之前粗略的读过西瓜书的关于模型的评估与选择这一章
关于对模型的泛化性评估,以为无非就是分为训练集和测试集,分别用来训练模型以及计算误差。
再往下看,什么交叉验证法、留出法.....,都是不断的捯饬训练集和测试集这两个集合,交叉验证当初也就想当然的以为和书上讲的一样,交叉验证通常称为"K折交叉验证",这个不断腾挪测试集和训练集的过程,我就以为是所谓的"交叉"了。
直到我决定完整的看一遍吴恩达在coursera的课程,看到“模型的选择和/训练/验证/测试集合”这一段视频,B站也有视频可以去翻(链接下面已经补上了),里面讲到关于回归模型如何去选择多项式的次数时,就讲到了交叉验证相关的问题。评估这种带有超参模型泛化误差时,引入了交叉验证集合,下面统称验证集,这个概念,我立马联想到我所知的交叉验证,感觉甚是奇怪。
为什么要引入这个"验证集"呢,对照着来看,首先来想想,我们为什么引入测试集?原因就是我们如果在训练集上又训练又测试,这样的测试误差只能称为训练误差,如果以这个误差为目标调整算法,最终我们的模型很可能就是一个不会举一反三的"沙雕",因为譬如我根据训练数据梯度下降,得出的回归模型参数是尽量拟合我们的训练集合的,以拟合训练数据为目标优化算法,过拟合是迟早的事,所以需要从训练数据中划分一部分作为客观的第三方来评价我们的模型,以此来模拟泛化误差。接下来我们的超参怎么选择呢?这个时候如果盲目的理解书中的"读者可能马上想到,调参和算法选择没什么本质的区别: 对每种参数配置都训练出模型,然后把对应最好的模型的参数作为结果,这样的考虑基本是对的"。注意这句"基本是对的"。
回归正题,按照书中的做法我们只要一次列举出多项式的不同次数然后依次进行模型的训练,最后取测试集合效果最好的次数作为我们的最终选择就能得到我们的结果,那么这个结果能够推广到一般的情况中去吗?照搬上面引入测试集的思考方法,可以得出我们最终的多项式次数的选择,其实来自对测试集的拟合,我们根据测试集得到了拟合度最好的多项式的次数,但是这个误差结果只是作用于测试集的结果上,也并不是我们要的泛化误差,期间我也翻阅了sklearn的官方文档,其中"This way, knowledge about the test set can “leak” into the model and evaluation metrics no longer report on generalization performance",这句话比喻的非常好,”大概的意思就是测试集的构成已经泄露给了模型,评估的指标也就不再具有泛化性“,所以产生了和用训练集测试一样的效果,引入验证集合也就成了必然的。sklearn官方文档也阐述了交叉验证的历史,一开始的确是要分为,训练/验证/测试,而由于这样会导致训练数据的减少,才出现了我们熟知的K折交叉验证,而K折交叉验证则说明了不再需要验证集,这是为什么呢?
我想由于其K折的特性,测试集就不像之前的交叉验证的测试集是固定的,而是取多次不同的测试误差的均值,可能是因为这样就弱化了对单一测试集的拟合,更加接近泛化误差,就不用额外引入验证集规避测试集导致超参过拟合的问题。
打脸!!!
想当然果然是错的,在看过利用GridSearchCV搜索超参的例子中,我最终发现了答案,而K折交叉验证也并不是真的不需要验证集,而是从直观上来看,没有声明而已,但是却“隐藏”在了交叉验证中,官方文档所说的不需要验证集的意思是不用在整个数据集中再特别声明测试集。
我们看一下这个链接当中是如何具体操作的:
Parameter estimation using grid search with cross-validation — scikit-learn 0.20.2 documentation
最开始利用train_test_split就已经分割了训练与测试数据,不想翻译就直接看下面的链接
sklearn.GridSearchCV选择超参 -
之后我们可以看到在进行GridSearchCV进行参数选择的时候,CV所用的数据就是train_data,而在交叉验证的过程中又会进行训练集、测试集的分割,而这时的测试集则就可以看作是我们之前提到的"验证集",所以说并不是CV不需要"验证集",而是他这种K折的方式充分利用了训练集而已,文档中的"but the validation set is no longer needed when doing CV",让我误解了好一会儿,最终选取的是验证误差最小的参数,所以说这其实就是在用交叉验证的方式变相的用验证集选择参数。
继续往下看,最终才轮到我们真正的"测试集"登场,也就是在一开始从数据集中分割出来的测试集,用来评估最终的泛化误差。
最后总结一下,其实我就是为了个"称呼"折腾了好久,在有超参的情况下,把交叉验证嵌套在泛化误差测量之前,那么这个交叉验证中的"测试集"就达到了"验证集"的效果而已。
最后这个链接的内容再一次印证了需要嵌套CV,才能实现一开始所讲到的引入验证集的初衷,不泄露测试集的信息,保证最后结果的泛化性。
Nested versus non-nested cross-validation — scikit-learn 0.20.2 documentation
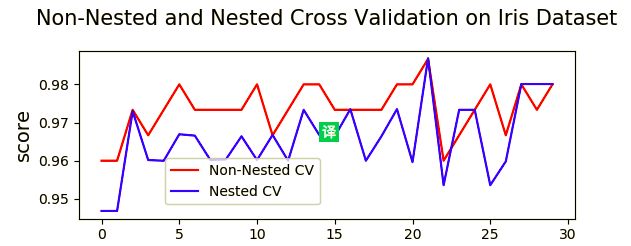
可以看到非嵌套CV的得分就比较盲目,由于超参对测试集过拟合导致分数虚高,而嵌套CV的曲线就能较为真实的反应出泛化能力。
附上sklearn的文档链接:
3.1. Cross-validation: evaluating estimator performance — scikit-learn 0.20.2 documentation
B站:模型选择_交叉验证相关视频链接
https://www.bilibili.com/video/av9912938/?p=61