第一次将笔记部署在上,因为这次的部署心得体会比较深刻.仅作为自己的参考
一.基本配置:
1.jdk安装
安装依赖 yum -y install gcc openssl-devel pcre-devel zlib-devel
tar -zxvf jdk-8u60-linux-x64.tar.gz
vim etc/profile
一定要加在文件的末尾
export JAVA_HOME="/opt/jdk1.7.0_80"
export PATH="$JAVA_HOME/bin:$PATH"
刷新配置,让配置生效
source /etc/profile
验证是否成功# java -version

2.匹配host文件
vim /etc/host
3.配置秘钥
node 1
生成秘钥
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
生成的路径在: cd ~/.ssh/

解决原理: 必须要把秘钥追加到认证文件中去
~/.ssh/authorized_keys
将自己的公钥追加到自己的认证文件中去
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
如果要相互免密 ,必须相互放公钥到别人的认证文件中区
目的: node1 可以免密登录node3
将node1 下的公钥拷贝到node3下的认证文件中去
在node1 下面的.ssh 下面
scp~/.ssh/id_dsa.pub root@node3:/tmp/
然后再追加到认证文件中去
cat /tmp/id_dsa.pub >> ~/.ssh/authorized_keys
4.搭建环境主从环境
创建目录
mkdir -p /data/hdfs/name /data/hdfs/data /data/hdfs/tmp
将 data#hadoop-2.7.1.tar.gz 放到data下面
然后解压
data#tar -zxvf hadoop-2.7.1.tar.gz
配置环境变量
export HADOOP_HOME="/data/hadoop-2.7.5"
export PATH="$HADOOP_HOME/bin:$PATH"
# source /etc/profile
# hadoop
检测是否生效
5.更改相关的配置信息

1.core-site.xml
hadoop.tmp.dirfile:/data/hdfs/tmp A base for other temporary directories. io.file.buffer.size 131072 fs.default.namehdfs://node1:9000hadoop.proxyuser.root.hosts*hadoop.proxyuser.root.groups*
修改vim hdfs-site.xmldfs.replication2 dfs.namenode.name.dirfile:/data/hdfs/nametruedfs.datanode.data.dir file:/data/hdfs/data truedfs.namenode.secondary.http-address master:9001 dfs.webhdfs.enabled true dfs.permissionsfalse
修改vim mapred-site.xml
复制template,生成xml,命令如下:
# cp mapred-site.xml.template mapred-site.xml
# vim mapred-site.xml
mapreduce.framework.nameyarn
修改vim yarn-site.xml
# vim yarn-site.xml
yarn.resourcemanager.address node1:18040 yarn.resourcemanager.scheduler.address node1:18030 yarn.resourcemanager.webapp.address node1:18088 yarn.resourcemanager.resource-tracker.address node1:18025 yarn.resourcemanager.admin.address node1:18141 yarn.nodemanager.aux-services mapreduce.shuffle yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler
修改hadoop-env.sh与yarn-env.sh的JAVA_HOME的路径配置
将语句 export JAVA_HOME=$JAVA_HOME
修改为 export JAVA_HOME="/opt/jdk1.7.0_80"
和一开始配置的PATH路径一样就行
6.修改data/hadoop-2.7.1/etc/hadoop/slaves
将原来的localhost删除,改成如下内容
vim / data/hadoop-2.7.1/etc/hadoop/slaves

7.递归复制整个目录在node2 和node3上面
scp -r /data/hadoop-2.7.5 root@node2:/data/
scp -r /data/hadoop-2.7.5 root@node3:/data/
二.设置其他问题
格式化NameNode
# hadoop namenode -format
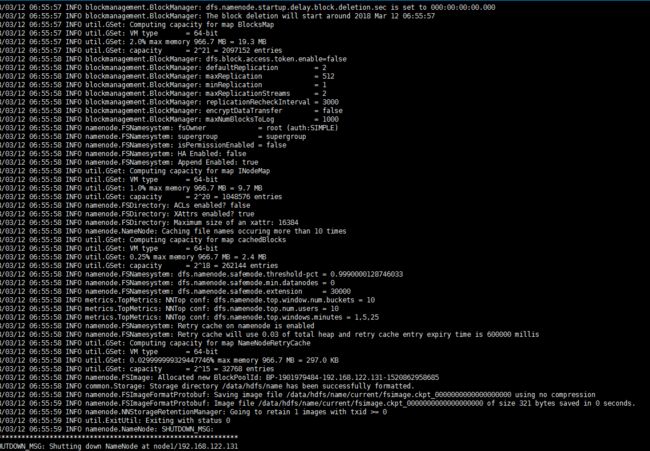
启动NameNode
# /data/hadoop-2.7.5/sbin/hadoop-daemon.sh start namenode
查看进程 ps -ef |grep hadoop

启动服务器
# /data/hadoop-2.7.5/sbin/start-all.sh 启动各服务期(注意关闭是stop-all.sh)
在Master上执行jps命令,得到如下结果:
#jps

在slave上的版本
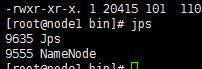
启动DataNode
执行命令如下:
# /data/hadoop-2.7.5/sbin/hadoop-daemons.sh start datanode

最后测试下亲手搭建的Hadoop集群是否执行正常,测试的命令如下图所示:
sbin/start-dfs.sh
查看集群状态
# /data/hadoop-2.7.5/bin/hdfs dfsadmin -report

最终检测
http://192.168.122.131:18088/cluster
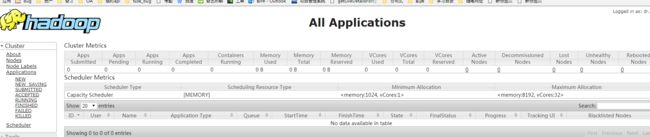
测试mapreduce
不想编写mapreduce代码。幸好Hadoop安装包里提供了现成的例子,在Hadoop的share/hadoop/mapreduce目录下。运行例子:
# /data/hadoop-2.7.5/bin/hadoop jar /data/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar pi 5 10

need-to-insert-img