在一个Kafka集群中如何选择topics/partitions的数量
翻译自How to choose the number of topics/partitions in a Kafka cluster? ,同时结合了Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines) 的内容
通过阅读您可以了解过:
- kafka的基本运行原理
- kafka的性能如何
- kafka为何效能好
- kafka有哪些瓶颈
目前在Kafka 2.0版本中已经支持单集群200K的Partition数量,这真是可喜可贺啊~~~
更多的Partition数量会产生更高的吞吐量
首先需要明白的一件事是,Partition是Kafka的最小并行单元。在生间者和broker端,针对不同Partition的写操作是可以完成并行的。这样一些诸如压缩等昂贵的操作能够充分利用硬件资源。在消费者端,Kafka让单个Partition数据仅被一个消费线程消费,因此其消费并行度取决于能够被消费的Partition的数量。因此,通常来说在一个Kafka集群中Partition数据越多,越是可以达到一个更高的吞吐量。
这里有一个粗略的公式可以根据吞吐量来计算Partition的数量。你可以估算出生产者在每个Parition上的吞吐量(我们叫它为 p),再估算出消费者在每个 Partition上的吞吐量(叫它为 c)。假设你的目标吞吐量是t, 那么你至少需要 max(t/p, t/c)个Partitions。每个Partition可以达到的吞吐量取决于诸于batch size, 压缩codec, ack级别,复本数等一系列配置。消费者的吞吐量经常受限于应用程序处理message的消费逻辑有多快。因此我们需要实际的评估。
随着时间推移Partition数量可能是逐步增加的,我们需要留意生产Msg时附加Key的情况。当发送一个带Key的Msg时, Kafka基于这个 Key的hash值来将它映射到不同的Partition。这可以保证相同Key的msg总会写入到同一个Partiton中。这个保证对于需要按顺序消费Msg的应用来说是很重要的。如果Partition的数量发生变化,这个保证就不存在了。为了避免这种情况,一种通常的作法是提前多分配一些Partition,基本上,你可以根据未来1到2年的吞吐量来确定Partition数量,这样来使Partition数量在一个长时期内保持不变。
最初,你可能只有一个基于当前吞吐量的小的集群。随着时间的推移,集群内的topic数量越来越多,数据量也越来越大。Kafka的Partition实际上是个物理概念,它最终对应着物理机器文件系统中的一个目录,单机存储容量实际上就限制了Partition容量的上限。这时就需你能够增加最多的broker到集群中并且按比例地在线迁移已有partition的子集到新的broker上,同时因为这个方法只是迁移Partition,没有增加Partition, 也就能够保证在不破坏按Key写入msg的语义下增加了整体的吞吐量。
性能测试
下面是从Benchmark of Kafka 中抽取的压测结果,仅供参考:
- 三台机器部署一个Kafka Cluster, 硬件配置如下:
- Intel Xeon 2.5 GHz processor with 6 cores
- 6块 7200 RPM SATA drives 没有作RAID (JBOD方式)
- 32GB of RAM
- 1Gb Ethernet
-
压测结果:
其中 同步复制 指的是msg复制到所有复本后才给Producer回ack, 异步复制指msg写Leader成功即给Producer回ack。
- 生产吞吐量:
| Broker数量 | Producer 数量 | Msg大小(Byte) | Partition数量 | 复本数量 | 复本同步策略 | 吞吐量(record/s) | 吞吐量 (MB/s) |
|---|---|---|---|---|---|---|---|
| 3 | 1 | 100 | 6 | 1 | 821,557 | 78.3 | |
| 3 | 1 | 100 | 6 | 3 | 异步复制 | 786,980 | 75.1 |
| 3 | 1 | 100 | 6 | 3 | 同步复制 | 421,823 | 40.2 |
| 3 | 3 | 100 | 6 | 3 | 异步复制 | 2,024,032 | 193.0 |
