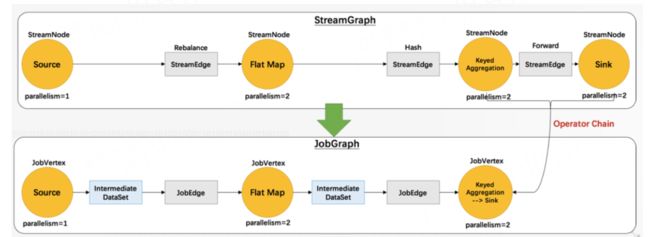
编译阶段生成JobGraph
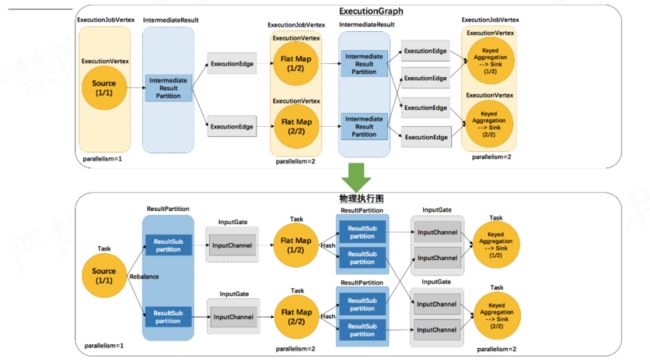
运行阶段生成调度ExecutionGraph
task 数据之间的传输

- 上图代表了一个简单的 map-reduce 类型的作业,有两个并行的任务。有两个 TaskManager,每个 TaskManager 都分别运行一个 map Task 和一个 reduce Task。我们重点观察 M1 和 R2 这两个 Task 之间的数据传输的发起过程。数据传输用粗箭头表示,消息用细箭头表示。首先,M1 产出了一个 ResultPartition(RP1)(箭头1)。当这个 RP 可以被消费是,会告知 JobManager(箭头2)。JobManager 会通知想要接收这个 RP 分区数据的接收者(tasks R1 and R2)当前分区数据已经准备好。如果接受放还没有被调度,这将会触发对应任务的部署(箭头 3a,3b)。接着,接受方会从 RP 中请求数据(箭头 4a,4b)。这将会初始化 Task 之间的数据传输(5a,5b),数据传输可能是本地的(5a),也可能是通过 TaskManager 的网络栈进行(5b)
-
对于一个 RP 什么时候告知 JobManager 当前已经出于可用状态,在这个过程中是有充分的自由度的:例如,如果在 RP1 在告知 JM 之前已经完整地产出了所有的数据(甚至可能写入了本地文件),那么相应的数据传输更类似于 Batch 的批交换;如果 RP1 在第一条记录产出时就告知 JM,那么就是 Streaming 流交换。
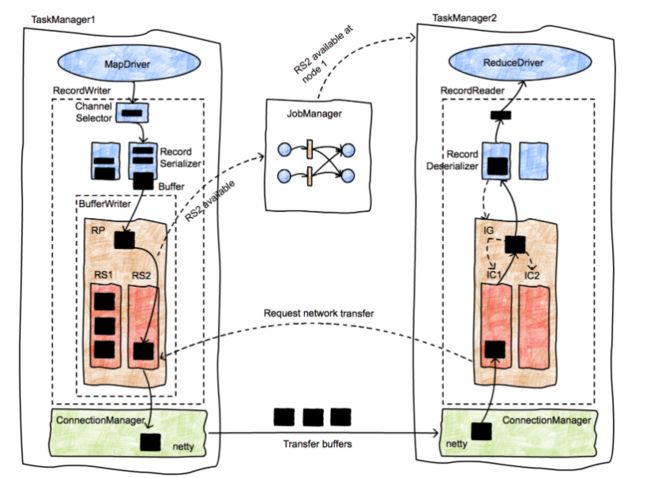 image.png
image.png -
ResultPartition as RP和ResultSubpartition as RS
ExecutionGraph 还是 JobManager 中用于描述作业拓扑的一种逻辑上的数据结构,其中表示并行子任务的ExecutionVertex会被调度到TaskManager中执行,一个 Task 对应一个 ExecutionVertex。同 ExecutionVertex 的输出结果 IntermediateResultPartition 相对应的则是ResultPartition。IntermediateResultPartition 可能会有多个 ExecutionEdge 作为消费者,那么在 Task 这里,ResultPartition 就会被拆分为多个ResultSubpartition,下游每一个需要从当前 ResultPartition 消费数据的 Task 都会有一个专属的ResultSubpartition。
ResultPartitionType指定了ResultPartition的不同属性,这些属性包括是否流水线模式、是否会产生反压以及是否限制使用的 Network buffer 的数量。enum ResultPartitionType有三个枚举值:
BLOCKING:非流水线模式,无反压,不限制使用的网络缓冲的数量
PIPELINED:流水线模式,有反压,不限制使用的网络缓冲的数量
PIPELINED_BOUNDED:流水线模式,有反压,限制使用的网络缓冲的数量 -
InputGate as IG和InputChannel as IC
在Task中,InputGate是对输入的封装,InputGate是和JobGraph中JobEdge一一对应的。也就是说,InputGate实际上对应的是该Task依赖的上游算子(包含多个并行子任务),每个InputGate消费了一个或多个ResultPartition。InputGate由InputChannel构成,InputChannel和ExecutionEdge一一对应;也就是说,InputChannel和ResultSubpartition一一相连,一个InputChannel接收一个ResultSubpartition的输出。根据读取的ResultSubpartition的位置,InputChannel有LocalInputChannel和RemoteInputChannel两种不同的实现。
数据交换机制的分析
数据交换从本质上来说就是一个典型的生产者-消费者模型,上游算子生产数据到 ResultPartition 中,下游算子通过 InputGate 消费数据。由于不同的 Task 可能在同一个 TaskManager 中运行,也可能在不同的 TaskManager 中运行:对于前者,不同的 Task 其实就是同一个 TaskManager 进程中的不同的线程,它们的数据交换就是在本地不同线程间进行的;对于后者,必须要通过网络进行通信,通过合理的设计和抽象,Flink 确保本地数据交换和通过网络进行数据交换可以复用同一套代码。
