引入
我们在使用mysql数据库时,习惯使用int型作为主键,并设置为自增,这既能够保证唯一,使用起来又很方便,但int型的长度是有限的,如果超过长度怎么办呢?
暴露问题
我们先创建一个测试表,创建语句如下:
CREATE TABLE test1 ( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20) )
然后我们插入两条数据:
INSERT INTO test1 VALUES(NULL,'小牛'); INSERT INTO test1 VALUES(NULL,'大牛');
查询表显示正常:
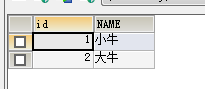
int型的有符号的范围为231 -1 = 2147483647,我们直接插入一条数据id为2147483647,如下:
INSERT INTO test1 VALUES(2147483647 ,'小华')
结果显示正常:

此时自增ID已达到了int型的上限,如果我再插入数据,就会报错:
INSERT INTO test1 VALUES(NULL,'母牛');
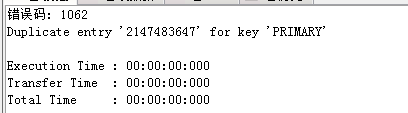
此时主键已无法自增,插入的id仍然是2147483647,就违反了主键唯一的条件,所以报错。
解决问题
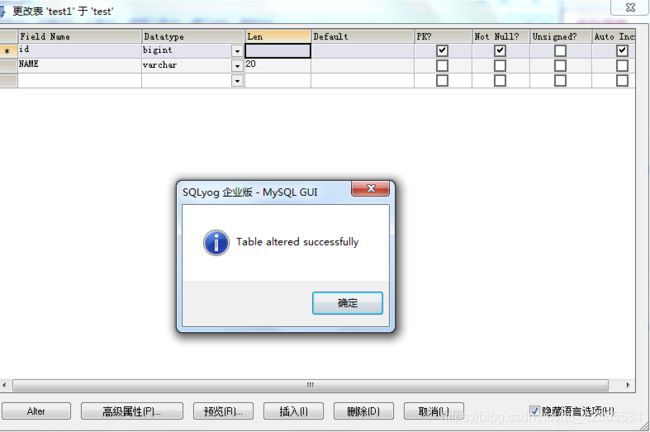
(1)使用更大的数据类型bigint
bigint的范围是263-1,所谓指数爆炸,此时的大小达到了9,223,372,036,854,775,807的可怕量级,简单来说就是用bigint 一天100w条数据也得存200亿年才能自增爆炸,所以在当前场景,几乎不用担心bigint会自增满
我们修改数据类型为bigint,如图
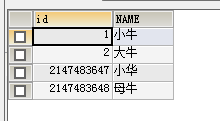
再执行插入语句:
INSERT INTO test1 VALUES(NULL,'母牛');
又能够正常插入了:
(2)使用UUID作为主键
我们都知道,UUID会根据当前系统性能,时间戳等一系列参数经过运算得到一个全世界唯一的字符串,并且mysql提供了生成UUID的方法,用它作为主键能够保证数据的唯一性。
利用如下代码可以生成32位的UUID:
-- 生成32位UUID SELECT REPLACE(UUID(),'-','') AS UUID;
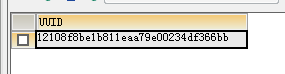
然后咱们再创建一个测试表:
CREATE TABLE test2( id VARCHAR(50) PRIMARY KEY, NAME VARCHAR(20) NOT NULL )
插入一条数据:
-- 插入UUID INSERT INTO test2 VALUES(REPLACE(UUID(),'-',''),'老王');
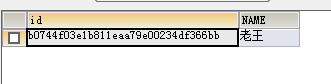
但这样写插入语句每次都要手写UUID函数,貌似有点太麻烦了,咱们可以写一个触发器,让触发器自动为我们设置ID:
-- 创建触发器 DELIMITER $$ CREATE TRIGGER auto_id -- 名称 BEFORE INSERT -- 触发时机 ON test2 FOR EACH ROW -- 作用于test2表,对每行数据生效 BEGIN IF new.id = '' THEN -- 当id为空字符串时设置UUID SET new.id = REPLACE(UUID(),'-',''); END IF; END$$
插入一条数据:
-- 插入一条数据
INSERT INTO test2 VALUES('','小王');
结果能正常添加

总结
(1) 用int型和bigInt型增删改查速度较UUID更快,并且更节省空间。
(2) 用UUID更方便。
为何要使用自增int作为主键
相信大家都知道要使用无符号自增int作为主键的数据类型,可你知道为何要使自用增int而不是使用varchar、text、varchar等类型吗?
大家也能说出一些优点:对上层业务透明,插入数据时无需显示指定;数据类型简单,更便于存储维护表结构
其实,使用自增int作为主键好处多多,今天我们就来一起学习一下,并强烈建议大家在实际开发中使用自增int作为主键。
优点:
1、int 相比varchar、char、text使用更少的存储空间,而且数据类型简单,可以节约CPU的开销,更便于表结构的维护
2、默认都会在主键上建立主键索引,使用整形作为主键可以将更多的索引载入内存,提高查询性能
3、对于InnoDB存储引擎而言,每个二级索引都会使用主键作为索引值的后缀,使用自增主键可以减少索引的长度(大小),方便更多的索引数据载入内存
4、可以使索引数据更加紧凑,在数据插入、删除、更新时可以做到索引数据尽可能少的移动、分裂页,减少碎片的产生(可以通过optimize table 来重建表),减少维护开销
5、在数据插入时,可以保证逻辑相邻的元素物理也相邻,便于范围查找
当然,使用自增int作为主键也不是百利无一害,在高并发的情况下也可能会造成锁的争用问题。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。