【科研数据处理建模】SPSS实战操作生成36类常用论文研究案例,供学习参考
SPSS实战操作
- 0 注意事项
- 1 描述性统计
-
- 1.1 频数分析表
-
- 案例1
- 1.2 交叉分析表
-
- 案例2
- 1.3 分组汇总
-
- 案例3
- 2 假设检验
-
- 2.1 正态性检验
-
- 案例4
- 2.2 单样本比率检验
-
- 案例5
- 2.3 单样本T检验
-
- 案例6
- 2.4 配对样本T检验
-
- 案例7
- 2.5 两独立样本T检验
-
- 案例8
- 2.6 摘要独立样本T检验
-
- 案例9
- 3 方差分析
-
- 3.1 单因素方差分析
-
- 案例10
- 3.2 两因素方差分析(无交互作用)
-
- 案例11
- 3.3 两因素方差分析(有交互作用)
-
- 案例12
- 3.4 多因素方差分析
-
- 案例13
- 3.5 协方差分析
-
- 案例14
- 4 卡方检验与Kappa一致性检验
-
- 4.1 卡方拟合优度(适合性)检验
-
- 案例15
- 4.2 卡方独立性检验
-
- 案例16
- 4.3 分层卡方检验
-
- 案例17
- 4.4 配对卡方检验(麦克尼马尔检验)
-
- 案例18
- 4.5 Kappa一致性分析
-
- 案例19
- 5 非参数检验
-
- 5.1 单样本wilcoxon检验
-
- 案例20
- 5.2 配对样本wilcoxon符号秩检验
-
- 案例21
- 5.3 Kendall协同系数检验
-
- 案例22
- 5.4 两独立样本Mann-Whitney 检验
-
- 案例23
- 5.5 多独立样本Kruskal-Wallis 检验
-
- 案例24
- 5.6 多独立样本非参数检验与多重比较(Kruskal-Wallis 检验)
-
- 案例25
- 6 相关分析与回归模型
-
- 6.1 相关分析
-
- 案例26
- 6.2 偏相关分析
-
- 案例27
- 6.3 一元线性回归
-
- 案例28
- 6.4 多元线性回归
-
- 案例29
- 案例30
- 案例31
- 6.5 曲线回归分析
-
- 案例32
- 6.6 层级回归分析
-
- 案例33
- 6.7 二分类逻辑回归
-
- 案例34
- 6.8 无序多分类逻辑回归
-
- 案例35
- 6.9 有序多分类逻辑回归
-
- 案例36
0 注意事项
有关于SPSS的下载,及软件基本介绍内容可以直接百度或者看B站的讲解视频,这里就是对于科研论文中常见的一些统计学的要点进行梳理,主要参照了网易云课堂的课程的讲解和板书:SPSS论文数据分析实战

梳理这个的初衷也是方便我日后在写论文时候方便回忆,如果有错误也希望看到的人批评指正,文章禁止转载。原博地址 https://blog.csdn.net/lys_828/article/details/117594893
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
SPSS版本为26,注意安装时候勾选添加python扩展选项。整个实战操作共有28项内容,每一项都会按照如下四个方面进行
- (1)是什么
- (2)使用要求
- (3)怎么使用
- (4)结果分析

1 描述性统计
1.1 频数分析表
(1) 是什么
频数分析是针对单个变量(类别变量)的分析,分析得到的结果是不同类别(不同取值区间)的频数,以及频数对应的百分比/或者是累计百分比。
- 频数:变量值落在某一类别(或者某个区间)中的次数
- 百分比:各频数占总样本量的百分比
- 有效百分比:去掉缺失值/空值后的各频数占总样本量的百分比
- 累计百分比:将百分比从上而下的累加,加到最后一项就是100%
(2) 使用要求
spss里面的变量(被称作测量)可以归纳为数值变量(标度)和类别变量(类别变量按照是否有顺序分为名义变量和有序变量),频数分析是针对于类别变量,具体如下。
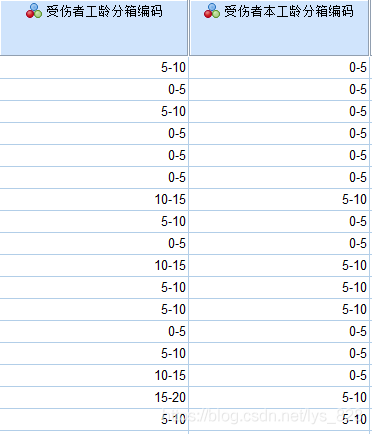
数值变量没有必要进行频数分析,但是可以通过数据分箱转化为分类变量,比如年龄是数值变量,可以手动进行区间划分,比如以十岁为一个区间,自然就把0-100岁人的年龄划分为10类,从而实现由数值变量到类别变量的转变,这也是论文中常见的方法。如下是将工龄和本工龄进行分箱转化为类别变量。
(3) 怎么使用
用SPSS软件进行频率分析:【分析】→ 【描述】→【频率】
案例1
以居民收支调查数据进行分析,为了方便展示,这里仅选择性别和学历两个分类变量进行实战操作

在弹出的窗口中,将性别和最高学历两个字段的名称选到变量框中,然后点击确定按钮即可

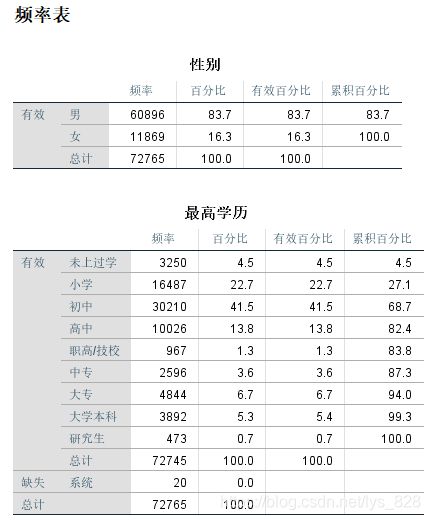
生成的结果如下,系统会默认将两个变量的频数分析表输出出来。
(4) 结果分析
在论文中一般要求三线表的样式,因此需要对最后的结果进行整理,输出如下
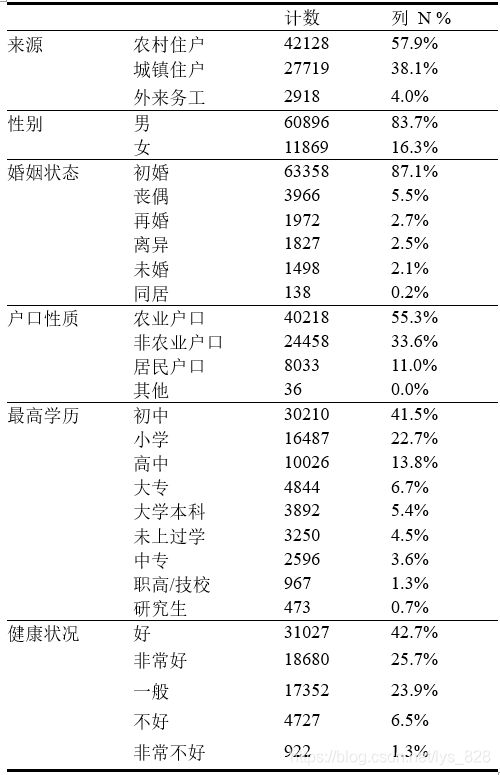
频数分析表的结果可以帮助我们了解类别变量中的相关信息,用在论文中的分析可以讨论占比的多少,还有就是绘制饼图和帕累托图,找到每个类别变量中的主要因素。比如上面的结果中,男性占据主要角色,人员中有50%以上的是来自农村住户等等~~~
1.2 交叉分析表
(1) 是什么
频率分析表是针对一个类别变量进行分析的结果,而交叉分析表是针对两个或者两个以上的类别变量进行分析的结果,通常会根据结果探讨多个变量之间的相关性(卡方独立性检验)
(2) 使用要求
选择两个或者多个类别变量
(3) 怎么使用
用SPSS软件进行交叉分析:【分析】→ 【描述】→【交叉表】
案例2
这里还是以性别和最高学历两个类别变量进行展示,选择“交叉表”选项后,点击鼠标左键确认

在弹出的窗口中选择要分析的两个变量,对于区分因变量和自变量,一般因变量是放在纵向(列),自变量放在横向(行)。选择完毕后直接点击确定按钮即可输出结果。
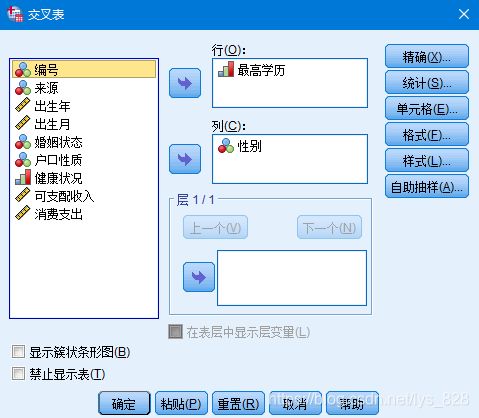
输出结果为:(已经设置好输出的样式即为三线表)

(4) 结果分析
也可以选择“定制表”的选项(下面分组汇总会详细讲解),添加一下列百分数,或者根据自己的需要调整表格
最后点击确认后就形成下面的样式了。基于结果就可以探究两个变量之间的关系,最主要的就是判断两个变量关联性,需要用到后面的卡方独立性检验。

1.3 分组汇总
(1) 是什么
对一个类别变量或者多个类别变量进行分组,按照某一数值变量输出每个分组对应的数值变量的均值、中位数、标准差等统计量
(2) 使用要求
类别变量(横向/行) + 数值变量(纵向/列)
(3) 怎么使用
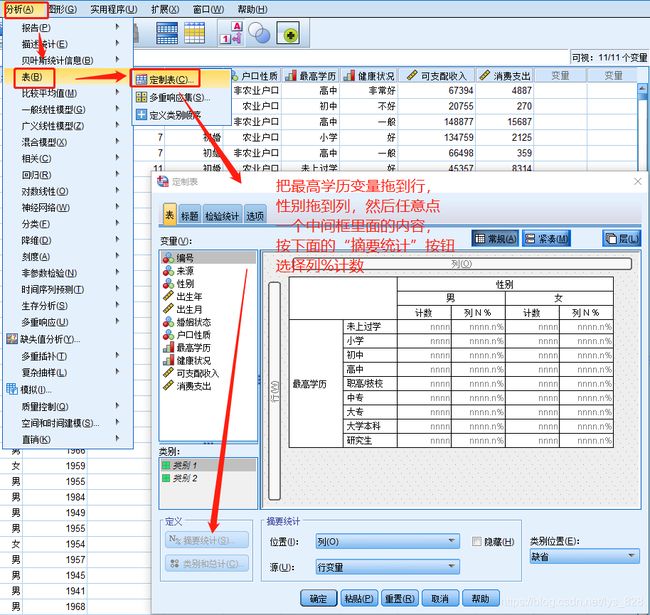
用SPSS软件进行分组汇总:【分析】→ 【表】→【定制表】
案例3
前面提到了定制表的操作,这里就进行详细的展示。首先将要展示的类别变量拖到行,数值变量拖到列,如下