跨taskManager的反压

task输出
Task 产出的每一个 ResultPartition 都有一个关联的 ResultPartitionWriter,同时也都有一个独立的 LocalBufferPool负责提供写入数据所需的 buffer。ResultPartion 实现了 ResultPartitionWriter 接口
- ResultPartion #setup
Registers a buffer pool with this result partition.
There is one pool for each result partition, which is shared by all its sub partitions.
The pool is registered with the partition *after* it as been constructed in order to conform
to the life-cycle of task registrations in the {@link TaskExecutor}
ResultPartitionManager 会管理当前 Task 的所有 ResultPartition。
The result partition manager keeps track of all currently produced/consumed partitions of a task manager
@Override
public void setup() throws IOException {
checkState(this.bufferPool == null, "Bug in result partition setup logic: Already registered buffer pool.");
BufferPool bufferPool = checkNotNull(bufferPoolFactory.apply(this));
checkArgument(bufferPool.getNumberOfRequiredMemorySegments() >= getNumberOfSubpartitions(),
"Bug in result partition setup logic: Buffer pool has not enough guaranteed buffers for this result partition.");
this.bufferPool = bufferPool;
//ResultPartitionManager
partitionManager.registerResultPartition(this);
}
- Task#doRun#setupPartitionsAndGates
public static void setupPartitionsAndGates(
ResultPartitionWriter[] producedPartitions, InputGate[] inputGates) throws IOException, InterruptedException {
for (ResultPartitionWriter partition : producedPartitions) {
partition.setup();
}
// InputGates must be initialized after the partitions, since during InputGate#setup
// we are requesting partitions
for (InputGate gate : inputGates) {
gate.setup();
}
}
- ResultPartitionFactory#create#createSubpartitions()#initializeBoundedBlockingPartitions 在batch模式下会创建BoundedBlockingPartitions,spill文件;在stream模式创建下PipelinedSubpartition
private void createSubpartitions(
ResultPartition partition,
ResultPartitionType type,
BoundedBlockingSubpartitionType blockingSubpartitionType,
ResultSubpartition[] subpartitions) {
// Create the subpartitions.
