open-falcon整体架构
下图是open-falcon的整体架构,模块比较多,可以看完整篇文章介绍再回头看这个架构图。
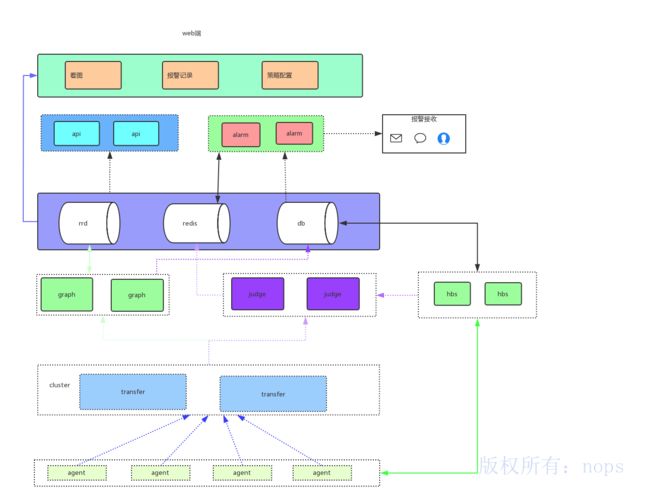
open-falcon架构
简化版架构图
简化的falcon基本工作流程可描述如下图所示:
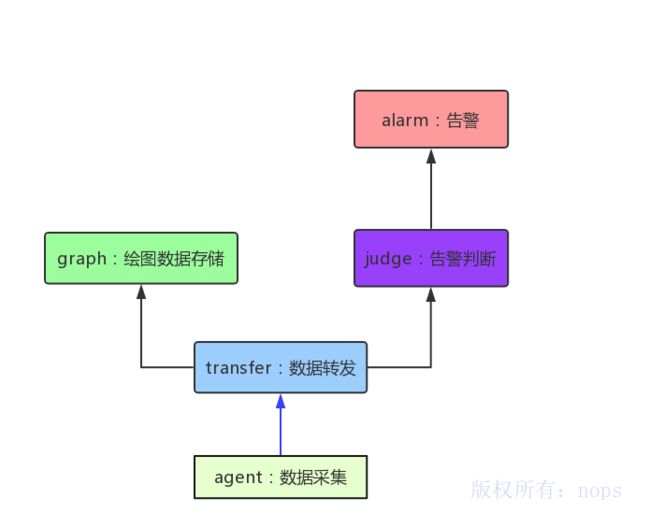
简化流程
下面就根据这个简化版流程图,介绍下open-falcon到底是怎么工作的。
agent
功能:数据采集上报,部署在每台物理机上。
数据到底是什么样的?
{
'endpoint': hostname-of-machine,
"metric": cpu.busy,
"timestamp": 1540286013,
"value": 1.234
}
注:为了简化,进行了字段精简
怎么采集?
基本上都是通过解析linux系统目录/proc下的文件,举例:
cpu: /proc/stat
load: /proc/loadavg
net: /proc/net/dev
怎么上报?
定时采集(默认每分钟一次),采集完通过rpc调用,发送给transfer模块
transfer
主要功能:数据转发
啥叫数据转发?到底干啥的?
接收数据->非法数据过滤->缓存在内存中->发送给不同模块(graph、judge、opentsdb)
graph
功能:基于环形数据库rrdtool,存储监控数据,并提供查询接口
rrdtool是啥玩意?
1. 存储数据之时,设置了数据保存的时间,比如一个月,超过一个月的数据会被删除。
2. 数据以文件的形式存储在磁盘上
rrdtool数据的底层结构是啥?
数据保存在以rrd结尾的文件中,内容格式为 时间戳:值,举例如下:
1540286013 1.12
1540286073 2.34
1540286133 1.35
是不是很简单
怎么查询数据?
假设要查询hostname1,最近30分钟,load情况
1. 根据查询参数生成文件名:hostname1_load.rrd
2. 读取这个文件内容并返回时间戳为30分钟之内的数据
注:这里对文件名规则进行了简化
judge
功能:根据配置的报警策略,判断是否需要报警
策略是什么样的?
以hostname为维度,保存每个机器配置的所有策略
hostname:[策略1,策略2,...,策略n]
策略举例:
all(#3) load > 20
意思是:连续三次负载超过20就报警
报警怎么发出去?
根据策略,将需要报警的事件写入redis。由alarm模块定期读取并发送出去
写入redis的数据可简化如下:
{
'hostname': 'hostname-of-machine',
'时间':1540286013,
'值':1.234
'策略':'all(#3) load > 20 报警接收人:张三',
'报警次数':'第三次报警'
}
注:为方便理解,对真实的结构进行了改造
alarm
功能:报警发送
这个模块比较简单,主要实现以下功能:
1.格式化报警内容
2.简单的报警合并
3.报警发送:短信、邮件、IM
其他模块
略。
欢迎加入我的知识星球,一起讨论技术。Coding A Better Life!
知识星球