结果如下,默认会对数值变量进行平均值展示,此外还可以显示其它的统计量,这时候鼠标放在列对应的变量上(也就是这里的红色框线),然后左下角的“摘要统计”按钮会亮起,就可以点击选择了
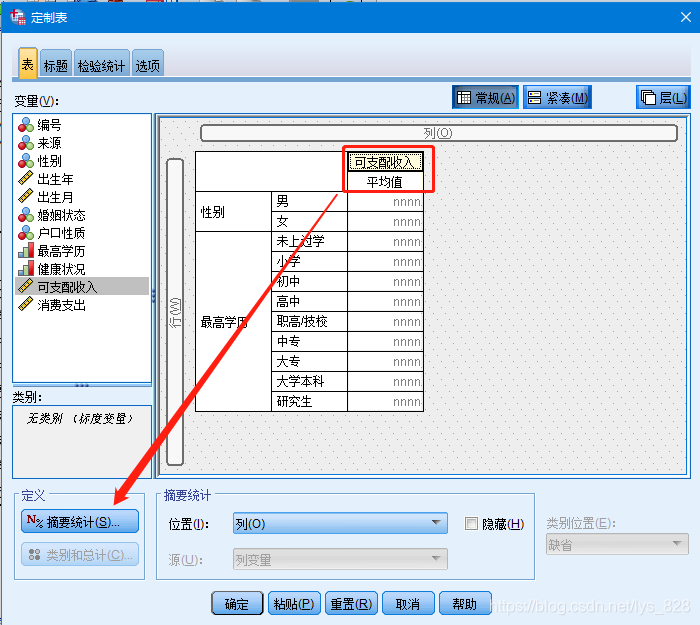
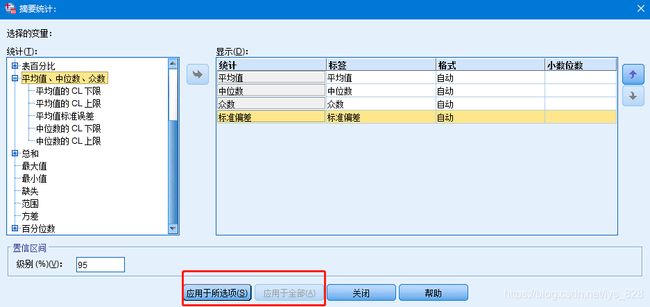
点击按钮后选择要展示中位数和标准差统计量,如下。如果是有多个数值变量就可以选择应用于全部,这里只有一个数值变量,最后选择应用所选项后点击关闭即可
回到定制表的界面,相关的统计量也就加载上来了,最后确认没有问题点击确定就会自动生成分组汇总表了
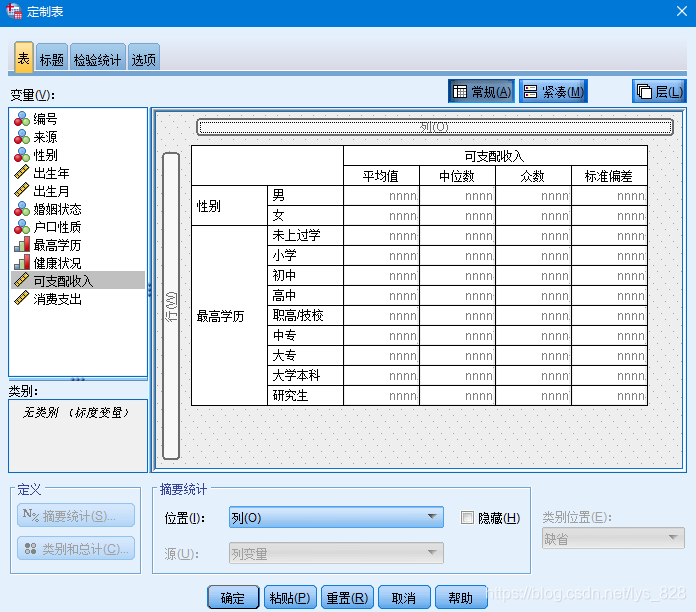
输出结果如下:
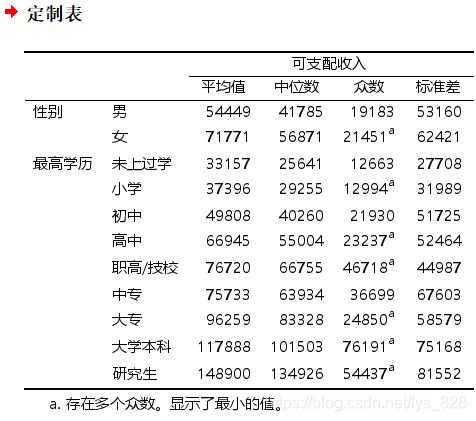
(4) 结果分析
通过分组汇总,可以探讨每个类别变量中的元素随着数值变量的变化,比如这里分析性别对于可支配收入之间的关系,明显女性要比男性可支配收入的均值要大,但是之前的频数分析表中,女性数量是远低于男性,只占了约16%,这就是个很有意思的现象。同样也可以看到学历和可支配收入之间的关系,学历越高,可支配的收入也就越多,证明还是要好好学习,天天想上。
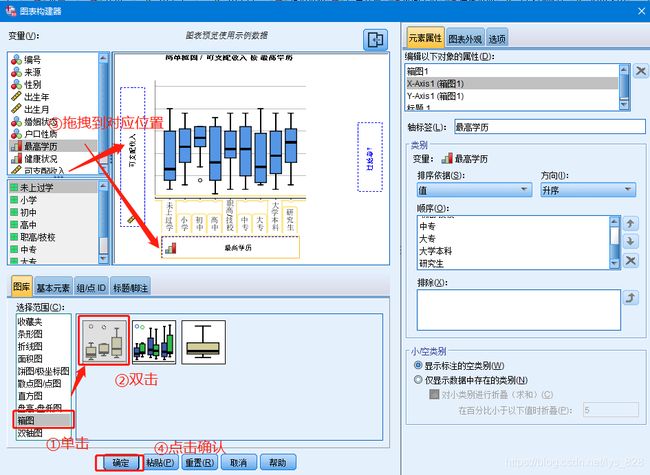
分组汇总一般也可以通过分类箱型图来表示,比如学历和可支配收入之间的关系。SPSS软件进行分类箱型图绘制:【图形】→ 【图表构建器】→【箱型图】
2 假设检验
2.1 正态性检验
(1) 是什么
判断数值变量的数据是否服从正态分布,因为有很多方法使用的前提就是变量服从正态分布,关于正态分布及python的实现检验可以参考之前写的文章,这里进行spss操作
(2) 使用要求
数值变量
(3) 怎么使用
可以使用茎叶图、直方图、箱线图、正态QQ图帮助判断,但是具体判断需要用到假设检验,如果p-value>0.05,则认为数据满足正态分布
用SPSS软件进行分组汇总:【分析】→ 【描述】→【探索】
案例4
数据是使用-10到10之间的20个数值,判断是不是服从正态分布
然后将检查变量添加到因变量列表中,这时候选择“图”按钮,勾选“含检验的正态图”,之后点击“继续”按钮后确认
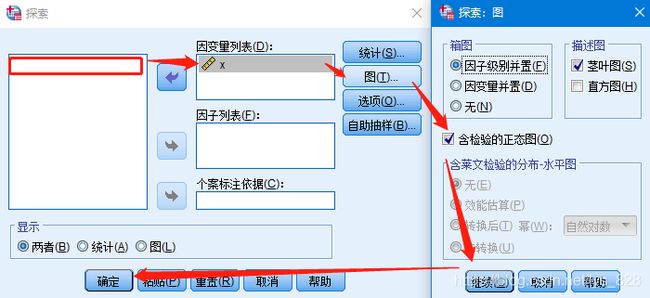
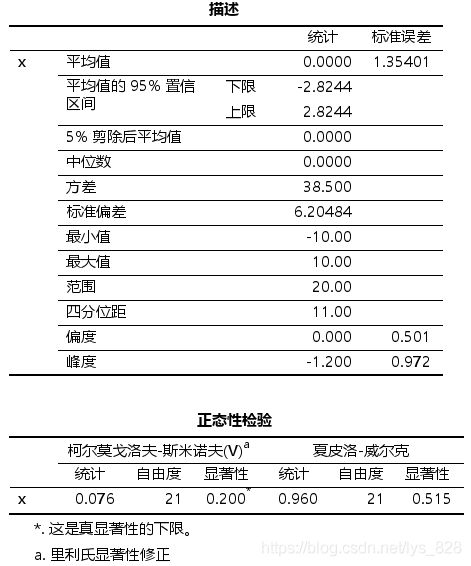
在结果输出栏就可以发现,显著性p-value均是大于0.05的,符合正态分布
同时也会生成辅助判断的QQ图,箱型图等,如下

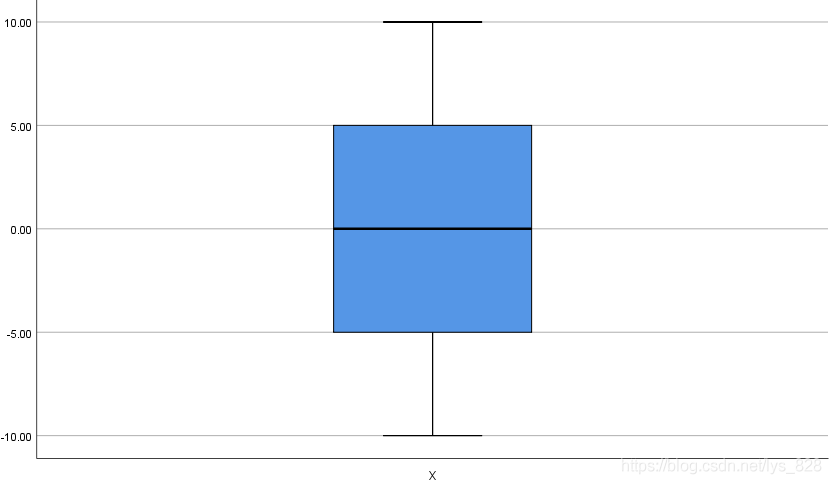
(4) 结果分析
需要注意的是:当样本量较小的时候,结果会输出柯尔莫戈洛夫-斯米诺夫(Kolmogorov-Smirnov)检验结果和夏皮洛-威尔克(Shapiro-Wilk)检验结果,如果数据量较大时,比如超过一万条数据,最后只会输出柯尔莫戈洛夫-斯米诺夫(Kolmogorov-Smirnov)检验结果
比如将上面的结果用在论文中的形式如下(要去掉最后两行的注释)

2.2 单样本比率检验
(1) 是什么
判断类别数据中包含两类元素(比如失业/未失业)时确定总体比率是否不同于指定的假设比率(用人话来说,就是看一下总体数据的比率是不是和指定的比率相同)

(2) 使用要求
分类变量 + 数值
(3) 怎么使用
如果是单个样本数据,SPSS操作单样本比率检验:【分析】→ 【描述统计】→【比率】
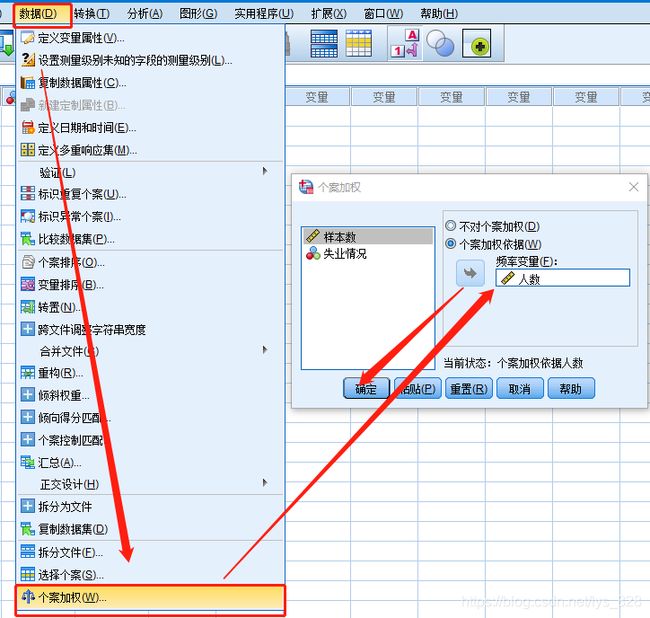
如果是汇总后的数据,操作步骤就是:【数据】→ 【个案加权】→【分析】→ 【描述统计】→【比率】
案例5
数据就使用刚刚的失业与未失业的人数,由于使用的是汇总后的数据,因此要开启权重,进行个案加权
然后再进行比率分析,操作如下,注意要分析的变量作为分子,数据量作为分母,然后统计按钮中只用勾选均值和置信区间,其余的都取消勾选
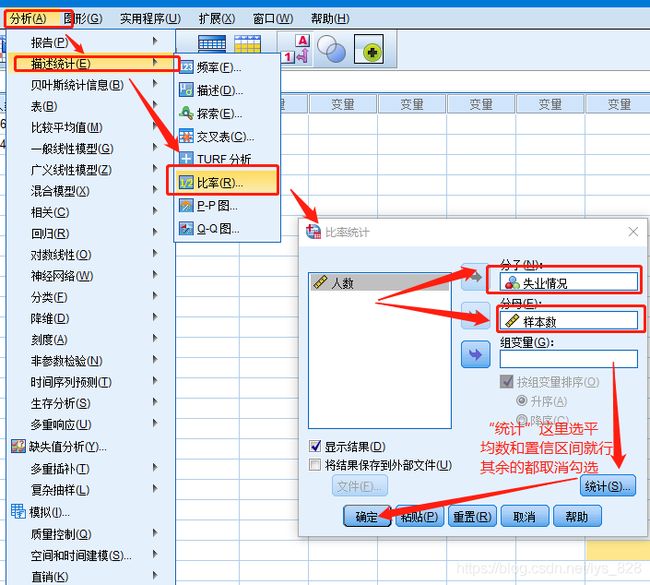
然后在输出一栏就可以看到均值和置信区间,这里就是为了有一个底,知道比率是多少,然后进行检验,比如这里比率是0.086,有一个置信区间为0.084-0.08。

使用卡方检验来验证比率,假定验证的这个比率就是为0.085
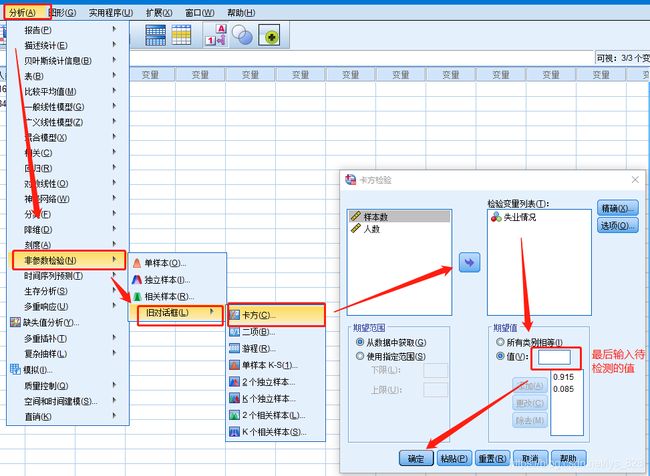
输出结果为:(卡方值用于计算z统计量,显著性用于对比0.05)

(4) 结果分析
最后的p值大于0.05说名不能拒绝原假设,就是认为失业人群占总体样本的0.085。用三线表展示如下(其中z统计量就是前面卡方检验的卡方值进行开平方得到的)

2.3 单样本T检验
(1) 是什么
对于单个总体的均值是否等于某个声称值进行假设检验
(2) 使用要求
数值变量,待检验的样本数据是大样本(n>=30)或者来自于正态总体,如果样本数据为小样本且来自非正态总体,需要使用非参数检验
(3) 怎么使用
先进行正态性检验:【分析】→ 【描述】→【探索】
再进行单样本T检验:【分析】→ 【比较平均值】→【单样本T检验】
案例6
假定有这样一个问题

