限流(Rate Limiting,即速率限制)通过限制每个用户调用API的频率来防止API被过度使用,这可以防止他们因疏忽或恶意导致的API滥用。在没有速率限制的情况下,每个用户可以随心所欲地请求,这可能会导致“峰值”请求,从而导致其他用户得不到响应。在启用速率限制之后,它们的请求将被限制为每秒固定的数量。
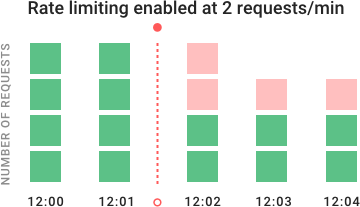
在示例图表中,你可以看到速率限制如何在一段时间内阻塞请求。API最初每分钟接收4个请求,用绿色表示。当12:02启用速率限制时,以红色显示的其他请求将被拒绝。速率限制对于公共API是非常重要的,因为你想要为每个消费者(API调用者)维护良好的服务质量,即使有些用户获取了超出其公平配额的服务。计算密集型的端点特别需要速率限制——特别是通过自动伸缩或AWS Lambda和OpenWhisk等按计算付费服务来提供服务时。你还可能希望对提供敏感数据的API进行评级,因为如果攻击者在某些不可预见的事件中获得访问权限,这可能会限制暴露的数据。实际上有许多不同的方法来实现速率限制,我们将探讨不同速率限制算法的优缺点。我们还将探讨跨集群扩展时出现的问题。最后,我们将向你展示一个如何使用Kong快速设置速率限制的示例,Kong是最流行的开源API网关。
速度限制算法
有各种各样的速率限制算法,每一种都有自己的优点和缺点。让我们回顾一下,这样你就可以根据自己的需要选择最好的限流算法。
漏桶算法
漏桶算法(Leaky Bucket,与令牌桶密切相关)是这样一种算法,它提供了一种简单、直观的方法来通过队列限制速率,你可以将队列看作一个存储请求的桶。当一个请求被注册时,它被附加到队列的末尾。每隔一段时间处理队列上的第一项。这也称为先进先出(FIFO)队列。如果队列已满,则丢弃(或泄漏)其他请求。

这种算法的优点是它可以平滑请求的爆发,并以近似平均的速度处理它们。它也很容易在单个服务器或负载均衡器上实现,并且在有限的队列大小下对于每个用户都是内存有效的。然而,突发的访问量会用旧的请求填满队列,并使最近的请求无法被处理。它也不能保证在固定的时间内处理请求。此外,如果为了容错或增加吞吐量而负载平衡服务器,则必须使用策略来协调和强制它们之间的限制。稍后我们将讨论分布式环境的挑战。
固定窗口算法
在固定窗口(Fixed Window)算法中,使用n秒的窗口大小(通常使用对人类友好的值,如60秒或3600秒)来跟踪速率。每个传入的请求都会增加窗口的计数器。如果计数器超过阈值,则丢弃请求。窗口通常由当前时间戳的层定义,因此12:00:03的窗口长度为60秒,应该在12:00:00的窗口中。

这种算法的优点是,它可以确保处理更多最近的请求,而不会被旧的请求饿死。然而,发生在窗口边界附近的单个流量突发会导致处理请求的速度增加一倍,因为它允许在短时间内同时处理当前窗口和下一个窗口的请求。另外,如果许多消费者等待一个重置窗口,例如在一个小时的顶部,那么他们可能同时扰乱你的API。
滑动日志算法
滑动日志(Sliding Log)速率限制涉及到跟踪每个使用者请求的时间戳日志。这些日志通常存储在按时间排序的散列集或表中。时间戳超过阈值的日志将被丢弃。当新请求出现时,我们计算日志的总和来确定请求率。如果请求将超过阈值速率,则保留该请求。