if (type.isBlocking()) {
initializeBoundedBlockingPartitions(
subpartitions,
partition,
blockingSubpartitionType,
networkBufferSize,
channelManager);
} else {
for (int i = 0; i < subpartitions.length; i++) {
subpartitions[i] = new PipelinedSubpartition(i, partition);
}
}
}
private static void initializeBoundedBlockingPartitions(
ResultSubpartition[] subpartitions,
ResultPartition parent,
BoundedBlockingSubpartitionType blockingSubpartitionType,
int networkBufferSize,
FileChannelManager channelManager) {
int i = 0;
try {
for (i = 0; i < subpartitions.length; i++) {
final File spillFile = channelManager.createChannel().getPathFile();
subpartitions[i] = blockingSubpartitionType.create(i, parent, spillFile, networkBufferSize);
}
}
catch (IOException e) {
throw new FlinkRuntimeException(e);
}
}
RecordWriter
Task 通过 RecordWriter 将结果写入 ResultPartition 中,主要流程
1.通过 ChannelSelector 确定写入的目标 channel
2.使用 RecordSerializer 对记录进行序列化
3.向 ResultPartition 请求 BufferBuilder,用于写入序列化结果
4.向 ResultPartition 添加 BufferConsumer,用于读取写入 Buffer 的数据
public abstract class RecordWriter implements AvailabilityProvider {
ChannelSelectorRecordWriter extends RecordWriter
//决定一条记录应该写入哪一个channel, 即 sub-partition
private final ChannelSelector channelSelector;
//供每一个 channel 写入数据使用
private final BufferBuilder[] bufferBuilders;
protected final ResultPartitionWriter targetPartition;
//channel的数量,即 sub-partition的数量
protected final int numberOfChannels;
protected final RecordSerializer serializer;
protected final Random rng = new XORShiftRandom();
private Counter numBytesOut = new SimpleCounter();
private Counter numBuffersOut = new SimpleCounter();
private final boolean flushAlways;
/** The thread that periodically flushes the output, to give an upper latency bound. */
@Nullable
private final OutputFlusher outputFlusher;
ChannelSelectorRecordWriter#emit
public void emit(T record) throws IOException, InterruptedException {
emit(record, channelSelector.selectChannel(record));
}
protected void emit(T record, int targetChannel) throws IOException, InterruptedException {
checkErroneous();
serializer.serializeRecord(record);
// Make sure we don't hold onto the large intermediate serialization buffer for too long
if (copyFromSerializerToTargetChannel(targetChannel)) {
serializer.prune();
}
}
protected boolean copyFromSerializerToTargetChannel(int targetChannel) throws IOException, InterruptedException {
// We should reset the initial position of the intermediate serialization buffer before
// copying, so the serialization results can be copied to multiple target buffers.
serializer.reset();
boolean pruneTriggered = false;
BufferBuilder bufferBuilder = getBufferBuilder(targetChannel);
SerializationResult result = serializer.copyToBufferBuilder(bufferBuilder);
//buffer 写满了,调用 finishBufferBuilder方法
while (result.isFullBuffer()) {
finishBufferBuilder(bufferBuilder);
// If this was a full record, we are done. Not breaking out of the loop at this point
// will lead to another buffer request before breaking out (that would not be a
// problem per se, but it can lead to stalls in the pipeline).
