1.Solr简介
1.1.Solr是什么
Solr是一个基于全文检索的企业级应用服务器。
全文检索:可以输入一段文字,通过分词检索数据!!(复习)
应用服务器:它是单独的服务。
1.2.Solr能做什么
它就是用于做全文搜索。
1.3.为什么需要Solr
问题:我们已经学过Lucene,为什么还要学习solr?
答:Lucene是一个工具包,不能单独运行,需要导入到java代码中。
Solr可以独立运行在tomcat容器中,通过http协议,以接口的方式对外提供服务,java代码只需要专注于业务的处理就可以。

1.4.Solr下载路径
http://archive.apache.org/dist/lucene/solr/
solr是基于lucene实现的,和Lucene同步更新。
1.5.Solr目录结构说明
下载solr-4.10.3.zip并解压:

bin:solr的运行脚本
contrib:solr的一些扩展jar包,用于增强solr的功能。
dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
docs:solr的API文档
example:solr工程的例子目录:
licenses:solr相关的一些许可信息
2.入门示例
2.1.需求
使用Solr实现电商网站的商品搜索功能。
2.2.配置步骤说明
(1)配置Solr服务器。
(2)配置SolrHome。(Solr服务的主目录,磁盘)
(3)在Solr服务器中加载SolrHome。
(4)java程序访问Solr服务器,实现全文搜索。
2.3.配置步骤
2.4.第一部分:配置Solr服务器
--说明:Solr可以独立运行,需要servlet容器加载它。本文使用tomcat。
2.4.1.第一步:解压一个Tomcat
解压一个新的Tomcat,专门用来加载Solr。

2.4.2.第二步:部署Solr服务到Tomcat中
--在Solr的下载包中,提供了Solr的war包程序。(空的war包程序)

--拷贝solr.war到Tomcat的webapp目录下。并解压
[图片上传失败...(image-a9623d-1563540122837)]

2.4.3.第三步:添加Solr运行依赖的jar包
--在Solr的下载包中,提供Solr服务器运行所依赖的jar包。

(1)拷贝/example/lib/ext下的所有包,到solr应用的lib目录中
(2)拷贝/example/resource/log4j.properties,到solr应用的classes目录下。
--前提:先在/WEB-INF/目录下,创建classes目录。

2.5.第二部分:配置SolrHome
--说明:Solr的下载包中,提供了标准的SolrHome配置。
2.5.1.第一步:拷贝到本地,修改名称为SolrHome。(见名知意)

2.5.1.1.SolrHome说明
--SolrHome目录结构:

(1)SolrHome是Solr配置搜索服务的主目录。
(2)collection1称为Solr服务的一个实例(solrCore)。
(3)一个solr实例对应一个索引库。
(4)Solr可以同时配置多个实例。以便为不同的java程序提供搜索服务。
配置solr服务,就是在配置solr实例。
2.5.2.第二步:配置SolrCore
2.5.2.1.Step1:配置SolrCore实例的名称
--说明:每一个实例都有自己的名称。在core.properties文件中配置
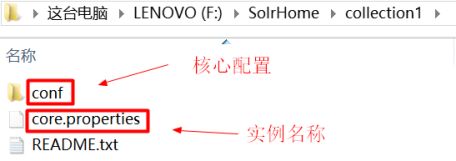
--在这里,我们将其修改为:soreCore0719

2.5.2.2.Step2:配置SolrCore所需的jar依赖
--说明:Solr下载包中,提供SolrCore所需要的所有jar依赖。

(1)在SolrHome同级目录下,创建depJar文件夹。(目的:方便管理jar依赖)

(2)拷贝contrib、dist两个目录到depJar目录下。

(3)修改/collection1/conf目录下的solrconfig.xml,加载jar包
--说明:solr是通过

(4)配置索引库目录
--说明:solr是通过
--默认路径是在SolrCore目录下,跟conf目录同级。首次加载时,将自动创建。
[图片上传失败...(image-d60bc7-1563540122837)]

本课程就使用该默认路径。
2.6.第三部分:在Solr服务器中加载SolrHome
2.6.1.第一步:修改web.xml加载SolrHome
--在solr的应用中,是通过web.xml来加载SolrHome的。

