人类的视觉原理
深度学习的许多研究成果,离不开对大脑认知原理的研究,尤其是视觉原理的研究。
1981年的诺贝尔医学奖,颁发给了David Hubel(出生于加拿大的美国神经生物学家)和TorstenWiesel,以及Roger Sperry。前两位的主要贡献,是“发现了视觉系统的信息处理”,可视皮层是分级的。
人类的视觉原理如下:从原始信号摄入开始(瞳孔摄入像素Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。下面是人脑进行人脸识别的一个示例:
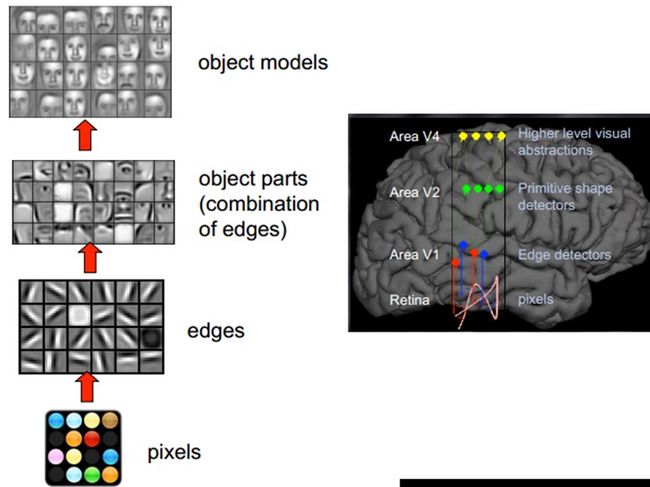
对于不同的物体,人类视觉也是通过这样逐层分级,来进行认知的:

我们可以看到,在最底层特征基本上是类似的,就是各种边缘,越往上,越能提取出此类物体的一些特征(轮子、眼睛、躯干等),到最上层,不同的高级特征最终组合成相应的图像,从而能够让人类准确的区分不同的物体。
所以我们可以很自然的想到:可以不可以模仿人类大脑的这个特点,构造多层的神经网络,较低层的识别初级的图像特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,最终在顶层做出分类呢?答案是肯定的,这也是许多深度学习算法的灵感来源,也包括卷积神经网络(CNN)算法。
图像的表示
实质上,每张图片都可以表示为由像素值组成的矩阵。

通道(channel)是一个传统术语,指图像的一个特定成分。标准数码相机拍摄的照片具有三个通道:红、绿和蓝。你可以将它们想象为三个堆叠在一起的二维矩阵(每种颜色一个),每个矩阵的像素值都在0到255之间。
而灰度图像只有一个通道,即一个代表图像的二维矩阵。矩阵中每个像素值的范围在0到255之间:0表示黑色,255表示白色。

卷积处理灰度图片
如果想让计算机搞清楚图像上有什么物体,我们可以做的事情是检测图像的垂直边缘和水平边缘,如下图所示:

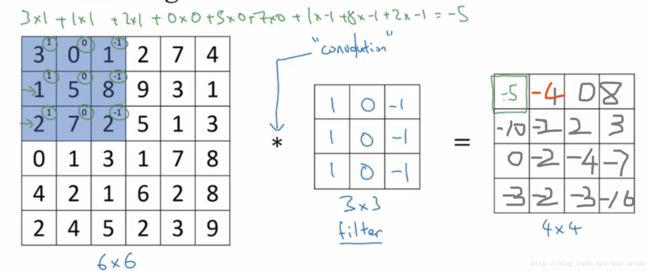