2. 消费吞吐量:
| Broker数量 | Consumer 数量 | Msg大小(Byte) | Partition数量 | 复本数量 | 是否同时生产 | 是否从page cache读 | 吞吐量(record/s) | 吞吐量 (MB/s) |
|---|---|---|---|---|---|---|---|---|
| 3 | 1 | 100 | 6 | 3 | 否 | 否 | 940,521 | 89.7 |
| 3 | 3 | 100 | 6 | 3 | 否 | 否 | 2,615,968 | 249.5 |
| 3 | 1 | 100 | 6 | 3 | 1个 异步复制 | 是 (边写边读) | 795,064 | 75.8 |
##### 消息大小对性能的影响
处理大量的小消息(小于 100字节) 对于一个消息系统来说是比较困难的,无法更有效地利用网络带宽,服务端也会为处理每一个小消息来消耗大量资源。Kafka实际上也和其他的消息系统一样提供了批量写入的功能。针对消息大小对性能的影响,我们用两张图来说明一下。
- 随着消息体的增大,每秒钟能写入的record条数逐渐递减。
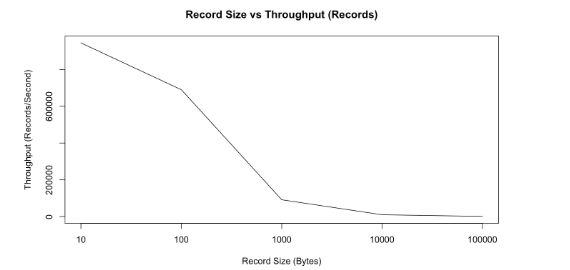
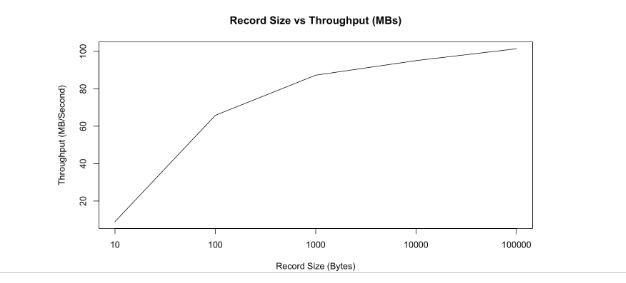
- 随着消息体的增大,每秒钟能写入的数据量逐渐递增。
PageCache对于性能的影响
我们知道Kafka在接受到msg后,并不是实时强制落盘,理论上它只定入PageCache, 这也是它可能loss data的原因之一。
对于消费者来说,如果它的消费没有lag, 那基本上它消费的数据全来自PageCache,将不会有任何的磁盘IO。但是如果有消费Group尝试消费旧数据,将引发从磁盘读取,这些旧数据进入PageCache,又进而引发了与新写入数据竞争PageCache。解决这个问题,可以通过对新写入数据自行增加一层缓存,以内存来换取性能。
更多的Partition需要更多的打开文件句柄
正如上面提到的,每个Partition最终会对应到Broker上文件系统中的一个目录。在这个目录中,每个log segment对应三类文件:存储实际数据的log文件,offset索引文件,时间索引文件 。当前对于每个log segment,Kafka都会打开这三类文件。因此,更多的partition,就意味着需要配置更多的允许打开的文件句柄数。我们在生产环境中见到过每台broker上有多于30万的打开文件句柄。
更多的Partition可能导致不可用时间增长
Kafka通过集群内Partition级别的主从复制来保证高可用和持久化。一个Partition可以有多个复本,存储在不同的broker上,其中一个作为Leader, 其它的都是followers。Kafka自动管理所有的复本并确保数据同步。数据的写入和读取都是由Partition的 Leader来提供。当一个broker发生故障,以这个broker为leader的这批partition将变为临时不可用,Kafka会自动作leader的迁移操作,在每个Parition的ISR列表中选择一个follower成为新的 Leader继续对外提供服务。这个自动迁移的操作是由一个作为Controller的broker来完成的,Controller针对每个受影响的partition从zookeeper读取并写入新的metadata来完成leader和follower的变更。当前Controller对zk的所有操作都是串行化(一个一个串行着写zk太慢了,一次可以写一批)完成的。
通常情况下,当broker正常优雅停止时,broker会发消息给Controller告之自已要shutdown, Controller会主动作leader的迁移,并且每次只操作一个partition(每次一个太慢了,这里完全可以并行啊),只耗时几个毫秒。因此,从客户端的角度来说,这个不可用的时间窗口只有几个毫秒,加之客户端有重试机制,影响几乎可忽略不计。
当一个broker非正常停止(比如 kill -9,另外kill -9 后重启broker, 还会导致很长时间的log data revovery)时,这个不可用的时间就会和partition的数量成正比了。举个例子来说,假设某个broker是1000个partiton的leader, 当这个broker被kill -9后,这1000个partition几乎是同时变为不可用状态。假设Controller选举每个partition主耗时5毫秒,这1000个partition就一共需要5秒钟才能全部恢复,也就是说有些paritition要经过5秒多才能恢复可用。
