MediaPipe 集成人脸识别,人体姿态评估,人手检测模型
上期文章,我们介绍了MediaPipe Holistic的基础知识,了解到MediaPipe Holistic分别利用MediaPipe Pose,MediaPipe Face Mesh和MediaPipe Hands中的姿势,面部和手界标模型来生成总共543个界标(每手33个姿势界标,468个脸部界标和21个手界标)。
对于姿势模型的精度足够低以至于所得到的手的ROI仍然不够准确的情况,但我们运行附加的轻型手重新裁剪模型,该模型起着的作用,并且仅花费了手模型推断时间的10%左右。

MediaPipe
MediaPipe 是一款由 Google Research 开发并开源的多媒体机器学习模型应用框架。在谷歌,一系列重要产品,如 、Google Lens、ARCore、Google Home 以及 ,都已深度整合了 MediaPipe。

MediaPipe图片检测
作为一款跨平台框架,MediaPipe 不仅可以被部署在服务器端,更可以在多个移动端 (安卓和苹果 iOS)和嵌入式平台(Google Coral 和树莓派)中作为设备端机器学习推理 (On-device Machine Learning Inference)框架。
一款多媒体机器学习应用的成败除了依赖于模型本身的好坏,还取决于设备资源的有效调配、多个输入流之间的高效同步、跨平台部署上的便捷程度、以及应用搭建的快速与否。
基于这些需求,谷歌开发并开源了 MediaPipe 项目。除了上述的特性,MediaPipe 还支持 TensorFlow 和 TF Lite 的推理引擎(Inference Engine),任何 TensorFlow 和 TF Lite 的模型都可以在 MediaPipe 上使用。同时,在移动端和嵌入式平台,MediaPipe 也支持设备本身的 GPU 加速。
MediaPipe 主要概念
MediaPipe 的核心框架由 C++ 实现,并提供 Java 以及 Objective C 等语言的支持。MediaPipe 的主要概念包括数据包(Packet)、数据流(Stream)、计算单元(Calculator)、图(Graph)以及子图(Subgraph)。数据包是最基础的数据单位,一个数据包代表了在某一特定时间节点的数据,例如一帧图像或一小段音频信号;数据流是由按时间顺序升序排列的多个数据包组成,一个数据流的某一特定时间戳(Timestamp)只允许至多一个数据包的存在;而数据流则是在多个计算单元构成的图中流动。MediaPipe 的图是有向的——数据包从数据源(Source Calculator或者 Graph Input Stream)流入图直至在汇聚结点(Sink Calculator 或者 Graph Output Stream) 离开。
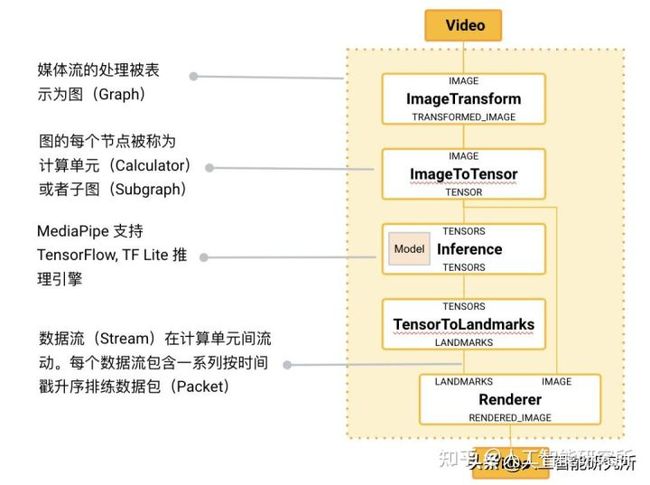
MediaPipe 的核心框架
若我们想使用MediaPipe,
首先,在我们的电脑cmd命令框中输入
python –m pip install MediaPipe安装第三方模型,
然后我们便可以使用代码来进行图片或者视频的检测了,
此模型最主要的优点是不需要我们下载预训练模型,只是安装上其mediapipe包即可
MediaPipe 图片检测
Mediapipe 模型的图片代码检测
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_holistic = mp.solutions.holistic
file = '4.jpg'
holistic = mp_holistic.Holistic(static_image_mode=True)
image = cv2.imread(file)
image_hight, image_width, _ = image.shape
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = holistic.process(image)首先,我们导入需要的第三方库,并配置一下需要画图的点的尺寸,线的尺寸以及颜色等,这些信息都可以自行修改,这里我们直接引用官方的配置进行设计(mp.solutions.drawing_utils函数)
然后定义一个holistic检测模型函数
mp_holistic = mp.solutions.holistic
file = '4.jpg'
holistic = mp_holistic.Holistic(static_image_mode=True)然后使用我们前期介绍的opencv的相关知识从系统中读取我们需要检测的图片,并获取图片的尺寸
image = cv2.imread(file)
image_hight, image_width, _ = image.shape由于OpenCV默认的颜色空间是BGR,但是一般我们说的颜色空间为RGB,这里mediapipe便修改了颜色空间
然后使用我们前面建立的holistic检测模型,对图片进行检测即可
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = holistic.process(image)模型检测完成后的结果保存在results里面,我们需要访问此结果,并把检测到的人脸,人手,以及姿态评估的数据点画在原始检测的图片上,以便查看
if results.pose_landmarks:
print(
f'Nose coordinates: ('
f'{results.pose_landmarks.landmark[mp_holistic.PoseLandmark.NOSE].x * image_width}, '
f'{results.pose_landmarks.landmark[mp_holistic.PoseLandmark.NOSE].y * image_hight})'
)
annotated_image = image.copy()
mp_drawing.draw_landmarks(
annotated_image, results.face_landmarks, mp_holistic.FACE_CONNECTIONS)
mp_drawing.draw_landmarks(
annotated_image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
mp_drawing.draw_landmarks(
annotated_image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
mp_drawing.draw_landmarks(
annotated_image, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS)这里我们打印了图片检测的结果,并分别画出人脸检测模型数据,人左右手的检测数据,以及人体姿态检测数据
#cv2.imshow('annotated_image',annotated_image)
cv2.imwrite('4.png', annotated_image)
cv2.waitKey(0)
holistic.close()画图完成后,我们可以显示图片方便查看,也可以直接使用OpenCV的imwrite 函数进行结果图片的保存,最后只需要close holistic检测模型,这里在检测多人的时候出现了问题,只是检测了单人,我们后期研究