if (result.isFullRecord()) {
pruneTriggered = true;
emptyCurrentBufferBuilder(targetChannel);
break;
}
bufferBuilder = requestNewBufferBuilder(targetChannel);
result = serializer.copyToBufferBuilder(bufferBuilder);
}
checkState(!serializer.hasSerializedData(), "All data should be written at once");
if (flushAlways) {
flushTargetPartition(targetChannel);
}
return pruneTriggered;
}
public BufferBuilder requestNewBufferBuilder(int targetChannel) throws IOException, InterruptedException {
checkState(bufferBuilders[targetChannel] == null || bufferBuilders[targetChannel].isFinished());
//从 LocalBufferPool 中请求 BufferBuilder,就是上面提到的ResultPartition的bufferPool
BufferBuilder bufferBuilder = targetPartition.getBufferBuilder();
//添加一个BufferConsumer,用于读取写入到 MemorySegment 的数据
targetPartition.addBufferConsumer(bufferBuilder.createBufferConsumer(), targetChannel);
bufferBuilders[targetChannel] = bufferBuilder;
return bufferBuilder;
}
向 ResultPartition 添加一个 BufferConsumer, ResultPartition 会将其转交给对应的 ResultSubpartition,消费ResultSubpartition的数据
ResultPartition implements ResultPartitionWriter, BufferPoolOwner
public boolean addBufferConsumer(BufferConsumer bufferConsumer, int subpartitionIndex) throws IOException {
checkNotNull(bufferConsumer);
ResultSubpartition subpartition;
try {
checkInProduceState();
subpartition = subpartitions[subpartitionIndex];
}
catch (Exception ex) {
bufferConsumer.close();
throw ex;
}
return subpartition.add(bufferConsumer);
}
对于 Streaming 模式 PipelinedSubpartition#add 实现,通知taskmanager数据可用,可以消费,在强制进行 flush 的时候,也会发出数据可用的通知,这是因为,假如产出的数据记录较少无法完整地填充一个 MemorySegment,那么 ResultSubpartition 可能会一直处于不可被消费的状态,在 RecordWriter 中有一个 OutputFlusher 会定时触发 flush,间隔可以通过 DataStream.setBufferTimeout() 来控制。
private boolean add(BufferConsumer bufferConsumer, boolean finish) {
checkNotNull(bufferConsumer);
final boolean notifyDataAvailable;
synchronized (buffers) {
if (isFinished || isReleased) {
bufferConsumer.close();
return false;
}
// Add the bufferConsumer and update the stats
buffers.add(bufferConsumer);
updateStatistics(bufferConsumer);
increaseBuffersInBacklog(bufferConsumer);
notifyDataAvailable = shouldNotifyDataAvailable() || finish;
isFinished |= finish;
}
if (notifyDataAvailable) {
notifyDataAvailable();
}
return true;
}
private class OutputFlusher extends Thread {
private final long timeout;
private volatile boolean running = true;
OutputFlusher(String name, long timeout) {
super(name);
setDaemon(true);
this.timeout = timeout;
}
public void terminate() {
running = false;
interrupt();
}
@Override
public void run() {
try {
while (running) {
try {
Thread.sleep(timeout);
} catch (InterruptedException e) {
// propagate this if we are still running, because it should not happen
// in that case
if (running) {
throw new Exception(e);
}
}
// any errors here should let the thread come to a halt and be
// recognized by the writer
flushAll();
}
} catch (Throwable t) {
notifyFlusherException(t);
}
}
}
task输入
前面已经介绍过,Task 的输入被抽象为 InputGate, 而 InputGate 则由 InputChannel 组成, InputChannel 和该 Task 需要消费的 ResultSubpartition 是一一对应的。如物理执行图所示
- Task 通过循环调用
InputGate.getNextBufferOrEvent方法获取输入数据,并将获取的数据交给它所封装的算子进行处理,这构成了一个 Task 的基本运行逻辑。 InputGate 有两个具体的实现,分别为 SingleInputGate 和 UnionInputGate, UnionInputGate 有多个 SingleInputGate 联合构成 - InputGate 相当于是对 InputChannel 的一层封装,实际数据的获取还是要依赖于 InputChannel。
SingleInputGate impl InputGatenotifyChannelNonEmpty
SingleInputGate.java
/**用于接收输入的缓冲池 Buffer pool for incoming buffers. Incoming data from remote channels is copied to buffers from this pool.*/
private BufferPool bufferPool;
/** InputChannel 构成的队列,这些 InputChannel 中都有有可供消费的数据 Channels, which notified this input gate about available data. */
private final ArrayDeque inputChannelsWithData = new ArrayDeque<>();
/** The number of input channels (equivalent to the number of consumed partitions). */
private final int numberOfInputChannels;
private Optional getNextBufferOrEvent(boolean blocking) throws IOException, InterruptedException {
if (hasReceivedAllEndOfPartitionEvents) {
return Optional.empty();
}
if (closeFuture.isDone()) {
throw new CancelTaskException("Input gate is already closed.");
}
Optional> next = waitAndGetNextData(blocking);
if (!next.isPresent()) {
return Optional.empty();
}
InputWithData inputWithData = next.get();
return Optional.of(transformToBufferOrEvent(
inputWithData.data.buffer(),
inputWithData.moreAvailable,
inputWithData.input));
}
private Optional> waitAndGetNextData(boolean blocking)
throws IOException, InterruptedException {
while (true) {
Optional inputChannel = getChannel(blocking);
if (!inputChannel.isPresent()) {
return Optional.empty();
}
// Do not query inputChannel under the lock, to avoid potential deadlocks coming from
// notifications.