先进行t检验进行输出的均值和检验的结果,判断是满足正态分布的

然后再进行单样本T检验,操作步骤如下,注意需要指定验证的数据和对应验证指标数值
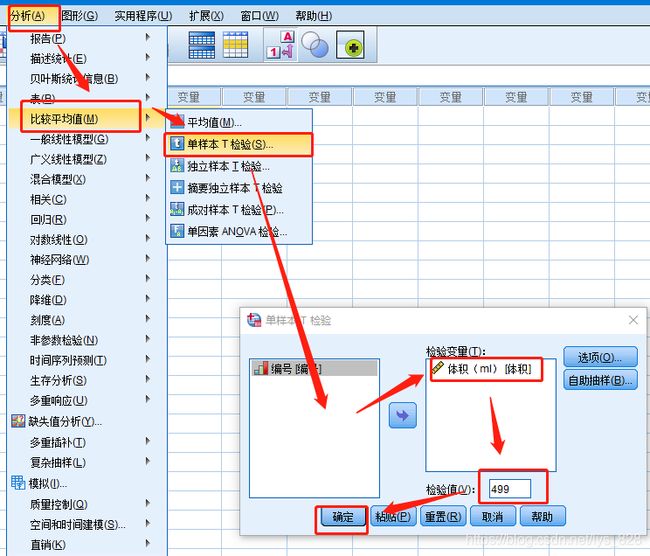
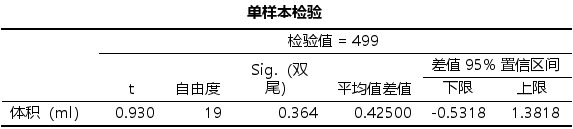
输出结果为:指定检验指标为499时,最后的p值是大于0.05,说明无法拒绝原假设
然后再看一下检验指标为500时(也就是题目中的要求),输出结果为:这时候的p值还是大于0.05,说明还是无法拒绝原假设

最后再看一下检验指标为501时,输出的结果为:说明如果假定每罐饮料的净含量为501ml,那么实际数据检验结果就会拒绝这个假设
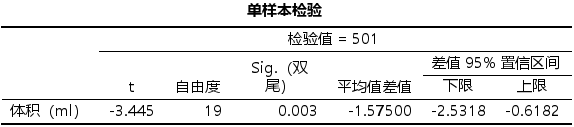
(4) 结果分析
可以发现,测试了499,500,501单个指标,其中前两个都是可以满足,无法拒绝原假设,认为最初的原假设成立,也就是每罐饮料的净含量为499ml或者500ml,但是501ml就会被假设检验结果拒绝。论文最终的表现形式如下(也可以直接把spss的输出原样式结果放在论文中)

2.4 配对样本T检验
(1)是什么
对两个配对样本所来自总体的均值是否相等进行检验
- 配对样本:有对照的两组数据(比如新款/旧款)
(2)使用要求
二分类变量 + 数值
配对数据的对数大于等于30或者配对数据的差值满足正态分布。若样本数据为小样本且配对差值来自非正态总体,应该使用非参数检验
(3)怎么使用
先进行正态性检验:【分析】→ 【描述】→【探索】
在进行配对样本T检验: 【分析】→ 【比较平均值】→【成对样本T检验】
案例7
假定要解决的问题如下:

数据录入spss中,然后由于数据是小样本,所以必须要验证配对差值,故采用计算字段来求解

生成配对差值后,进行正态性检验,检验结果直接给出,如下。两种检验方法的p值均大于0.05,说明配对差值满足正态分布,可以运用配对样本T检验

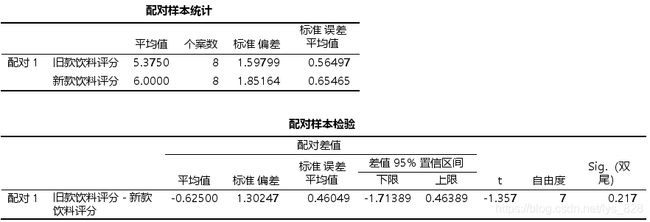
然后进行配对样本T检验操作,操作如下(注意在spss界面中显示的是成对样本T检验)
检验结果为:输出中会先输出基本的统计情况,然后给出配对样本检验的结果
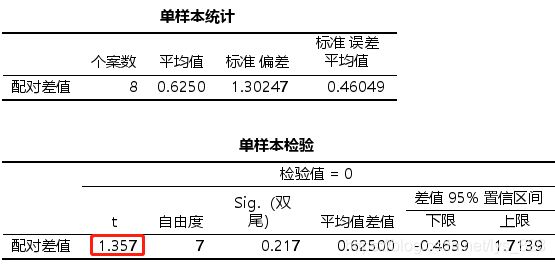
除了直接通过配对样本T检验,也可以直接对产生的配对差值进行单样本T检验,最后的输出结果如下。注意看一下t统计量和最后的p值,p值是一致的,说明配对样本T检验就是通过转化为单样本T检验进行的,然后t统计量这里是负的,因为在选择的时候是用新款-旧款,上面的配对T检验是旧款-新款。
(4)结果分析
最终检验的是两样本的差值,所以最初要求这个差值满足正态分布,然后结果显示p值是大于0.05的,无法拒绝原假设,所以最后得出的结果就为两款饮料之间不存在差异。将结果写在论文中的表现形式参考如下

2.5 两独立样本T检验
(1)是什么
对两个独立样本来自总体的均值是否相等进行检验
(2)使用要求
两分类变量 + 数值
两独立样本所来自的总体都需要满足正态分布,两独立样本T检验对于偏离正态性是相当稳健的。当以图形方式检查分布时,可以检查是否对称且没有离群值
(3)怎么使用
先检验分组数据的总体的正态性:【分析】→ 【描述】→【探索】
在进行独立样本T检验: 【分析】→ 【比较平均值】→【两独立样本T检验】
案例8
某电商公司为评价一种新促销方式的效果,随机选择了500名会员客户,其中一半收到了新促销方式的广告,另一半收到了标准的季节性广告,收集这500个会员客户在促销期间的花费,请根据收集得到的数据判断新的促销方式是否更有效。
先进行分组检验总体的正态性,这里是有一个分组,就是现在二分类中每个类别对应数据的正态性,操作如下(这里要将二分类的变量添加到因子列表)

分组正态性检验的结果如下,两种检验方法最后的p值均大于0.05,说明两样本总体都满足正态分布
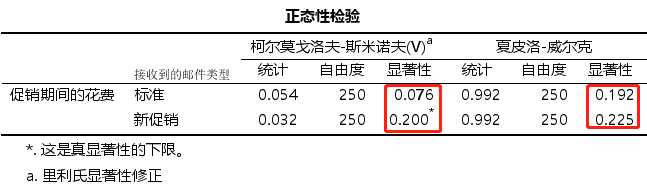
接下来就是进行两独立样本T检验了,操作如下

这时候就要指定一下分组中的标签,要在传入分组变量之前就指好,比如这里就把标准指定为0,不标准指定为1

那么接着上面的操作,点击定义组按钮,将标签填入,然后点击确认按钮即可

最后输出的结果如下:

(4)结果分析
首先会给出方差齐性检验,这里的p值大于0.05,说明方差是相同的,那么后面的内容就需要看第一行,对应“假定等方差”,结果中显示两独立样本T检验的p值小于0.05说明这种新促销的方式对客户之间是有显著差异的,也就说明促销广告是有效的。(如果方差齐性检验p值小于0.05,需要查看第二行的数据)。
论文中示例参考输出,结果解读:从均值上来看新促销的方式高于标准促销的方式,满足方差齐性,且两者之间的差异是统计显著的(即有统计学意义)

2.6 摘要独立样本T检验
(需要安装python扩展)
案例9
上面在进行“独立样本T检验”下面就是“摘要独立样本T检验”,这种方法相当于是对独立样本检验的补充。前面一种方法使用的前提是存在明细的数据,也就是一行行的数据,后者是直接针对分组汇总后的数据进行的。比如下面的汇总数据

使用要求:由于只有最后汇总的数据,所以也就不用进行正态检验了,直接进行摘要独立样本T检验,操作如下,将上面的数据填到对应的框中
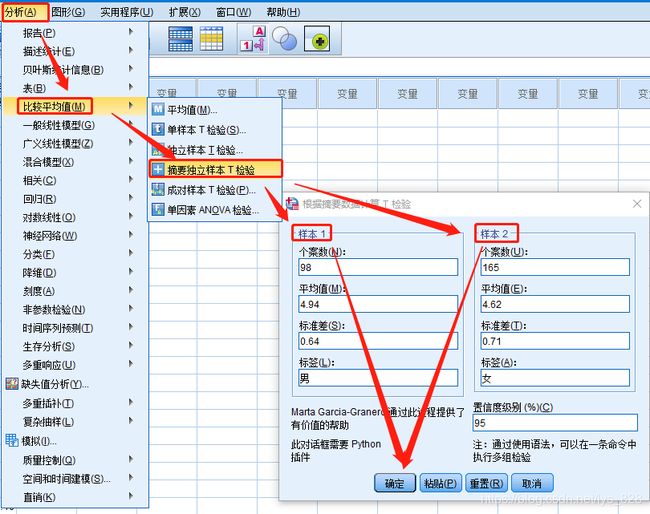
输出结果为:这里使用方差齐性的检验的方式不同了,但是显著性p值大于0.05,所以需要查看第一行的数据,对应着t统计量为3.664,这个上面论文中给出的3.57有所差别,原因就是在于论文中的数据展示的经过四舍五入后保留两位的数据,我们拿的就是经过取舍的数据,所以自然会有所偏差(损失部分信息)

为了说明这个确实是这个问题,直接使用刚刚的两样本独立T检验的数据进行验证。结果界面会输出汇总后的组统计,里面就包含了摘要独立样本T检验中所需的全部信息
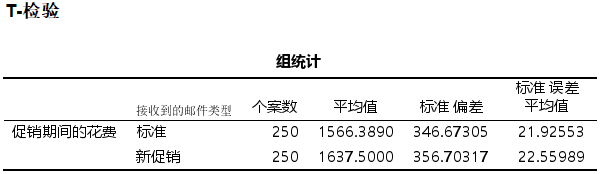
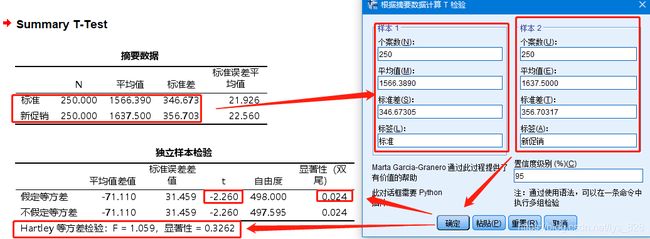
直接进行摘要独立样本T检验,操作如下。可以发现最后的结果和独立样本T检验的输出是一样的,虽然方差齐性的检验方法是不同,但是最后的结果是一致的
3 方差分析
问题: 为什么会有方差分析?
前面介绍了两独立样本T检验,可用于比较两个总体均值是否有显著性差异,注意是两个,那么两个以上的呢?依然可以使用独立样本T检验,但是如果类别变量中的类别过多,也就不是二分类的数据,是k分类的数据,那么在进行检验时候就需要依次进行 c k 2 = k ( k − 1 ) / 2 c_{k}^{2} = k(k-1)/2 ck2=k(k−1)/2次操作,这个在软件操作上可以实现,但是很费时间,更不用说在早期没有计算机软件的时候了。
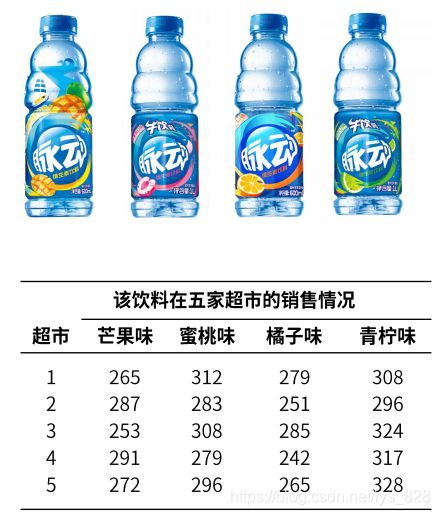
因此就有了方差分析。可以用来比较三个或者三个以上总体均值是否有显著性差异,除此之外还可以分析多个自变量对因变量的影响以及自变量之间的交互效应。比如脉动饮料在不同超市的销售情况
方差分析的基本原理:对不同试验组施加不同的处理,然后观察施加这些处理后各组的试验指标。方差分析将经多种处理后的试验指标作为一个总体,用方差来表示指标的变异情况,把总的变异分解为各可控试验因素引起的变异和随机变异,比较这两者的相对大小,如果可控因素引起的变异明显大于随机因素引起的变异,那么说明可控因素引起了不同组间的差异;相反如果可控因素引起的变异与随机变异大小相当或更小,则无法说明可控因素在起作用了。
如何衡量变异程度:直接引用课程提供的板书
方差分析的前提条件:
- 线性可加。方差分析是建立在一定的线性可加模型之上的,平方和和自由度的分解就是基于线性可加这一前提。所谓线性可加模型是指每个观察值可以被视为若干个线性组成部分之和。也就是因变量的取值是由若干个已知自变量和随机因素影响的。这个条件一般是满足的。
- 误差是随机的、彼此独立的、且都服从均数为0的正态分布。因此方差分析完成后,需要对残差进行分析,观察残差是否满足均值为0的正态分布,如果残差不满足均值为0的正态分布,那么建议选择非参数检验对数据进行分析。
- 满足方差齐性,也即不同亚组的方差相等。这要求在进行方差分析时,检验组间方差是否具有齐性。
3.1 单因素方差分析
(1)是什么
只有一个自变量的方差分析
(2)使用要求
一个多分类的类别变量 + 数值
待分析的数据集中至少应该包含1个作为自变量的分类变量(类别不小于3)和一个作为因变量的连续变量
(3)怎么使用
案例10
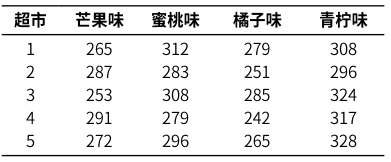
某饮料生产企业研制出一种新型饮料,饮料共有四种口味,分别为芒果味、蜜桃味、青柠味和橘子味,除了口味和包装图案不,同外,饮料的瓶的外形、售价等完全一致。现从地理位置相似、经营规模相仿的五家超市收集了前一相同时期该饮料的销售情况。试分析饮料的口味是否对销售量产生影响。
单因素方差的操作步骤如下:
- ① 录入数据,然后对分类数据进行值标签编码
- ② 方差齐性检验与方差分析。操作步骤:【分析】→ 【比较平均值】→ 【单因素ANOVA 检验】
- ③ 残差分析。先执行【分析】→ 【一般线性模型】→ 【单变量】菜单中得到残差,然后在进行残差正态性检验
- ④ 如果有需要进行组间两两比较
上面给出的案例可能有所疑惑,明明包含了超市和饮料口味两个多分类变量,怎么就满足单因素方差分析条件呢?这里就是对方差分析的原理不是很理解,注意看题目中说到的,五家超市虽然是多分类变量,但是属于地理位置相似、经营规模相仿,说明刻意强调了这个变量是属于组内因素(不可控的因素),而饮料的口味才是属于组件因素(可控因素),所以是可以进行方差分析。
第一步,录入数据,然后对分类数据进行值标签编码,如下
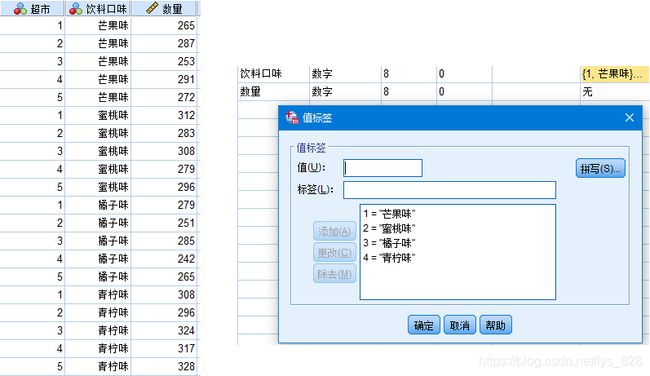
第二步,方差齐性检验与方差分析,操作如下(添加因子的前提就是这个分类变量经过值标签编码了,不然没有办法选入),在选项按钮点中后选择“方差齐性检验”,也可以顺带勾选一下其它的选项,然后继续点击确定即可
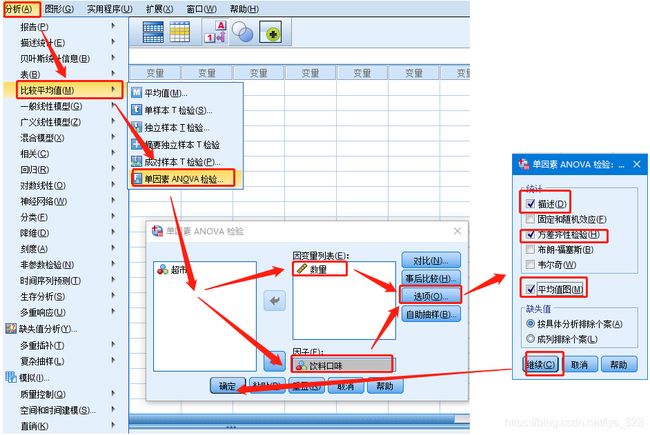
输出结果如下,可以发现方差齐性检验的p值大于0.05,说明各组的方差是相等的,没有拒绝原假设。在论文中的表述中,不需要将这个表格写上去,只需要一句话介绍一下即可:经过方差齐性检验,各组数据满足方差齐性。
第三步,残差分析。操作步骤如下:
输出结果如下,在输出端会有主体间因子和主体间效应检验,然后在数据中会多了一列就是RES_1,也就是系统自动保存的残差
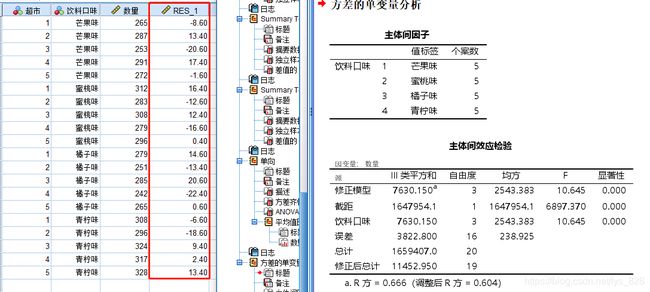
对残差进行正态性检验,输出结果如下。两种检验的方法得到的p值均大于0.05,说明是满足残差正态性

