最近在整理一些源码,看一些大公司的面试题时,整理出来一些比较经典的面试题,供大家巩固和参考。如果答案有什么疑问或者本人有理解错的地方,欢迎大家批评指正。
1.反射的用途及实现
反射是在运行时期间,动态的将class信息,装载到class中,动态调用和动态获取,主要用到两个类,Class 和method.invoke(owner,args) 如果是静态方法的话,则无需实例。主要用到的类有Constructor,Field,method,调用任何对象的任何方法反射用多了会有性能问题
2.自定义注解和场景的实现
自定义注解的场景:在我们项目中,有过一处的用法就是 @CurrentUser,作为全局的参数注解。可以通用一点。ElementType,Retention,Target
3.HTTP的get 和post的区别
get 和post的最大的区别就是get在请求行带有参数(只允许ascII)和url后面,参数大小一般限制在2k左右,根据浏览器不同而设置,post请求则通过表单封装,比较安全,不会造成csrf的攻击,get的回退对浏览器来说是无害的,post会重新提交。对于security层面来说,post的大小,在tomact会受到限制。同时get请求能被浏览器缓存,post则不可以。但是他们的本质都是基于TCP协议来传输的。get产生一个数据包,post则会有两个数据包。post浏览器第一次会发送header数据包,第二次才发送data
4.session和cookie的区别
session与cookie的共同点是保持访问用户与后端服务器的交互状态。cookie带信息传输费带宽,session则不容易共享,所以需要session集群。session是基于cookie工作的。cookie是存储在客服端的,session是存储在服务端的。cookie的大小有限制,不同浏览器不同。cookie有安全隐患,可以拦截本地文件,修改cookie。session有失效时间
5.hashSet底层实现,hashMap的put操作过程
private transient HashMap
private static final Object PRESENT = new Object(); //map,中键对应的value值
hashSet底层是根据hashMap来实现的,因为map无序,所以hashes也是无序的
hashMap put的过程
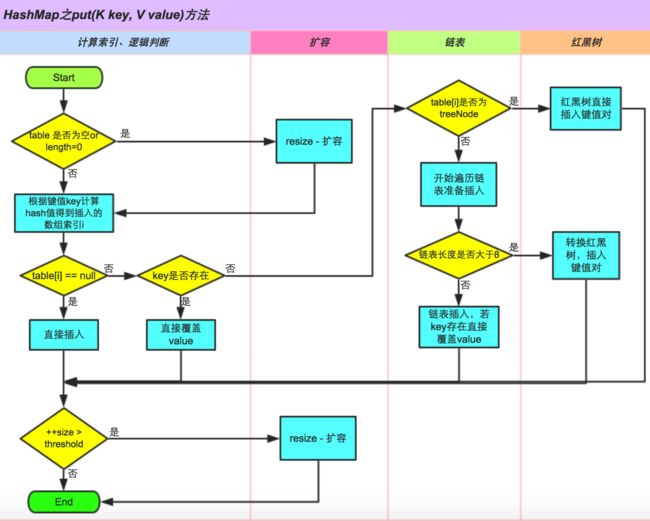
6.一致性hash算法
一致性hash算法主要应用在redis的集群定为对象。原先有的问题是直接根据缓存服务器的数量去取模,在增加服务器或者服务器宕机时,会出现雪崩的情况。所以就出现了一致性hash算法
相当于将服务器和图片分别hash到我的hash环上进行就近缓存,hash环就是对232次方进行取模,从0开始一直到232,均匀分布在一个圆环(一个比方),0的顺时针方向的第一位为1,逆时针方向第一位为2^32。在节点少的情况下会出现分配不均衡的问题,所以hash环出现了虚拟节点来平衡。优点就是当我有一台服务器挂了之后,其它节点不会受到影响,只有当前节点的用户受到影响。
7.接口和抽象类的区别 实现有哪些不同?
