防抖节流
优化高频率事件 onscroll oninput resize onkeyup keydown.... 降低代码执行频率

- js动画/往页面里添加一些dom元素
- style确定每个dom应该用什么样式规则
- Layout布局,计算最终显示的位置和大小
- Paint绘制dom,在不同的层上绘制
- Composite渲染层合并
用户scroll和resize行为会导致页面不断的重新渲染,如果在绑定的回调函数中大量操作dom也会出现页面卡顿
优化方案:
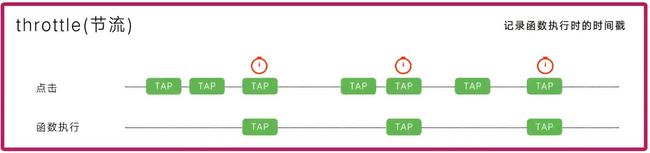
函数节流
节流就是保证一段时间内,核心代码只执行一次
打个比方:水滴积攒到一定重量才会下落
简易节流函数
Document
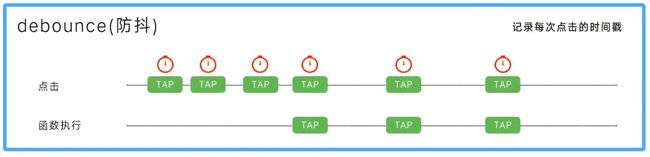
防抖
防抖就是一段时间结束后,才触发一次事件,如果一段时间未结束再次触发事件,就会重新开始计算时间
打个比方:电梯中,门快要关了,突然游刃准备上来,电梯并没有改变楼层,而是再次打开电梯门。电梯延迟了改变楼层的功能,但是优化了资源。
简易防抖代码
Document
requestAnimationFrame
编写动画循环的关键是要知道延迟时间多长合适,如果时间过长会导致动画补流畅,时间过短会造成过度的绘制。
requestAnimationFrame采用系统时间间隔,保持最佳绘制效率。此方法是用来在页面重绘之前,
通知浏览器调用一个指定的函数,被调用的频率是约每秒60次,在运行时浏览器会自动优化方法的调用.
重点:这个函数的核心就是浏览器可以根据不同PC性能算出最佳绘制时间,以实现最佳显示效果
Document
柯里化
函数柯里化,是固定部分参数,返回一个接受剩余参数的函数,也称为部分计算函数,目的是为了缩小适用范围,创建一个针对性更强的函数。
其实质就是预先处理机制,核心就是利用闭包实现
(function () {
function myBind(context=window,...outerArg) {
//此处的this是fn,因为是fn.myBind
let _this=this;
return function(...innerArg) {
//此处就相当于fn.call
// _this.call(context,...outerArg.concat(innerArg));
//innerArg:就是自动传递的event对象
_this.apply (context,outerArg.concat(innerArg));
}
}
Function.prototype.myBind = myBind;
})();
let obj = {
name: "OBJ"
}
function fn(...args) {
console.log(this, args);
}
/**
自定义实现了bind机制,而这个核心其实就是预先合并参数
利用这个机制可以实现下面案例的题目
*/
document.body.onclick=fn.myBind(obj,100,200);
//ev浏览器会自动追加在最后面传递,bind其实返回就是匿名函数,和下面的等效
// document.body.onclick=fn.bind(obj,100,200);
//其实bind函数内部就是这么实现的,可以避免立即执行
// document.body.onclick = function (ev) {
// fn.call(obj, 100, 200, ev);
// }
假如需求是固定三层相加需求,但是每层参数不固定,可以如下实现
function add(...A) {
return function(...B) {
return function(...C) {