第四步,进行组间两两比较,操作如下。点击“事后比较”按钮,然后点选"S-N-K"和"邓肯法"后点击继续后确定

输出结果如下。使用这两种方法进行比较的结果几乎都是一样的,而且容易进行解读
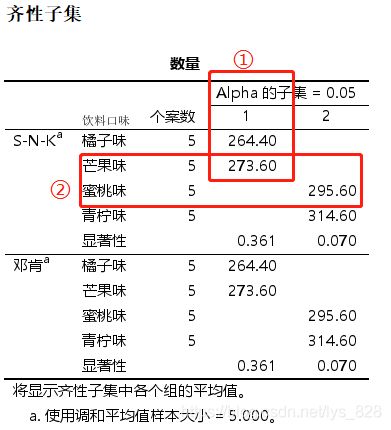
(4)结果分析
由上面的输出结果可知,如果分列了,说明统计显著(上面标记②),如果同一列说明统计不显著(上面标记①)。最后论文中说明如下三点:
- ① 方差齐性检验与残差正态性检验做完后,用文字交代结论即可:方差齐性检验结果显示数据满足方差齐性,且残差分析显示残差满足均值为0的正态分布。
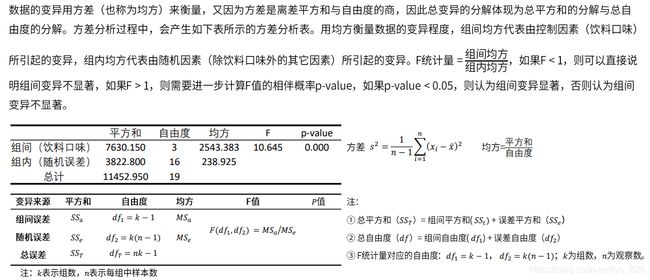
- ② 方差分析的结果一般需要整合成如下的表格,下表中给出了不同组的个案数、均值土标准差,方差分析的F统计量以及相伴概率,两两比较的结果也以标记字母法的形式做了标记。
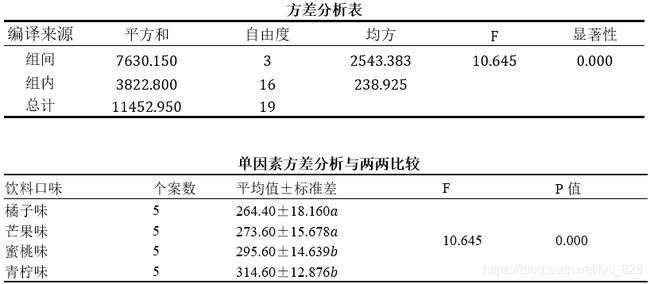
③ 方差分析结果描述: F检验表明,不同的饮料口味对饮料的销量存在显著影响。由进一步的两两比较可知,橘子味饮料销量最低,显著低于蜜桃味和青柠味,但与芒果味饮料销量间不存在显著差异;青柠味饮料销量最高,显著高于橘子味和芒果味,但与蜜桃味饮料销量间不存在显著差异。
3.2 两因素方差分析(无交互作用)
(1)是什么
有两个自变量的方差分析 。
交互作用:多个因素对同一个结果都有影响,那么它们在对结果施加影响时,就可能产生交互作用。在进行方差分析时,如果不确定,是否存在交互作用,可以在分析建模时,纳入交互项,即先认为有交互作用,如果分析结果显示交互项的假设检验不显著,那么再将交互项移除再做无交互项的方差分析。需要注意的是,每一个处理组合下,至少有2个数据,才能够检验交互作用。
(2)使用要求
待分析的数据集至少应该包含2个作为自变量的分类变量和一个作为因变量的连续变量。两因素方差分析可以分析两个自变量之间的交互作用。
(3)怎么使用
案例11
六个水稻品种(A1 ,A2, A3, A4, A5, A6)种在四种不同类型的土壤中(B1,B2, B3, B4) ,产量数据如下表所示,品种和土壤类型都是固定因素,分析品种和土壤类型对产量的影响。(注意这里和前面单因素方差的分析,特意强调四个不同类型的土壤和六个不同水稻品种)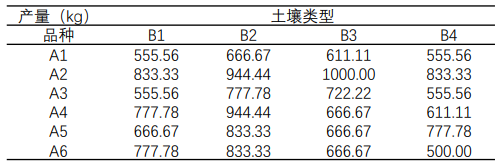
两因素方差的操作步骤如下:
- ① 录入数据,然后对分类数据进行值标签编码
- ② 分别检验两个自变量对应的方差齐性
- ③ 残差分析。检验建立两因素方差分析模型是整体的残差是否满足均值为0 的正态分布。如果满足条件,才执行两因素方差分析。
- ④ 分析时候先纳入交互项,如果交互项显著,则需要进行因素的简单效应分析,不显著或者不显示则直接取出交互项
- ⑤ 如果显著就可以进行结果比较
第一步就直接加载录入好的数据,如下(4x6=24行数据),值标签编码已手动设置好
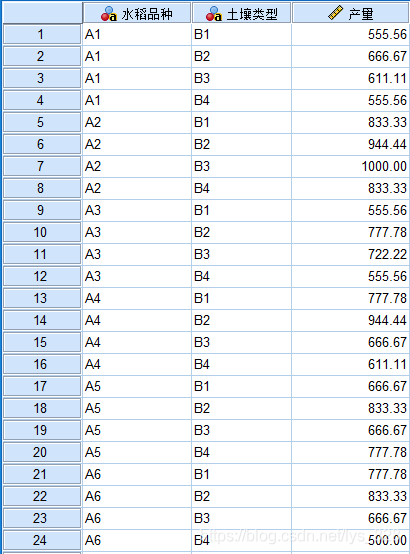
第二步,分别检验两个自变量对应的方差齐性,这里操作步骤和单因素方差分析是一致的,输出结果如下
水稻品种对应的方差齐性检验,p值大于0.05说明满足方差齐性
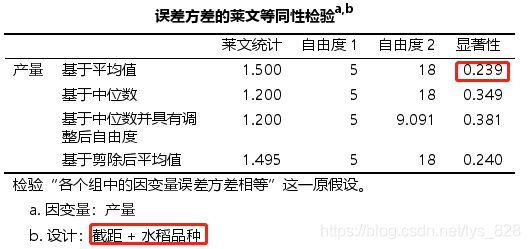
土壤类型对应的方差齐性检验,p值大于0.05说明满足方差齐性

第三步,残差分析。这里的设置就需要注意一下了,由于这里每块地的土壤类型只种植一种水稻,所以说这两个变量之间是没有交互效应的,而spss中是默认将多变量的的交互效应考虑进去。操作过程如下(在点击“保存”按钮勾选未标准化的残差后,要点击这个窗口下面的“继续”按钮,再点击单变量页面最下面的“确定”按钮,下面主要演示时候空间不够,就把这步忽略了)

输出结果如下,系统自动计算一列残差数据,并且会给出组间效应检验
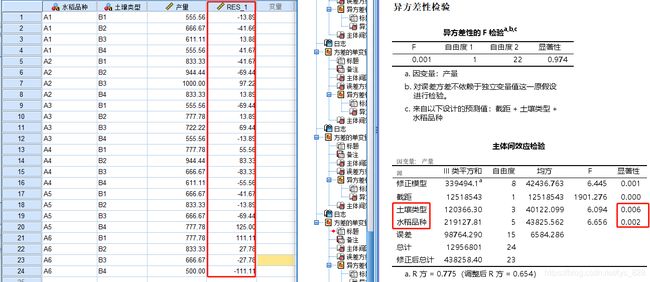
接着就是对残差进行检验,这里就直接给出结果,输出的两种方法中p值均大于0.05,满足正态分布。

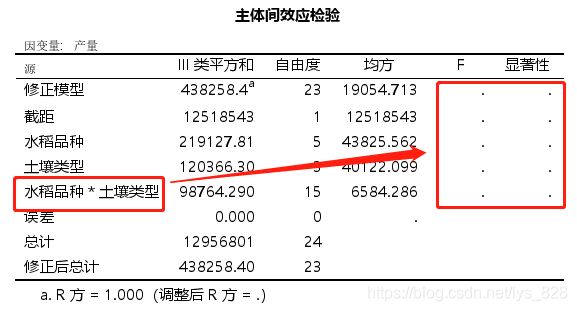
第四步,由于这里是没有交互作用可以忽略这一步。如果没有注意到这一点也没有关系,在“模型”按钮那里的设置,当选择了两组变量时,就是自动交互的(上面是手动选择了主效应,没有交互),默认打开的界面如下

