一.实现效果
【压缩】
huffman.gif
【解压缩】
huffman2.gif
【压缩效率】
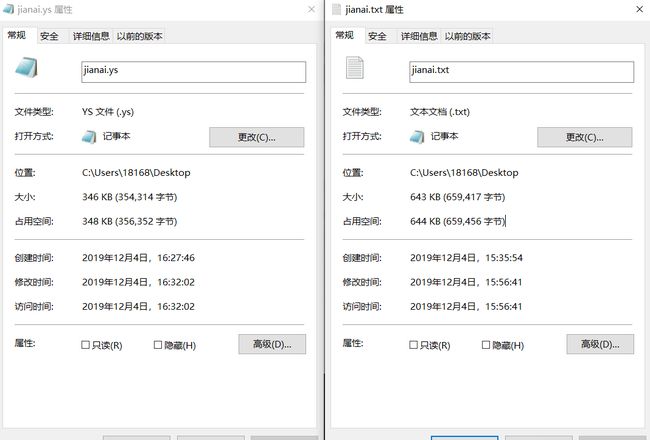

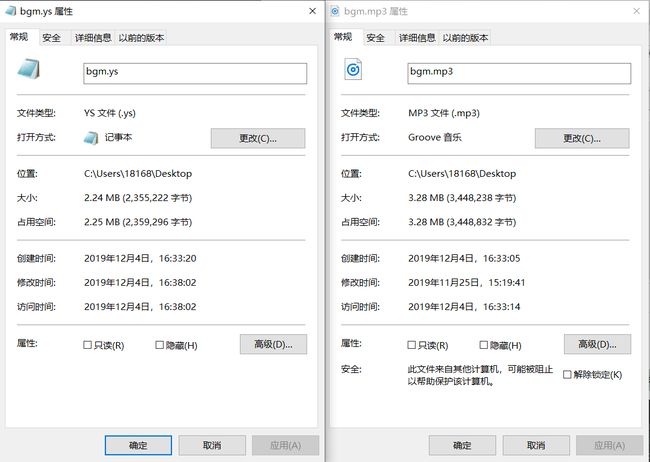
EAA}7T{AT2@L77{25MI}_YD.png
二.哈夫曼算法
哈夫曼又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。
三.哈夫曼树
【1. 哈夫曼树也称最优二叉树】
叶子节点的权值是对叶子节点赋予的一个有意义的数值量。
设二叉树具有 n 个带权值的叶子结点,从根节点到各个叶子结点的路径长度与相应叶子结点权值的乘积之和叫做二叉树的带权路径长度。
给定一组具有确定权值的叶子结点,可以构造处不同的二叉树,将其中带权路径长度最小的二叉树称为哈夫曼树。
【2. 基本思想】
初始化:由给定的 n 个权值 {ω1,ω2,⋯,ωn}构造 n 棵只有一个根节点的二叉树,从而得到一个二叉树集合F={T1,T2,⋯,Tn}。
选取与合并:在F中选取根节点的权值最小的两颗二叉树分别作为左右子树构造一棵新的二叉树(一般情况下将权值大的结点作为右子树。),这棵新二叉树的根节点的权值为其左、右子树根节点的权值之和。
删除与加入:在F中删除作为左、右子树的两棵二叉树,并将新建立的二叉树加入到F中。
重复上述两个步骤,当集合F中只剩下一棵二叉树时,这棵二叉树便是哈夫曼树。

四.哈夫曼编码
【1. 哈夫曼编码是一种可变字长编码】
如果一组编码中任一编码都不是其他任何一个编码的前缀,我们称这组编码为前缀编码。哈夫曼树可用于构造最短的不等长编码方案。
【2. 算法流程】
规定哈夫曼编码树的作分支代表 0,右分支代表 1,则从根结点到每个叶子结点所经过的路径组成的 0 和 1 的序列便成为该叶子结点对应字符的编码。

解码则是将编码串从左到右逐位判别,直到确定一个字符。
哈夫曼编码树中,树的带权路径长度的含义是各个字符的码长与其出现次数的乘积之和,所以采用哈夫曼树构造的编码是一种能使字符串的编码总长度最短的不等长编码。
五.代码实现
【窗口搭建】
import tkinter
import tkinter.filedialog
from tkinter import *
import tkinter.messagebox
# 压缩大文件实时会出现超出递归深度,故修改限制
sys.setrecursionlimit(1000000)
# 创建住窗口
root = tkinter.Tk()
root.minsize(700,500)
root.title('Iwen-哈夫曼压缩软件')
root['bg'] = '#F2F2F2'
# 声明一个全局变量files
files = ()
# 声明lable的使用变量
filenames = tkinter.StringVar()
textvars = tkinter.StringVar()
.......
