1、爬取网页分析
爬取的目标网址为:https://www.gushiwen.cn/
在登陆界面需要做的工作有,获取验证码图片,并识别该验证码,才能实现登录。
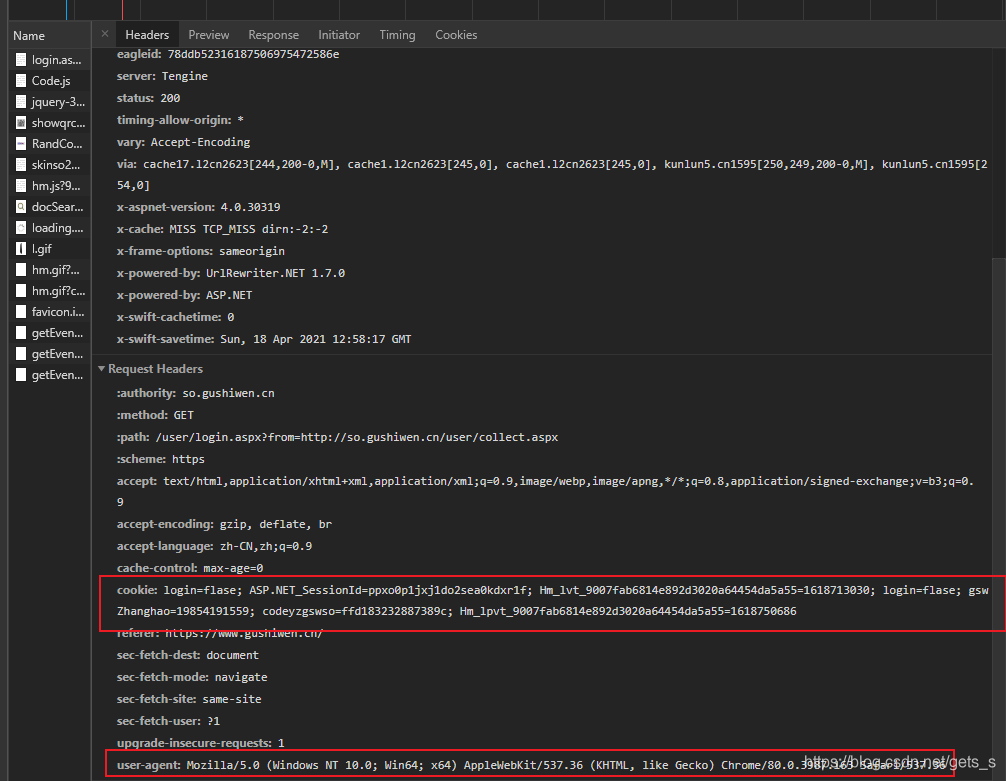
使用浏览器抓包工具可以看到,登陆界面请求头包括cookie和user-agent,故在发送请求时需要这两个数据。其中user-agent可通过手动添加到请求头中,而cookie值需要自动获取。
分析完毕,实践开始!!!
2、验证码识别
(1)基于线上打码平台识别验证码
(2)打码平台:超级鹰、云打码、打码兔
该项目使用超级鹰打码平台完成。网站链接:https://www.chaojiying.com/
将下载好的源码进行封装

3、cookie自动获取
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36",
#手动处理cookie
# "Cookie": "acw_tc=2760820816186635434807019e3f39e1bf4a8a9b9ad20b50586fb6c8184f56; xq_a_token=520e7bca78673752ed71e19b8820b5eb854123af; xqat=520e7bca78673752ed71e19b8820b5eb854123af; xq_r_token=598dda88240ff69f663261a3bf4ca3d9f9700cc0; xq_id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJ1aWQiOi0xLCJpc3MiOiJ1YyIsImV4cCI6MTYyMTIxOTc0OSwiY3RtIjoxNjE4NjYzNTE1MDI1LCJjaWQiOiJkOWQwbjRBWnVwIn0.BGdEgnctB-rv0Xiu8TxrBEshPF4w0StKOE5jKTxy8OFz_pLwNl5VK9v2e8jyU4jaQt9xZTvgsPiYYbiIgmUUpPkamuT0pITHOFoNoKFYFz0syxQMuuAa93pPvSJxeCutqod4cvdWt6f4iRjtHyjAY0zVrv3xLi2ksc9noSf9sH3eLVu9Yjr3PzbF1QDzbXyQsX7oS5Y5Iwt2p-XartCGMlKWzWz9TPiFc3oZ6o7CMWu7Tvfb5D2XGlIU6L8wlPBMwoz2Zdy_zQif9itUqoBvQjNIa3E6UYag-vlY7nNFSDJh0UCobapBjdNITBVVvwFtYn6C-R16y6O8S5iko4E59g; u=461618663543485; Hm_lvt_1db88642e346389874251b5a1eded6e3=1618663545; device_id=24700f9f1986800ab4fcc880530dd0ed; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1618664825"
}
session = requests.Session() # 创建session对象
# 第一次使用session,捕获请求cookie
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
page_text = session.get(url = url,headers = headers).text
# 解析验证码图片地址
tree = etree.HTML(page_text)
img_src = 'https://so.gushiwen.cn/' + tree.xpath('//*[@id="imgCode"]/@src')[0]
# 将验证码图片保存到本地
img_data = session.get(img_src,headers = headers).content
with open('./code.jpg','wb') as fp:
fp.write(img_data)
4、程序源代码
chaojiying.py
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001') #用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 1902)) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
sign in.py
# 模拟登录
# 流程:1 对点击登录按钮对应的请求进行发送(post请求)
# 2 处理请求参数:
# 用户名 密码 验证码 其他防伪参数
import requests
from lxml import etree
from chaojiying_Python.chaojiying import Chaojiying_Client
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36",
}
# 封装好的验证码识别函数
def tranformImgCode(imgPath,imgType):
chaojiying = Chaojiying_Client('用户名', '密码', '软件ID') # 用户中心>>软件ID 生成一个替换 软件ID
im = open(imgPath, 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
return(chaojiying.PostPic(im, imgType))['pic_str']
# 自动获取cookie
session = requests.Session()
# 识别验证码
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
page_text = session.get(url = url,headers = headers).text
# 解析验证码图片地址
tree = etree.HTML(page_text)
img_src = 'https://so.gushiwen.cn/' + tree.xpath('//*[@id="imgCode"]/@src')[0]
# 将验证码图片保存到本地
img_data = session.get(img_src,headers = headers).content
with open('./code.jpg','wb') as fp:
fp.write(img_data)
# 识别验证码
code_text = tranformImgCode('./code.jpg',1902)
print(code_text)
login_url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data = {
'__VIEWSTATE': 'frn5Bnnr5HRYCoJJ9fIlFFjsta310405ClDr+hy0/V9dyMGgBf34A2YjI8iCAaXHZarltdz1LPU8hGWIAUP9y5eLjxKeYaJxouGAa4YcCPC+qLQstMsdpWvKGjg=',
'__VIEWSTATEGENERATOR': 'C93BE1AE',
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '用户名', # 更换自己的用户名
'pwd': '密码', # 更换自己的密码
'code': code_text,
'denglu': '登录'
}
# 对点击登录按钮发起请求,获取登录成功后对应的页面源码数据
page_text_login = session.post(url = login_url,data = data,headers = headers).text
with open('./gushiwen.html','w',encoding = 'utf-8') as fp:
fp.write(page_text_login)
觉得不错的话,就点个赞吧!!
到此这篇关于python网络爬虫之模拟登录 自动获取cookie值 验证码识别的具体实现的文章就介绍到这了,更多相关python 模拟登录 内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!