AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE

刚入这块的小白,写个博客督促自己深入弄懂文献,仅为个人理解。
其中代码来自https://github.com/lucidrains/vit-pytorch
这篇文章最大的创新点就是把transformer给运用到了cv中,做了一个图像分类,但是这个模型的性能依赖于pretrain。
方法(ViT)
这个主要分成四步。
①
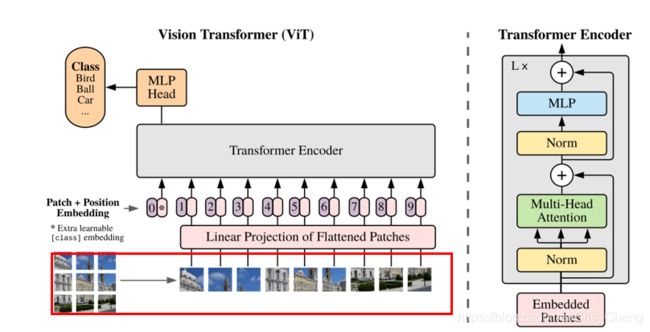
因为transformer的输入是一个序列,而图片是一个三维的,所以先得把图像给转化成序列数据。将H×W×C的图片切分成N个P×P×C的图像块,其中序列长度N=H×W/P²,然后将每个图片转换成一维的向量表示P²C,就是文中所说的flatte patche。
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=p, p2=p)
PS:这里之前纠结了好久,这化块后只知道维度,并不知道具体数值什么的,难道不需要整个CNN取提取特征图什么的?后来问了师兄才知道其实图片本身传入计算机中都是有像素数值表示的,范围是0到255,这里是直接以数值作为编码的。(我可能是个憨憨=-=)
②

![]()
这里用了一个patch embedding,即将第一步得到的一维的向量表示,1×P²C,其维度会随着P的改变而改变,为了固定这个维度,所以此处做了一个线性变换,将维度固定为D维,现在原本的图片已经变成了N个D维的向量。(所谓的embedding,就是乘一个矩阵W,改变输出结果的维度,其中权重矩阵最初是随机初始化的,后面是可以学习的)
公式(1)中的XpE这部分就是patch embedding。
#线性变换其实就是个全连接层?
self.patch_to_embedding = nn.Linear(patch_dim, dim)
# forward前向代码
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=p, p2=p)
x = self.patch_to_embedding(x)
接着就是position embedding,为了充分利用序列的顺序信息,原始的transformer引入了一个 positional encoding 来加入序列的位置信息,就是图中的0-9。
然后采用position embedding(紫色框) + patch embedding(粉色框)方式来结合position信息。
即公式(1)中的Epos,关于维度问题,position维度是(N+1)×D,是因为除了N个序列外,还有一个额外的Xclass,所以序列长度变成了(N+1),把这些码在一起就变成了了(N+1)×D的一个二维矩阵。
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
关于这个Xclass的问题,Xclass就是一个learnable embedding,就是图中那个带星号的粉色框。
Xclass是可学习的,它与图片label有关,预训练用一个隐藏层的MLP,微调用线性层。
和BERT相类似,BERT在第一句前添加一个[CLS]标志位,最后一层该标志位对应的向量可以作为整句话的语义表示,从而用于下游的分类任务等。
将[CLS]标志位对应的向量作为整个文本的语义表示,是因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
(关于BERT目前我也不了解,下来还是得去把BERT整明白。。。)
# 假设dim=128,这里shape为(1, 1, 128)
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
# forward前向代码
# 假设batchsize=10,这里shape为(10, 1, 128)
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b)
# 跟前面的分块为x(10,64, 128)的进行concat
# 得到(10, 65, 128)向量
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
③
![]()
将前面得到的初始的Z0作为transformer的初始输入,
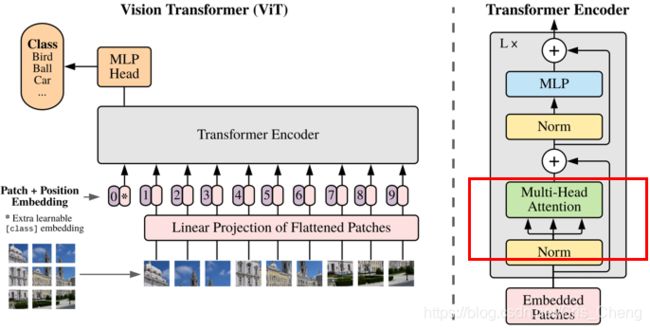
transformer encoder 是由多个MSA和MLP块交替组成的,每次在MSA和MLP前都要进行LN归一化:
![]()
为什么采用LN?LN其实就是在每个样本上都计算均值和方差,将输入数据转化成均值为0,方差为1的数据。而不采用BN是因为,batchnorm是对一批样本中进行归一化,而layernorm是对每一个样本进行一次归一化,而此处输入的N+1个序列,每个序列的长度可能是不同的。而且transformer原始论文用的就是LN。。。
在每个MSA和MLP后都加了残差网络。(防止梯度弥散)
④

![]()
MLP:就是一个两层的全连接层,采用了GELU激活函数。
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, mlp_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim, num_classes)
)
总:
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, channels=3, dropout=0.,
emb_dropout=0.):
super().__init__()
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_size // patch_size) ** 2
patch_dim = channels * patch_size ** 2
assert num_patches > MIN_NUM_PATCHES, f'your number of patches ({num_patches}) is way too small for attention to be effective (at least 16). Try decreasing your patch size'
self.patch_size = patch_size
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.patch_to_embedding = nn.Linear(patch_dim, dim)
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, mlp_dim, dropout)
self.to_cls_token = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, mlp_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim, num_classes)
)
def forward(self, img, mask=None):
p = self.patch_size
x = self.patch_to_embedding(x)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x, mask)
x = self.to_cls_token(x[:, 0])
return self.mlp_head(x)
混合结构
将transformer和CNN结合,即将ResNet的中间层的feature map作为transformer的输入。
微调
先在large数据集上进行预训练,然后针对小规模的下游任务对模型进行微调。移除预训练的预测头,添加一个零初始化的D×K前馈层,其中K是下游任务中类的数量。
与预训练相比,在更高分辨率时进行微调通常更有好。当输入更高分辨率的图像时,保持 patch 大小不变,从而得到更大的有效序列长度(记分辨率增大后新的patch个数为N’)。但是在预训练时,position embedding的个数和pretrain时分割得到的patch个数(N )相同,则多出来的(N’-N) 个positioin embedding在pretrain中是未定义或者无意义的。将pretrain中的N个position embedding插值成 N’ 个。这样在得到N’个position embedding的同时也保证了position embedding的语义信息。
(目前并没有特别理解这段话。。。)
实验
消融实验。
参考:
https://zhuanlan.zhihu.com/p/317756159
https://zhuanlan.zhihu.com/p/266311690