我们可以用一个66的灰度图像来打比方,构造一个33的矩阵,在卷积神经网络中通常称之为过滤器(filter),对这个6*6的图像进行卷积运算,以左上角的-5计算为例:
31 + 00 + 1-1 + 11 + 50 + 8-1 + 21 + 70 + 2*-1 = -5
其它的以此类推,让过滤器在图像上逐步滑动,对整个图像进行卷积计算得到一幅4*4的图像。(灰色图片是单通道颜色值)
为什么这种卷积计算可以得到图像的边缘,下图0表示图像暗色区域,10为图像比较亮的区域,同样用一个3*3过滤器,对图像进行卷积,得到的图像中间亮,两边暗,亮色区域就对应图像边缘。
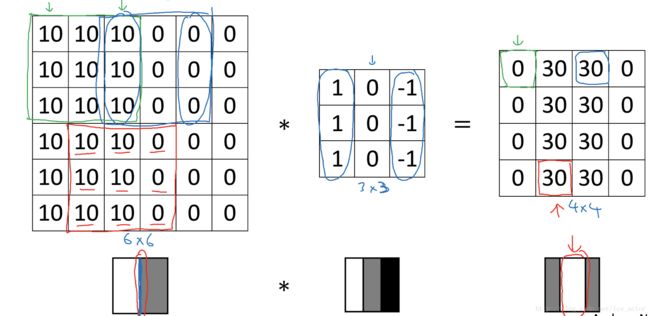
通过以下的水平过滤器和垂直过滤器,可以实现图像水平和垂直边缘检测。

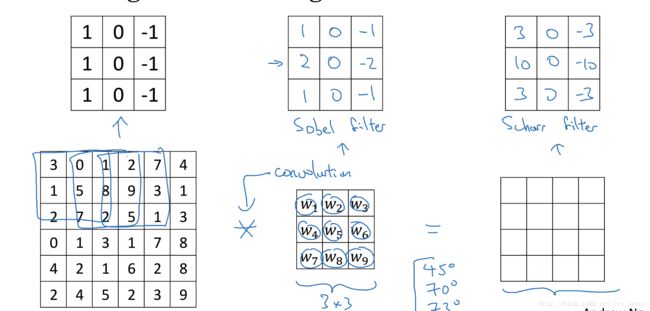
以下列出了一些常用的过滤器,对于不同的过滤器也有着不同的争论,在卷积神经网络中把这些过滤器当成我们要学习的参数,卷积神经网络训练的目标就是去理解过滤器的参数。
卷积前填充图片
在上部分中,通过一个33的过滤器来对66的图像进行卷积,得到了一幅44的图像,假设输出图像大小为nn与过滤器大小为f*f,输出图像大小则为:
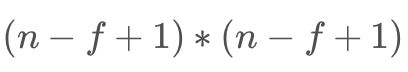
这样做卷积运算的缺点是,卷积图像的大小会不断缩小,另外图像的左上角的元素只被一个输出所使用,所以在图像边缘的像素在输出中采用较少,也就意味着我们丢掉了很多图像边缘的信息,为了解决这两个问题,就引入了填充(padding)操作,也就是在图像卷积操作之前,沿着图像边缘用0进行图像填充。对于3*3的过滤器,我们填充宽度为1时,就可以保证输出图像和输入图像一样大。
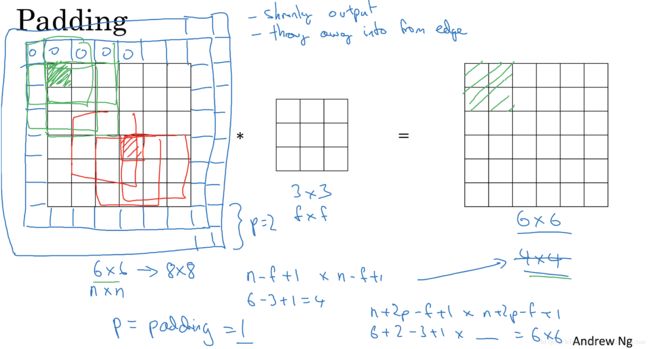
填充(padding)的两种模式:
Valid:没有填充,输入图像nn,过滤器ff,输出图像大小为:
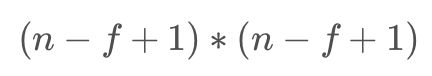
Same:有填充,输出图像和输入图像一样大
卷积图像的步长