--说明:在这里是通过修改

2.6.2.第二步:启动Tomcat测试
--访问地址 http://localhost:8080/solr

--solr服务器配置成功!!!
2.7.第四部分:创建java程序访问solr服务器
--前提:创建好了数据库。(导入products-solr.sql文件即可)

--配置步骤说明:
(1)创建项目。
(2)创建索引
(3)搜索索引
2.7.1.第一步:创建项目,导入jar包
--导包说明:
SolrJ核心包 /solr-4.10.3/dist/solr-solrj-4.10.3.jar
SolrJ依赖包 /solr-4.10.3/dist/solrj-lib下的所有包
日志依赖包 /solr-4.10.3/example/lib/ext目录下的所有jar包
JDBC驱动包 mysql-connector-java-5.1.10-bin.jar
--拷贝log4j.properties到src目录下。(或者创建一个Source Folder)
--项目结构:

2.7.2.第二步:创建索引
--步骤说明。(复习回顾)
(1)采集数据。
(2)将数据转换成Solr文档。
(3)连接solr服务器,将文档写入索引库。
2.7.2.1.Step1:采集数据
--需求采集的字段说明:
参与搜索的字段:名称、价格、商品类别、描述信息
参与结果展示的字段:商品id、图片、
(1)创建Product类
public class Product {
private Integer pid;
private String name;
private String catalog_name;
private double price;
private String description;
private String picture;
// 补全get、set方法
}
(2)创建ProductDao类
package cn.gzsxt.solr.dao;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import cn.gzsxt.solr.pojo.Product;
public class ProductDao {
private Connection connection;
private PreparedStatement pst;
private ResultSet rs;
/**
* 采集数据,查询所有商品
* @return
*/
public List getAllProducts() {
List products = new ArrayList<>();
try {
//1、加载驱动
Class.forName("com.mysql.jdbc.Driver");
//2、获取Connection连接
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/solr", "root", "gzsxt");
//3、获取PreparedStatement,执行预编译
pst = connection.prepareStatement("select pid,name, catalog_name,price,description,picture from products");
//4、执行sql搜索
rs = pst.executeQuery();
Product p = null;
while(rs.next()){
p = new Product();
p.setPid(rs.getInt("pid"));
p.setName(rs.getString("name"));
p.setPrice(rs.getFloat("price"));
p.setPicture(rs.getString("picture"));
p.setDescription(rs.getString("description"));
p.setCatalog_name(rs.getString("catalog_name"));
products.add(p);
}
} catch (Exception e) {
e.printStackTrace();
}finally {
if(null!=rs){
try {
rs.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(null!=pst){
try {
pst.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(null!=connection){
try {
connection.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
return products;
}
}
(3)创建一个测试类ProductDaoTest
--导入junit类库。(快捷键ctrl+1)
package cn.gzsxt.solr.test;
import org.junit.Test;
import cn.gzsxt.solr.dao.ProductDao;
public class ProductDaoTest {
@Test
public void getAllProducts(){
ProductDao dao = new ProductDao();
System.out.println(dao.getAllProducts());
}
}
--测试结果,采集数据成功!!!
2.7.2.2.Step2:将数据转换成Solr文档SolrInputDocument
--说明:solr是通过SolrInputDocument来封装数据的。部分源码如下:
public SolrInputDocument(Map fields){
_documentBoost = 1.0F;
_fields = fields;
}
public void addField(String name, Object value){
addField(name, value, 1.0F);
}
问题:我们在Lucene中知道,域有三大属性,在创建文档的时候指定。而Solr的源码中,只是用一个Map集合来封装域的信息。那域的三大属性怎么定义呢?
答:Solr是通过一个配置文件schema.xml,事先定义域的信息的。
2.7.2.2.1.Solr域的说明
--通过

name属性:域的名称
type属性: 域的类型(
indexed属性:是否索引
stored属性:是否存储
multiValued属性:是否支持多个值
--通过

name属性:域类型的名称
class属性:指定域类型的solr类型。
2.7.2.2.2.Solr域的特点
(1)、Solr的域必须先定义,后使用。(否则报错:unknown fieldName)
(2)、定义solr域的时候,必须指定是否索引、是否存储这两个属性。
(3)、定义solr域的时候,必须指定域的类型
因为域的类型确定了这个域在索引、搜索两个阶段的分词属性。
(4)、每一个文档中,必须包含id这个域,它的值标记文档的唯一性。
2.7.2.2.3.配置Solr业务域
--商品各字段属性说明

