阿里AI天池大赛-阿里云安全恶意程序检测-TF-IDF特征+XGBoost与LightGBM模型融合
1:报名地址
https://tianchi.aliyun.com/competition/entrance/231694/rankingList
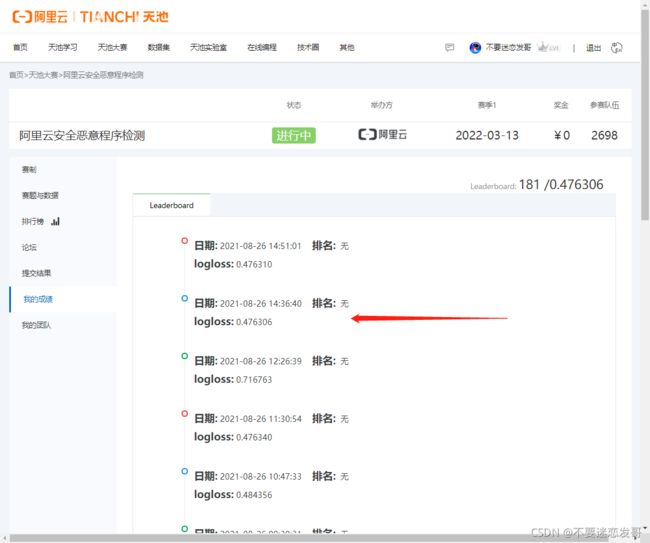
2:排名分数

3:模型源码
废话不多说,直接上源码
import pandas as pd
# 分段数据加载基础方法
def get_data(file_name):
result = []
chunk_index = 0
for df in pd.read_csv(open(file_name, 'r'), chunksize = 1000000):
result.append(df)
#print('chunk', chunk_index)
chunk_index += 1
result = pd.concat(result, ignore_index=True, axis=0)
return result
#数据加载
test = get_data('./security_test.csv')
train = get_data('./security_train.csv')
#将数据采用pickle方式存储
import pickle
with open('./train.pkl', 'wb') as file:
pickle.dump(train,file)
with open('./test.pkl', 'wb') as file:
pickle.dump(test,file)
import pandas as pd
# 对api字段进行LabelEncoder
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
# 将训练集 和 测试集进行合并
df_all = pd.concat([train, test])
df_all['api'] = le.fit_transform(df_all['api'])
df_all[['api']]
# 提取train['api']
train['api'] = df_all[df_all['label'].notnull()]['api']
test['api'] = df_all[df_all['label'].isnull()]['api']
#定义重要特征,主要包括数量,最大值,最小值,平均值等等
def get_features(df):
df_file = df.groupby('file_id')
if 'label' in df.columns:
df1 = df.drop_duplicates(subset=['file_id', 'label'], keep='first')
else:
df1 = df.drop_duplicates(subset=['file_id'], keep='first')
df1 = df1.sort_values('file_id')
features = ['api', 'tid', 'index']
for f in features:
df1[f+'_count'] = df_file[f].count().values
df1[f+'_nunique'] = df_file[f].nunique().values
df1[f+'_min'] = df_file[f].min().values
df1[f+'_max'] = df_file[f].max().values
df1[f+'_mean'] = df_file[f].mean().values
df1[f+'_median'] = df_file[f].median().values
df1[f+'_std'] = df_file[f].std().values
df1[f+'_ptp'] = df1[f+'_max'] - df1[f+'_min']
return df1
#训练集与测试集添加特征
df_train = get_features(train)
df_test = get_features(test)
#将特征的结果集保持,一遍后续直接使用
df_train.to_pickle('.df_train.pkl')
df_test.to_pickle('./df_test.pkl')
#再次加载原始的训练集与测试集
with open('./train.pkl', 'rb') as file:
train = pickle.load(file)
with open('./test.pkl', 'rb') as file:
test = pickle.load(file)
def get_apis(df):
# 按照file_id进行分组
group_fileid = df.groupby('file_id')
# 统计file_id 和对应的 api_sequence
file_api = {}
# 计算每个file_id的api_sequence
for file_id, file_group in group_fileid:
# 针对file_id 按照线程tid 和 顺序index进行排序
result = file_group.sort_values(['tid', 'index'], ascending=True)
#得到api的调用序列
api_sequence = ' '.join(result['api'])
#print(api_sequence)
file_api[file_id] = api_sequence
return file_api
train_apis = get_apis(train)
test_apis=get_apis(test)
with open('./df_train.pkl', 'rb') as file:
df_train = pickle.load(file)
with open('./df_test.pkl', 'rb') as file:
df_test = pickle.load(file)
df_train.drop(['api','tid','index'],axis=1,inplace=True)
df_test.drop(['api','tid','index'],axis=1,inplace=True)
temp = pd.DataFrame.from_dict(train_apis, orient='index', columns=['api'])
temp = temp.reset_index().rename(columns={'index': 'file_id'})
df_train = df_train.merge(temp, on='file_id', how='left')
temp = pd.DataFrame.from_dict(test_apis, orient='index', columns=['api'])
temp = temp.reset_index().rename(columns={'index': 'file_id'})
df_test = df_test.merge(temp, on='file_id', how='left')
df_all = pd.concat([df_train, df_test], axis=0)
from sklearn.feature_extraction.text import TfidfVectorizer
#使用1-3元语法(1元语法 + 2元语法 + 3 元语法)
vec=TfidfVectorizer(ngram_range=(1,3),min_df=0.01)
api_features=vec.fit_transform(df_all['api'])
df_apis = pd.DataFrame(api_features.toarray(), columns=vec.get_feature_names())
df_apis.to_pickle('./df_apis.pkl')
df_train_apis=df_apis[df_apis.index<=13886]
df_test_apis=df_apis[df_apis.index>13886]
df_test_apis.index=range(len(df_test_apis))
