本篇相当于该系列的科普文。
一、机器学习方法
1、机器学习 Machine Learning
通常来说,机器学习的方法包括:
- 监督学习 supervised learning
有数据和标签的学习方法。大家熟悉的神经网络即为监督学习的方式。 - 非监督学习 unsupervised learning
只有数据没有标签的学习方法。 - 半监督学习 semi-supervised learning
综合了监督学习和非监督学习的学习方法。 - 强化学习 reinforcement learning
从经验中总结和提升的学习方法。
在规划机器人的行为准则方面,有一种机器学习方法叫强化学习。 - 遗传算法 genetic algorithm
这种方法是模拟我们熟知的进化理论,淘汰弱者,适者生存。通过这种淘汰机制去选择最优的设计或者模型。
二、神经网络
1、科普:人工神经网络 VS 生物神经网络
人工神经网络靠的是正向和反向传播(误差反向传播)来更新神经元, 从而形成一个好的神经系统, 本质上, 这是一个能让计算机处理和优化的数学模型. 而生物神经网络是通过刺激, 产生新的联结, 让信号能够通过新的联结传递而形成反馈.
2、神经网络 Neural Network
1、分为 input layer,hide layer,output layer
2、神经网络的工作方式:构建神经网络,输入数据/图片,将输出结果和正确答案进行对比并将误差反向传播回去,调整神经元的参数以更改神经网络的结构。
3、每个神经元都有自己的刺激函数 activated function,计算机很重视被激活/激励的神经元传递的信息。若输出的信息跟正确答案有出入,就会改动神经元的参数,不断进行下去,不断靠近正确的结果。
3、卷积神经网络 Convolutional Neural Network
CNN 最常被应用的方面是计算机的图像识别,后期也被应用在视频分析、nlp、药物发现等等。近期最火的 Alpha Go 同样有运用到这门技术。
卷积 和 神经网络
我们先把卷积神经网络这个词拆开来看. “卷积” 和 “神经网络”. 卷积也就是说神经网络不再是对每个像素的输入信息做处理了,而是图片上每一小块像素区域进行处理, 这种做法加强了图片信息的连续性. 使得神经网络能看到图形, 而非一个点. 这种做法同时也加深了神经网络对图片的理解. 具体来说, 卷积神经网络有一个批量过滤器, 持续不断的在图片上滚动收集图片里的信息,每一次收集的时候都只是收集一小块像素区域, 然后把收集来的信息进行整理, 这时候整理出来的信息有了一些实际上的呈现, 比如这时的神经网络能看到一些边缘的图片信息, 然后在以同样的步骤, 用类似的批量过滤器扫过产生的这些边缘信息, 神经网络从这些边缘信息里面总结出更高层的信息结构,比如说总结的边缘能够画出眼睛,鼻子等等. 再经过一次过滤, 脸部的信息也从这些眼睛鼻子的信息中被总结出来. 最后我们再把这些信息套入几层普通的全连接神经层进行分类, 这样就能得到输入的图片能被分为哪一类的结果了.
池化 pooling
研究发现, 在每一次卷积的时候, 神经层可能会无意地丢失一些信息. 这时, 池化 (pooling) 就可以很好地解决这一问题. 而且池化是一个筛选过滤的过程, 能将 layer 中有用的信息筛选出来, 给下一个层分析. 同时也减轻了神经网络的计算负担 (具体细节参考). 也就是说在卷集的时候, 我们不压缩长宽, 尽量地保留更多信息, 压缩的工作就交给池化了,这样的一项附加工作能够很有效的提高准确性. 有了这些技术,我们就可以搭建一个属于我们自己的卷积神经网络啦.