如果这时候直接点击继续后确认,最后的输出结果也会提醒我们的,如下。虽然设置交互项,但是本身数据之间没有交互关系,自然最后的F统计量没有办法计算得到,所以最后两列也就为空了。
第五步,“事后比较”,还是选择“S-N-K”和“邓肯法”进行结果输出(注意前面的 交互性设置要主效应,这里是没有交互项的)
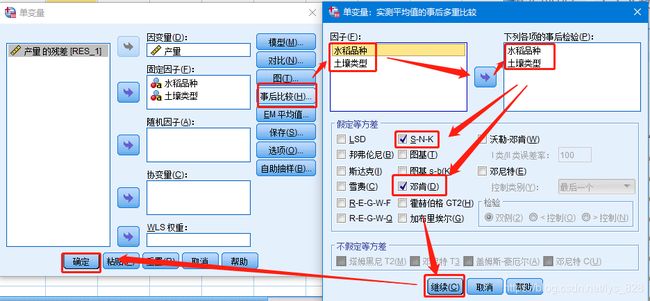
输出结果如下,首先是水稻品种检验结果。可以发现A2和其它的5种品种是有区别的
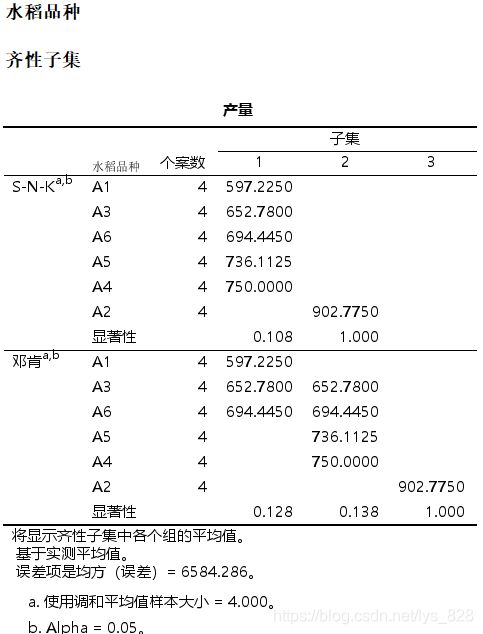
其次是土壤类型检验结果,可以发现B2与其它的3种土壤类型有区别

(4)结果分析
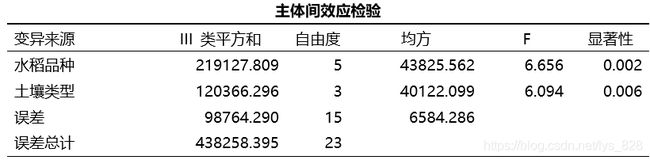
对上面输出的结果进行整理为三线表的形式,先整理主体间效应检验,如下。
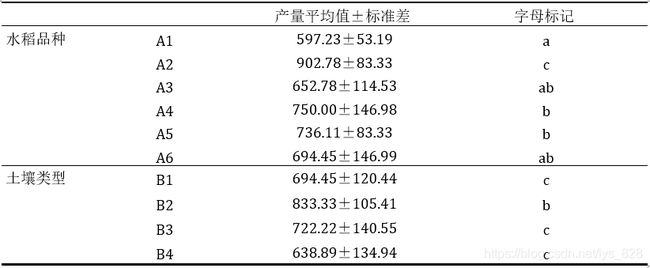
按照邓肯法分析的结果,整理结果如下(在论文中记得写明使用比较的方法,可能不同的方法之间的结果有所不同)
3.3 两因素方差分析(有交互作用)
(1)是什么
两个类别变量之间有交叉的方差分析(比如上面的不同土壤里面种植两种水稻)
(2)使用要求
二个多类别变量(有交叉) + 数值
(3)怎么使用
案例12
某水稻研究所研制出了三个水稻品种(A1、A2、A3) ,现在将这3种水稻种在四种不同的土壤中(B1、B2、B3、B4) ,每·个组合种两块试验田(所有试验田的面积相同) ,最终测得水稻的亩产量如下表所示。请比较品种、土壤类型对产量是否有显著影响,并分析品种与土壤类型间的交互作用。

有交互作用的两因素方差分析步骤和前面无交互作用的一致,主要是在于第四步交互项的处理上面
第一步将上面的示例数据录入spss,然后进行第二步方差齐性检验(是检查自变量的,不是检查交互项)和第三步残差正态性验证,结果如下
注意最后一行的注释,检查的是两个变量,对应的方差齐性满足

残差正态性检验,p值大于0.05,也是满足正态分布的

第四步,就是直接默认就可以了,前面也分析过了,“模型”按钮点击后是自动考虑交互项的,所以最后输出的结果如下。最终两个变量以及交互项都是显著的,说明存在明显的交互作用

这种交互作用也可以通过绘制图形看出,就是在“图”按钮中,选择横轴(比如选择土壤)和纵轴(选择品种)对应的数据,
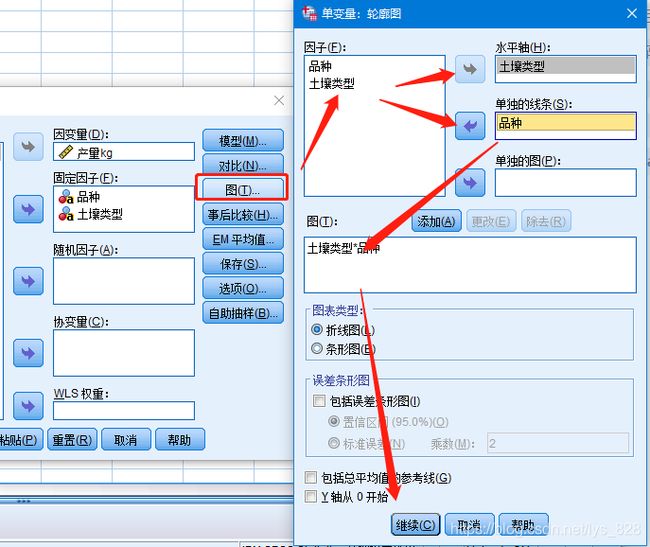
然后再点击确定后输出图形如下,折线之间有交叉就说明存在着明显这交互作用
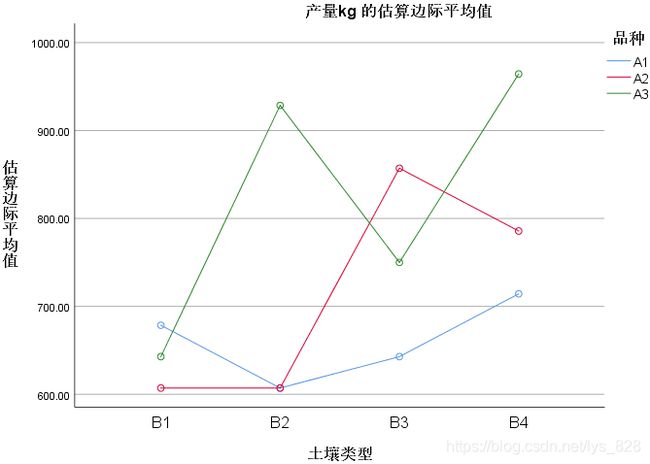
一个问题:交互效应存在时候,意味着什么?
- 如下图所示,用土壤类型和品种分别进行分组。4种土壤类型对应的产量按照B1、 B2、 B3、 B4的顺序依次递增; 3种品种对应的产量按照A1、 A2、 A3的顺序因此递增。如果土壤类型和品种之间不存在交互作用,那么理论上士壤类型和品种的组合A3B4的产量应该最高,A1B1的产量应该最低。
- 最下面的图展示了用土壤类型和品种联合进行分组后的均值图,从图中可以看出, A3B4的组合产量最高,但A1B1的组合产量却不是最低的。这说明土壤类型和品种之间存在交互效应,前面的方差分析也证明了这一点:方差分析表明交互项是显著的。
- 对于存在交互作用的多因素方差分析模型,不能简单的分析和对比各因素的主效应,应该控制其中的部分变量,分析其它变量的简单效应,简单效应的分析需要借助SPSS编程来实现(其实就是添加几个词汇)。
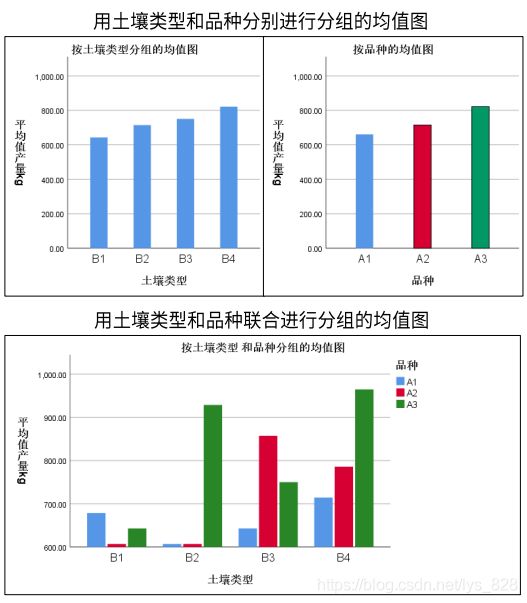
第五步,验证交互效应,进行变量之间的比较。操作如下,在前面各项操作不变的情况下,点击“EM平均值”按钮,然后添加交互项后继续,最后点击粘贴按钮,会自动弹出spss代码编辑的页面(windows会自动弹出,mac需要手动点击)
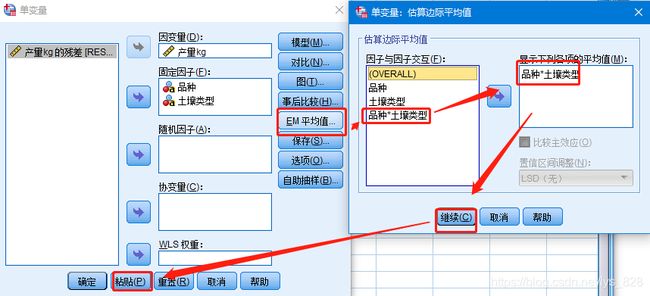
spss编程界面如下,然后添加框中的内容COMPARE(品种) ADJ(BONFERRONI)之后选中全部代码点击上方运行的绿色三角就可以了
UNIANOVA 产量kg BY 品种 土壤类型
/METHOD=SSTYPE(3)
/INTERCEPT=INCLUDE
/EMMEANS=TABLES(品种*土壤类型)
/CRITERIA=ALPHA(0.05)
/DESIGN=品种 土壤类型 品种*土壤类型.

输出结果如下。会先给出估算值,这部分需要根据后面的内容筛选出显著行的类别放在论文中

然后给出的是成对比较结果,这里可以发现带有星号的均是显著性的数据

。注意这里使用检验的方式为:邦弗伦尼法(也就是代码中的BONFERRONI),此外还有其它的一些方法,在代码ADJ()括号中输入一个字母(下面单词的首字母爱)后会自动弹出
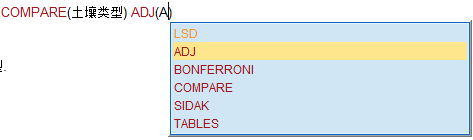
最后给出的是单变量检验的结果,可以发现只要是各类中存在一个显著的数据,然后对应的这个类别就是显著的,如下面的B2(B2土壤中,A1和A3品种,A2和A3品种之间存在显著性差异)和B4(B4土壤中,A1和A3品种之间存在显著性差异)

如果要调整一下研究两因素的位置,比如将品种放在前面,土壤类型让在后面,这时候只需要稍微修改一下代码部分就行了,不需要重新选择对应的按钮操作。如下。把第一个框里把品种放在前面,第二个框中把品种改成土壤类型,最后一个框中可以调换一下检验的方法

最后输出的结果如下,比如估算值结果。

(4)结果分析
首先需要汇报一下主体间效应检验(也就是方差分析的计算结果)
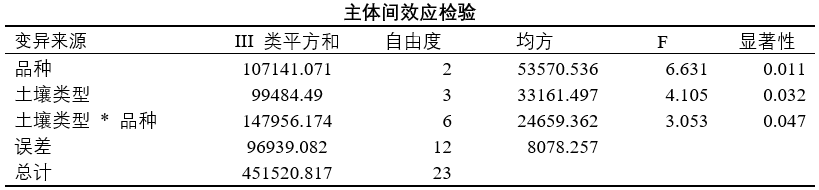
然后在对单变量检验进行输出,注意这里选定的是土壤类型,就是看一下每个土壤地中不同的品种之间的差异
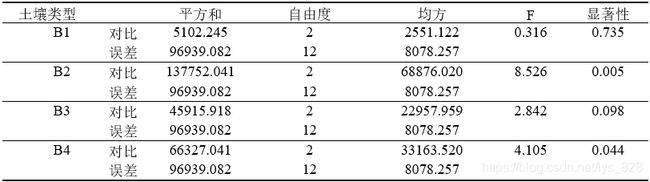
最后就是比较的结果了,注意这里填的是均值和标准差(可以通过前面介绍定制表的方式得到结果),不是生成的成对比较结果里面的平均值差值和标准误差,结果如下。前面几列填写的是基本信息,最后一列就是存在显著性的组合
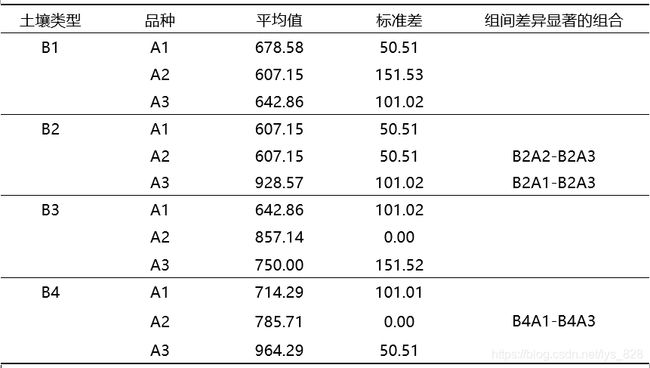
由上结果可以分析出:控制土壤类型取值不变,比较不同品种间的产量差异,发现仅在土壤类型取B2、B4时,不同品种间的产量存在显著差异。控制品种的取值不变,比较不同土壤类型间的产量差异,发现近在品种取A2,A3时,不同土壤类型间的产量差异显著。可结合简单效应分析时输出的两两比较表格,进行进一步的分析和比较。
3.4 多因素方差分析
方法原理: 将总的变异分解成来自各因素主效应引起的变异、各因素间交互作用引起的变异以及随机误差导致的变异。对总平方和、自由度进行拆解,计算各自的均方(方差)。用各自的均方除以随机误差项的均方,得到各自的F值,如果F值对应的p-value < 0.05说明对应因素的各水平,或交互项各组合间差异显著。
交互作用: 多个因素对同一个结果都有影响,那么它们在对结果施加影响时,就可能产生交互作用,两个变量间的交互作用成为一级互作,三个变量间的交互作用称为二级互作。在实际应用中,二级以及二级以上的交互作用很难解释,没有什么实际意义,一级互作便于解释有实际意义。需要注意的是,每一个处理组合下,至少有2个数据,才能够检验交互作用。
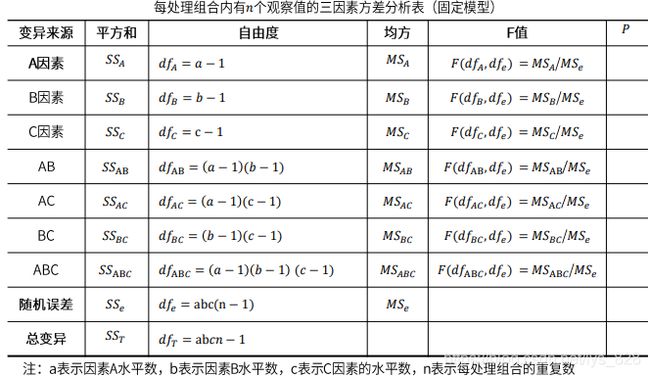
上面展示了三因素方差分析的方差分析表,该表中列出了因素A,B,C的主效应,以及它们之间的一级交互,二级交互。在实际的使用中,一般保留一级交互即可。
(1)是什么
多个类别变量之间的方差分析
(2)使用要求
多个类别变量(可以二分类也可以是多分类) + 数值
(3)怎么使用
案例13
某研究者以大白鼠作试验,观察指标是肝重与体重之比(%),研究正氟醚与观察指标的作用,同时要考察用生理盐水和用戊巴比妥作为·诱导药对正氟醚毒性作用的影响,并且考略不同性别大白鼠对诱导物的作用和正氟醚毒性作用,本研究共有3个因素: 0是否用正氟醚,②诱导物; ③性别,试验所得数据如下表所示。
和之前一样的操作步骤,主要区别还是在第四步中。将上面表中的数据录入spss,然后进行方差齐性检验和残差正态性检验,结果如下
方差齐性满足