1).首先抽象类和抽象方法都是abstract修饰的,接口为interface修饰
2).java8 中出现了default方法,变量不用写public static final,方法不用写 public abstract
3).一个类可以实现多个接口,一个类只能继承一个父类
4).接口定义的变量只能是公共静态常量
5). 抽象类中允许有自己的方法,如果是private方法,则子类不能使用
8.序列化如何实现?用代码描述ObjectOutputStream.writeObject(),
ObjectInputStream.readObject
1).让类实现Serializable标志性接口,则表明该类可以被序列化
2).然后用ObjectOutputStream.writeObject()将该实现对象写出
3).如果需要反序列化则构建一个ObjectInputStream.readObject()读取输入对象
4).如果要想某个字段不被序列化,则可以加上transient来修饰该字段
9.IO框架如何判断文件是否存在?如何读取一个目录下面的所有文件和子目录?代码描述。
主要考察file类,file.exists() File[] files = file.listFiles();
10.缓冲流buffer的用途?原理?
以BufferedInputStream为例,其中有一个方法为fill方法,是将输入流需要读取的数据根据定义的size大小,一次性读到内存中,这样可以减少内存到磁盘的交互,因为从内存到物理磁盘的交互比较消耗性能。并且这个read方法是线程安全的
11.ArrayList源码分析;如果存取相同的数据,ArrayList 和 LinkedList 谁占用空间更大?
ArrayList的源码分析详见ArrayList深度分析疑问
ArrayList的底层结构是数组,而linkedList的底层是双向链表,所以在数据量相同的情况下,应该是linkedListed占用的内存更大,因为它需要维护指向下一个节点的指针。
12.基础类String的处理
1).String类是final的,所以不能被继承
2).使用字符串常量池,每当我们创建字符串常量时,jvm会先检查字符串常量池,如果字符串存在,则会直接返回字符串常量池当中的引用
3).String a = new String(“aa”) 实际上是创建了两个对象。类加载过程中创建了一个,代码允许时堆上创建了一个
4).String 创建对象时,要看是不是在编译期就能确定对象类型
5).使用包含变量的字符串连接符如"aa" + s1创建的对象是运行期才创建的,存储在heap中
6).关于String.intern()
intern方法使用:一个初始为空的字符串池,它由类String独自维护。当调用 intern方法时,如果池已经包含一个等于此String对象的字符串(用equals(oject)方法确定),则返回池中的字符串。否则,将此String对象添加到池中,并返回此String对象的引用。
它遵循以下规则:对于任意两个字符串 s 和 t,当且仅当 s.equals(t) 为 true 时,s.intern() == t.intern() 才为 true。产生的差异在于在jdk1.6中 intern 方法会把首次遇到的字符串实例复制到永久待(常量池)中,并返回此引用;但在jdk1.7中,只是会把首次遇到的字符串实例的引用添加到常量池中(没有复制),并返回此引用。
7).string效率低下的原因:每做一次 + 就产生个StringBuilder对象,然后append后就扔掉。下次循环再到达时重新产生个StringBuilder对象,然后 append 字符串,如此循环直至结束。 如果我们直接采用 StringBuilder 对象进行 append 的话,我们可以节省 N - 1 次创建和销毁对象的时间。所以对于在循环中要进行字符串连接的应用,一般都是用StringBuffer或StringBulider对象来进行append操作。
13.Object 的 hashcode 方法重写了,equals 方法要不要改
不需要,因为重写了equals方法,hashcode一定要重写,相反并不成立。因为即使hashcode相等,equals并不一定相等
14.Object 类中的方法
toString(),wait(),notify(),notifyAll(),hashCode(),equals(),finalize(),clone(),getClass(),(RegisterNatives()从你自己的库中的本机代码调用JNI函数),使用clone方法的同时,不能用final,final的值是不能被覆盖的
15.前端浏览器地址的一个 http 请求到后端整个流程是怎么样?能够说下吗?https是如何保证数据安全的
根据地址栏输入的地址向DNS(Domain Name System)查询IP
通过IP向服务器发起TCP连接
向服务器发起请求
服务器返回请求内容
浏览器开始解析渲染页面并显示
关闭连接
https是通过ca证书,加非对称加密的方式来保证数据传输的安全性