Optional result = inputChannel.get().getNextBuffer();
synchronized (inputChannelsWithData) {
if (result.isPresent() && result.get().moreAvailable()) {
// enqueue the inputChannel at the end to avoid starvation
inputChannelsWithData.add(inputChannel.get());
enqueuedInputChannelsWithData.set(inputChannel.get().getChannelIndex());
}
if (inputChannelsWithData.isEmpty()) {
availabilityHelper.resetUnavailable();
}
if (result.isPresent()) {
return Optional.of(new InputWithData<>(
inputChannel.get(),
result.get(),
!inputChannelsWithData.isEmpty()));
}
}
}
}
从inputChannelsWithData ArrayDeque 里获取有数据的channel
private Optional getChannel(boolean blocking) throws InterruptedException {
synchronized (inputChannelsWithData) {
while (inputChannelsWithData.size() == 0) {
if (closeFuture.isDone()) {
throw new IllegalStateException("Released");
}
if (blocking) {
// 如果没有有数据的channel,则当前线程wait,阻塞
inputChannelsWithData.wait();
}
else {
availabilityHelper.resetUnavailable();
return Optional.empty();
}
}
InputChannel inputChannel = inputChannelsWithData.remove();
enqueuedInputChannelsWithData.clear(inputChannel.getChannelIndex());
return Optional.of(inputChannel);
}
}
//当一个 InputChannel 有数据时的回调,这个就是在 rs 通知数据可用时候调用的函数
void notifyChannelNonEmpty(InputChannel channel) {
queueChannel(checkNotNull(channel));
}
private void queueChannel(InputChannel channel) {
int availableChannels;
CompletableFuture toNotify = null;
synchronized (inputChannelsWithData) {
if (enqueuedInputChannelsWithData.get(channel.getChannelIndex())) {
return;
}
availableChannels = inputChannelsWithData.size();
// 添加有数据的channel
inputChannelsWithData.add(channel);
enqueuedInputChannelsWithData.set(channel.getChannelIndex());
if (availableChannels == 0) {
// 让刚才getchannel阻塞的线程被唤醒,消费channel
inputChannelsWithData.notifyAll();
toNotify = availabilityHelper.getUnavailableToResetAvailable();
}
}
if (toNotify != null) {
toNotify.complete(null);
}
}
启动inputgate
public void setup() throws IOException, InterruptedException {
checkState(this.bufferPool == null, "Bug in input gate setup logic: Already registered buffer pool.");
// assign exclusive buffers to input channels directly and use the rest for floating buffers
assignExclusiveSegments();
BufferPool bufferPool = bufferPoolFactory.get();
setBufferPool(bufferPool);
//请求分区
requestPartitions();
}
void requestPartitions() throws IOException, InterruptedException {
synchronized (requestLock) {
if (!requestedPartitionsFlag) {
if (closeFuture.isDone()) {
throw new IllegalStateException("Already released.");
}
// Sanity checks
if (numberOfInputChannels != inputChannels.size()) {
throw new IllegalStateException(String.format(
"Bug in input gate setup logic: mismatch between " +
"number of total input channels [%s] and the currently set number of input " +
"channels [%s].",
inputChannels.size(),
numberOfInputChannels));
}
// 遍历inputChannels,请求NettyConnectionManager ,下面讲解
for (InputChannel inputChannel : inputChannels.values()) {
inputChannel.requestSubpartition(consumedSubpartitionIndex);
}
}
requestedPartitionsFlag = true;
}
}
RemoteInputChannel # requestSubpartition
public void requestSubpartition(int subpartitionIndex) throws IOException, InterruptedException {