卷积步长是指过滤器在图像上滑动的距离,前两部分步长都默认为1,如果卷积步长为2,卷积运算过程如下。
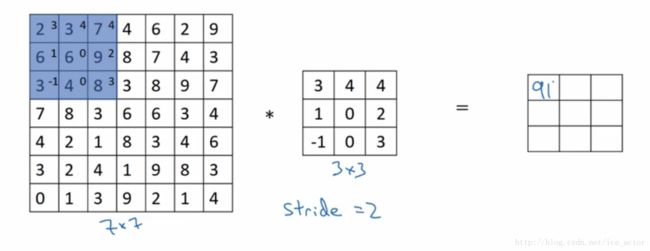
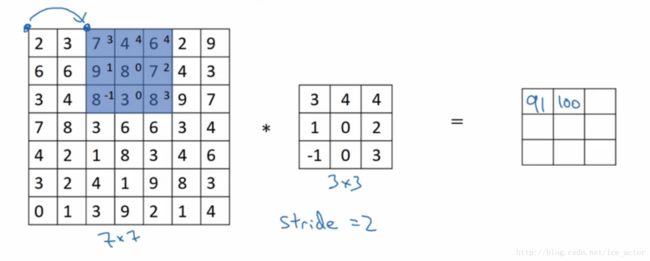
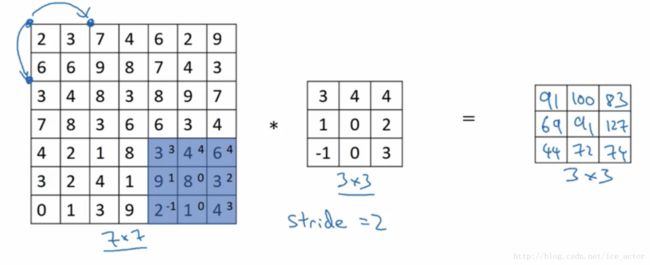
加入步长(stride)后卷积图像大小的通用计算公式为:
输入图像:nn,过滤器:ff步长:s,填充:p
输出图像大小为:

⌊⌋表示向下取整以输入图像77,过滤器33,步长为2,填充(padding)模式为没有填充(valid)时为例,输出图像大小为:
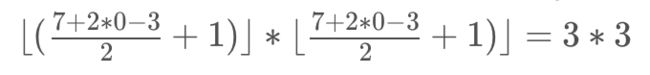
卷积处理彩色图片
以上讲述的卷积都是灰度图像的,如果想要在RGB图像上进行卷积,过滤器的大小不再是33而是333,最后的3对应为通道数(channels),卷积生成图像中每个像素值为333过滤器对应位置和图像对应位置相乘累加,过滤器依次在RGB图像上滑动,最终生成图像大小为44。
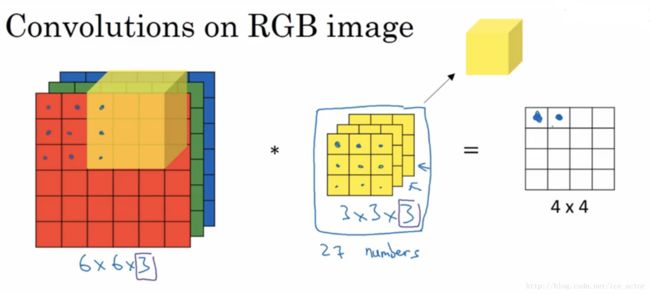
另外一个问题是,如果我们不仅仅在图像中检测一种类型的特征,而是要同时检测垂直边缘、水平边缘、45度边缘等等,也就是多个过滤器的问题。如果有两个过滤器,最终生成图像为442的立方体,这里的2来源于我们采用了两个过滤器。如果有10个过滤器那么输出图像就是4410的立方体。
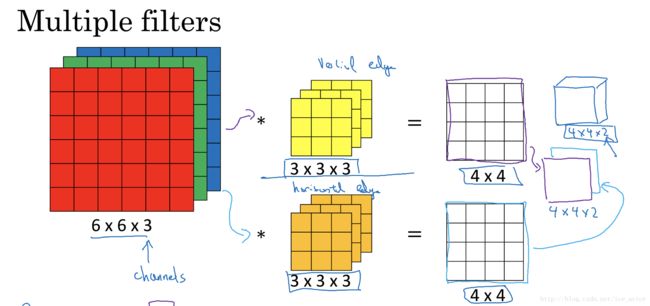
单层卷积网络
通过上一部分的讲述,图像通过两个过滤器得到了两个44的矩阵,在两个矩阵上分别加入偏差b1和b2,然后对加入偏差的矩阵做非线性的修正线性激活函数(Relu)变换,得到一个新的44矩阵,这就是单层卷积网络的完整计算过程。用公式表示:
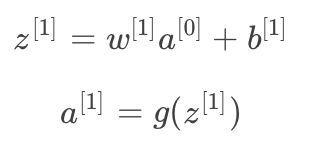
其中输入图像为a[0],过滤器用w[1]表示,对图像进行线性变化并加入偏差得到矩阵z[1],a[1]是应用修正线性激活函数(Relu)激活后的结果。