return eval([...A,...B,...C].join('+'))
}
}
}
//也可以(1,2,4)(3)(5)这种层数固定但是每层参数不固定
add(1)(2)(3)
下面实现核心逻辑
/**请实现一个add函数,满足以下功能
* add(1); 1
* add(1)(2); 3
* add(1)(2)(3) 6
* add(1)(2)(3)(4) 10
* add(1)(2,3) 6
* add(1,2)(3) 6
* add(1,2,3) 6
*/
function currying(fn, length) {
length = length || fn.length;
return function (...args) {
if (args.length >= length) {
return fn(...args);
}
//传入null/undefined的时候将执行js全局对象浏览器中是window,其他环境是global
return currying(fn.bind(null, ...args), length - args.length);
}
}
// function $add(n1, n2, n3, n4) {
// return n1 + n2 + n3 + n4;
// }
// let add = currying($add, 4);
// console.log(add(1)(2)(3)(4));
// console.log(add(1, 2, 3, 4));
//$add.bind(null,1).bind(null,2).bind(null,3)(4);
//联系之前柯里化的案例
//function any1(...innerArg){$add.call(null,...[1,...innerArg])} 这样一层层关联预处理了参数
//function any2(...innerArg){any1.call(null,...[2,...innerArg])}
//function any3(...innerArg){any2.call(null,...[3,...innerArg])}
//any3(4)
//any2.call(null,3,4)
//any1.call(null,2,3,4)
//$add.call(null,1,2,3,4)
let add=currying((...arg)=>eval(arg.join('+')),5);
console.log(add(1,2,3,4,5));
总结:currying传递的第二参数就是实际真实计算是几个数据,一定要对应。
而从currying内部逻辑可发现,其实是递归实现,内部也有闭包,而这种需求核心其实就是不论多少层每层多少参数都要可以计算,参考前面的柯里化思想,每层递归其实类似于call这种绑定关联。
而在最终递归(预先处理)结束开始计算的时候,实际就是参数的合并逻辑。
参考视频:https://www.bilibili.com/video/BV1aE411C7pt?p=27
反柯里化
从字面讲,意义和用法跟函数柯里化相比正好相反,扩大适用范围,创建一个应用范围更广的函数。使本来只有特定对象才适用的方法,扩展到更多的对象。
Function.prototype.uncurrying=function() {
return str=>{
// Object.prototype.toString.call('str')
//this就是 Object.prototype.toString
//Object.prototype.toString.call(参数)就是输出类型
return this.call(str);
//这只是简单案例,其实可以添加很多自己的逻辑
}
}
let toString=Object.prototype.toString.uncurrying();
