I.优质内容躺在收藏夹吃灰,Why?
我很喜欢知乎,这里有大量的优质回答和文章,以及媲美P**nhub的推荐算法。
换句话说,我刷知乎的行为模式简直像个无情的手冲机器。
看到算法推荐的好东西,先粗看一遍就扔到收藏夹里,然后等到要用了(通常是几周后)再回去现翻。
开始时我觉得这样好,我能记住我的收藏夹里有什么东西,要用的时候也能及时找到。可是随着我收藏数量的增加,检索收藏夹的难度越来越大,「复习」收藏夹的频率也越来越低。

每当我要从垃圾桶般的收藏夹里找东西的时候,我都感觉很头疼,我反思了一下,这能怪我吗?知乎的收藏系统完全就是屑嘛
知乎收藏功能的问题主要体现以下几方面:
1.电脑版收藏夹每页只能显示10个条目,没有搜索功能。
2.手机版收藏夹则是做成了瀑布流显示,没有搜索功能。
3.收藏夹(https://www.zhihu.com/collection/xxx)这个网页平均要4000ms左右才能加载完成,速度很慢。
4.对于我这类用户,使用「收藏」的频率远比使用「点赞」的频率高,而知乎收藏夹偏偏没有更高级的「导出」,「排序」等操作。
收藏系统问题这么多,要怎么办呢?

II.用爬虫收集收藏内容?HOW?
最近Python频频在我的朋友圈刷屏,用Python提高生产力成了培训机构的有力广告词,这些机构用的最多的案例就是用python爬虫采集数据,辅助决策。
JB公司的调查显示,有81%的开发者不止在工作中使用python,在生活和教育方面python占比也很大。
看起来,用爬虫处理这个生活小问题非常合适,那么本篇文章主要讲的就是python爬虫吗?

不完全是,我python比较菜,所以本篇「暂时」用java来写收藏夹爬虫,不过原理是类似的,有兴趣的看官也可以拿python重写一下这个爬虫。
正式开始之前..
如果只是想爬取自己的收藏夹,请查看「III.爬取你的收藏夹内容」。
如果想查看爬虫编写的过程,请查看「IV.技术实现」。
III.爬取你的收藏夹内容
在使用我编写的这个爬虫之前,请确保计算机上安装了JDK8或JRE8,你可以通过在搜索栏输入Java来确定自己是否安装了必须的环境。
链接:https://pan.baidu.com/s/1VHEgWVmVmrg4WsQbFUvgmw
提取码:ytbw
爬虫主体Sophy.jar请前往https://github.com/Masonic9/Sophy/releases下载。
操作步骤:
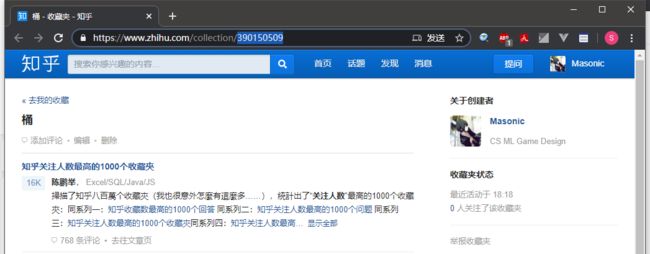
1) 打开你的网页版知乎收藏夹
找到你的收藏夹编号,在这个例子中,我的收藏夹编号为「390150509」
2) 新建一个文件夹,把下载下来的Sophy.jar放到这个文件夹里。
3) 在这个文件夹的空白处按「Shift+右键」,找到右键菜单的「在此处打开PowerShell窗口」或「在此处打开命令提示符(CMD)」。

在新打开的CMD或Powershell中输入
java -jar .\Sophy.jar mine[收藏夹编号]
在我这个例子中,我应该输入
java -jar .\Sophy.jar mine 390150509
按下回车,稍等一会(1-∞分钟不等,取决于你的收藏夹页数)。
4) 爬虫爬取结束后,在你的文件夹里会出现一个.csv文件,使用Excel即可打开查看。
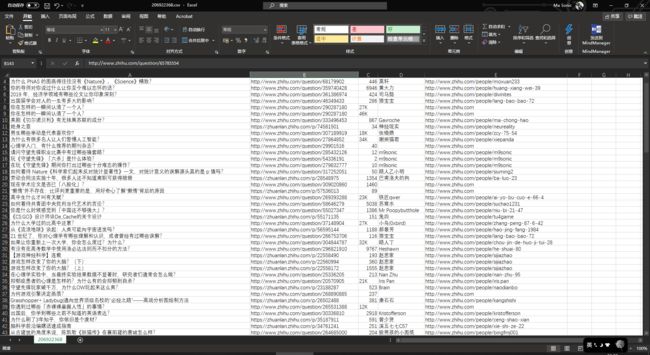
剩下的工作就可以交给Excel了,「搜索」,「排序」,「统计」,甚至「绘图」,对于这些数据,你可以用强悍的Excel胡作非为。

PS: 可能遇到的错误
- 爬不到内容
- 请检查你的收藏夹状态是否设为「私密」
- CMD提示「找不到文件」
- 你的电脑可能没有安装JDK,或者环境变量设置有误,请查询「JDK/JRE 环境变量设置」
IV.技术实现
1 ) 分析页面
用浏览器自带的「源代码查看器」(快捷键通常是F12)的Network项,你可以观察本地浏览器和远程服务器偷偷摸摸传输的数据。
知乎发来的数据包包含的是已经「渲染过的」收藏夹内容,要处理这种数据,只能在源代码里匹配HTML节点。
2 ) 框架简介
这个爬虫使用了WebCollector这一框架,特点是非常容易上手。
WebCollectorgithub.com
看一下WebCollector的Demo示例,即可快速掌握这一框架。
3 ) 思路
没什么思路,这个爬虫结构很简单,爬就完了
V. 一点点感想
如果用一下「麦肯锡空雨伞法」分析知乎收藏这件事,大概是这样的
空
1) 很多提供干货的高赞答主,常常吐槽「收藏是点赞的十倍」「别光收藏,多点点赞啊」。
2) 知乎最近才把用户的「收藏」行为展示在动态里,之前是只显示点赞。
3 )在12-16年这段时间,有许多的关注收藏夹的优秀内容,而现在很少见到了

雨
1) 知乎的收藏夹页面使用的UI是旧版的,收藏夹推荐功能的内容也很陈旧。知乎最近做的Live,付费咨询,带货都是为了盈利,反而对这些增强用户体验的系统不太上心。
2) 知乎用户的行为中,「收藏」行为可能比「点赞」还要多,收藏夹的创建和维护者们本身就是最强的内容筛选系统。
3) 现行的推荐算法都会刻意迎合用户的点击趋势,导致视野越来越小,这一现象在一本书中总结(其实是预测)的很好:
过量的信息与有限的注意力之间的矛盾不可调和,于是我们会不断缩小自己关注的领域,以确保头脑不因信息过载而“死机”。久而久之,亿万网民就会变得只关注自己感兴趣的信息,分化成无数个拥有共同爱好的小圈子。大数据技术又会统计出各个用户平时浏览最多的信息,然后让新媒体平台精准地推送他们最关注的内容
伞
用深度学习来推荐内容已经相当普遍了,但是我觉得目前知乎算法学会更多的是「什么东西用户想看」,而不是「什么东西对用户有好处」。
发掘收藏夹数据,把收藏夹创建者当成推荐系统工具人,在这一方向上建议加 大 力 度。
总结
本篇文章是「Sophy」项目链条的第一部分,后续还有更多新鲜干货。