流行的 CNN 结构

4、循环神经网络 Recurrent Neural Network
RNN 在语言分析、序列化数据中应用自如。
普通的 NN 不能包含输入数据之间的顺序关系,因此 RNN 出现了。
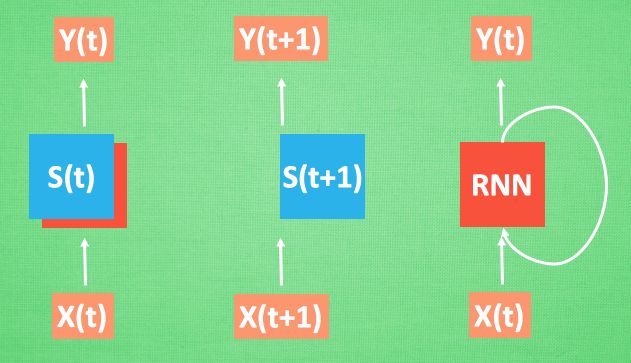
如上图,对于输入 x(t+1),RNN运算完之后会生成相应的中间状态 s(t+1),但此时的输出 y(t+1) 是由此时的中间状态和上一时刻的中间状态共同决定的,即 RNN 相对于普通的 NN 有了记忆的功能。使得之前的输入对现在的输出也产生了影响。
RNN 的应用:让 RNN 描述图片,让 RNN 写学术论文,让 RNN 写程序脚本,让 RNN 作曲。
5、LSTM RNN 循环神经网络
LSTM,long-short term memory,长短时记忆。
前面有提到,RNN 是针对顺序数据进行处理的,但是 RNN 比较健忘。比如关心的关键信息在输入数据的前部,那么这个信息要经过长途跋涉才能到达最后一个时间点,然后得到误差,此时在反向传播误差的时候,很容易发生梯度消失/梯度弥散(Gradient vanishing)或是梯度爆炸(Gradient exploding)。这就是普通 RNN 没办法回忆起久远记忆的原因。
而 LSTM 就是为了解决这个问题而诞生的。相比普通的 RNN 多了三个控制器,输入/输出/忘记。当前关键信息的更新是由输入控制和忘记控制来更新的,输出控制则负责判断最后要输出什么。所以 LSTM 相当于治疗 RNN 健忘的良药。
6、自编码 Autoencoder
本节会聊聊如何用神经网络进行非监督形式的学习,也即 Autoencoder。
压缩 与 解压

- 为何要经过压缩-解压这一负责的步骤呢?
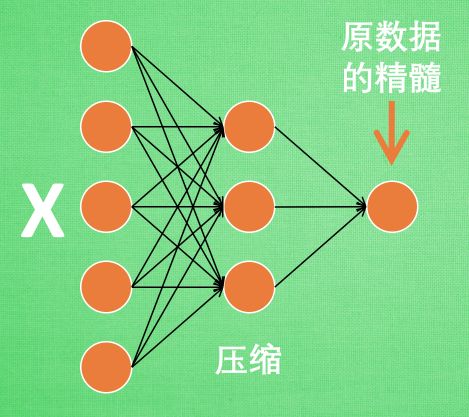
因为如果要神经网络读取千万张高清图片是一个很大的工作量,因此实际上我们只需要处理原图片中最有代表性的信息即精髓就好了。所以就有了压缩-解压这一过程。
- 自编码的工作方式是什么?
如上图,通过将原数据白色的 X 压缩, 解压成黑色的 X, 然后通过对比黑白 X ,求出预测误差, 进行反向传递, 逐步提升自编码的准确性. 训练好的自编码中间这一部分就是能总结原数据的精髓. 可以看出, 从头到尾, 我们只用到了输入数据 X, 并没有用到 X 对应的数据标签, 所以也可以说自编码是一种非监督学习. 到了真正使用自编码的时候. 通常只会用到自编码前半部分.