//扩展了函数的功能
console.log(toString('hello')); //[object String]
//Object.prototype.toString本身就是一个函数,函数自然就有Function.prototype上面的属性
总结:柯里化和反柯里化是一个思路,理解即可,不需要关心N多的具体实现,没有实际意义
SourceMap
说起sourceMap大家肯定都不陌生,随着前端工程化的演进,我们打包出来的代码都是混淆压缩过的,当源代码经过转换后,调试就成了一个问题。在浏览器中调试时,如何判断原始代码的位置?
为了解决这个问题,google 提出了sourceMap 的想法,并在chorme上最先支持sourceMap的使用。sourceMap 由于包含许多信息,前期也经过多版的编码算法优化,最后在2011年探索出了Source Map Revision 3.0 ,这个版本也就是我们现在一直在使用的sourceMap版本。这一版本的mapping信息使用Base64 VLQ 编码,大大缩小了.map文件的体积。
sourceMap可以帮我们直接定位到编译前代码的特定位置,接下来我们直接拿个sourceMap文件来看看它包含了一些什么信息:
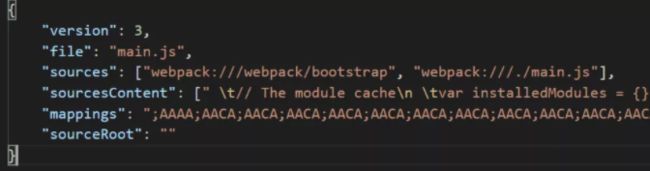
上面可以看到,sourceMap其实就是就是一段维护了前后代码映射关系的json描述文件,包含了以下一些信息:
- version:sourcemap版本(现在都是v3)
- file:转换后的文件名。
- sourceRoot:转换前的文件所在的目录。如果与转换前的文件在同一目录,该项为空。
- sources:转换前的文件。该项是一个数组,表示可能存在多个文件合并。
- names:转换前的所有变量名和属性名。
- mappings:记录位置信息的字符串。
mappings 信息是关键,它使用Base64 VLQ 编码,包含了源代码与生成代码的位置映射信息。mappings的编码原理详解可见:http://www.ruanyifeng.com/blog/2013/01/javascript_source_map.html,这里就不再详述。
webpack中的sourceMap配置
webpack 给出了多种sourceMap配置方式,相信很多人第一眼看到的时候和我一样,疑惑这些都有啥区别
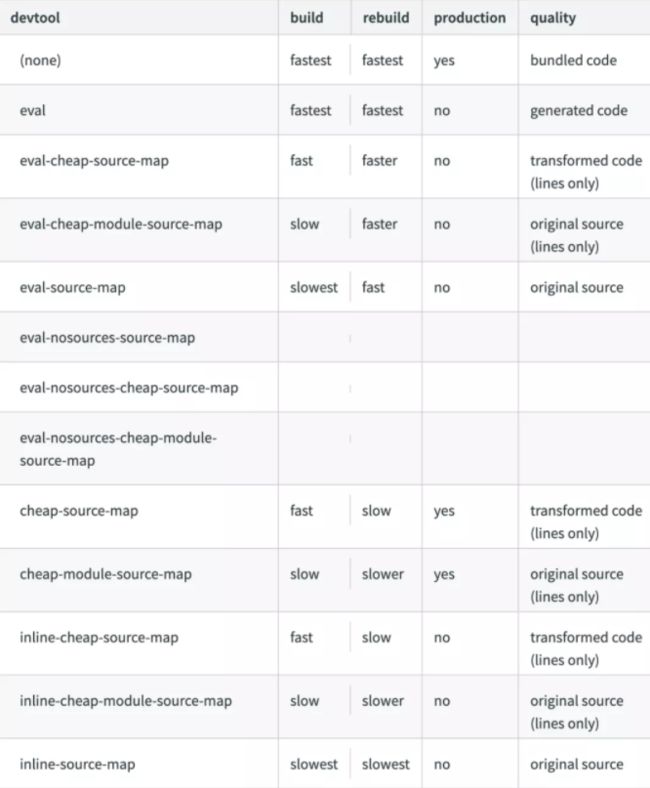
其实不难发现这么多配置,这些就是source-map和eval、inline、cheap、module 的自由组合。所以我们来拆开看下每项配置。
为了方便演示,这里的源代码只包含了一行代码
console.log( hello world );
最原始的只设置’source-map’配置,可以看到输出了两个文件,其中包含一个map文件
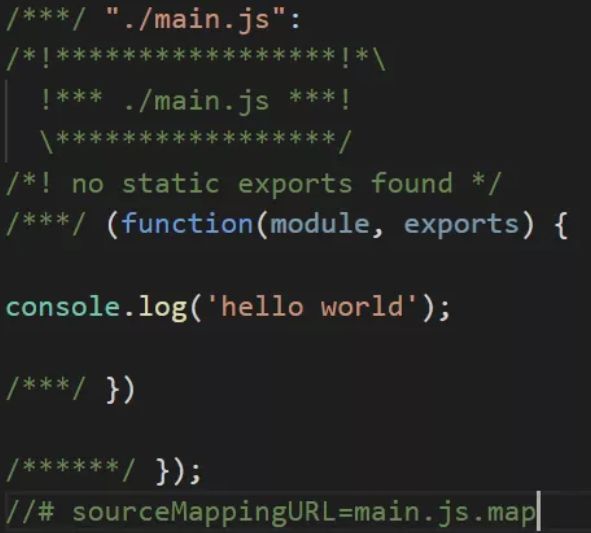
- eval
每个模块用eval()包裹执行。-
devtool: eval
我们先看看单独的eval配置,这个配置相对于其他会特殊一点 。因为配置里没有sourceMap,实际上它也会生出map,只是它映射的是转换后的代码,而不是映射到原始代码。
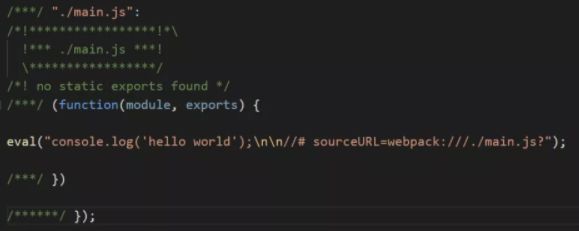 image.png
image.png -
2)devtool: eval-source-map
所以eval-source-map就会带上源码的sourceMap,打包结果如下:
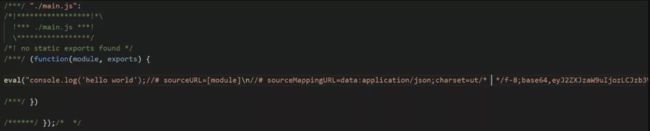 image.png
image.png
-
值得注意的是加了eval的配置生成的sourceMap会作为DataURI嵌入,不单独生成.map文件。