# 添加按钮界面
label = tkinter.Label(root,bg = '#F2F2F2')
label.place(width = 700,height = 115)
# 1.添加文件按钮
btnadd = tkinter.Button(root,text = '选择文件',bg = '#C0C0C0',bd = 0.5,fg = 'black',command = selecfiles)
btnadd.place(x = 100,y = 70,width = '80',height = 30)
# 2.压缩操作按钮
btnadd = tkinter.Button(root,text = '压缩文件',bg = '#C0C0C0',bd = 0.5,fg = 'black',command = encodefile)
btnadd.place(x = 300,y = 70,width = '80',height = 30)
# 3.解压操作按钮
btnadd = tkinter.Button(root,text = '解压文件',bg = '#C0C0C0',bd = 0.5,fg = 'black',command = decodefile)
btnadd.place(x = 500,y = 70,width = '80',height = 30)
img1 = tkinter.PhotoImage(file = 'renew.png')
labelg1 = tkinter.Label(root,image = img1 )
labelg1.place(x = 115,y =15,width = 50,height = 50)
img2 = tkinter.PhotoImage(file = 'lock.png')
labelg2 = tkinter.Label(root, image = img2)
labelg2.place(x = 317,y =15,width = 50,height = 50)
img3 = tkinter.PhotoImage(file = 'unlock.png')
labelg3 = tkinter.Label(root, image = img3)
labelg3.place(x = 515,y =15,width = 50,height = 50)
# 4显示信息的组件
label_2 = tkinter.Label(root,bg = '#DCDCDC',textvariable = filenames,anchor = 'nw',justify = 'left',font=('GB2312', 14))
label_2.place(x= 5,y = 150,width = '690',height = '340')
root.mainloop()
【选取文件操作】
# 1.选取文件操作
def selecfiles():
# 声明全局变量
global files
# 使用文件对话框选择文件
files = tkinter.filedialog.askopenfilenames(title = '选择你要操作的文件')
# 显示选中文件的信息
# 临时的路径容器
tmpfiles = []
for i in files:
if len(i) > 60:
i = i[0:20] + '...' + i[-15:]
tmpfiles.append(i)
filestr = '\n'.join(tmpfiles)
print(filestr)
filenames.set(filestr) # 在标签中显示文件名称
【哈夫曼算法】
# 定义哈夫曼树的节点类
class node(object):
def __init__(self, value=None, left=None, right=None, father=None):
self.value = value # 数据域
self.left = left # 左孩子
self.right = right # 右孩子
self.father = father # 父亲结点
def build_father(left, right):
n = node(value=left.value + right.value, left=left, right=right)
left.father = right.father = n
return n
def encode(n):
if n.father == None:
return b''
if n.father.left == n:
return node.encode(n.father) + b'0' # 左节点编号'0'
else:
return node.encode(n.father) + b'1' # 右节点编号'1'
# 哈夫曼树构建
def build_tree(l):
if len(l) == 1:
return l
sorts = sorted(l, key=lambda x: x.value, reverse=False)
n = node.build_father(sorts[0], sorts[1])
sorts.pop(0)
sorts.pop(0)
sorts.append(n)
return build_tree(sorts)
def encode(echo):
for x in node_dict.keys():
ec_dict[x] = node.encode(node_dict[x])
if echo == True: # 输出编码表(用于调试)
print(x)
print(ec_dict[x])
【文件的压缩】
# 2.压缩文件函数
def encodefile():
filename = tkinter.filedialog.asksaveasfilename(title='选择文件')
# filenames.set("开始压缩,请稍后...")
print("开始压缩,请稍后...")
f = open(filename, "rb")
bytes_width = 1 # 每次读取的字节宽度
i = 0
f.seek(0, 2) # 用于移动文件读取指针到指定位置 0-开始的偏移量,也就是代表需要移动偏移的字节数;2-从文件末尾算起
count = f.tell() / bytes_width # tell返回文件的当前位置,即文件指针当前位置。
print(count)
nodes = [] # 结点列表,用于构建哈夫曼树
buff = [b''] * int(count)
f.seek(0)
# 计算字符频率,并将单个字符构建成单一节点
while i < count:
buff[i] = f.read(bytes_width)
if count_dict.get(buff[i], -1) == -1:
count_dict[buff[i]] = 0
count_dict[buff[i]] = count_dict[buff[i]] + 1
i = i + 1
print("读取完毕,开始压缩...")