if (partitionRequestClient == null) {
// Create a client and request the partition
try {
// connectionManager 对象就是基于netty的
partitionRequestClient = connectionManager.createPartitionRequestClient(connectionId);
} catch (IOException e) {
// IOExceptions indicate that we could not open a connection to the remote TaskExecutor
throw new PartitionConnectionException(partitionId, e);
}
partitionRequestClient.requestSubpartition(partitionId, subpartitionIndex, this, 0);
}
}
InputChannel 的基本逻辑比较简单,它的生命周期按照 requestSubpartition(int subpartitionIndex), getNextBuffer() 和 releaseAllResources() 这样的顺序进行。
通过网络进行数据交换
- 在一个 TaskManager 中可能会同时并行运行多个 Task,每个 Task 都在单独的线程中运行。在不同的 TaskManager 中运行的 Task 之间进行数据传输要基于网络进行通信。实际上,是 TaskManager 和另一个 TaskManager 之间通过网络进行通信,通信是基于 Netty 创建的标准的 TCP 连接,同一个 TaskManager 内运行的不同 Task 会复用网络连接
- 在 Flink 中,不同 Task 之间的网络传输基于 Netty 实现NetworkEnvironment 中通过 ConnectionManager 来管理所有的网络的连接,而 NettyConnectionManager 就是 ConnectionManager 的具体实现。
NettyConnectionManager.java
@Override
public int start() throws IOException {
client.init(nettyProtocol, bufferPool);
return server.init(nettyProtocol, bufferPool);
}
NettyServer.java#init
当 RemoteInputChannel 请求一个远端的 ResultSubpartition 的时候,NettyClient 就会发起和请求的
ResultSubpartition 所在 Task 的 NettyServer 的连接,后续所有的数据交换都在这个连接上进行。两个 Task
之间只会建立一个连接,这个连接会在不同的 RemoteInputChannel 和 ResultSubpartition 之间进行复用
private void initNioBootstrap() {
// Add the server port number to the name in order to distinguish
// multiple servers running on the same host.
String name = NettyConfig.SERVER_THREAD_GROUP_NAME + " (" + config.getServerPort() + ")";
NioEventLoopGroup nioGroup = new NioEventLoopGroup(config.getServerNumThreads(), getNamedThreadFactory(name));
bootstrap.group(nioGroup).channel(NioServerSocketChannel.class);
}
netty级别的水位线,反压机制,配置水位线,确保不往网络中写入太多数据
1.当输出缓冲中的字节数超过高水位值, 则 Channel.isWritable() 会返回false
2.当输出缓存中的字节数低于低水位值, 则 Channel.isWritable() 会重新返回true
final int defaultHighWaterMark = 64 * 1024; // from DefaultChannelConfig (not exposed)
final int newLowWaterMark = config.getMemorySegmentSize() + 1;
final int newHighWaterMark = 2 * config.getMemorySegmentSize();
if (newLowWaterMark > defaultHighWaterMark) {
bootstrap.childOption(ChannelOption.WRITE_BUFFER_HIGH_WATER_MARK, newHighWaterMark);
bootstrap.childOption(ChannelOption.WRITE_BUFFER_LOW_WATER_MARK, newLowWaterMark);
} else { // including (newHighWaterMark < defaultLowWaterMark)
bootstrap.childOption(ChannelOption.WRITE_BUFFER_LOW_WATER_MARK, newLowWaterMark);
bootstrap.childOption(ChannelOption.WRITE_BUFFER_HIGH_WATER_MARK, newHighWaterMark);
}
RemoteInputChannel # requestSubpartition#partitionRequestClient = connectionManager.createPartitionRequestClient(connectionId)实现调用
public class NettyConnectionManager implements ConnectionManager {
@Override
public PartitionRequestClient createPartitionRequestClient(ConnectionID connectionId)
throws IOException, InterruptedException {
return partitionRequestClientFactory.createPartitionRequestClient(connectionId);
}
taskManager内部的反压
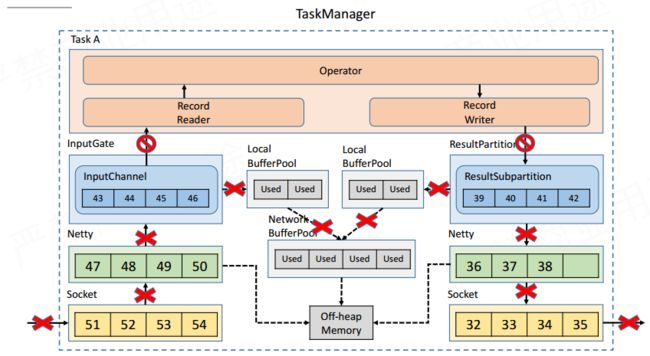
flink 动态反压实现