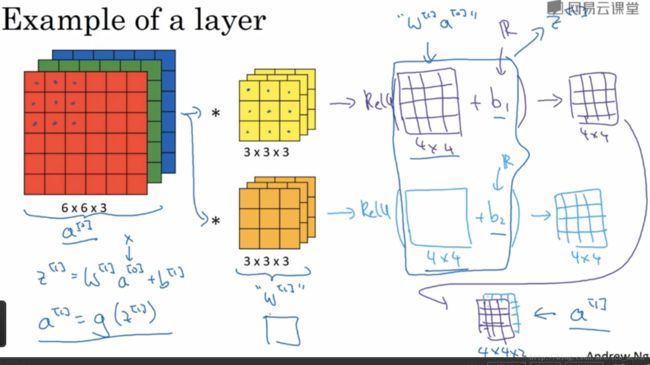
如果有10个过滤器参数个数有多少个呢? 每个过滤器都有333+1=28个参数,333为过滤器大小,1是偏差系数,10个过滤器参数个数就是28*10=280个。不论输入图像大小参数个数是不会发生改变的。
描述卷积神经网络的一些符号标识:

简单卷积网络
输入图像:39393,符号表示:
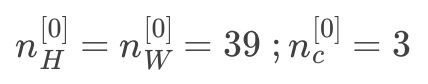
第1层超参数:
第1层输出图像:373710,符号表示:
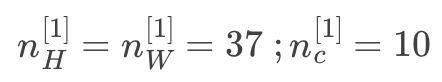
第2层超参数:
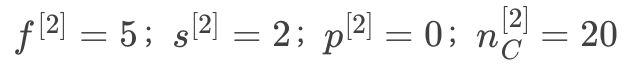
第2层输出图像:171720,符号表示:
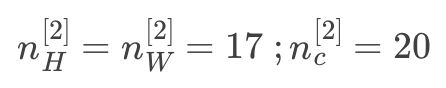
第3层超参数:
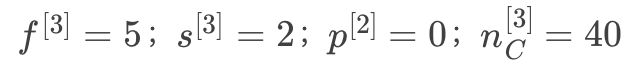
第3层输出图像:7740,符号表示:
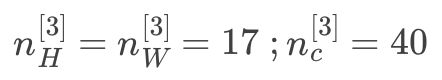
将第三层的输出展开成1960个元素,然后将其输出到二分类模型(logistic)或多分类模型(softmax)来决定是判断图片中有没有猫,还是想识别图像中不同的对象。

卷积神经网络层有三种类型:
卷积层(convolution,conv)
池化层(pooling,pool)
全连接层(Fully connected,FC)
池化层网络
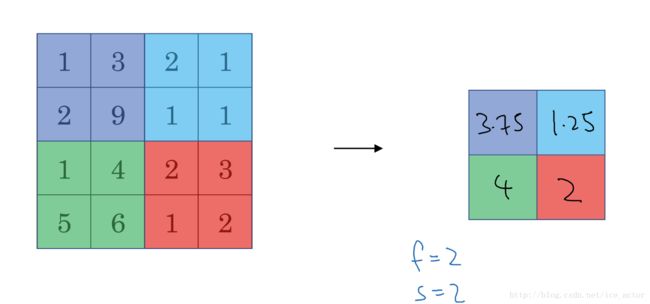
最大池化(Max pooling)的思想很简单,以下图为例,把44的图像分割成4个不同的区域,然后输出每个区域的最大值,这就是最大池化所做的事情。其实这里我们选择了22的过滤器,步长为2。在一幅真正的图像中提取最大值可能意味着提取了某些特定特征,比如垂直边缘、一只眼睛等等。
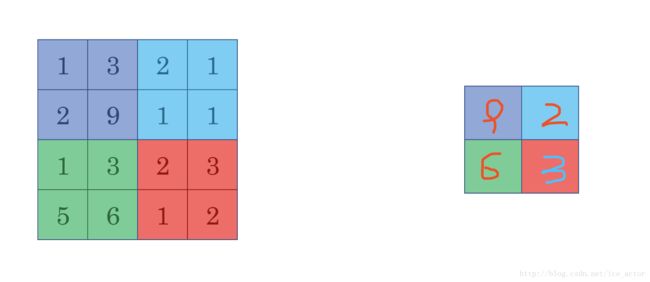
