背景
深度学习模型被广泛应用到各种领域,像是图像分类,自然语言处理,自动驾驶等。以ResNet,VGG为代表的一系列深度网络在这些领域上都取得了不错的效果,甚至超过人类的水平。然而,Szegedy等人在2014年的工作(Intriguing properties of neural networks)揭示了深度网络的脆弱性(vulnerability),即在输入上做一些微小的扰动(perturbation)就可以令一个训练好的模型输出错误的结果,以下面这张经典的熊猫图为例:
可以看到,左边的熊猫图,被模型以57.7%的置性度(confidence)分类为熊猫,加上一个微小的噪声之后,虽然图片肉眼看上去还是熊猫,但是却被模型以99.3%的置性度分类为长臂猿(gibbon)。
这个带噪声的样本被称作 对抗样本(Adversarial Example),而生成对抗样本的方法便属于一类攻击。
这类攻击一般来说,可以分为两类:
- 黑盒攻击
- 白盒攻击
黑盒攻击一般是假定攻击者不能干涉训练过程,不知道模型的具体参数,只能获取最后的输出,即softmax层之后的概率向量。
而白盒攻击一般是认为攻击者可以获取到模型的具体参数,包括每一层卷积核的权重等。
进行黑盒和白盒分类之后,攻击还可以继续再分:
- 有目标的攻击(targeted attack)
- 无目标的攻击(untargeted attack)
有目标的攻击即攻击者有一个特定的类,希望生成对抗样本,使得模型分类为那个特定的类别。
而无目标攻击会比较简单一点,只需要令模型的分类结果错误即可,至于分成哪一个类别则无所谓。
主要内容
本文主要是回顾这些年来的一些著名的攻击工作,包括:FGSM,JSMA,C&W,PGD,MIM,BIM,EAD。讲一讲这些攻击的思路以及一些细节,并以最近的一些防御工作为例,看看这些攻击的效果。
FGSM
FGSM全名是Fast Gradient Sign Method,是2015年Goodfellow等人在ICLR15:Explaining and harnessing adversarial examples中提出来的,通过梯度的符号来生成对抗样本,核心公式为:
其中,分别是干净的样本以及对应的label,这里的label是指one hot向量。
函数是交叉熵函数(cross-entropy),则是对应的对抗样本。
函数是符号函数,正数返回1,负数返回-1,0返回0。
交叉熵函数一般是在我们训练的时候会用到,作为最终的损失函数进行优化,这里直接利用损失函数的梯度,仿照反向传播的思路,对样本求梯度,使得损失函数变大。注意到这里我们计算交叉熵函数的梯度的时候,最后只取符号,代表一个变化的方向。参数控制着噪声的多少,如果太大的话人眼也不可区分了,就不算是对抗样本了,一般可能设置成8/255。
JSMA
JSMA全名是Jacobian-based Saliency Map Attack,是2016年由papernot等人在“The Limitations of Deep Learning in Adversarial Settings”中提出来的。其思路主要是利用一个热力图,也就是方法名字中的Saliency Map来指导对抗样本的生成。给出其核心的公式:
这便是热力图的生成方法,其中表示模型的输出结果,而则是指模型输出结果的第个位置的数值,通常也表示第个类别的置信度。可以理解为输出的第个像素点的值。
这个热力图的含义即,一旦在该像素上添加噪声之后,不能提高其他类别的置信度(偏导数大于0)或者不能降低真实类别的置信度(偏导数小于0),则不操作该像素。对于其他的情况,则使用两个偏导数的乘积作为值,代表其影响的程度。
在JSMA中,往往会先计算热力图,然后选取热力值最大的那个像素进行修改,反复迭代至成功攻击或者可操作的像素数目达到阈值。
C&W
C&W是两个人的人名的首字母组合而成的,即Carlini和Wagner在2017年的 “Towards Evaluating the Robustness of Neural Networks” 中提出来的。
对于以往的攻击形式,可以表述为:
其中表示和之间的距离
该式子的意思即,找到一个最小的噪声,使得分类结果为目标分类
但是该种表述中的过于非线性(Highly Non-Linear),导致优化可能出现问题。
于是将其改进为
进一步的,表述为
其中
同时对于进行变换,令
因为,同时
最后,给出其攻击的核心式子:
其中为softmax层之前的向量,用来作为目标函数进行优化,整个优化目标为
PGD
PGD全称是Projected Gradient Descent,是由Madry等人在2019年的“Towards Deep Learning Models Resistant to Adversarial Attacks”中提出来的。其思路类似于将FGSM多次迭代,形式如下:
重点是其中的一个投影操作,将修改后的值映射到其邻域。
BIM
BIM全称是Basic Iterative Method,由Kurakin等人于2017年的“Adversarial examples in the physical world”中提出来。其原理是,先找到一个分类置性度最低的类别,沿着这个类别的方向进行梯度计算,进而得到对应的对抗样本。
其定义了一个称之为迭代性最小可信类别(iterative least-likely class):
其核心式子类似于迭代形式的FGSM,如下:
函数用于进行截断,使得整体的噪声不超过阈值。
MIM
MIM全称是Momentum Iterative Method,是有Dong等人在2018年的“Boosting Adversarial Attacks with Momentum”中提出来的,在FGSM的基础上,加入了迭代和动量项,形式如下:
EAD
EAD全称是Elastic-Net Attacks to DNNs,是由chen等人在2018年的“EAD: Elastic-Net Attacks to Deep Neural Networks via Adversarial Examples”中所提出。
其也是迭代的形式,有点类似MIM和C&W的结合。
其形式如下:
其中,
同时,, 其中为softmax层之前的向量。
并且,
函数本质上是对构造的对抗样本和干净的输入进行比对和压缩,将变化范围压缩到0和1之间。
现有防御下攻击的性能比较
先以ICML19,Jun Zhu组的Improving Adversarial Robustness via Promoting Ensemble Diversity为例,这是一种利用模型之间的diversity来实现对抗鲁棒性的防御手段。
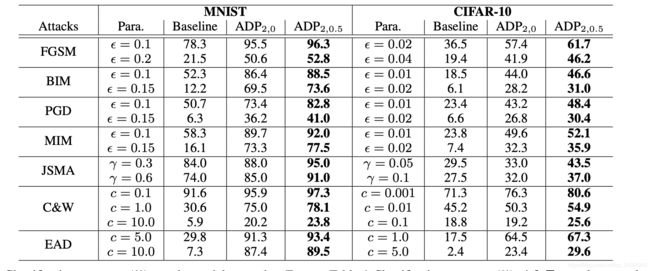
该表格的数值为分类的正确率,可以看到在MNIST数据集上,PGD攻击似乎是效果最好的,BIM次之。在CIFAR-10数据集上,JSMA、BIM、PGD都比较不错。
对于简单数据集MNIST在对噪声有限制的情况下,防御效果都还不错。
对于复杂一点的数据集CIFAR-10则表现仍然不尽如人意。