- Flink 在两个 Task 之间建立 Netty 连接进行数据传输,每一个 Task 会分配两个缓冲池,一个用于输出数据,一个用于接收数据。当一个 Task 的缓冲池用尽之后,网络连接就处于阻塞状态,上游 Task 无法产出数据,下游 Task 无法接收数据
- flink1.5之前的反压机制是通过tcp流控和bounded buffe 来实现反压,这种反压弊端是会直接阻塞tcp的网络通信,使正常的checkpoint barrier通信都无法进行,所以flink1.5之后实现了自己托管的credit based流控机制,在应用层模拟tcp流控机制
tcp流控:通过滑动窗口实现,socket sender和socket receiver,user-space-consumer
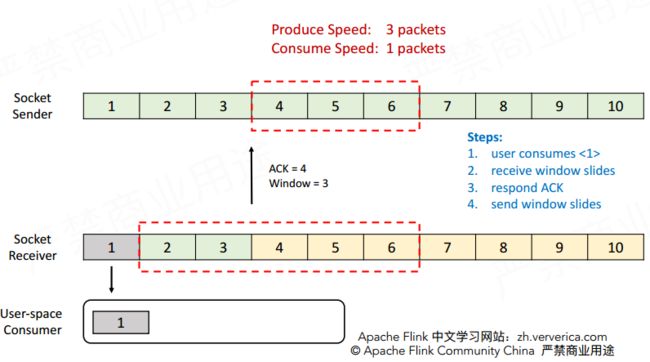 image.png
image.png
backlog生产者当前的积压
credit信用值就是接收端可用的 Buffer(MemorySegment 32k) 的数量,一个可用的 buffer 对应一点 credit
 image.png
image.png - 注意:Flink1.5 之后 会为每一个
InputChannel分配一批独占的缓冲(exclusive buffers=2),而本地缓冲池中的 buffer 则作为流动的(floating buffers=8),可以被所有的InputChannel使用。 -
taskmanager.network.memory.buffers-per-channel=2指定每个outgoing/incoming channel使用buffers数量In credit-based flow control mode, this indicates how many credits are exclusive in each input channel -
taskmanager.network.memory.floating-buffers-per-gate=8指定每个outgoing/incoming gate使用buffers数量,In credit-based flow control mode, this indicates how many floating credits are shared among all the input channels -
taskmanager.network.request-backoff.max指定input channels的partition requests的最大backoff时间(毫秒),默认为10000
Credit-based Flow Control 的具体机制为:
1.接收端向发送端声明可用的 Credit(一个可用的 buffer 对应一点 credit);
2.当发送端获得了 X 点 Credit,表明它可以向网络中发送 X 个 buffer;当接收端分配了 X 点 Credit 给发送端,表明它有 X 个空闲的 buffer 可以接收数据;
3.只有在 Credit > 0 的情况下发送端才发送 buffer;发送端每发送一个 buffer,Credit 也相应地减少一点
由于 CheckpointBarrier,EndOfPartitionEvent 等事件可以被立即处理,因而事件可以立即发送,无需使用 Credit
4.当发送端发送 buffer 的时候,它同样把当前堆积的 buffer 数量(backlog size)告知接收端;接收端根据发送端堆积的数量来申请 floating buffer
- 代码实现
SingleInputGate#setup()
@Override
public void setup() throws IOException, InterruptedException {
checkState(this.bufferPool == null, "Bug in input gate setup logic: Already registered buffer pool.");
// 请求独占的 buffer assign exclusive buffers to input channels directly and use the rest for floating buffers
assignExclusiveSegments();
BufferPool bufferPool = bufferPoolFactory.get();
//分配 LocalBufferPool 本地缓冲池,这是所有 channel 共享的
setBufferPool(bufferPool);
requestPartitions();
}
/*** Assign the exclusive buffers to all remote input channels directly for credit-based mode.*/
@VisibleForTesting
public void assignExclusiveSegments() throws IOException {
synchronized (requestLock) {
for (InputChannel inputChannel : inputChannels.values()) {
if (inputChannel instanceof RemoteInputChannel) {
((RemoteInputChannel) inputChannel).assignExclusiveSegments();
}
}
}
}
- netty 端消费reader
class CreditBasedPartitionRequestClientHandler extends ChannelInboundHandlerAdapter
CreditBasedPartitionRequestClientHandler#channelRead#decodeMsg#decodeBufferOrEvent#onBuffer
RemoteInputChannel#inputChannel.onBuffer(buffer, bufferOrEvent.sequenceNumber, bufferOrEvent.backlog)
public class RemoteInputChannel extends InputChannel implements BufferRecycler, BufferListener {
public void onBuffer(Buffer buffer, int sequenceNumber, int backlog) throws IOException {
boolean recycleBuffer = true;
try {
final boolean wasEmpty;
synchronized (receivedBuffers) {
// Similar to notifyBufferAvailable(), make sure that we never add a buffer
// after releaseAllResources() released all buffers from receivedBuffers
// (see above for details).