--修改schema.xml,添加如下配置。(id域不用配置,直接使用solr的id域)
2.7.2.2.4.修改ProductDao,新增getDocuments方法
/**
* 将采集到的商品数据,转换成solr文档类型
* @param products
* @return
*/
public List getDocuments(List products){
List docs = new ArrayList<>();
SolrInputDocument doc = null;
for (Product product : products) {
doc = new SolrInputDocument();
doc.addField("id", product.getPid());
doc.addField("product_name", product.getName());
doc.addField("product_price", product.getPrice());
doc.addField("product_catalog_name", product.getCatalog_name());
doc.addField("product_description", product.getDescription());
doc.addField("product_picture", product.getPicture());
docs.add(doc);
}
return docs;
}
2.7.2.3.Step3:连接Solr服务器,创建索引
--前提:已经启动了Tomcat,加载了Solr服务器。(前面给过schema.xml,需要重写启动Tomcat)
--修改ProductDaoTest类,新增createIndex方法
@Test
public void createIndex(){
// 1、 创建HttpSolrServer对象,通过它和Solr服务器建立连接。
// 参数:solr服务器的访问地址
HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr/solrCore0719");
// 2、 通过HttpSolrServer对象将SolrInputDocument添加到索引库。
ProductDao dao = new ProductDao();
try {
server.add(dao.getDocuments(dao.getAllProducts()));
// 3、 提交。
server.commit();
System.out.println("创建索引库成功!!!");
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
2.7.2.4.Step4:访问Solr主界面,在Query选项下测试
--创建索引库成功!!!
2.7.3.第三步:搜索索引
--修改ProductDaoTest类型,新增一个查询方法
@Test
public void queryIndex() throws Exception {
// 创建HttpSolrServer对象,通过它和Solr服务器建立连接。
// 参数:solr服务器的访问地址
HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr/solrCore0719");
// 创建SolrQuery对象
SolrQuery query = new SolrQuery();
// 设置查询条件,参考主界面
query.set("q", "*:*");
// 调用server的查询方法,查询索引库
QueryResponse response = server.query(query);
// 查询结果
SolrDocumentList results = response.getResults();
// 查询结果总数
long cnt = results.getNumFound();
System.out.println("查询结果总数:" + cnt);
System.out.println("--------------------分隔符-------------------");
for (SolrDocument solrDocument : results) {
System.out.println("商品id:"+solrDocument.get("id"));
System.out.println("商品名称:"+solrDocument.get("product_name"));
System.out.println("商品价格:"+solrDocument.get("product_price"));
System.out.println("商品类别:"+solrDocument.get("product_catalog_name"));
System.out.println("商品图片:"+solrDocument.get("product_picture"));
System.out.println("----------------------------------------");
}
}
--查询结果,非常成功!!!