对于eval的构建模式,我们可以看看官方的描述:可以看出官方是比较推荐开发场景下使用的,因为它能cache sourceMap,从而rebuild的速度会比较快。
-
inline
inline配置想必大家肯定已经能猜到了,就是将map作为DataURI嵌入,不单独生成.map文件。
devtool: inline-source-map构建出来的文件如下, 这个比较好理解,就不多说了
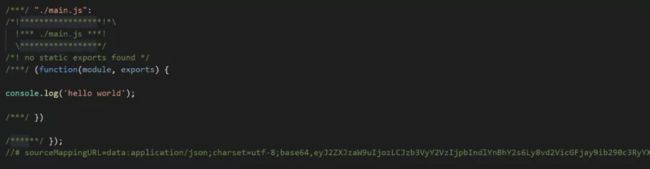 image.png
image.png cheap
这是 “cheap(低开销)” 的 source map,因为它没有生成列映射(column mapping),只是映射行数 。
为了方便演示,我们在代码加一行错误抛出:
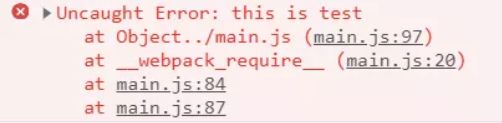
console.log('hello');
throw new Error('this is test');
可以看到错误信息只有行映射,但实际上开发时我们有行映射也基本足够了,所以开发场景下完全可以使用cheap 模式 ,来节省sourceMap的开销
- module
Webpack会利用loader将所有非js模块转化为webpack可处理的js模块,而增加上面的cheap配置后也不会有loader模块之间对应的sourceMap。
什么是模块之间的sourceMap呢?比如jsx文件会经历loader处理成js文件再混淆压缩, 如果没有loader之间的sourceMap,那么在debug的时候定义到上图中的压缩前的js处,而不能追踪到jsx中。
所以为了映射到loader处理前的代码,我们一般也会加上module配置
总结
1、开发环境
综上所述,考虑到我们在开发环境对sourceMap的要求是:快(eval),信息全(module),且由于此时代码未压缩,我们并不那么在意代码列信息(cheap),所以开发环境比较推荐配置:devtool: cheap-module-eval-source-map
2、生产环境
一般情况下,我们并不希望任何人都可以在浏览器直接看到我们未编译的源码,所以我们不应该直接提供sourceMap给浏览器。但我们又需要sourceMap来定位我们的错误信息, 这时我们可以设置hidden-source-map:
一方面webpack会生成sourcemap文件以提供给错误收集工具比如sentry,另一方面又不会为 bundle 添加引用注释,以避免浏览器使用。
当然如果没有这一类的错误处理工具,可以看看webpack推荐的其他配置:
https://www.webpackjs.com/configuration/devtool/
CSS sourceMap
说起sourceMap我们第一反应通常是JavaScript的sourceMap,实际上现在css也可以使用sourceMap。因为sourceMap本质只是一个json,里面包含了源码的映射信息。所以其实只要了解sourcemap的编码规范,我们可以对任何我们想要的资源生成sourceMap,当然sourceMap 的支持也还是要取决于浏览器的支持。
现在,对于css我们也有同样诉求,比如我现在打开调试器看到的样式配置没有任何源信息。如果想像js一样,知道这个css样式是在哪个文件需要怎么弄呢?
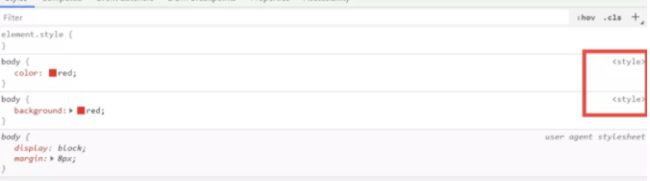
上面讲解的配置其实都是针对js的sourceMap,配置后webpack会自动帮我们生成各类js sourceMap。因为本质上webpack只处理js,对于webpack来说,css是否有sourceMap依赖于对css处理的loader是否有sourceMap输出,所以loader需要开启并传递sourceMap,这样最后生成的css才会带上sourceMap 。
