r语言dmy()函数转化出现na_R语言从入门到精通:Day5

是时候
关注
我们一波了

经过前面几次推文的学习,相信大家对R语言已经有了一个大概的了解,同时也初步感受了R语言在数据处理领域的强大功能,不过实话实说,前面的内容还只是R语言应用的冰山一角而已。从这次推文开始,我们就要正式开始接触R语言对数据处理的强大能力。
在正文内容开始之前,我先给大家推荐一个文档https://google.github.io/styleguide/Rguide.xml
相信很多同学在前几次推文的指导下,练习R代码编写的时候会发现,R语言和其他编程语言不太一样的地方,比如:赋值符,两者我该用哪个?同时,有些操作符前后有空格,有些又没有,到底该怎么写才对?除此之外,R语言的换行和缩进似乎也不像python那么严格。那我们平时自己写代码的时候应该遵循什么样的规则呢?
上面提到的这个文档就可以解答大家的这些疑问。这个文档是Google’s R Style Guide,众所周知,医生在临床上工作有临床指南,那程序员工作也有“指南”,上面的这个文档就是我们写R代码的指南。具体我这里不展开来讲,希望大家好好看看,务必遵守!!!
话不多说,我们进入这次课程的主要内容,上节课中完成了R语言中的数据导入工作,那么这次课程的主要内容就是给大家介绍一些数据管理和操作的基本函数或语句。
温馨提示
1、本节内容重点内容较多,
务必紧跟红色标记。
2、测试数据及代码
见文末客服小姐姐二维码。
一般来说,创建新变量是项目中必不可少的步骤。举个例子,有一个数据框mydata,其中有两列变量x1,x2。现在要求创建两个新的变量x3,x4,其中x3是变量x1,x2的加和,x4是x1,x2的均值。下面有三个实现方式的示例:

图1:创建新变量的三种方式。
第一种方法是通过赋值操作在数据框mydata中生成新的两列;第二种方法是通过attach函数加载mydata,赋值生成新的两列数据,再detach取消加载mydata数据框;第三种方法是通过transform函数把数据列合并在一起。大家可以根据自己的习惯来选择其中一种方法实现(跟大家讲个悄悄话:我喜欢第一种方法,直接明了)。同时我们也跟大家讲一下R里面的常用运算符:加(+)、减(-)、乘(*)、除(/)、求幂(^或者**)、求余(%%)、整数除法(%/%,如5%/%2=2)。
变量的重命名很好理解,变量的重编码的含义是根据一个或者一组变量的现有值创建新值的过程,比如,项目中要求将错误的数据改为准确值、将学生的百分制成绩改为等级制成绩等等。这个过程中逻辑运算发挥了很重要的作用。说到逻辑运算,就是对TRUE和FALSE两个逻辑变量的运算,逻辑运算符包括&(与)、| (或)、!(非)三种。我们以如图2中的一组数据来进行示范。
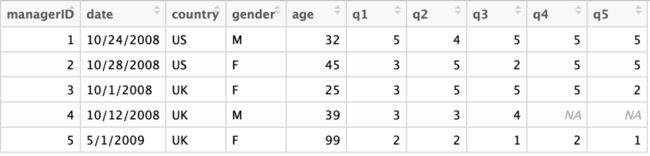
图2:示例数据
首先我们把age=99的数据改为缺失数据,然后将age重编码为等级制变量agecat,代码如图3。

图3:变量的重编码
这样我们发现处理完之后数据有了变化:

图4:注意最后一列agecat。
实际上变量重编码是一个很复杂的问题,绝不仅仅是像上面两步操作那么简单的。其中,car包中的recode()和doBy包中的recodevar()、R语言中自带的cut(),这三个函数都是很受欢迎的变量重编码函数。
相比于重编码,重命名就不那么神秘了,通过names()函数可以更改数据框的行名和列名。下面给大家举几个变量重命名的方法,大家可以自己动手试一下,感受一下这三个语句的效果。
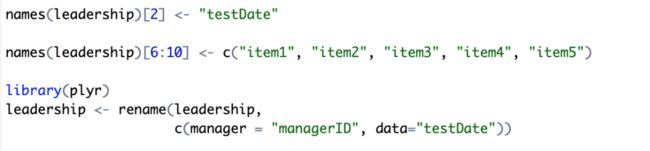
图5:变量重命名的方法。
*plyr包是一个集合了很多数据集操作函数的R包,大家可以查看其帮助文档进一步学习。
几乎所有项目中,都存在缺失值,在R中缺失值用NA代替(前面我们已经见过了)。R语言提供了一个简单而重要的函数is.na()来监测数据集中的缺失值。下面是该函数的一个使用实例。
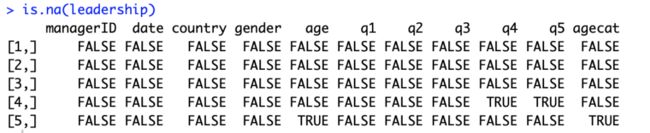
图6:使用is.na()函数
数据集leadership中缺失值NA的位置都被标记上了TRUE。
这个函数简单在于用法简单易记,重要在于R语言中不存在x == NA来判断变量x是否为缺失值的用法!!!值得一提的是,NA只是表示缺失值,和无效运算产生的结果NaN是不一样的。
我们在前面已经实验过了重编码某些值为缺失值的用法,就是将age为99的值标记为缺失值的步骤(如图3)。这一步虽然很简单,但在一些项目中如果遗漏了这个步骤,会对结果产生巨大的影响!
在识别和编码了缺失值之后,我们该怎么处理这些可恶的缺失值呢?缺失值的插补是一个非常复杂的问题,如果你的数据有很大一部分都是缺失值,你或许应该先去问问提供数据的人,为什么会有缺失值。或者,等我们后续课程专门讲解缺失值插补的操作。如果你的数据中只是存在很小一部分缺失值,直接删除这些麻烦的缺失值是一个理想的选择。R语言中提供了函数na.omit()来删除带有缺失值的行(如图7)。

图7:函数na.omit()的使用。
在R语言中的很多数值函数都有一个na.rm=TRUE的可选参数,比如函数sum()。这个参数可以在计算之前就移除缺失值并使用剩余值计算(如图8)。
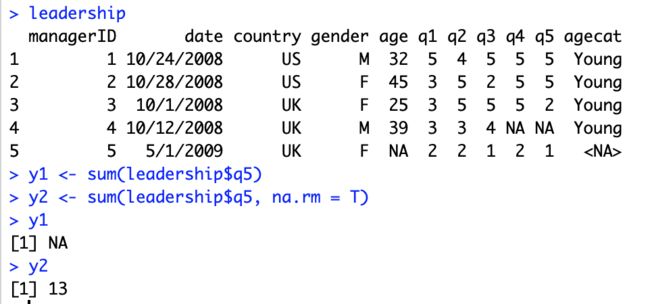
图8:函数sum()中na.rm=TRUE的举例
总之,缺失值的处理是一个很复杂的问题,在删除缺失值对总体影响很小的情况下,这是最理想的选择。
学过任何一门编程语言的同学都不会对数据类型陌生,有些语言中的数据类型转换甚至难倒了很多人。R语言中不会出现这种情况了,它为我们提供了一系列用来判断某个对象的数据类型和将其转换为另一种数据类型的函数,如图9。

图9:类型判断与转换函数。
下面图10是一个简单的示范。

图10:数据类型判断和转换函数的使用
数据中比较特殊的一类就是日期数据,R语言中日期值通常以字符串的形式输入,然后转换为数值形式存储。类似上面用到的as.datatype()函数,函数as.Date()用于执行这个转换过程,具体用法为:as.Date(x, “input_format”)。参数input_format给出读入日期x的适当格式。具体用法见下图11。日期格式的列表如图12,表中详细罗列了不同日期格式的格式符号。