以下是一个过滤器大小为3*3,步长为1的池化过程,具体计算和上面相同,最大池化中输出图像的大小计算方式和卷积网络中计算方法一致,如果有多个通道需要做池化操作,那么就分通道计算池化操作。
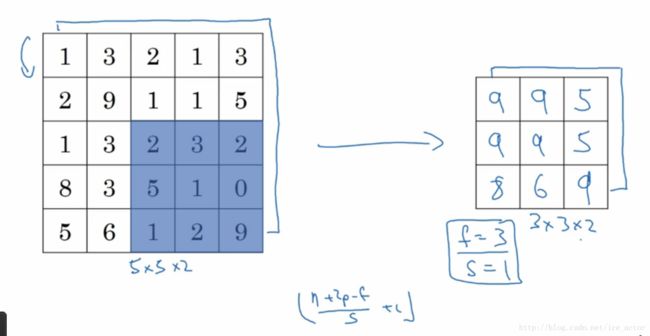
平均池化和最大池化唯一的不同是,它计算的是区域内的平均值而最大池化计算的是最大值。在日常应用使用最多的还是最大池化。
池化的超参数:步长、过滤器大小、池化类型(最大池化或平均池化)。
全连接层
在常见的卷积神经网络的最后往往会出现一两层全连接层,全连接一般会把卷积输出的二维特征图(feature map)转化成一维(N*1)的一个向量。或者说就是一排神经元,因为这一层是每一个单元都和前一层的每一个单元相连接,所以称之为“全连接”。
在经过数次卷积和池化之后,我们最后会先将多维的数据进行“扁平化”,也就是把7740的卷积层压缩成长度为7740=1960的一维数组,然后再与全连接(FC)层连接,这之后就跟普通的神经网络无异了。
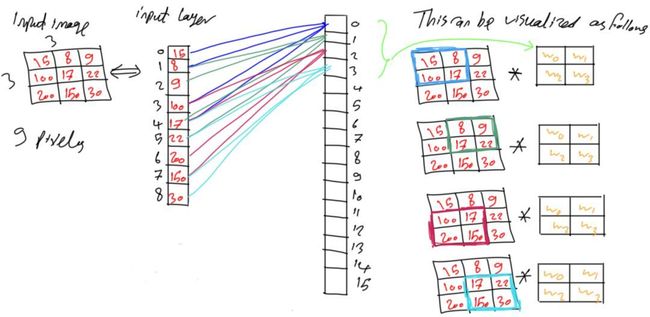
假设这里每次移动的步长设置为1(步长可以自己设置),每次相乘后将像素点索引移动一位,权重矩阵与另外一组像素相乘。以此类推,直到整个像素矩阵都与权重矩阵进行了相乘运算。整个过程与卷积运算相同,组的权重与图像矩阵之间进行卷积运算,这也是卷积神经网络(CNN)有“卷积”一词的原因。
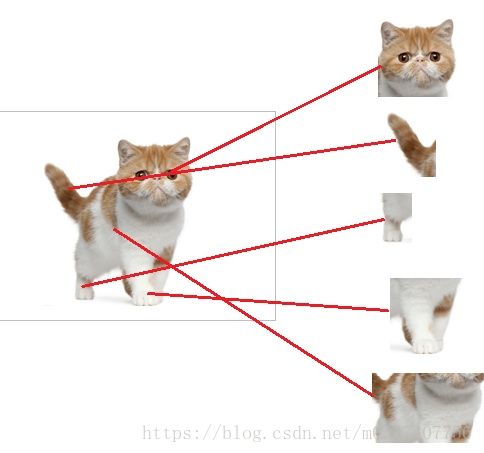
全连接层之前的卷积层、池化层作用是提取特征,全连接层的作用是分类,具体是怎么分类的呢?就是用到了数学中的概率统计等算法,这里就不深入说明了。假设,我们现在的任务是去区别一张图片是不是猫。

再假设,这个神经网络模型已经训练完了,全连接层已经知道猫的特征。
当我们得到以上特征,我们就可以判断这张图片是猫了,因为全连接层的作用主要就是实现分类(Classification),从下图,我们可以看出红色的神经元表示这个特征被找到了(激活了),同一层的其他神经元,要么猫的特征不明显,要么没找到。