残差正态性满足

第四步,先考虑一下全部的交互作用设置如下
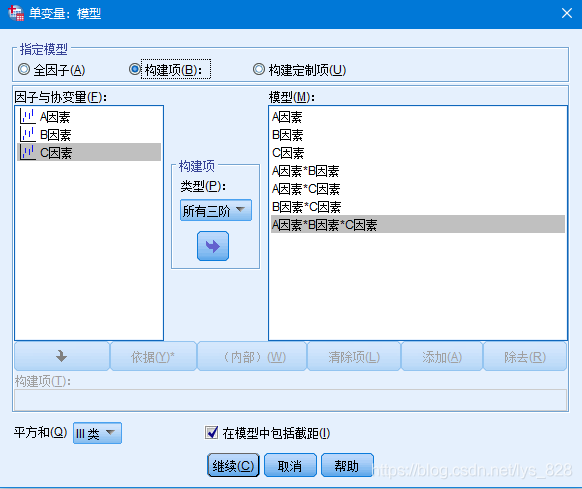
输出结果为,可以发现BC交互和ABC交互的结果不显著,因此就可以剔除这两个交互项以及不显著的A和B因素再进行结果输出
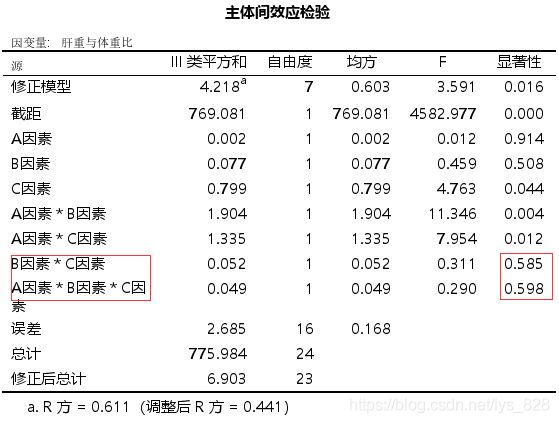
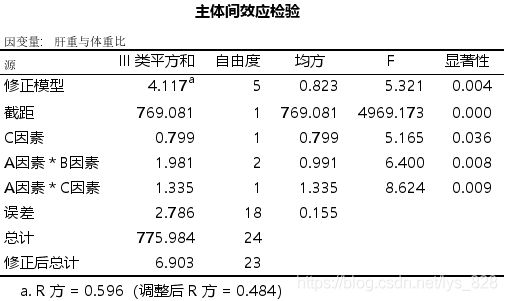
调整后的结果如下
然后就是对显著性的因素两两比较了,和之前的两因素交互项的方差分析一样,这里也是需要使用spss代码编写相应的内容
* Encoding: UTF-8.
UNIANOVA 肝重与体重比 BY A因素 B因素 C因素
/METHOD=SSTYPE(3)
/INTERCEPT=INCLUDE
/PLOT=PROFILE(B因素*A因素 C因素*A因素) TYPE=LINE ERRORBAR=NO MEANREFERENCE=NO YAXIS=AUTO
/EMMEANS=TABLES(A因素*B因素) COMPARE(A因素) ADJ(BONFERRONI)
/EMMEANS=TABLES(A因素*C因素) COMPARE(A因素) ADJ(BONFERRONI)
/CRITERIA=ALPHA(0.05)
/DESIGN=C因素 A因素*B因素 A因素*C因素.
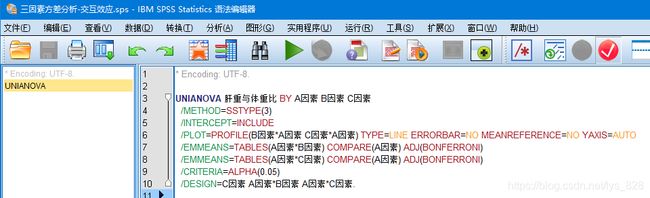
执行结果如下,AB因素交互均为显著
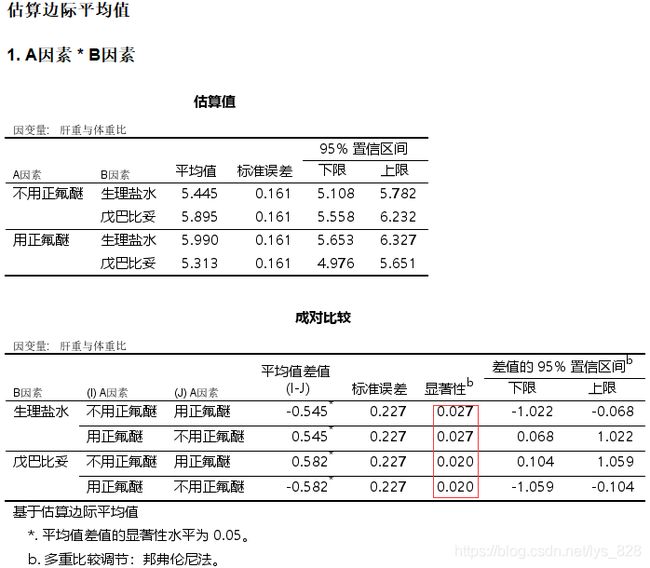
AC因素交互时,发现C因素取雄性时候交互作用不显著
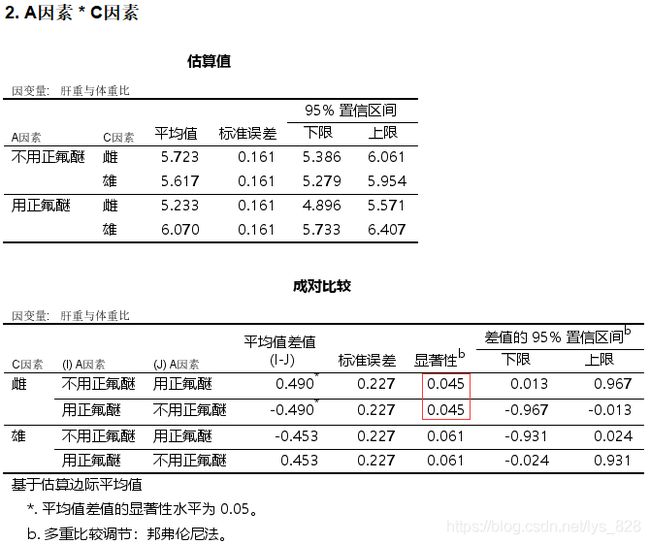
(4)结果分析
整理上述的结果,需要使用到定制表的功能。输出三线表如下,定制表中可以整理出来一部分,还有最后一列是需要手动录入。

3.5 协方差分析
(1)是什么
在许多实际问题中,有些因素很难人为控制,而它们的不同水平确实对观测变量产生了较为显著的影响。在对数据进行方差分析时,如果忽略这些因素的存在而单纯分析其它因素对观测变量的影响,往往会夸大或缩小其它因素的作用使分析结论不准确。协方差分析可将那些人为很难控制的混杂因素作为协变量,并在剔除协变量对观测变量影响的条件下,分析控制变量对观测指标的作用,从而更加准确地对控制变量进行评价。协方差分析是将方差分析和回归分析结合起来的一种统计分析方法。在协方差分析中,认为观测指标总的变异受3个方面的影响,即控制因素、混杂因素和随机因素。
- 方差分析:一个或几个因子(分类变量)对变量Y (连续变量)的影响
- 回归分析:一个或几个变量(连续变量)对变量Y (连续变量)的影响
(2)使用要求
- ①当试验指标(Y)的变异既受一个或几个分类变量(控制因素),也受一个或几个连续变量的影响(混杂因素),可采用协方差分析。
- ②协方差分析的基本前提与方差分析相同,包括试验指标(Y)的正态性、随机性、独立性、以及组间的方差齐性。
- ③因变量与协变量之间呈线性关系,可通过散点图观察。
- ④要满足平行性假定,即各组回归系数间的差别无统计学意义,或各组回归直线平行。可通过散点图观察,也可检验控制变量与协变量间交互项是否显著,交互项不显著才能说明满足平行线假定。
- ⑤协方差分析中,如果有多个协变量,通常要求多个协变量之间无交互作用。
(3)怎么使用
案例14
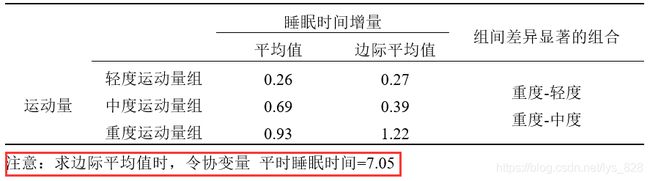
为研究轻度运动量组(A)、中度运动量组(B) 、重度运动量组( C)三种运动量的睡眠效果, 36人被随机分到各组,各测量一段时间,测得每人的初始平时睡眠时间(X)与运动后睡眠时间增量(Y)。试分析3种运动量对人的睡眠增量效果是否相同。
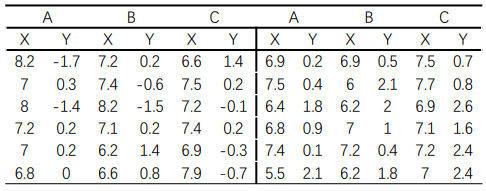
这里面平时睡眠时间也是可以影响运动后的睡眠时间,比如说一天睡10个小时的人和一天睡6小时的人,在运动后睡眠时候可能大有不同,前者只是小憩一下,后者估计就要补补觉了。因此这里应该将平时睡眠时间当做协变量,尝试进行协方差分析。
接着就是逐一进行前提条件的检验了,分析步骤:首先检查数据是否满足协方差分析的条件: ①方差齐性检验; ②残差是否满足均值为0的正态分布; ③协变量与因变量是否符合线性关系; ④满足平行性假定。如果数据满足协方差分析的前提条件,则执行协方差分析。
第一个条件方差齐性满足(这里不需要放入协变量)
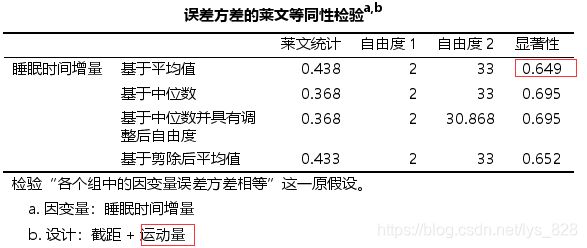
第二个条件中,生成残差时候要把协变量放在对应的位置再进行
第二个条件满足残差的正态性