编码器 Encoder
解码器 decoder
解码器就是将压缩后的精髓解压成原始信息,解压器的作用就相当于生成器,类似于 GAN。那做这件事的一种特殊自编码叫做 variational autoencoders,可以在这里找到他的具体说明。
7、生成对抗网络 Generative Adversarial Nets
神经网络有很多种,有普通的前向传播神经网络,有分析图片的 CNN,有分析序列化数据(语音)的 RNN,这些网络都是用来输入数据得到想要的结果。这些神经网络可以很好地将数据与结果通过某种关系联系起来。
但还有另外一种形式的神经网络,不是用来把数据对应上结果的,而是凭借随机数来捏造结果的,就是 GAN。

Generator 会根据随机数来生成有意义的数据 , Discriminator 会学习如何判断哪些是真实数据 , 哪些是生成数据, 然后将学习的经验反向传递给 Generator, 让 Generator 能根据随机数生成更像真实数据的数据. 这样训练出来的 Generator 可以有很多用途, 比如最近有人就拿它来生成各种卧室的图片.
甚至你还能玩点新花样, 比如让图片来做加减法, 戴眼镜的男人 减去 男人 加上 女人, 他居然能生成 戴眼镜的女人的图片. 甚至还能根据你随便画的几笔草图来生成可能是你需要的蓝天白云大草地图片.
8、科普:神经网络的黑盒不黑
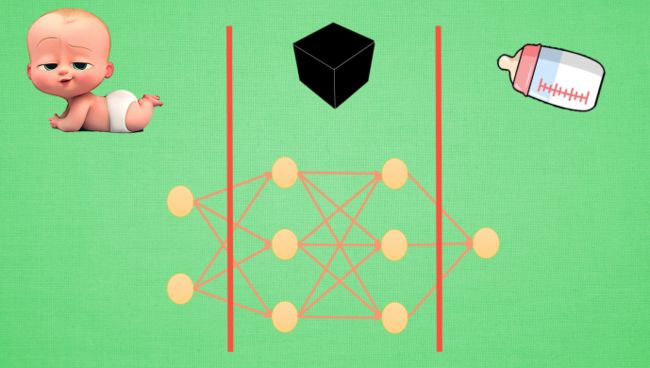
我们现在举个栗子,比如一个黑盒的输入是宝宝,输出是奶瓶。对应的输入层和输出层就是已知的。现在将左边的红线向右侧移动一步,红线左侧仍旧可以看作是“输入”,不过不是真实世界中的宝宝的输入,而是计算机可以理解的输入,也即宝宝的原始特征(feature)经过一层神经网络输出的代表特征(feature representation)。随着红线的右移,代表特征不断地被加工成新的代表特征,而黑盒也随之点亮,因此,黑盒的加工处理就是在将一种代表特征转换为另一种代表特征,一次次特征之间的转换,也就是一次次更有深度的理解。
有时候代表特征太多了,以至于人类没办法看懂他们代表的是什么,所以认定其为黑盒。但是计算机却能看清楚它学到的规律。这种代表特征的理解方式其实非常有用,以至于人们拿着它去研究更高级的神经网络玩法,比如迁移学习。
9、神经网络 梯度下降
神经网络是目前最流行的一种深度学习框架,基本原理其实就是一种梯度下降机制,现在来看看这神奇的优化模式吧。
Optimization 大家族
比如说牛顿法 (Newton’s method), 最小二乘法(Least Squares method), 梯度下降法 (Gradient Descent) 等等. 而神经网络就是属于梯度下降法这个分支中的一个. 大学里面学习过的求导求微分就是传说中”梯度下降”里面的”梯度” (gradient)啦.
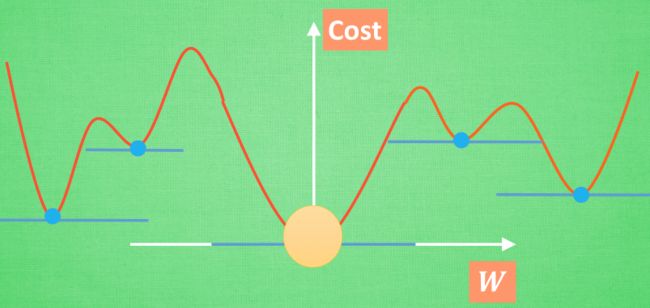
梯度下降
简而言之, 就是找到梯度线躺平的点. 可是神经网络的梯度下降可没这么简单.