print(count_dict) # 输出权值字典
for x in count_dict.keys():
node_dict[x] = node(count_dict[x])
nodes.append(node_dict[x])
f.close()
tree = build_tree(nodes) # 哈夫曼树构建
encode(False) # 构建编码表
print("编码完毕!")
head = sorted(count_dict.items(), key=lambda x: x[1], reverse=True) # 对所有根节点进行排序
bit_width = 1
print("head:", head[0][1]) # 动态调整编码表的字节长度,优化文件头大小
if head[0][1] > 255:
bit_width = 2
if head[0][1] > 65535:
bit_width = 3
if head[0][1] > 16777215:
bit_width = 4
print("bit_width:", bit_width)
i = 0
raw = 0b1
last = 0
name = filename.split('.')
o = open(name[0] + ".ys", 'wb')
name = filename.split('/')
o.write((name[len(name) - 1] + '\n').encode(encoding="utf-8")) # 写出原文件名
o.write(int.to_bytes(len(ec_dict), 2, byteorder='big')) # 写出结点数量
o.write(int.to_bytes(bit_width, 1, byteorder='big')) # 写出编码表字节宽度
for x in ec_dict.keys(): # 编码文件头
o.write(x)
o.write(int.to_bytes(count_dict[x], bit_width, byteorder='big'))
# filenames.set("编码头文件完毕!")
print('编码头文件完毕!')
while i < count: # 开始压缩数据
for x in ec_dict[buff[i]]:
raw = raw << 1
if x == 49:
raw = raw | 1
if raw.bit_length() == 9:
raw = raw & (~(1 << 8))
o.write(int.to_bytes(raw, 1, byteorder='big'))
o.flush() # 刷新缓存
raw = 0b1
tem = int(i / len(buff) * 100)
if tem > last:
print("压缩进度:", tem, '%') # 输出压缩进度
if tem < 99:
filenames.set("文件压缩成功!") # 在标签中显示文件名称
last = tem
i = i + 1
if raw.bit_length() > 1: # 处理文件尾部不足一个字节的数据
raw = raw << (8 - (raw.bit_length() - 1))
raw = raw & (~(1 << raw.bit_length() - 1))
o.write(int.to_bytes(raw, 1, byteorder='big'))
o.close()
print("文件压缩成功!")
# 提示用户压缩路径
tkinter.messagebox.showinfo(title='操作结果', message='文件压缩成功:' + filename)
【文件解压】
# 3.解压操作函数
def decodefile():
filename = tkinter.filedialog.asksaveasfilename(title='保存文件')
print("开始解压,请稍后...")
count = 0
raw = 0
last = 0
f = open(filename, 'rb')
f.seek(0, 2)
eof = f.tell()
f.seek(0)
name = filename.split('/')
outputfile = filename.replace(name[len(name) - 1], f.readline().decode(encoding="utf-8"))
o = open(outputfile.replace('\n', ''), 'wb')
count = int.from_bytes(f.read(2), byteorder='big') # 取出结点数量
bit_width = int.from_bytes(f.read(1), byteorder='big') # 取出编码表字宽
i = 0
de_dict = {}
while i < count: # 解析文件头
key = f.read(1)
value = int.from_bytes(f.read(bit_width), byteorder='big')
de_dict[key] = value
i = i + 1
for x in de_dict.keys():
node_dict[x] = node(de_dict[x])
nodes.append(node_dict[x])
tree = build_tree(nodes) # 重建哈夫曼树
encode(False) # 建立编码表
for x in ec_dict.keys(): # 反向字典构建
inverse_dict[ec_dict[x]] = x
i = f.tell()
data = b''
while i < eof: # 开始解压数据
raw = int.from_bytes(f.read(1), byteorder='big')
# print("raw:",raw)
i = i + 1
j = 8
while j > 0:
if (raw >> (j - 1)) & 1 == 1:
data = data + b'1'
raw = raw & (~(1 << (j - 1)))
else:
data = data + b'0'
raw = raw & (~(1 << (j - 1)))
if inverse_dict.get(data, 0) != 0:
o.write(inverse_dict[data])
o.flush()
# print("decode",data,":",inverse_dict[data])
data = b''
j = j - 1
temp = tem = int(i / eof * 100)
if tem > last:
print("解压进度:", tem, '%') # 输出解压进度
filenames.set(tem)
if tem < 99:
filenames.set("文件解压成功!") # 在标签中显示
last = tem
raw = 0
f.close()
o.close()
print("文件解压成功!")
# 提示用户压缩路径
tkinter.messagebox.showinfo(title='操作结果', message='文件解压成功:' + filename)