# 将tfidf特征 与原特征进行合并
df_train = df_train.merge(df_train_apis, left_index=True, right_index=True)
df_test = df_test.merge(df_test_apis, left_index=True, right_index=True)
df_train.to_pickle('./df_train2.pkl')
df_test.to_pickle('./df_test2.pkl')
df_train.drop('api', axis=1, inplace=True)
df_test.drop('api', axis=1, inplace=True)
#LightGBM模型
import lightgbm as lgb
clf = lgb.LGBMClassifier(num_leaves=2**5-1,reg_alpha=0.25,reg_lambda=0.25,objective='multiclass', max_depth=-1,learning_rate=0.005,min_child_sample=3,random_state=2021,
n_estimators=2000,subsample=1,colsample_bytree=1)
clf.fit(df_train.drop(['label'],axis=1),df_train['label'])
result = clf.predict_proba(df_test)
result
result_lgb = pd.DataFrame(result, columns=['prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7'])
result_lgb['file_id'] = df_test['file_id'].values
result_lgb
#XGBoost模型
import xgboost as xgb
model_xgb = xgb.XGBClassifier(
max_depth=5, learning_rate=0.005, n_estimators=3250,
objective='multi:softprob', tree_method='auto',
subsample=0.8, colsample_bytree=0.8,
min_child_samples=3, eval_metric='logloss', reg_lambda=0.5)
model_xgb.fit(df_train.drop('label', axis=1), df_train['label'])
result_xgb = model_xgb.predict_proba(df_test)
result_xgb = pd.DataFrame(result_xgb, columns=['prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7'])
result_xgb['file_id'] = df_test['file_id'].values
# 对两个模型的结果 进行加权平均
result = result_lgb.copy()
weight_lgb, weight_xgb = 0.5, 0.5
result['prob0'] = result['prob0'] * weight_lgb + result_xgb['prob0'] * weight_xgb
result['prob1'] = result['prob1'] * weight_lgb + result_xgb['prob1'] * weight_xgb
result['prob2'] = result['prob2'] * weight_lgb + result_xgb['prob2'] * weight_xgb
result['prob3'] = result['prob3'] * weight_lgb + result_xgb['prob3'] * weight_xgb
result['prob4'] = result['prob4'] * weight_lgb + result_xgb['prob4'] * weight_xgb
result['prob5'] = result['prob5'] * weight_lgb + result_xgb['prob5'] * weight_xgb
result['prob6'] = result['prob6'] * weight_lgb + result_xgb['prob6'] * weight_xgb
result['prob7'] = result['prob7'] * weight_lgb + result_xgb['prob7'] * weight_xgb
columns = ['file_id', 'prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7']
result.to_csv('./0.47.csv', index=False, columns=columns)4:提分要领
1:单个模型,例如只使用XGBoost模型,经过测试只达到了0.72分
2:该源码中模型融合是提分的关键,此处是直接采用五五分,将预测结果直接进行加权计算,关于模型融合,可以自行调整其中权重,或者基于预测结果计算之后加权。
3:TF-IDF特性也是此处的提分关键。
5:知识扩展
1:大数据处理(chunksize)
chunksize使用: pandas使用chunksize分块处理大型csv文件
chunksize,单个IO大小,设置越大占用内存高,需要的iteration少,速度快
方法1: for df in pd.read_csv(open(file_name, 'r'), chunksize = 100000):
方法2: # 获取读文件指针 data=pd.read_csv(filename, iterator=True)
# 顺序读取100000行数据 chunk = data.get_chunk(100000)
2:N-Gram特征
基于一个假设:第n个词出现与前n-1个词相关,而与其他任何词不相关.
N=1时为unigram,N=2为bigram,N=3为trigram
N-Gram指的是给定一段文本,其中的N个item的序列
比如文本:A B C D E,对应的Bi-Gram为A B, B C, C D, D E
当一阶特征不够用时,可以用N-Gram做为新的特征。比如在处理文本特征时,一个关键词是一个特征,但有些情况不够用,需要提取更多的特征,采用N-Gram => 可以理解是相邻两个关键词的特征组合。
3:TF-IDF计算
TF:Term Frequency,词频 一个单词的重要性和它在文档中出现的次数呈正比。
IDF:Inverse Document Frequency,逆向文档频率
一个单词在文档中的区分度。这个单词出现的文档数越少,区分度越大,IDF越大。
4:常见的特征工程
提取字段的个数 count()
唯一值个数 nunique()
统计特征 min, max, mean, std,ptp
5:模型选择先用哪个
使用LightGBM 祖传参数
clf = lgb.LGBMClassifier(
num_leaves=2**5-1, reg_alpha=0.25, reg_lambda=0.25, objective='multiclass',
max_depth=-1, learning_rate=0.005, min_child_samples=3, random_state=2021,
n_estimators=2000, subsample=1, colsample_bytree=1)
使用XGBoost
model_xgb = xgb.XGBClassifier(
max_depth=9, learning_rate=0.005, n_estimators=2000,
objective='multi:softprob', tree_method='gpu_hist',
subsample=0.8, colsample_bytree=0.8,
min_child_samples=3, eval_metric='logloss', reg_lambda=0.5)
6:XGBoost与LightGBM模型融合,效果会有提升吗
不一定,可能会下降