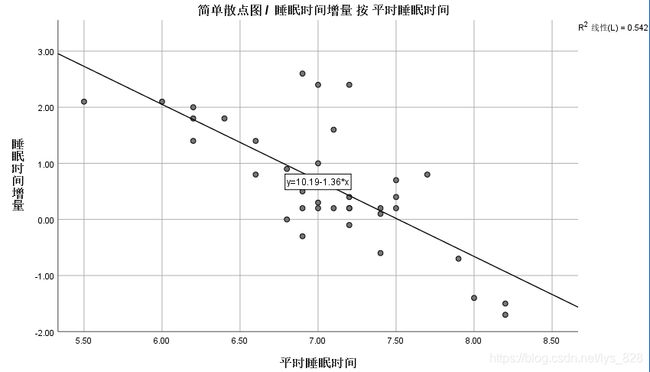
第三个条件通过绘制图形拟合直线即可,都是数值变量也可以使用皮尔逊相关系数检验,通过图像可以发现两个变量满足相关性,第三个条件满足
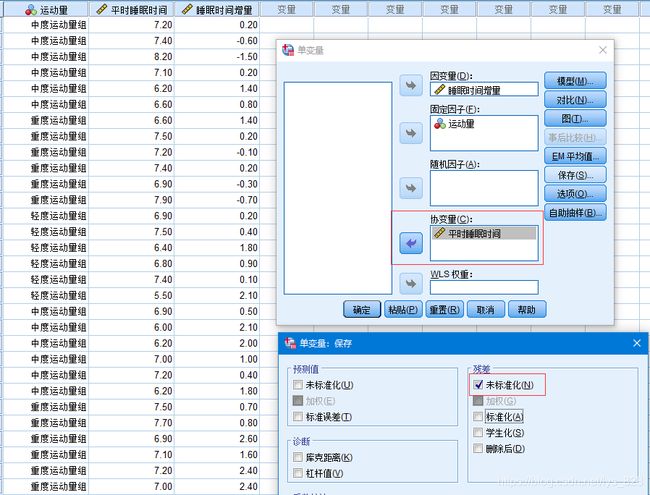
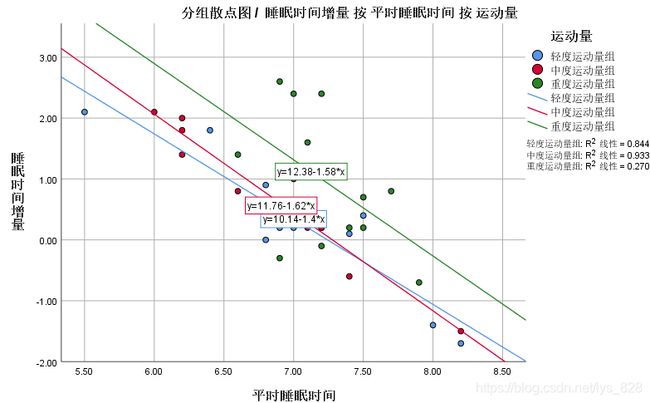
第四个条件,平行性假定,还是通过绘制散点图进行,不过这次绘制的是分组散点图,可以发现分组之间的变量基本上满足平行线假定,虽然有两条直线有相交但是范围很小,加上直线也是拟合的,所以这里初步人为是满足。
最后就是进行比较,操作步骤如下

结果输出如下,先输出的是估计量
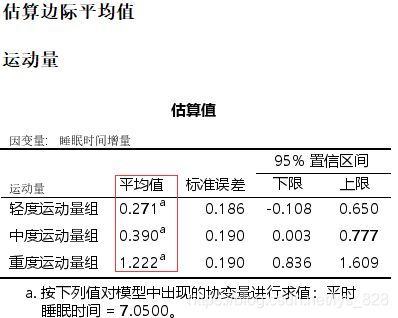
上面表格是考虑了协变量后的均值和标准差,也可以直接使用定制表输出之前没有考虑协变量的均值和标准差,可以发现还是有所差别。
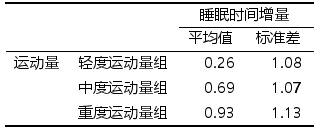
接着就是对结果的两两比较了,输出结果如下
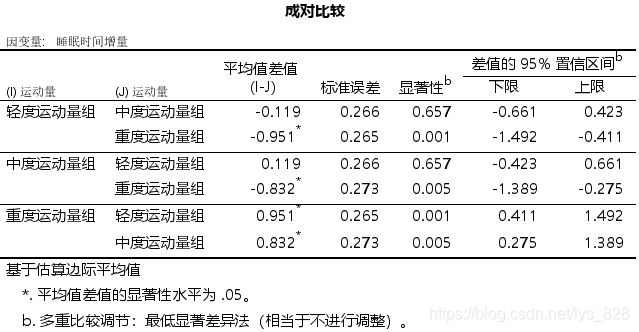
(4)结果分析
整理结果在论文中数据样式,首先就是协方差分析的计算结果,不想整理的话可以直接照搬,也可以和前面的处理方式一样,将红色框中的内容删除
然后就是协变量加入后的分析结果,汇总成三线表样式如下,最后一行的注释一定要添加,因为这个是分析的前提,中间给出了最初的均值和考虑协变量后的均值(边际平均值),最后就是将上面输出结果进行简化,列出有显著意义的组合
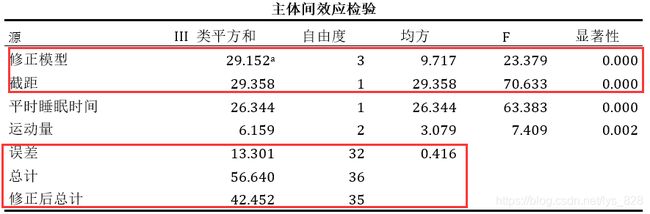
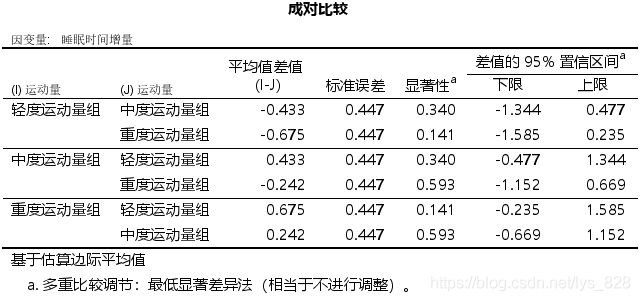
如果不考虑协变量的影响,操作一下,看看结果输出怎么样,可以发现运动量这时候就不显著了
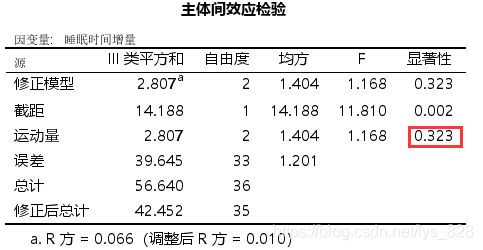
而且最后的两两比较的结果中也全部不显著,说明协变量的影响和协方差的分析也是很重要
4 卡方检验与Kappa一致性检验
关于卡方检验:卡方检验(Chi-square test)是以 χ 2 \chi^{2} χ2 分布为基础的一种常用假设检验方法,它的原假设 H 0 H_{0} H0。是:观察频数与期望频数没有差别。该检验的基本思想是:首先假设 H 0 H_{0} H0成立,基于此前提计算出 χ 2 \chi^{2} χ2 值,它表示观察值与理论值之间的偏离程度。根据 χ 2 \chi^{2} χ2 分布及自由度可以确定在 H 0 H_{0} H0成立的情况下获得当前 χ 2 \chi^{2} χ2 统计量以及更极端的 χ 2 \chi^{2} χ2 值所对应的概率P,如果P值很小,说明观察值与理论值偏离程度太大,应当拒绝无效假设,表示比较资料之间有显著差异;否则就不能拒绝无效假设,尚不能认为样本所代表的实际情况和理论假设有差别。
4.1 卡方拟合优度(适合性)检验
(1)是什么
检验某个分类变量各类别出现概率是否等于指定概率。当只研究一个类别变量时,可利用 χ 2 \chi^{2} χ2检验来判断各类别的观察频数与某一期望频数或理论频数是否一致。比如,各月份的产品销售额是否符合均匀分布、不同地区的离婚率是否有显著差异等。该检验是利用 χ 2 \chi^{2} χ2 统计量来判断某个类别变量各类别的观察频数分布与某一期望频数或理论频数是否一致,它也可用于判断各类别的观察频数分布是否符合某一理论分布,如泊松分布或正态分布等。
(2)使用要求
一个类别变量 + 数值
(3)怎么使用
案例15
一项社会学研究认为,离婚率的高低与受教育程度有关,而且由于社会经济发展程度及生活方式等因素的影响,不同地区也有定差异。在对全国离婚家庭的样本研究中发现,在离婚家庭中,受教育程度为小学及以下的家庭所占的比例为20%,初中家庭为35%,高中家庭为25%,大学家庭为12%,研究生家庭占8%。现对东部地区260个离婚家庭的调查中,不同受教育程度的离婚家庭分布如下表所示。检验东部地区不同受教育程度的离婚家庭数量占比与全国是否一致( α \alpha α =0.05)。

卡方拟合优度检验的步骤:
第一步:提出假设
- H 0 H_{0} H0:东部地区不同受教育程度的离婚家庭数与期望频数一致
- H 1 H_{1} H1:调查频数和期望频数不一致
第二步:计算 χ 2 \chi^{2} χ2 统计量: χ 2 = ∑ ( O − E ) 2 E \chi^{2} = \sum\frac{(O-E)^{2}}{E} χ2=∑E(O−E)2,下面的表格展示了 χ 2 \chi^{2} χ2统计量计算的详细过程。
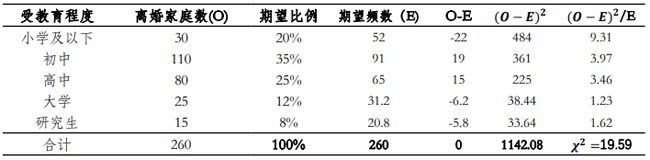
如果直接使用O-E最后得到的结果合计为0,没有办法看出差别,若是使用平方是可以方法差别,能够得到想要的结果,但是也有问题,当数据本身很大或者很小的时候,平方之后的结果也就会变得很大或者很小,故最终为了消除自身的影响,最后再除以E,这样就消除了量纲的影响,得到的结果就能直接反映出差别,这个结果就是 χ 2 \chi^{2} χ2统计量
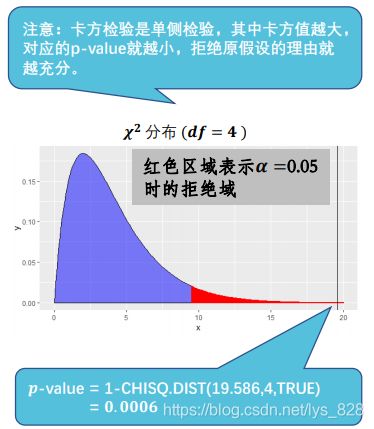
第三步:根据小概率原理决定是否拒绝原假设 H 0 H_{0} H0,第二步中得到 χ 2 \chi^{2} χ2=19.59,其落在右·上图所示的拒绝域当中,说明要拒绝原假设。也可以计算 χ 2 \chi^{2} χ2值对应的概率值,此处计算得到p-value =0.0006,远远小于0.05,可以拒绝原假设且具有很强的统计显著性。
在SPSS中执行卡方拟合优度检验:
- 方式一: 【分析】 →【非参数检验】 →【旧对话框】→【卡方】
- 方式二: 【分析】 →【非参数检验】→ 【单样本】
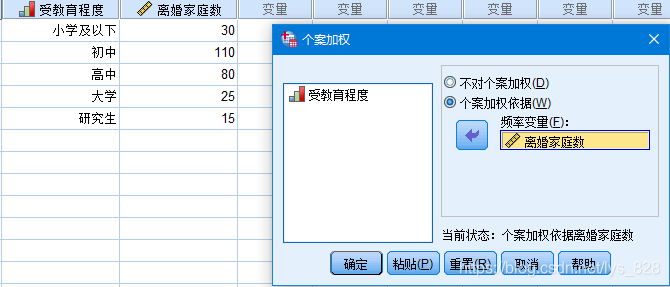
第一步,录入数据并进行标签值编码,由于上述给出的数据是汇总数据,所以需要进行加权操作
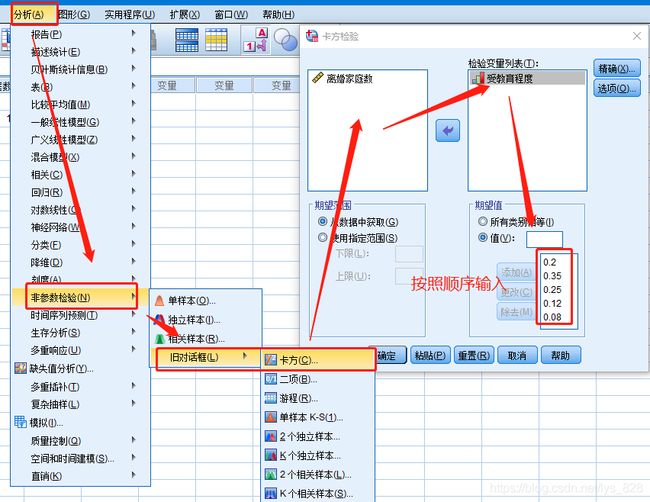
第二步进行卡方拟合优度检验,操作结果如下:
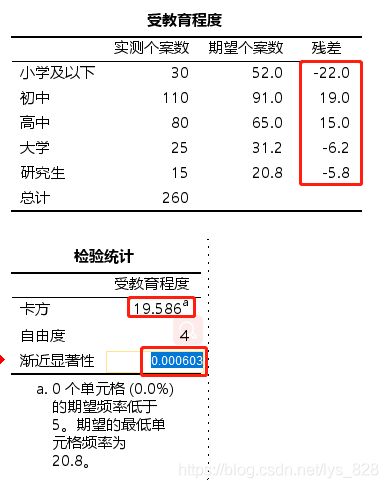
输出结果如下。可以发现最后的结果和上面表中的结果一致,最后的p-value也是0.0006
第二种方式进行卡方拟合优度检验,【分析】 →【非参数检验】→ 【单样本】,然后操作如下,注意指定期望概率时候前面的数值就对应着最初指定的值标签,然后后面的频率就是对应的期望

输出结果也是一致的。但是这种直接给原假设给列出来了,而且最后的决策也明确会给出了,就很直观

(4)结果分析
整合以上的结果,进行论文三线表的输出。整理后的表格结果就一目了然的知道原始数据以及期望,还有最后检验的卡方值及对应的p值。很明显最后的p值小于0.05是拒绝原假设的,所以认为受教育程度并不是以一定比例出现的,也就是说东部地区不同受教育程度的离婚家庭数量占比与全国不一致