图片检测
Mediapipe 模型的视频代码检测
当然,我们也可以直接在视频里面进行Mediapipe的模型检测

import cv2
import time
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_holistic = mp.solutions.holistic
holistic = mp_holistic.Holistic(
min_detection_confidence=0.5, min_tracking_confidence=0.5)首先跟图片检测一致,我们建立一个holistic检测模型,然后便可以打开摄像头进行模型的检测
cap = cv2.VideoCapture(0)
time.sleep(2)
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
continue
image = cv2.cvtColor(cv2.flip(image, 1), cv2.COLOR_BGR2RGB)
image.flags.writeable = False
results = holistic.process(image)首先我们打开默认摄像头,并从摄像头中获取检测的实时图片
cap = cv2.VideoCapture(0)
while cap.isOpened():
success, image = cap.read()检测到图片后,我们便可以直接使用图片检测的步骤,进行模型的检测
image = cv2.cvtColor(cv2.flip(image, 1), cv2.COLOR_BGR2RGB)
image.flags.writeable = False
results = holistic.process(image)这里我们使用到了cv2.flip(image, 1)图片翻转函数来增强数据图片,由于我们摄像头中的影像跟我们是镜像关系
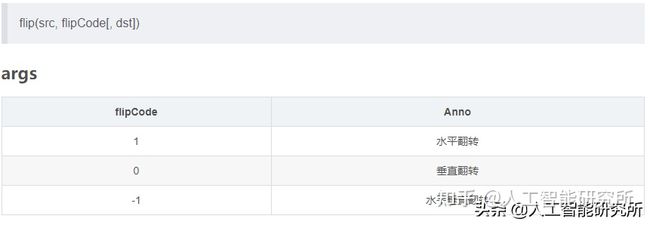
cv2.flip(image, 1)
使用此函数便可以镜像我们的图片影像,最后把图片赋值给holistic模型进行检测
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
mp_drawing.draw_landmarks(
image, results.face_landmarks, mp_holistic.FACE_CONNECTIONS)
mp_drawing.draw_landmarks(
image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
mp_drawing.draw_landmarks(
image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
mp_drawing.draw_landmarks(
image, results.pose_landmarks, mp_holistic.POSE_CONNECTIONS)
cv2.imshow('MediaPipe Holistic', image)
if cv2.waitKey(5) & 0xFF == ord('q'):
break
holistic.close()
cap.release()检测完成后,我们便可以把数据实时进行绘制,以便在视频中实时进行结果的查看

视频检测
这里由于默认设置,线条与点的尺寸不太合适,我们后期慢慢优化
微信搜索小程序:AI人工智能工具,体验不一样的AI工具