神经网络中的 W 可不止一个, 如果只有一个 W, 我们就能画出之前那样的误差曲线, 如果有两个 W 也简单, 我们可以用一个3D 图来展示, 可是超过3个 W, 我们可就没办法很好的可视化出来啦. 这可不是最要命的. 在通常的神经网络中, 误差曲线可没这么优雅.
全局 and 局部最优
10、迁移学习 Transfer Learning
迁移学习,通俗点讲,就是“站在巨人的肩膀上”,即要善于学习先辈的经验,一个人的成功往往还取决于先辈们累积的知识。
比如说原先训练好了一个神经网络,现在任务变了,但是训练好的神经网络对现在完成任务很有帮助,只不过输出是不一样的结果。那么我们现在就可以把输出层摘掉,然后替换成新构建的网络层,此时训练这个拼接型的网络,就可以省去很多时间。
但并不是一定要利用原先已有的网络结构,比如现在处理的数据和之前的处理数据有着很大的不同,那么此时训练新的神经网络反而要比拼接型网络更好。
三、神经网络技巧
1、检验神经网络 Evaluation
Training and Test data
一般收集到的数据,70% 用来训练,30% 用来测试。类比于我们学生时代的作业题和考试题。所以测试数据虽然量小,但是还是很重要。
误差曲线
一般刚开始下降的很快后来下降的很慢的曲线,已经是很不错的学习成果了。
准确度曲线
相当于误差曲线的互补曲线。
正规化
当训练数据表现得很好时,往往容易出现 overfitting,解决方法有很多种,如 L1,L2正规化,dropout 方法。
交叉验证
交叉验证不仅仅可以用于神经网络的调参,还能用于其他机器学习方法的调参。曲线同样是选择想观看的误差值或者是精确度,不过横坐标不再是学习时间,而是要测试的某一参数,比如说神经网络参数。

2、特征标准化 Feature Normalization
本节主要介绍特征数据的标准化,也可以说是正常化,归一化,正规化等等。
我们以经典的房屋预测为例,比如现在房屋价格的决定因素有两种,X1 房屋面积,X2 离市中心的距离。那么可以数学化表示为 W = a * X1 + b * X2,而我们要做的就是求出参数 a,b。其中 X1 的单位是 m^2,X2 的单位是 km,很明显的,X1 在数值上要远大于 X2,那么此时 X1 稍微的改动都会比 X2 很大的改动对式子产生的影响大。换句话说,就是 X1 对式子的贡献和 X2 对式子的贡献不一样大,那么这时候求出来的参数很可能有偏差。所以我们要标准化我们的输入数据 X1 和 X2。
常用的 特征标准化 的路径有两种,一种是min max normalization,会将所有的特征数据按比例缩放到 0-1 的取值区间。另一种是standard deviation normalization,会将所有的特征数据缩放成均值为0 方差为1 的数据。
使用这些标准化手段,不仅可以快速推进机器学习的学习速度,还可以避免机器学习学习过程扭曲。
3、选择好特征 Good Features
什么是好的特征呢?以分类器为例:
- 避免无意义的信息,即对分类结果没有贡献
- 避免重复性的信息。例如描述距离的时候数据有 m 和 km 两种单位
- 避免复杂的信息。例如我们要预测从 A 地到 B 地所需要的时间,一种输入特征信息是 AB 两地的经纬度,一种是 AB 间的距离,显而易见,这时候选第二种输入特征信息进行机器学习预测。
4、激励函数 Activation Function
为什么要使用激励函数?
