1.导入数据
import pandas #ipython notebook
titanic = pandas.read_csv("titanic_train.csv")
titanic.head(5)

数据预览
由上可知,该数据共有12个字段,各个字段含义如下:
- PassengerId 整型变量,标识乘客的ID,递增变量,对预测无帮助
- Survived 整型变量,标识该乘客是否幸存。0表示遇难,1表示幸存。将其转换为factor变量比较方便处理
- Pclass 整型变量,标识乘客的社会-经济状态,1代表Upper,2代表Middle,3代表Lower
- Name 字符型变量,除包含姓和名以外,还包含Mr.
Mrs. Dr.这样的具有西方文化特点的信息 - Sex 字符型变量,标识乘客性别,适合转换为factor类型变量
- Age 整型变量,标识乘客年龄,有缺失值
- SibSp 整型变量,代表兄弟姐妹及配偶的个数。其中Sib代表Sibling也即兄弟姐妹,Sp代表Spouse也即配偶
- Parch 整型变量,代表父母或子女的个数。其中Par代表Parent也即父母,Ch代表Child也即子女
- Ticket 字符型变量,代表乘客的船票号 Fare 数值型,代表乘客的船票价
- Cabin 字符型,代表乘客所在的舱位,有缺失值
- Embarked 字符型,代表乘客登船口岸,适合转换为factor型变量
2.数据预处理
2.1数据描述性统计
titanic.describe()
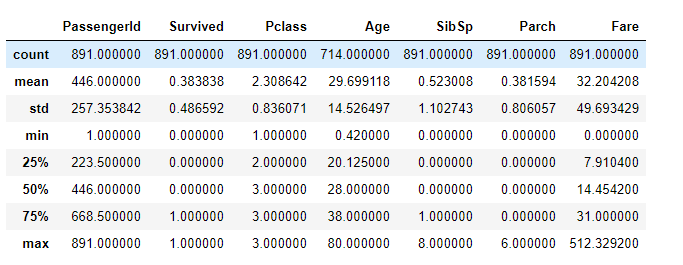
描述性统计
可以知道,字段Age有缺失值,将平均值作为填充
titanic["Age"] = titanic["Age"].fillna(titanic["Age"].median())
2.2非数字型数据转换为数字表示类型
# 男性用0表示,女性用1表示
titanic.loc[titanic["Sex"] == "male", "Sex"] = 0
titanic.loc[titanic["Sex"] == "female", "Sex"] = 1
print(titanic["Embarked"].unique())
# 将Embarked字段缺失值填充为数量最多的S
titanic["Embarked"] = titanic["Embarked"].fillna('S')
# 把S、C、Q分别用数字0、1、2表示
titanic.loc[titanic["Embarked"] == "S", "Embarked"] = 0
titanic.loc[titanic["Embarked"] == "C", "Embarked"] = 1
titanic.loc[titanic["Embarked"] == "Q", "Embarked"] = 2
处理后的数据预览:

处理后数据
2.3对训练数据进行划分,进行交叉验证
from sklearn.model_selection import KFold # cross_validation 已经被model_selection 代替
# 七个特征值
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
3.逻辑回归算法实现
# 从sklearn中导入逻辑回归算法
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
alg = LogisticRegression(random_state=1)
scores = model_selection.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=3)
print(scores.mean())
输出结果:
逻辑回归算法预测分数
可知,该算法预测准确率达到78%,预测效果不错
4.随机森林算法实现
from sklearn import model_selection
from sklearn.ensemble import RandomForestClassifier
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]
# Initialize our algorithm with the default paramters
# n_estimators is the number of trees we want to make
# min_samples_split is the minimum number of rows we need to make a split
# min_samples_leaf is the minimum number of samples we can have at the place where a tree branch ends (the bottom points of the tree)
alg = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2, min_samples_leaf=1)
# Compute the accuracy score for all the cross validation folds. (much simpler than what we did before!)
kf = model_selection.KFold( n_splits=3, random_state=1).split(titanic)
scores = model_selection.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=3)
# Take the mean of the scores (because we have one for each fold)
print(scores.mean())
输出结果:
随机森林算法预测分数
可知,随机森林算法预测准确率达到80%,预测效果好于逻辑回归算法
4.1调整随机森林算法参数
# 调参
alg = RandomForestClassifier(random_state=1, n_estimators=100, min_samples_split=4, min_samples_leaf=2)
# Compute the accuracy score for all the cross validation folds. (much simpler than what we did before!)
kf = model_selection.KFold(n_splits=3, random_state=1).split(titanic)
scores = model_selection.cross_val_score(alg, titanic[predictors], titanic["Survived"], cv=3)
# Take the mean of the scores (because we have one for each fold)
print(scores.mean())
输出结果:
参数调整后的预测分数
可以知道,通过调节参数,能够达到提高模型预测能力的效果