)
.plot:把学习过程的数据打出来,loss,lr,等各种指标
lambda:匿名函数,即没有函数名的函数,例如输入x返回x+1:result = lambda x:x+1
双斜杠:Python里相除取整的意思,比如size = src_size//2
3.1实例详细分析(用卫星图像预测天气)
上一节讲的是通过Google image自己找图片然后自己下载下来,打上标签。这一届直接用Kaggle竞赛提供的数据。
下载数据
注册Kaggle
安装Kaggle下载工具 ! pip install kaggle --upgrade
授权
创建API Token - kaggle.json
下载并传到自己的Jupyter目录
接受该卫星项目许可(不然会遇到下载失败情况)
下载数据下载 kaggle competitions download -c competition_name -f file_name.
解压缩数据 需要安装edil7zip
创建DataBunch
先养成查看数据的习惯,看目录结构,看数据样本 pd.read_csv
准备输入的数据 ImageFileList.from_folder(path)
划分训练组和验证组数据 random_split_by_pct(0.2)
给输入的数据打标签 label_from_csv()
「可选」变形 transform(tfms, size=128)
「可选」增加测试组
转化成databunch databunch().normalize()
训练模型
调优
核心小技巧:先训练128x128尺寸的图像,然后再用迁移学习,训练256x256尺寸的图像,这样又快又准
3.2实例详细分析(图像分割,用不同颜色区分行人、道路、房子等)
下载数据,通过内置的Camvid数据库
查看数据,找到一条数据,用open_mask打开看看
创建databunch SegmentationItemList.from_folder(path_img)
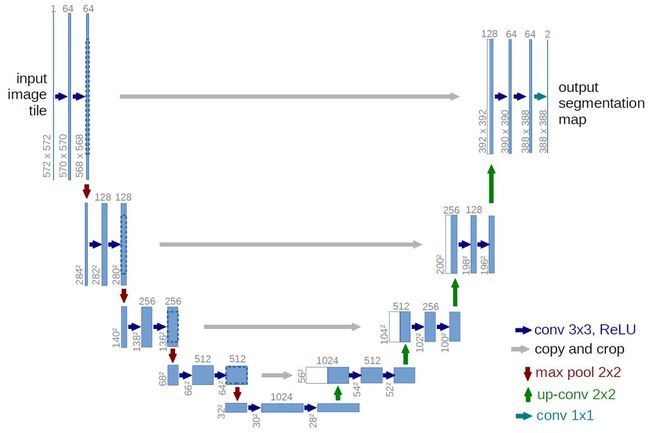
创建learner 使用u-net代替CNN来训练模型
开始训练
调优
3.3原理详细分析
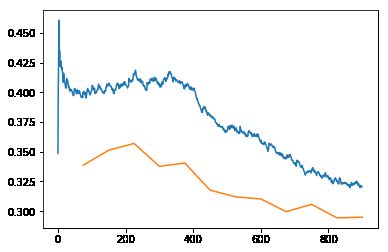
learn.recorder.plot_losses()
learn.recorder.plot_lr()
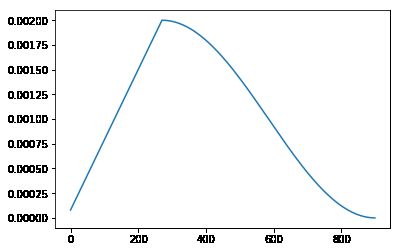
为什么lr会先升后降呢,这就是fit_one_cycle做的方式,因为相对而言,这种学习效率更高,形象点说就是先探探路,然后再大步走,感觉方向对了,就逐渐放慢脚步,然后到达那个最优点。如下演示的是以一个固定的lr,如下分别是lr为0.1,0.7,0.99,1.01时的机器的学习路径,看到0.7是最快接近底部,也就是loss最低的时候,而过低的lr和过高的lr都会影响效率,而高到一定程度反而会无法触达底部。
这是一种比较理想的情况,而实际应用中不会有这么平滑的弧度,肯定有各种小坑,而那时,固定的lr很容易陷到某一个小坑中而得到了不够理想的准确度,俗称拟合不足。
所以这里采用了更加动态的lr,只需要设定一个上限值,系统就会自动生成一个lr的抛物曲线,然后得到更准确的模型。
4.最后
本节课还讲了一个用回归模型识别头部中心点的例子,以及如何用IMDB数据预测评论的正负面情绪(NLP),之后的课程有更详细的讲解,所以这里就先不展开。