因为激励函数可以解决日常生活中不能用线性方程 linear function 所概括的问题。
比如说我们可以把神经网络简化为 Y = WX,但是这样只能描述一个线性问题,于是就需要激励函数来将这条直线“掰弯”,即 Y = AF(WX)。
AF 其实就是激励函数,常有的选择是 relu sigmoid tanh,把这些掰弯利器嵌套在原有的结果就可以强行把原先的线性结果扭曲成曲线了。同时我们也可以自己创造激励函数,不过要求是必须可微分,因为在 back propagation 误差反向传递时,只有可微分的激励函数才能把误差传递回去。
恰当地使用激励函数,是有窍门的。
- 少量层结构中,对于隐藏层使用任意的激励函数不会有很大的影响。一般地,在 CNN 的卷积层中推荐 Relu,在 RNN 中推荐 tanh 或 Relu。(具体怎么选,看之后 RNN 中详细介绍)
- 多层神经网络中,掰弯利器不能随意选择,因为会涉及到
梯度爆炸和梯度消失的问题。
5、过拟合 Overfitting
过拟合就是我们训练出来的模型“过于自负”,导致他认为自己将训练数据的误差降到最小,就能打遍天下的数据。
那么解决过拟合的方法是什么呢?
- 增大数据量。其实某种意义上,有时不好实现。
- 运用正规化。这种方法适用于大部分的机器学习,当然也包括神经网络。思想就是:首先简化机器学习公式 Y = WX,当过拟合时,W的值往往变化得过大或者过小,所以我们可以让 cost 的变化和 W 的变化关联起来,加入惩罚机制。原先,cost = (预测值-真实值)^2,现在

这里 abs 是绝对值,这一种形式的 正规化, 叫做 L1 正规化。 L2 正规化和 L1 类似,只是绝对值换成了平方。其他的 L3 L4 也都是换成了立方和4次方等等,形式类似。用这些方法,我们就能保证让学出来的线条不会过于扭曲。