如果更不幸,坏掉的这台broker正好是Controller,那集群首先需要选举产生新的Controller, 这个选举是集群自动处理的。但是新的Controller在启动过程中需要从zk读取每个topic的每一个patition的信息。如果parition数据众多的话,这又是一笔巨大的时间开销。
更多的Partition数量可能会增加端到端的延迟
Kafka里的端到端的延迟被定义为消息从被生产者发送到被消费者接收到所经过的时间间隔。一条消息只有在被ISR中的复本都同步成功了,才会更新leader上的高水位,这样这条消息才可以被消费者消费到。因此复本同步数据的耗时就成了端到端延迟的一个重要决定因素。默认情况下,broker仅使用单线程来从其他broker上复制数据,即两个broker间的所有partition复制是共享一个线程的。从我们的经验来看,从一个broker到另一broker如果有1000个partition需要复制(大部分情况都是增量复制)大致的延迟是20ms左右, 也就是说这个端到端的延迟至少也要有20+ms。这对于对时效性要求高的应用来说是不太能接受的。
这种情况在规模大的集群上是会得到缓解的。因为集群规模越大,partition可能越分散,broker间需要复制的partition相对会少,复制延迟也会降低。
还有一种方法,就是增加复制线程数量。
根据经验,如果你关心端到端的延迟,可以将每个 broker上的partition数限制到100 x b x r,其中b是broker数量,r是复本数。
更多的Partition数量可能需要客户端使用过多的内存
使用Java SDK时,生产者会按partition来缓存发送的消息,当消息累积到一定数量或者到达一定时间后,这此累积的消息将被移出缓存并被批量发送。
如果parition数量增加,则意味着客户端需要累积更多partition的数据,这可能会使内存占用超过配置的上限。如果这种情况发生,生产者可能会被阻塞或被丢掉新的msg。为了避免这种情况,我们需要使用一个更新的memory size重新配置生产者。
同样的情况也出现在消费者上面。这个消费者针对每个partition来拉取消息。更多的partition同样需要更多的内存来缓存拉取过来的消息。
经验值
针对kafka 1.1.0以及之后的版本,建议单台broker上partition数量不超过4000, 整个集群partition数量不超过2000,000,主要原因还是上面讲过的controller选举和controller重新选举partition leader的耗时。
相对kafka 1.1.0之前版本,这个parition数量已经有了很大提高,这全部得益于controller处理broker shutdown流程的优化,主要是针对zk的写操作异步化,批量化,将新的metadata通知给没有shutdown的broker也批量化,减少RPC次数,但是最最主要的,大家肯定想不到,是减少了不必要的log, 具体可参考Apache Kafka Supports 200K Partitions Per Cluster, 我贴一段作者的说明:
A big part of the improvement comes from fixing a logging overhead, which unnecessarily logs all partitions in the cluster every time the leader of a single partition changes. By just fixing the logging overhead, the controlled shutdown time was reduced from 6.5 minutes to 30 seconds. The asynchronous ZooKeeper API change reduced this time further to 3 seconds. These improvements significantly reduce the time to restart a Kafka cluster.