图11:日期的转换

图12:日期格式
数据的排序在R语言中可以说比在Excel中还要简单了,简单给大家展示一下函数order()的用法。如图13,分别按照age和同时按照gender、age对leadership数据集进行了排序。此外,排序的函数还有sort()和rank(),可以自制试试看不同函数的用途哦。
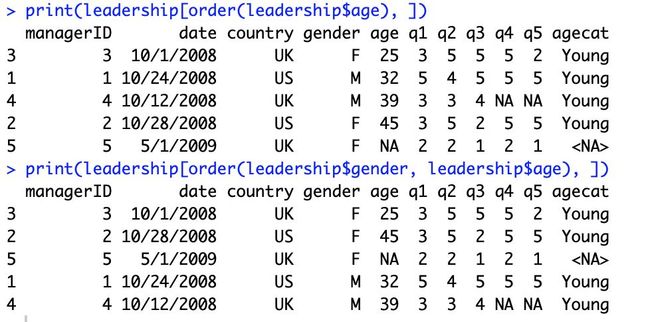
图13:函数order()的用法。
有时候数据并不是一个整体,需要自己整合一下。R语言中常用的合并数据集的函数有merge()、cbind()、rbind()。其中函数cbind()是将两个矩阵或者数据框直接横向合并,要求被合并的两个对象有同样的行数。
如果要在数据框中添加行(或者理解为将两个数据框纵向合并),使用函数rbind(),要求两个数据框有相同的变量,不过顺序不必要相同。一般用于向数据框中添加新的观测。
函数merge()的用法就稍微复杂一点,下面还是用leadership数据集给大家举一个简单的例子,如图14。

图14:函数merge()的使用
简单来说,就是把leadership和leadership.new两个数据集按照变量managerID、date进行了合并,用于给观测添加新的数据。
在前面介绍R语言中数据类型的推文中我们已经展示过选择数据框中某几列数据的方法,下面我们为大家展示选择或者剔除变量(观测)的几种常用方法。如图15.

图15:数据取子集的操作实例。
篇幅有限,就不给大家展示代码的运行结果了。图里面值得注意的是%in%这个运算符,它的主要功能是判断一个向量中的元素是否在另外一个向量中。还有一个重点就是函数subset()。这个函数可以独立解决取一部分观测和一部分变量的工作,是数据集取子集最简单的方法了。
相信大家都有体会,我们的难度在逐渐增大。本次课程的重点是R中的常用数据操作,这个是数据挖掘的基础,其实说难也不难,掌握几个函数,后面的操作就简单多了。希望大家不要气馁,坚持学习,精通R语言指日可待哦。
本期干货
·
!R语言数据操作示例及数据!
关注“科研猫”公众号,联系客服
胖雨小姐姐
or
折耳猫小姐姐
领取
上海交通大学硕士,MIT博士,长期从事医学与生物信息学研究,主要研究方向为高通量测序在肿瘤早期筛查和无创产前诊断中的临床应用,独立开发多个数据分析软件并发表相关文章(影响因子≥5分6篇,≥10分2篇),熟知R、Python、Perl及C语言等多种编程语言及程序设计,曾累计书写R代码超过5万余行。
下期推文预告
描述性统计/循环控制结构
往期热文:
R语言从入门到精通系列
从今天开始,每天学点R语言~ (领取教材)
R语言从入门到精通:Day1 (领取安装包)
R语言从入门到精通:Day2 (领取RStudio操作视频)
R语言从入门到精通:Day3 (领取测试代码)
R语言从入门到精通:Day4 (领取测试代码)
科研作图系列
【科研猫·绘图】今夏最热的“热图”(带R代码分享)
【科研猫·绘图】看·箱线图·如何美丽动人(代码分享)
【科研猫·绘图】优雅版·小提琴图(带R代码分享)
【科研猫·绘图】缤纷版·韦恩图(带R代码分享)
生存分析系列
【科研猫】生存分析的正确姿势(1)视频+R代码分享
【科研猫·出品】TCGA超大批量生存分析教程
GEO数据挖掘系列
GEO数据库挖掘(1)--SCI文章速成
GEO数据库挖掘(2)--快速锁定目标数据
挖掘GEO速成SCI文章系列教程(3)-R语言基础
重磅:GEO数据库挖掘教程(4)一体化分析代码(带视频+R代码分享)
GO/KEGG功能富集系列
3分钟了解GO/KEGG功能富集分析
干货预警:3分钟搞定GO/KEGG功能富集分析(2)
终极篇:3分钟搞定GO/KEGG功能富集分析-柱状图
终极篇:3分钟搞定GO/KEGG功能富集分析-气泡图
TCGA数据挖掘系列
隔壁实验室的“秃鹫”师兄又发SCI啦--TCGA数据挖掘实战
TCGA数据挖掘终结者:cBioPortal
生物信息入门系列
大咖聊“生信”—生物信息系列(1)
生物信息系列课程-R语言入门
更多科研新鲜资讯、文献精读和生物信息技能,请关注科研猫公众号
下方点好看,更多好看。


爱我请给我好看!