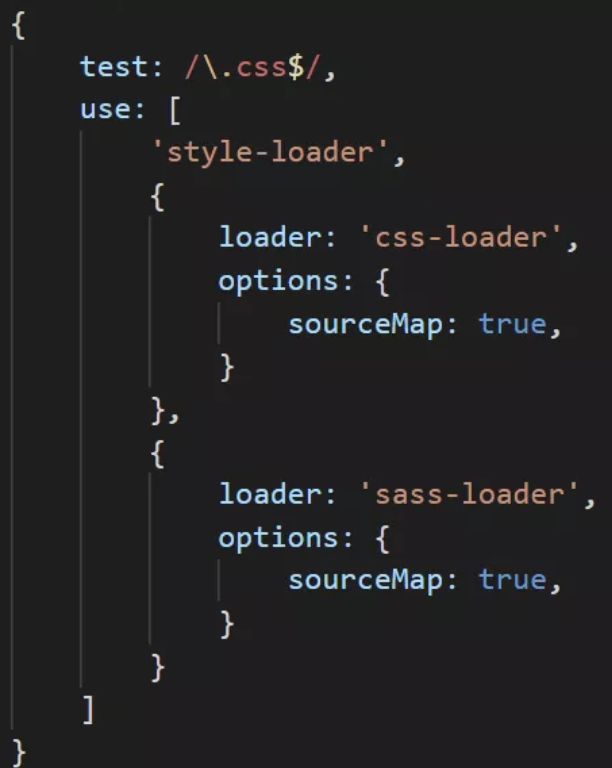
目前使用的css-loader,sass-loader都已经提供了生成sourceMap的能力,只需要我们加上配置即可。
需要注意的是,这里如果要拿到sass编译前的源码信息,那么sourceMap一定要从sass-loader一直传递到css-loader,中间如有其他loader处理,也要透传sourceMap
可以看到,加了sourceMap 配置后,sourceMap会被内联在css代码里(这一层是css-loader处理的,与你是否使用min-extract-css-plugin抽出css无关)

加了css sourceMap后,我们可以很轻松的定位到sass编译前的源码路径了。

通过debug,打印出生成的css sourceMap,和js sourceMap对比并无他样:

利用css sourceMap 解决css url resolve的问题
如果大家用了sass的话,很可能会遇到一个css url resolve的问题,在之前的一篇讲webpack 配置的文章里我也提到过:

实际上,利用css sourceMap这个问题便可以在不改变源码的情况下就可以完美解决。
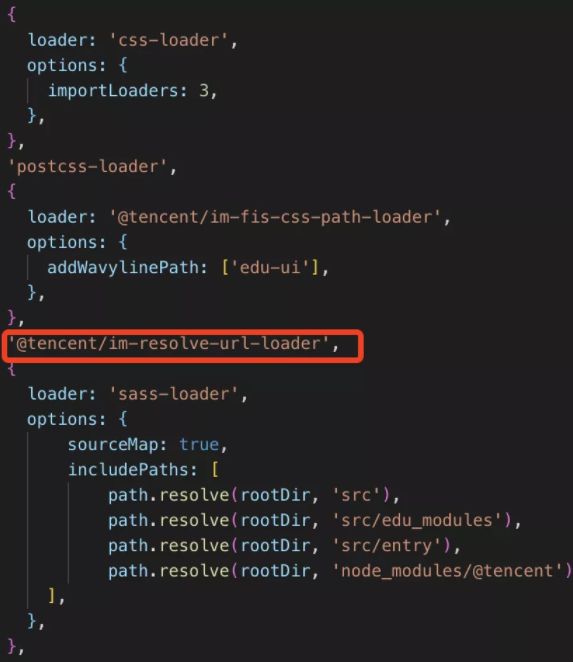
这里会增加一个loader去处理,loader处理流程主要分为二步:
1、根据sourceMap的sourcesContent和url内容进行匹配,然后从sources定位到原有的css资源路径
2、将传递给下个loader的url内容替换成绝对路径
代码如下:
module.exports = function (content, map) {
const res = content.replace(/url((?: |")?((./|../)+([^ ")]*))( |")?)/g, (str, img, p2, imgPath) => {
let index = -1;
const {sourcesContent = [], sources = [], sourceRoot = []} = map || {};
sourcesContent.some((item, i)=> {
if (item.indexOf(img) !== -1) {
index = i;
return true;
}
});
if (index !== -1) {
const dir = path.dirname(sources[index]); // 获取文件所在目录
str = str.replace(img, `~${path.join(dir, img)}`);
}
return str;
});
this.callback(null, res, map);
return;
}
因为依赖sass-loader 处理之后的sourceMap, 所以@tencent/im-resolve-url-loader应配置在sass-loader 前面,配置如下:
说明:sourcemap部分内容,完全复制前端Q公众号文章:hSourceMap知多少:介绍与实践
SVG矢量图操作
概述
svg是有一种基于xml语法的图像格式,全称是可缩放矢量图。其他图像格式都是基于像素处理的,svg则是属于对图像的形状描述,所以它本质上是文本文件,体积比较小,且不管放多少倍都不会失真。
SVG文件可以直接插入网页,成为DOM的一部分,然后js和css进行操作。
Document
上面是svg代码直接插入网页的例子。
SVG代码也可以写在一个独立文件中,然后使用img/object/iframe/embed等标签插入网页。