该算法的优点是不受固定窗口边界条件的限制,速率限制将严格执行。此外,因为滑动日志是针对每个消费者进行跟踪的,所以不会出现对固定窗口造成挑战的踩踏效应。但是,为每个请求存储无限数量的日志可能非常昂贵。它的计算成本也很高,因为每个请求都需要计算使用者先前请求的总和,这些请求可能跨越一个服务器集群。因此,它不能很好地处理大规模的流量突发或拒绝服务攻击。
滑动窗口
这是一种将固定窗口算法的低处理成本与改进的滑动日志边界条件相结合的混合方法。与固定窗口算法一样,我们跟踪每个固定窗口的计数器。接下来,我们根据当前的时间戳计算前一个窗口请求率的加权值,以平滑突发的流量。例如,如果当前窗口通过了25%,那么我们将前一个窗口的计数加权为75%。跟踪每个键所需的相对较少的数据点允许我们在大型集群中扩展和分布。

我们推荐使用滑动窗口方法,因为它可以灵活地调整速率限制,并且具有良好的性能。速率窗口是它向API消费者提供速率限制数据的一种直观方式。它还避免了漏桶的饥饿问题和固定窗口实现的突发问题。
分布式系统中的速率限制
同步策略如果希望在使用多个节点的集群时实施全局速率限制,则必须设置策略来实施该限制。如果每个节点都要跟踪自己的速率限制,那么当请求被发送到不同节点时,使用者可能会超过全局速率限制。实际上,节点的数量越大,用户越有可能超过全局限制。执行此限制的最简单方法是在负载均衡器中设置粘性会话,以便每个使用者都被精确地发送到一个节点。缺点包括缺乏容错性和节点过载时的缩放问题。允许更灵活的负载平衡规则的更好解决方案是使用集中的数据存储,如Redis或Cassandra。这将存储每个窗口和消费者的计数。这种方法的两个主要问题是增加了向数据存储发出请求的延迟,以及竞争条件(我们将在下面讨论)。
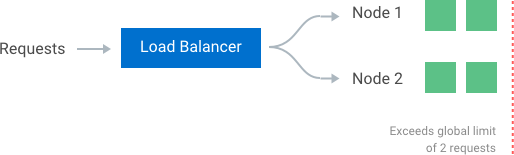
竞态条件
集中式数据存储的最大问题之一是高并发请求模式中的竞争条件。当你使用一种简单的“get-then-set”方法时,就会发生这种情况,在这种方法中,你检索当前速率限制计数器,增加它的值,然后将其推回到数据存储中。这个模型的问题是,在执行一个完整的读递增存储周期时,可能会出现额外的请求,每个请求都试图用无效的(较低的)计数器值存储递增计数器。这允许使用者发送非常高的请求率来绕过速率限制控制。

避免这个问题的一种方法是在有问题的密钥周围放置一个“锁”,防止任何其他进程访问或写入计数器。这将很快成为一个主要的性能瓶颈,而且伸缩性不好,特别是在使用诸如Redis之类的远程服务器作为备份数据存储时。更好的方法是使用“先设置后获取”的心态,依赖于原子操作符,它们以一种非常高性能的方式实现锁,允许你快速增加和检查计数器值,而不让原子操作成为障碍。
性能优化
使用集中式数据存储的另一个缺点是,在检查速率限制计数器时增加了延迟。不幸的是,即使是检查像Redis这样的快速数据存储,也会导致每个请求增加毫秒的延迟。为了以最小的延迟确定这些速率限制,有必要在内存中进行本地检查。这可以通过放松速率检查条件和使用最终一致的模型来实现。例如,每个节点可以创建一个数据同步周期,该周期将与中央数据存储同步。每个节点定期将每个使用者的计数器增量和它看到的窗口推送到数据存储,数据存储将自动更新这些值。然后,节点可以检索更新后的值来更新其内存版本。集群内节点之间的这种收敛→发散→再收敛的循环最终是一致的。

