- 常用参数
1.1 query
1.2 analyzer
1.3 auto_generate_synonyms_phrase_query
1.4 fuzziness
1.5 max_expansions
1.6 prefix_length
1.7 fuzzy_transpositions
1.8 fuzzy_rewrite
1.9 lenient
1.10 operator
1.11 minimum_should_match
1.12 zero_terms_query
match返回与提供的文本、数字、日期或bool匹配的文档。匹配之前对提供的文本进行分析(分词)。该match查询用于执行全文搜索的标准查询,其中包含模糊匹配的选项。
GET /_search
{
"query": {
"match": {
"message": {
"query": "this is a test"
}
}
}
}
1. 常用参数
1.1 query
- 必填
- 查询条件
- 希望在提供的
字段中找到的Text、number、boolean或者date类型。
match搜索之前,会将text进行分词操作,这意味着match操作搜索的是text分词后tokens,而不是确切的词。
2. analyzer
- 选填,字符串
- 分词器
- 若
的字段为text,则显示的指定query条件的分词器进行分词。若不指定,则使用 的分词器。


# 创建索引和映射关系(使用ik分词器)
PUT test_analyzer
{
"mappings": {
"properties" : {
"subject":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
# 默认字段分词器的分词结果
POST test_analyzer/_analyze
{
"field": "subject",
"text": "天下"
}
# 填充数据
POST test_analyzer/_doc
{
"subject":"天下"
}
# 使用标准分词器
POST test_analyzer/_search
{
"query": {
"match": {
"subject": {
"query": "天下",
"analyzer": "standard"
}
}
}
}
1.3 auto_generate_synonyms_phrase_query
- 可选,boolean
- 默认为true
- 会自动为多个术语同义词创建匹配词组查询
1.4 fuzziness
- 选填,字符串
- 模糊查询
-
匹配允许的最大编辑距离。
 image.png
image.png
1.5 max_expansions
- 选填,字符串
- 指定应考虑的最大匹配项数,默认50
- 作用在分片级别(即最终查询到的结果可能大于max_expansions的数量)
match_phrase_prefix 查询中有个参数 max_expansions 说的是参数 max_expansions 控制着可以与前缀匹配的词的数量,默认值是 50。
elasticsearch 全文搜索 match_phrase_prefix 查询中的 max_expansions 该怎么用?
PUT test_fuzz
{
"mappings": {
"properties": {
"name":{
"type": "text"
}
}
}
}
POST test_fuzz/_doc
{
"name":"go to smile"
}
POST test_fuzz/_doc
{
"name":"bye bye stal"
}
POST test_fuzz/_doc
{
"name":"haha school"
}
POST test_fuzz/_doc
{
"name":"sclo hp"
}
# 分片
GET test_fuzz/_search?routing=1
{
"query": {
"match_phrase_prefix": {
"name": {
"query": "s",
"max_expansions": 1
}
}
}
}
1.6 prefix_length
- 选填,整数
- 默认为0
prefix_length只能结合fuzziness使用;由于大部分的拼写错误发生在词的结尾,而不是词的开始。prefix_length表示进行模糊搜索的起始单词位置,即之前的必须完全匹配
prefix_length的含义

如上图所示,文档中存储的为sclo,但是query查询的为aclo,因为使用了prefix_length,clo后的数据才能进行模糊搜索,clo前的数据只能完成匹配。故查询不出来。
1.7 fuzzy_transpositions
- 可选,布尔值
如果true为,则模糊匹配的编辑内容包括两个相邻字符的变位(ab→ba)。默认为true。
1.8 fuzzy_rewrite
- 可选,字符串
用于重写查询的方法。高级用法。
如果fuzziness参数不是0,则match查询默认使用的fuzzy_rewrite 方法top_terms_blended_freqs_${max_expansions}。
1.9 lenient
- 可选,布尔值
- 默认false
如果为true,则将忽略基于格式的错误,例如为数字字段提供文本 query值。
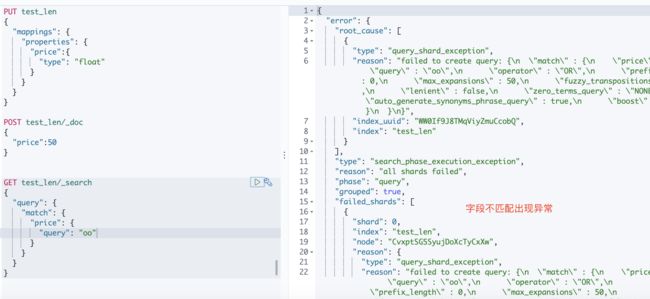

1.10 operator
- 可选,字符串
- 默认or
- 枚举值:or、and
用于解释query值中的文本。是or=任意匹配;and=同时匹配。
1.11 minimum_should_match
- 可选,字符串
要返回的文档必须匹配的最小子句数。
es7.x(6)—minimum_should_match最低匹配度
1.12 zero_terms_query
- 可选,字符串
指示如果analyzer 除去所有标记(例如使用stop过滤器时),是否不返回任何文档。有效值为:
none(默认)
如果analyzer删除所有标记,则不会返回任何文档。all
返回所有文档,类似于match_all 查询。
Zero terms Query查询


zero_terms_query 就是为了解决这个问题而生的。它的默认值是 none ,就是搜不到停止词(对 stop 分析器字段而言),如果设置成 all ,它的效果就和 match_all 类似,就可以搜到了。

# 创建索引和映射
PUT test_zero
{
"mappings": {
"properties": {
"message":{
"type": "text",
"analyzer": "stop"
}
}
}
}
# 搜索message,发现to be or not to be都是过滤器,解析结果为null
GET test_zero/_analyze
{
"field": "message",
"text": "to be or not to be"
}
# 填充数据
POST test_zero/_doc
{
"message":"to be or not to be"
}
POST test_zero/_doc
{
"message":"hahah"
}
GET test_zero/_search
{
"query": {
"match": {
"message": {
"query": "to be or not to be",
"zero_terms_query": "all"
}
}
}
}
推荐阅读
Elasticsearch7.x Match query官方文档