if (isReleased.get()) {
return;
}
if (expectedSequenceNumber != sequenceNumber) {
onError(new BufferReorderingException(expectedSequenceNumber, sequenceNumber));
return;
}
wasEmpty = receivedBuffers.isEmpty();
receivedBuffers.add(buffer);
recycleBuffer = false;
}
++expectedSequenceNumber;
if (wasEmpty) {
// 通知input gate channel不是空的
notifyChannelNonEmpty();
}
if (backlog >= 0) {
//根据客户端的积压申请float buffer
onSenderBacklog(backlog);
}
} finally {
if (recycleBuffer) {
buffer.recycleBuffer();
}
}
}
对应SingleInputGate#notifyChannelNonEmpty
void notifyChannelNonEmpty(InputChannel channel) {
queueChannel(checkNotNull(channel));
}
/*** Receives the backlog from the producer's buffer response. If the number of available
* buffers is less than backlog + initialCredit, it will request floating buffers from the buffer
* pool, and then notify unannounced credits to the producer.
backlog 是发送端的堆积 的 buffer 数量
如果 bufferQueue 中 buffer 的数量不足,就去须从 LocalBufferPool 中请求 floating buffer
在请求了新的 buffer 后,通知生产者有 credit 可用
* @param backlog The number of unsent buffers in the producer's sub partition.
*/
void onSenderBacklog(int backlog) throws IOException {
int numRequestedBuffers = 0;
synchronized (bufferQueue) {
// Similar to notifyBufferAvailable(), make sure that we never add a buffer
// after releaseAllResources() released all buffers (see above for details).
if (isReleased.get()) {
return;
}
numRequiredBuffers = backlog + initialCredit;
while (bufferQueue.getAvailableBufferSize() < numRequiredBuffers && !isWaitingForFloatingBuffers) {
Buffer buffer = inputGate.getBufferPool().requestBuffer();
if (buffer != null) {
bufferQueue.addFloatingBuffer(buffer);
numRequestedBuffers++;
} else if (inputGate.getBufferProvider().addBufferListener(this)) {
// If the channel has not got enough buffers, register it as listener to wait for more floating buffers.
isWaitingForFloatingBuffers = true;
break;
}
}
}
if (numRequestedBuffers > 0 && unannouncedCredit.getAndAdd(numRequestedBuffers) == 0) {
notifyCreditAvailable();
}
}
RemoteInputChannel.java 管理
private static class AvailableBufferQueue {
/** The current available floating buffers from the fixed buffer pool. */
private final ArrayDeque floatingBuffers;
/** The current available exclusive buffers from the global buffer pool. */
private final ArrayDeque exclusiveBuffers;
flink wiki文档
https://cwiki.apache.org/confluence/display/FLINK/Data+exchange+between+tasks
参考
https://blog.jrwang.me/2019/flink-source-code-data-exchange/#%E6%A6%82%E8%A7%88
https://blog.csdn.net/yidan7063/article/details/90260434
https://ververica.cn/developers/flink-network-protocol/
Task 和 OperatorChain
https://blog.jrwang.me/2019/flink-source-code-task-lifecycle/#task-%E5%92%8C-operatorchain