- 还有一种专门用在神经网络的正规化的方法,叫作 dropout。在训练的时候,随机忽略掉一些神经元和神经联结 使得神经网络变得”不完整”,用一个不完整的神经网络训练一次。到第二次再随机忽略另一些,变成另一个不完整的神经网络。有了这些随机 drop 掉的规则,保证让每一次预测结果都不会依赖于其中某部分特定的神经元。像l1, l2正规化一样,过度依赖的 W,也就是训练参数的数值会很大,而 l1, l2会惩罚这些大的参数。Dropout 的做法是从根本上让神经网络没机会过度依赖。
6、加速神经网络训练 Speed Up Training
Stochastic Gradient Descent - SGD
数据量很大的时候,如果重复不断地把整套数据放入 NN 中训练,将很耗时间和内存。但是如果如果把数据拆分成小批小批的,然后分批不断得放入 NN 中计算,那么就可以在很大程度上加速 NN 的训练过程,而且也不会丢失太多准确率。
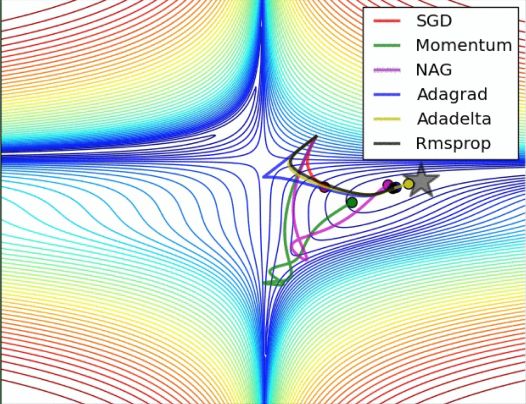
事实证明,SGD 并不是最快速的训练方法。红色的线是 SGD,但它达到学习目标的时间却是最长的。
Momentum
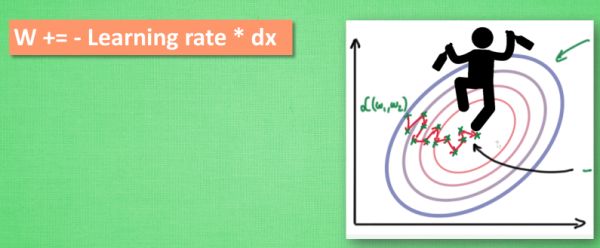
W += -Learning rate * dx,但这种方法可能会让学习过程看起来曲折无比。
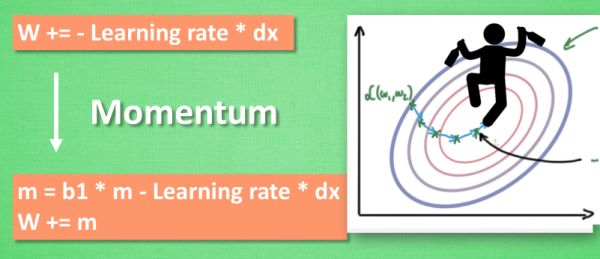
Momentum 参数更新。
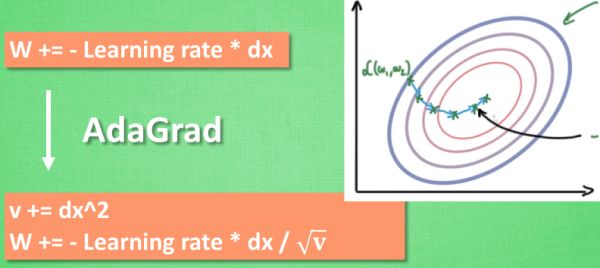
AdaGrad
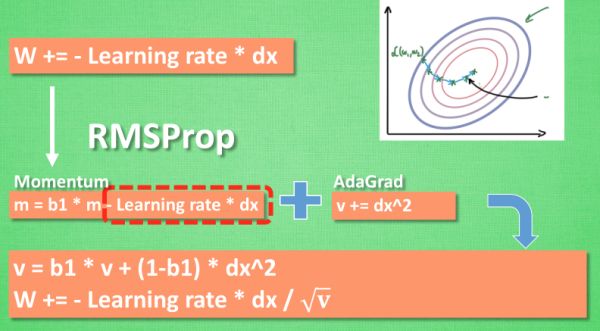
RMSProp
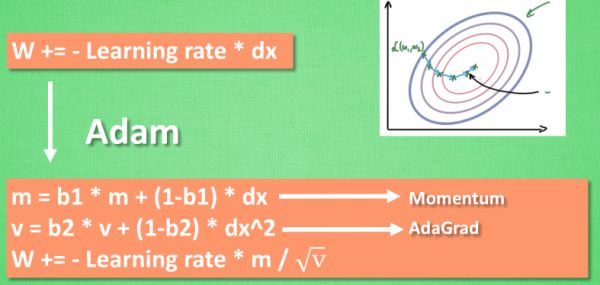
Adam
7、处理不均衡数据 Imbalanced data
何为不均衡数据?
例如,我们现在有苹果和梨两种水果,如果手中的数据显示几乎全世界的人都只会吃梨。那么这时候随便抓一个路人甲,我们肯定会猜他吃梨。
不均衡的数据预测起来很简单,比如吃梨:吃苹果的人 = 9:1,这时候只要每次猜吃梨,预测准确率就能高达 90%。机器学习也懂这个小伎俩啊,但是我们怎么防止呢?