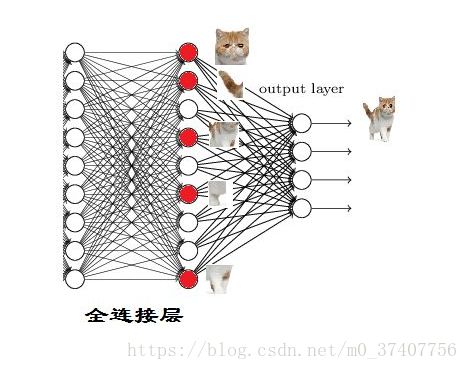
当我们把这些找到的特征组合在一起,发现最符合要求的是猫,那么我们可以认为这是猫了,猫头有下面这些特征。
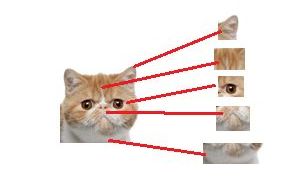
于是我们下一步的任务就是把猫头的这些特征找到,比如眼睛、耳朵。
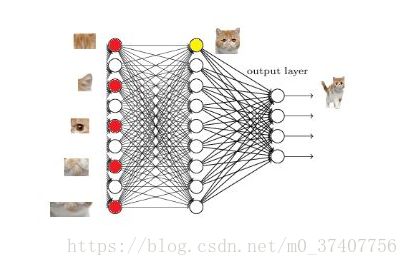
当我们找到这些特征,神经元就被激活了(红色圆圈),这细节特征又是怎么来的呢?就是从前面的卷积层、池化层来的。
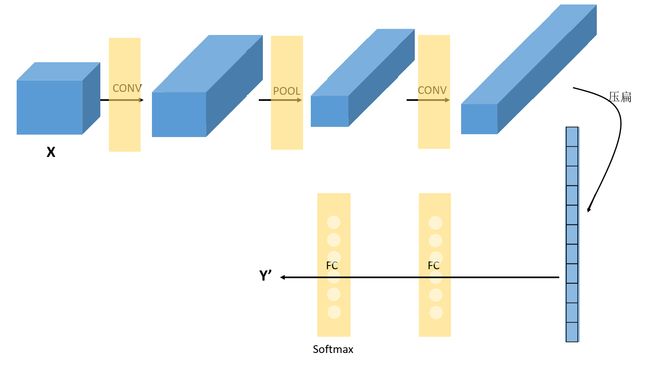
卷积神经网络
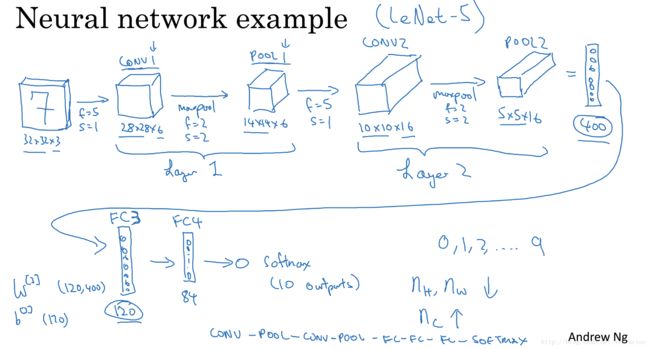
以下是一个完整的卷积神经网络,用于手写字识别,这并不是一个LeNet-5网络,但是设计需求来自于LeNet-5。
LeNet-5卷积神经网络模型,是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。
网络各层参数个数表:
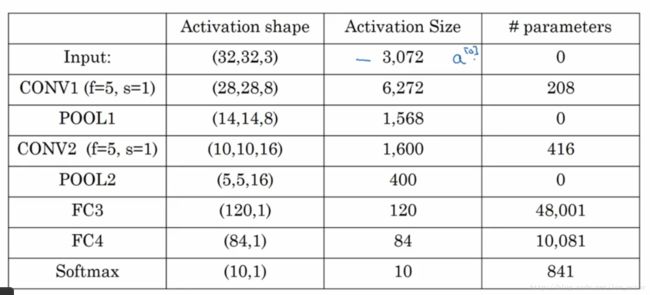
上面的数表中,CONV表示卷积层,POOL表示池化层,FC表示全连接层。
参考内容
https://www.cnblogs.com/kex1n/p/9083024.html
https://blog.csdn.net/ice_actor/article/details/78648780
https://blog.csdn.net/m0_37407756/article/details/80904580
http://www.dataguru.cn/article-13436-1.html
https://www.jianshu.com/p/c0215d26d20a
https://blog.csdn.net/weixin_38208741/article/details/80615580
https://www.cnblogs.com/alexcai/p/5506806.html