3.solr管理控制台
3.1.查询界面说明

(1) q - 查询关键字,必须,如果查询所有文档时,使用:。

(2) fq - (filter query)过虑查询,可以有多个。如:价格10到50的记录。

(3) sort - 排序,格式:sort=

(4) start - 分页显示使用,开始记录下标,从0开始

(5) rows - 指定返回结果最多有多少条记录,配合start来实现分页。

(6) fl - 指定返回那些字段内容,用逗号或空格分隔多个。

(7) df-指定一个默认搜索的Field

(8) wt - (writer type)指定输出格式,默认json格式。
3.1.1.对照界面,实现复杂查询
--修改ProductDaoTest类型,新增动态查询方法
@Test
public void queryDynamic(){
//1、连接solr服务器
HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr/solrCore0719");
//2、创建查询对象,封装查询条件
SolrQuery query = new SolrQuery();
//设置默认搜索的域
query.set("df", "product_name");
//参考管理界面中的 "q"标签,封装查询的关键词
query.set("q", "音乐盒");
//添加价格过滤
query.addFilterQuery("product_price:[10 TO 50]");
//添加类别过滤
query.addFilterQuery("product_catalog_name:幽默杂货");
//设置排序 价格升序
query.set("sort","product_price asc");
//设置分页信息 第二页 每页10条 start=(page-1)*pageSize
query.set("start", 10);
query.set("rows",10);
//设置要查询字段
query.set("fl", "id,product_name,product_price");
//3、执行查询
try {
QueryResponse response = server.query(query);
//获取查询的响应码
int status = response.getStatus();
System.out.println("响应码:"+status);
if(0==status){
SolrDocumentList solrDocumentList = response.getResults();
long numFound = solrDocumentList.getNumFound();
System.out.println("共查询到"+numFound+"条满足条件的数据!");
System.out.println("--------------");
for (SolrDocument s : solrDocumentList) {
System.out.println("商品的id:"+s.get("id"));
System.out.println("商品的名称:"+s.get("product_name"));
System.out.println("商品的价格:"+s.get("product_price"));
System.out.println("商品的图片:"+s.get("product_picture"));
System.out.println("商品的类别名称:"+s.get("product_catalog_name"));
System.out.println("商品的描述:"+s.get("product_decsription"));
System.out.println("-----------分隔符---------------");
}
}
} catch (SolrServerException e) {
e.printStackTrace();
}
}
--测试结果:非常成功!!!(对比管理界面查询结果)

3.2.安装DataImport插件
3.2.1.Dataimport插件说明
--好处:可以在管理界面直接从数据库导入数据到索引库。(即:一个插件解决入门示例中,创建索引的全部操作)

3.2.2.安装步骤
3.2.2.1.第一步:添加jar依赖
(1)将/solr-4.10.3/dist/solr-dataimporthandler-4.10.3.jar拷贝到
/depJar/contrib/dataimporthandler/lib目录下

(2)、将jdbc驱动包拷贝到 /depJar/contrib/db/lib 目录下

(3)、在solrconfig.xml文件中,加载这两个jar依赖
3.2.2.2.第二步:配置数据库表和solr域的映射关系
--在solr实例的conf目录下,配置数据库映射文件data-config.xml
3.2.2.3.第三步:创建dataimport处理器
--说明:Solr是在solrconfig.xml文件中,通过
--修改solrconfig.xml,添加如下配置。(加载data-config.xml映射文件)
data-config.xml
3.2.2.4.第四步:重启tomcat,在管理界面测试
--测试清空索引库,成功!!!

--测试重新导入数据,成功!!!

3.3.Analyzer分析器,配置中文分词器
3.3.1.Solr自带分词器的缺陷
--solr跟Lucene一样,提供了很多分析器。可以在Analyzer选型下测试分词效果。

--测试发现:所以的分词器,对中文支持都不友好。
解决办法:配置中文分词器。
3.3.2.Solr配置中文分析器
3.3.2.1.中文分析器选择
选择IK中文分词器。
3.3.2.2.配置步骤
3.3.2.2.1.第一步:添加IkAnalyze的jar依赖
--把IKAnalyzer2012FF_u1.jar添加到solr/WEB-INF/lib目录下。
3.3.2.2.2.第二步:加载IkAnalyzer的核心配置文件
--拷贝IkAnalyzer的配置文件到solr/WEB-INF/classes目录

3.3.2.2.3.第三步:创建中文分词器
--在schema.xml中自定义一个FieldType,指定中文分词器IKAnalyzer。
3.3.2.3.测试中文分词器
3.3.2.3.1.第一步:重启tomcat
3.3.2.3.2.第二步:在analysis选项卡下,测试分词效果。成功!!!

3.3.3.改造业务域,使用IK做分词器
--修改schem.xml文件,修改需要分词的域的fieldType类型
我们只需要修改product_name、product_description两个业务域即可。
--重启tomcat即可。