A. 获得更多数据
有时候收集过程汇总前期呈现某种趋势,但随着数据量的增加,趋势会改变。
B. 更换评判方式
在不均衡数据面前,准确率 accuracy和误差 cost就变得没那么重要了。我们需要通过confusion matrix来计算precision和recall,然后通过这两者计算F1 Score/F-score。这种方式能成功区分不均衡数据,给出更好的评判分数,具体计算过程烦请自行查找。
C. 重组数据
简单粗暴,重组数据使之均衡。方式一:复制或者合成少数部分的样本,使之和多数部分差不多数量;方式二:砍掉一些多数部分,使两者数量差不多。
D. 使用其他机器学习方法
如果使用的机器学习方法如 NN 在面对不均衡数据时通常束手无策,但是像决策树这种机器学习方法就不会收到影响。
E. 修改算法
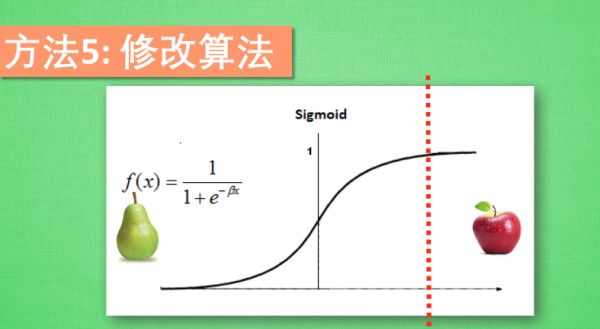
8、批标准化 Batch Normalization
为什么出现 Batch Normalization?
而这个不敏感问题不仅发生在神经网络的输入层,在隐藏层中也经常会发生,所以出现了 BN。BN 常常插在全连接网络和激励函数之间,以便于可以更好地利用 tanh 进行非线性化的过程。
BN 算法

图中引入了一些 batch normalization 的公式。前三步就是刚刚一直说的 normalization 工序,但公式的后面还有一个反向操作,将 normalize 后的数据再扩展和平移。这是为了让神经网络自己去学着使用和修改这个 扩展参数 gamma 和平移参数 β,这样神经网络就能自己慢慢琢磨出前面的 normalization 操作到底有没有起到优化的作用,如果没有起到作用,就使用 gamma 和 belt 来抵消一些 normalization 的操作。
9、L1/L2 正规化 Regularization
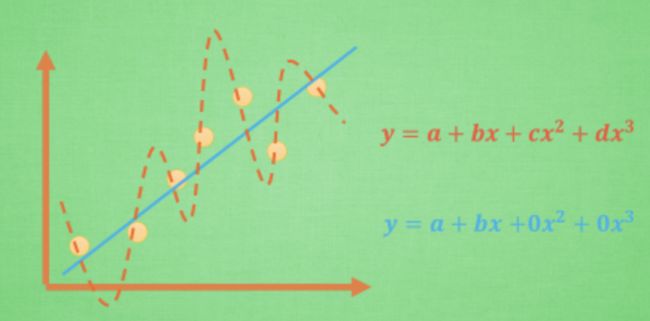
正规化操作就是为了解决过拟合的问题。比如上图中我们希望最终学习到的模型是蓝线,因为它能更有效地概括数据。这时候可以看作红蓝两线都有 4 个参数,只不过学习的过程中 c 和 d 逐渐趋向于 0。那如何保证呢?L1/L2 正规化应运而生。
核心思想就是尽量让所有的参数对模型的贡献量相差不大,所以就出现了惩罚机制,而惩罚项的不同决定了是 L1 还是 L2。其中 L1 正规化通常也用来挑选对结果贡献最大的重要特征,而且相对于 L2而言,L1 解更不稳定。
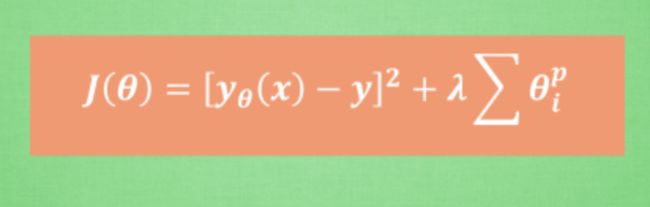
这是统一表达式。为了控制这种正规化的强度,通常会加上一个参数 lambda,并且通过交叉验证 cross validation 来选择比较好的 lambda。这时为了统一化这类型的正规化方法,我们还会使用 p 来代表对参数的正规化程度。这就是这一系列正规化方法的最终的表达形式啦。