节点聚合的周期速率应该是可配置的。当流量分布在群集中的多个节点上时(例如,当坐在一个轮询调度平衡器后面时),较短的同步间隔将导致较少的数据点分散,而较长的同步间隔将对数据存储施加较小的读/写压力,更少的开销在每个节点上获取新的同步值。
使用Kong快速设置速率限制
Kong是一个开源的API网关,它使构建具有速率限制的可伸缩服务变得非常容易。它被全球超过300,000个活动实例使用。它可以完美地从单个的Kong节点扩展到大规模的、跨越全球的Kong集群。Kong位于API前面,是上游API的主要入口。在处理请求和响应时,Kong将执行你决定添加到API中的任何插件。
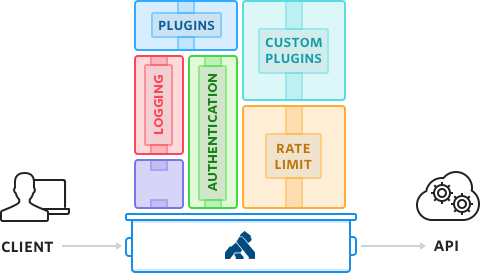
Kong的速率限制插件是高度可配置的。它提供了为每个API和消费者定义多个速率限制窗口和速率的灵活性。它支持本地内存、Redis、Postgres和Cassandra备份数据存储。它还提供了各种数据同步选项,包括同步和最终一致的模型。你可以在其中一台开发机器上快速安装Kong来测试它。我最喜欢的入门方式是使用AWS云形成模板,因为只需几次单击就可以获得预先配置好的开发机器。只需选择一个HVM选项,并将实例大小设置为使用t2.micro,这些对于测试都是负担得起的。然后ssh到新实例上的命令行进行下一步。
在Kong上添加API
下一步是使用Kong的admin API在Kong上添加一个API。我们将使用httpbin作为示例,它是一个针对API的免费测试服务。get URL将把我的请求数据镜像成JSON。我们还假设Kong在本地系统上的默认端口上运行。
curl -i -X POST \
--url http://localhost:8001/apis/ \
--data 'name=test' \
--data 'uris=/test' \
--data 'upstream_url=http://httpbin.org/get'
现在Kong意识到每个发送到“/test”的请求都应该代理到httpbin。我们可以向它的代理端口上的Kong发出以下请求来测试它:
curl http://localhost:8000/test
{
"args": {},
"headers": {
"Accept": "*/*",
"Connection": "close",
"Host": "httpbin.org",
"User-Agent": "curl/7.51.0",
"X-Forwarded-Host": "localhost"
},
"origin": "localhost, 52.89.171.202",
"url": "http://localhost/get"
}
它还是好的!Kong已经接收了请求并将其代理到httpbin,httpbin已将我的请求头和我的原始IP地址进行了镜像。
添加基本的速率限制
让我们继续,通过使用社区版的限速插件[1]添加限速功能来保护它不受过多请求的影响,每个消费者每分钟只能发出5个请求:
curl -i -X POST http://localhost:8001/apis/test/plugins/ \
-d "name=rate-limiting" \
-d "config.minute=5"
如果我们现在发出超过5个请求,Kong会回复以下错误信息:
curl http://localhost:8000/test
{
"message":"API rate limit exceeded"
}
看上去不错!我们在Kong上添加了一个API,并且仅在两个HTTP请求中向Kong的admin API添加了速率限制。它默认使用固定的窗口来限制IP地址的速率,并使用默认的数据存储在集群中的所有节点之间进行同步。有关其他选项,包括每个用户的速率限制或使用其他数据存储(如Redis),请参阅文档[1]。
企业版Kong,更好的性能
企业版[2]的速率限制增加了对滑动窗口算法的支持,以更好地控制和性能。滑动窗口可以防止你的API在窗口边界附近重载,如上面的部分所述。对于低延迟,它使用计数器的内存表,可以使用异步或同步更新跨集群进行同步。这提供了本地阈值的延迟,并且可以跨整个集群扩展。第一步是安装企业版的Kong。然后,可以配置速率限制、以秒为单位的窗口大小和同步计数器值的频率。它真的很容易使用,你可以得到这个强大的控制与一个简单的API调用:
curl -i -X POST http://localhost:8001/apis/test/plugins \
-d "name=rate-limiting" \
-d "config.limit=5" \
-d "config.window_size=60" \
-d "config.sync_rate=10"
企业还增加了对Redis Sentinel的支持,这使得Redis高可用性和更强的容错能力。你可以阅读更多的企业速率限制插件文档。