IN为什么慢?
在应用程序中使用子查询后,SQL语句的查询性能变得非常糟糕。例如:
SELECT driver_id FROM driver where driver_id in (SELECT driver_id FROM driver where _create_date > '2016-07-25 00:00:00');
独立子查询返回了符合条件的driver_id,这个问题是解决了,但是所用的时间需要6秒,可以通过EXPLAIN查看SQL语句的执行计划:

可以看到上面的SQL语句变成了相关子查询,通过EXPLAIN EXTENDED 和 SHOW WARNINGS命令,可以看到如下结果:
可以看出MySql优化器直接把IN子句转换成了EXISTS的相关子查询。下面这条相关IN子查询:
SELECT driver_id FROM driver where driver_id in (SELECT driver_id FROM user where user.uid = driver.driver_id);
查看SQL语句的执行计划:

就是相关子查询,通过EXPLAIN EXTENDED 和 SHOW WARNINGS命令,看到如下结果:
可以看出无论是独立子查询还是相关子查询,MySql 5.5之前的优化器都是将IN转换成EXISTS语句。如果子查询和外部查询分别返回M和N行,那么该子查询被扫描为O(N+N*M),而不是O(N+M)。这也就是为什么IN慢的原因。
IN和EXISTS哪个快?
网上百度到很多认为IN和EXISTS效率一样是错误的文章。
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
例如:表A(小表),表B(大表)
1:
select * from A where cc in (select cc from B) 效率低,用到了A表上cc列的索引;
select * from A where exists(select cc from B where cc=A.cc) 效率高,用到了B表上cc列的索引。
相反的
2:
select * from B where cc in (select cc from A) 效率高,用到了B表上cc列的索引;
select * from B where exists(select cc from A where cc=B.cc) 效率低,用到了A表上cc列的索引。
总结上面的描述,个人认为其主要的原因在于对索引的使用。任何情况下,只要是大表的索引被使用,就可以使效率提高。
但是在编辑本文的时候,多次测试,却没能得到上面所总结的结果。下面是测试SQL语句,先是外表为大表,内表为小表。(示例一)
SELECT count(driver_id) FROM driver where driver_id in (SELECT uid FROM user); SELECT count(driver_id) FROM driver where exists (SELECT 1 FROM user where uid = driver.driver_id);
执行结果是:
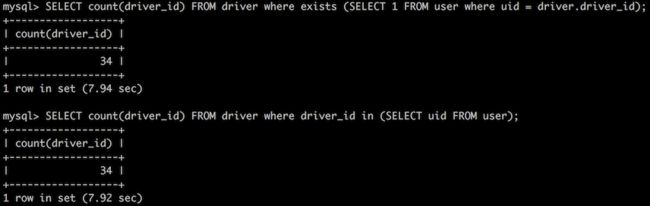
再是外表是小表,内表是大表。(示例二)
select count(uid) from user where uid in (SELECT driver_id FROM driver); select count(uid) from user where exists (SELECT 1 FROM driver where driver.driver_id = user.uid);
执行结果是:
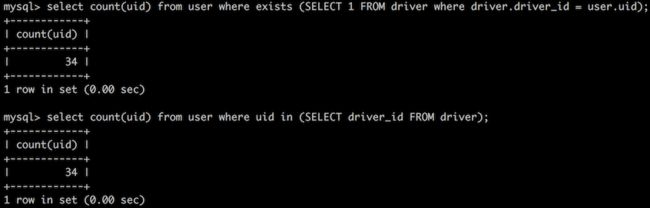
可以发现IN和EXISTS的执行效率,在任何情况下都正好是相同的。基于此,我们继续查看示例一两条SQL语句的执行计划,如下:
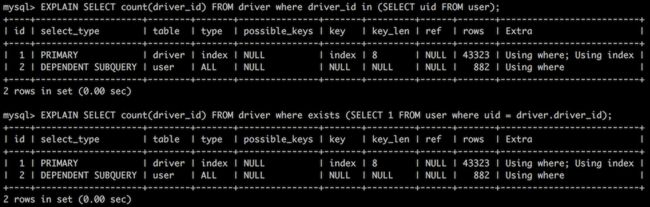
可以看到IN和EXISTS的执行计划是一样的,对此得出的结论两者的执行效率应该是一样的。
《MySql技术内幕:SQL编程》:书中描述的确实有很多DBA认为EXISTS比IN的执行效率更高,可能是当时优化器还不是很稳定和足够优秀,但是目前绝大数的情况下,IN和EXISTS都具有相同的执行计划。
如何提高效率?
上面示例二中的SQL语句执行时间约8秒,因为存在M*N的原因造成慢查询,但是还是可以进行优化,注意到慢的原因就是内部每次与外部比较时,都需要遍历一次表操作,可以采用另外一个方法,在嵌套一层子查询,避免多次遍历操作,语句如下:
SELECT count(driver_id) FROM driver where exists (SELECT uid FROM (SELECT uid from user) as b where b.uid = driver.driver_id);
执行效果如图:

可以发现优化减少了6s多的执行时间,下面是SQL的执行计划:

同样的还是相关子查询,但是减少了内部遍历查询的操作。所以可以通过预查询来减少遍历操作,而提高效率。
其实在实际编程中,很多开发人员选择不使用连接表查询,而是自己先把数据从一张表中取出,再到另一张表中执行WHEREIN操作,这原理和上面SQL语句实现的是一样的。
MySQL5.6对子查询的优化?
SEMI JOIN策略
优化器会识别出需要子查询的IN语句以便从区域表返回每个区域键的一个实例。这就导致了MySQL会以半连接的方式执行SELECT语句,所以全局表中每个区域只会有一个实例与记录相匹配。
半连接和常规连接之间存在两个非常重要的区别:
- 在半连接中,内表不会导致重复的结果。
- 此操作不会有内表中的字段添加到结果中去。
因此,半连接的结果常常是来自外表记录的一个子集。从有效性上看,半连接的优化在于有效的消除了来自内表的重复项,MySQL应用了四个不同的半连接执行策略用来去重。
Table Pullout优化
Convert the subquery to a join, or use table pullout and run the query as an inner join between subquery tables and outer tables. Table pullout pulls a table out from the subquery to the outer query.将子查询转变为一个连接,或是利用table pullout并将查询作为子查询表和外表之间的一个内连接来执行。Table pullout会为外部查询从子查询抽取出一个表。
有些时候,一个子查询可以被重写为JOIN,例如:
SELECT OrderID FROM Orders where EmployeeID IN (select EmployeeID from Employees where EmployeeID > 3);
如果知道OrderID是唯一的,即主键或者唯一索引,那么SQL语句会被重写为Join形式。
SELECT OrderID FROM Orders join Employees where Orders.EmployeeID = Employees.EmployeeID and Employees.EmployeeID > 3;
Table pullout的作用就是根据唯一索引将子查询重写为JOIN语句,在MySql 5.5中,上述的SQL语句执行计划:

如果通过EXPLAIN EXTENDED 和 SHOW WARNINGS命令,可以看到如下结果:
正是上面说的in为什么慢?
在MySql 5.6中,优化器会对SQL语句重写,得到的执行计划:

在MySql 5.6中,优化器没有将独立子查询重写为相关子查询,通过EXPLAIN EXTENDED 和 SHOW WARNINGS命令,得到优化器的执行方式为:
很显然,优化器将上述子查询重写为JOIN语句,这就是Table Pullout优化。
Duplicate Weedout优化
Run the semi-join as if it was a join and remove duplicate records using a temporary table.执行半连接,就如同它是一个连接并利用临时表移除了重复的记录。
上面内部表查出的列是唯一的,因此优化器会将子查询重写为JOIN语句,以提高SQL执行的效率。Duplicate Weedout优化是指外部查询条件是列是唯一的,MySql优化器会先将子查询查出的结果进行去重。比如下面这条SQL语句:
SELECT ContactName FROM Customers where CustomerID in (select CustomerID from Orders where OrderID > 10000 and Customers.Country = Orders.ShipCountry);
因为CustomerID是主键,所以应该对子查询得到的结果进行去重。在MySql 5.6中的执行计划:

Extra选项提示的Start temporary表示创建一张去重的临时表,End temporary表示删除该临时表。而通过EXPLAIN EXTENDED 和 SHOW WARNINGS命令,得到优化器的执行方式为:
与Table Pullout优化不同的是,显示的是semi join而不是join,其中原因在于多了一些去重的工作,对于上述的执行计划,其扫描成本约为830+830*1=1660次。
而在MySql 5.5中的执行计划为:

可以看到,在MySql 5.5中还是将语句转化为相关子查询,扫描成本约为93+93*9=930次。
我们可以看到MySql 5.6优化以后比5.5的扫描成本反而大,其实这只是在两张表较小的的情况下的结果,如果表很大,优化的效果会非常明显。
Materialization优化
Materialize the subquery into a temporary table with an index and use the temporary table to perform a join. The index is used to remove duplicates. The index might also be used later for lookups when joining the temporary table with the outer tables; if not, the table is scanned.
上面的子查询是相关子查询,如果子查询是独立子查询,则优化器可以选择将独立子查询产生的结果填充到单独一张物化临时表中,如图:

根据JOIN的顺序,Materialization优化可分为:
- Materialization scan:JOIN是将物化临时表和表进行关联。
- Materialization lookup:JOIN是将表和物化临时表进行关联。
下面的子查询可以利用Materialization来进行优化:
SELECT OrderID FROM Orders where OrderID in (select OrderID from `Order Details` where UnitPrice < 50 );
SQL语句的执行计划:

可以看到,在进行JOIN时(也就是id为1的步骤),先扫描的表是Orders,然后是subquery2,因此这是Materialization lookup的优化。对于下面的SQL:
select * FROM driver where driver_id in (select uid from user);
SQL语句的执行计划:

先扫描的是subquery2,再是driver表,这就是Materialization scan的优化。
FirstMacth优化
When scanning the inner tables for row combinations and there are multiple instances of a given value group, choose one rather than returning them all. This "shortcuts" scanning and eliminates production of unnecessary rows.为了对记录进行合并而在扫描内表,并且对于给定值群组有多个实例时,选择其一而不是将它们全部返回。这为表扫描提供了一个早期退出机制而且还消除了不必要记录的产生。
半连接的最先匹配(FirstMatch)策略执行子查询的方式与MySQL稍早版本中的IN-TO-EXISTS是非常相似的。对于外表中的每条匹配记录,MySQL都会在内表中进行匹配检查。当发现存在匹配时,它会从外表返回记录。只有在未发现匹配的情况下,引擎才会回退去扫描整个内表。
LooseScan优化
Scan a subquery table using an index that enables a single value to be chosen from each subquery's value group.利用索引来扫描一个子查询表可以从每个子查询的值群组中选出一个单一的值。
SEMI JOIN变量
Each of these strategies except Duplicate Weedout can be enabled or disabled using the optimizer_switch system variable. The semijoin flag controls whether semi-joins are used. If it is set to on, the firstmatch, loosescan, and materialization flags enable finer control over the permitted semi-join strategies. These flags are on by default.除Duplicate Weedout之外的每个策略可以用变量控制开关,semijoin控制semi-joins优化是否开启,如果设置开启,其他的策略也有独立的变量控制。所有的变量在5.6默认是打开的。
mysql> SELECT @@optimizer_switch\G; *************************** 1. row *************************** @@optimizer_switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on 1 row in set (0.00 sec)
EXPLAIN查看策略
- Semi-joined tables show up in the outer select. EXPLAIN EXTENDED plus SHOW WARNINGS shows the rewritten query, which displays the semi-join structure. From this you can get an idea about which tables were pulled out of the semi-join. If a subquery was converted to a semi-join, you will see that the subquery predicate is gone and its tables and WHERE clause were merged into the outer query join list and WHERE clause.
- Temporary table use for Duplicate Weedout is indicated by Start temporary and End temporary in the Extra column. Tables that were not pulled out and are in the range of EXPLAIN output rows covered by Start temporary and End temporary will have their rowid in the temporary table.
- FirstMatch(tbl_name) in the Extra column(列) indicates join shortcutting.
- LooseScan(m..n) in the Extra column indicates use of the LooseScan strategy. m and n are key part numbers.
- As of MySQL 5.6.7, temporary table use for materialization is indicated by rows with a select_type value of MATERIALIZED and rows with a table value of .
- Before MySQL 5.6.7, temporary table use for materialization is indicated in the Extra column by Materialize if a single table is used, or by Start materialize and End materialize if multiple tables are used. If Scan is present, no temporary table index is used for table reads. Otherwise, an index lookup is used.
上面介绍中FirstMacth优化、LooseScan优化的具体效果没有很好的例子去显示出来。有机会可以交流学习。
参考
《MySql技术内幕:SQL编程》
http://dev.mysql.com/doc/refman/5.6/en/subquery-optimization.html
http://tech.it168.com/a2013/0506/1479/000001479749.shtml
到此这篇关于MySql子查询IN的执行和优化的实现的文章就介绍到这了,更多相关MySql子查询IN 内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!