4.2 卡方独立性检验
如果研究的是两个类别变量,每个变量有多个类别,通常将两个变量多个类别的频数用交叉表的形式表示出来。其中一个变量放在行( r o w row row)的位置,称为行变量,其类别数(行数)用 r r r表示;另一个变量放在列 ( c o l u m n ) (column) (column)的位置,称为列变量,其类别数(列数)用 c c c表示。(一般因变量放在列,自变量放在行)
这种由两个或两个以上类别变量交叉分类的频数分布表就是列联表。一个由 r 行 r行 r行和 c c c列组成的列联表也称为 r ∗ c r*c r∗c列联表。对于两个类别变量的推断分析,主要是检验两个变量是否独立,这就是 χ 2 \chi^{2} χ2独立性检验。
(1)是什么
检验两个分类变量是否相互独立。如:检验吸烟是否与呼吸道疾病有关
(2)使用要求
两个类别变量 + 数值
(3)怎么使用
卡方独立性检验的步骤和前面卡方拟合优度检验很相似。
案例16
表1显示的是美国旧金山地区随机选择的1028个盗窃案件中,有罪辩护和无罪辩护以及对应的判决结果。检验假设:判决结果和辩护相互独立。
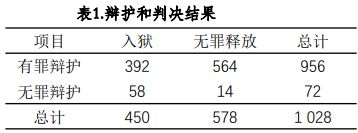
第一步:提出假设,
- H 0 H_{0} H0::判决和辩护相互独立
- H 1 H_{1} H1::判决和辩护不相互独立
第二步:计算 χ 2 \chi^{2} χ2 统计量: χ 2 = ∑ ( O − E ) 2 E \chi^{2} = \sum\frac{(O-E)^{2}}{E} χ2=∑E(O−E)2, χ 2 \chi^{2} χ2 独立性检验卡方值的计算过程与x2适合性检验相似。
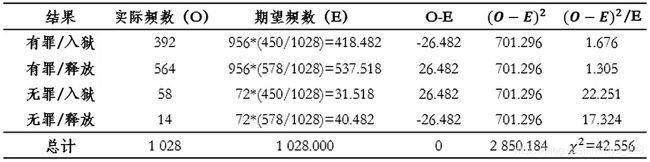
和之前的唯一区别就是在于期望频数E,之前直接给出,有指定的参考值,这里需要自己手动进行计算。最后的p值计算如下图

第三步,计算得到的 χ 2 \chi^{2} χ2值落在了拒绝域当中,应该拒绝原假设。
在SPSS中执行卡方独立性检验:
分析菜单: 【分析】 → 【描述】→ 【交叉表】
分析步骤: 数据录入 → 频数加权 → 交叉分析与卡方检验
第一步还是将数据录入spss,进行值标签编码和个案加权,然后再进行卡方独立性检验
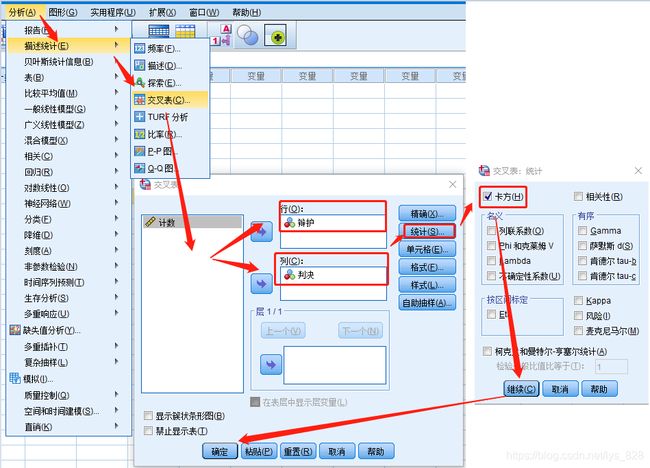
输出结果如下,可以看出最后的结果中有很多结果,到底看哪一个是要依据数据来决定的

四格表(2×2)卡方检验结果中检验方法的选择(以上述为例):
- 总例数>=40,所有理论频数>=5,看皮尔逊卡方(Pearson Chi-Square)结果;
- 总例数>=40,出现1个理论频数>=1且<5, χ 2 \chi^{2} χ2检验需进行连续性校正,这时以连续性修正(Continuity Correction)结果为准;
- 总例数>=40,至少2个理论频数>=1且<5,看费希尔精确检验(Fisher’s Exact Test)结果;
- 总例数<40或者出现理论频数<1,看费希尔精确检验(Fisher’s Exact Test)结果。
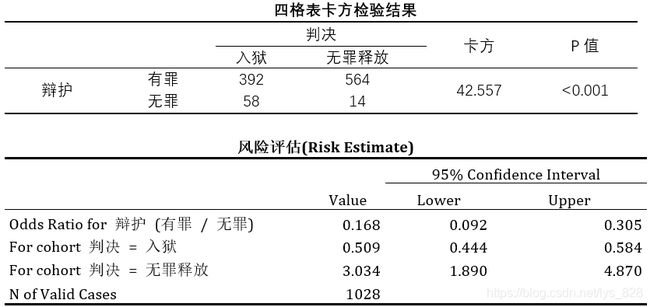
- SPSS也会友好地在表格下方的注释部分提示是否有理论频数小于5,以及最小的理论频数是多少,方便选择恰当的检验方法。本案例中总例数=1028>40,且所有理论频数>5,所以直接看皮尔逊卡方(Pearson Chi-Square)结果: χ 2 \chi^{2} χ2=42.557, p<0.001
关于理论频数除了上表的最下面a的注释会给出,也可以通过“单元格”按钮进行指定,如下

输出结果如下。如果期望计数小于1,就需要查看的是费希尔精确检验(Fisher’s Exact Test)结果
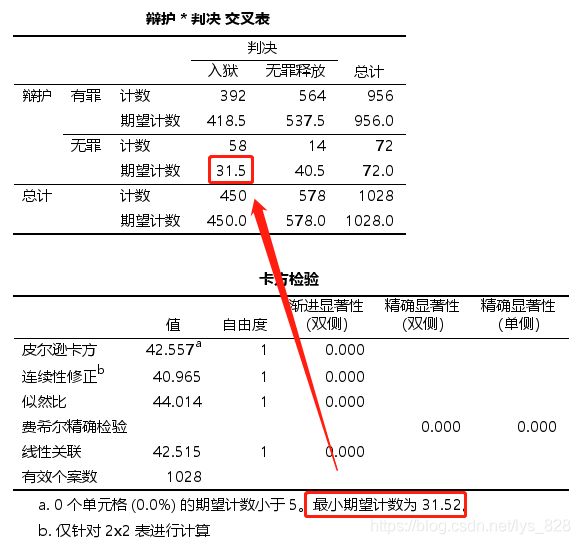
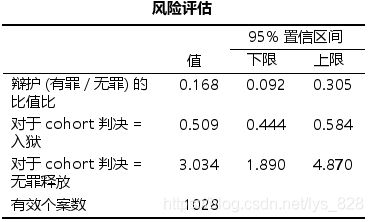
超级重要的论文中分析的内容:比值比和相对危险度
对于四格表数据(2 x2交叉表),执行卡方独立性检验时,可勾选【交叉表】的【统计】设置中的【风险】选项,输出比值比和相对危险度。

比值比(odds ratio) :根据交叉表可知956个有罪辩护中, 392个入狱, 546个未入狱,有罪辩护的比值为有罪辩护入狱和有罪辩护未入狱的人数比为: 392/564=0.695;同理可得无罪辨护的比值为: 58/14=4.143,从比值可知有罪辩护入狱的可能性更低。有罪辩护和无罪辩护的比值比为: 0.695/4.143=0.168,此处比值比小于1目95%置信区间不包括1,则代表有罪辩护入狱的可能性显著小于无罪辩护;如果比值比大于1且95%置信区间不包括1,代表有罪辩护入狱可能性显著大于无罪辩护;若比值比的95%置信区间包括1,则说明有罪辩护和无罪辩护入狱的可能性无统计学差异。
相对危险度(relative risk) :根据交叉表可知有罪辨护入狱的比例为: 392/956=0.410,无罪辨护中入狱的比例为: 58/72=0.806。可以得到初步结论:与无罪辩护相比,有罪辩护入狱的风险更低。对于入狱这一结局,有罪辩护相对于无罪辩护的相对危!险度为: 0.410/0.806 = 0.509,查看【风险评估】表中判决二入狱的行,这里输出了相·对危险度,其值小于1且95%C不包括1,则意味着有罪辩护组入狱风险降低,是入狱这一结局的保护因素;反之如果相对危险度大于1且95%C1包括1,说明有罪辩护组入狱的风险高于无罪辩护组,是结局的危险因素。如果相对危险度的95%置信区间包括1,说明有罪辩护组与无罪辩护组入狱的风险差异无统计学意义。需要注意的是,必须把自变量选入行,结局变量选入列,否则得到的相对危险度数值将会是错误的。
R*C列联表卡方检验应该注意的问题:
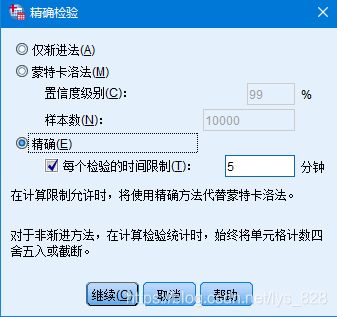
- 不同于四格表 χ 2 \chi^{2} χ2检验, SPSS对于 R ∗ C R*C R∗C 列联表 χ 2 \chi^{2} χ2检验不会自动输出Fisher确切概率检验结果,如果样本例数较少,请在【精确】设置中勾选【精确】以便输出Fisher确切概率检验结果(如下图)
- 所有理论频数>=5,看皮尔逊卡方(Pearson Chi-Square)结果。
- 超过20%的理论频数<5或至少1个理论频数<1,看费希尔精确检验(Fisher’s Exact Test)结果(也可以考虑增加样本量或者依据专业判断适当合并行或列,再进行 χ 2 \chi^{2} χ2检验)
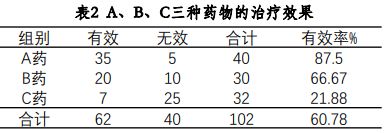
- 在表格下方的注释部分SPSS会提示是否有理论频数小于5,以及最小的理论频数是多少,方便选择恰当的检验方法。本案例中所有理论频数>5,所以直接看皮尔逊卡方(Pearson Chi-Square)结果: χ 2 \chi^{2} χ2=32.736, р < 0.001
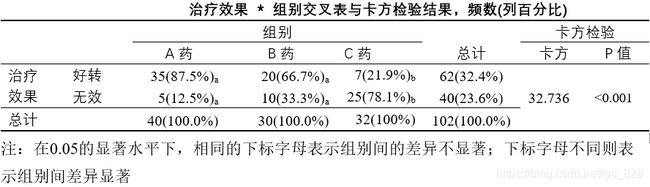
- 通过 χ 2 \chi^{2} χ2检验发现3种药物的治愈率存在显著差异,此时还需要进一步考虑三种药物到底谁与谁之间的差异存在统计学意义,这里就需要用到卡方检验的两两比较。在【单元格】设置中,勾选【比较列比例】同时勾选调整的p值。两两比较的结果将会直接标注在交叉表中。

输出结果如下,可以看到最后的提示,结果是满足皮尔逊卡方,看第一行结果就可以了

(4)结果分析
结果整理成三线表,首先针对于2x2列联表,输出的结果如下,先给出卡方检验的结果,然后再进行风险评估
对于RxC列联表,给出卡方检验结果和整合结果。注意最后要加注释,对里面整理的内容加一下注解
4.3 分层卡方检验
分层卡方检验:控制某种或某几种分类因素的作用后,检验另两个分类变最是否相互独立。比如控制性别,年龄等因素后,检验吸烟是否和呼吸道疾病有关。
(1)是什么
检验控制某种或某几种分类因素的作用以后,另两个分类变最是否相互独立。如控制性别,年龄等因素的影响以后,检验吸烟是否和呼吸道疾病有关
(2)使用要求
多个类比变量 + 数值
(3)怎么使用
案例17
比如为了研究吸烟对某呼吸道疾病发生风险的影响,共纳入了350名研究对象,并记录了他们的疾病状态、吸烟、性别等信息,数据如下表所示,请检验吸烟是否影响该疾病的发生风险,考虑性别这一可能的混杂因素情况又会如何?
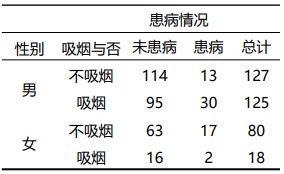
分析步骤:首先对吸烟和疾病之间的关联性进行了卡方检验,其结果显示 χ 2 \chi^{2} χ2= 3.607, P= 0.058 ,OR= 1.701, 95%置信区间为0.980-2.953,无统计学显著性,可认为吸烟对于该疾病的发生风险并无影响。

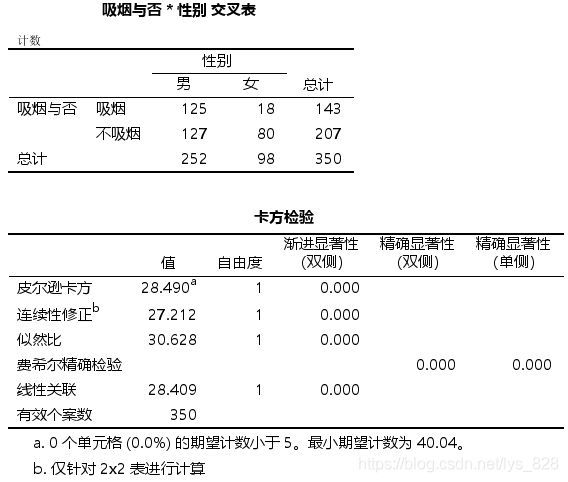
但值得注意的是卡方检验的P值很接近0.05,而且OR>1,对于患病这一结局,吸烟这一因素的相对危险度为1.544,倾向于认为吸烟是一个危险因素。观察交叉表可知男性和女性中,吸烟人群所占的比例存在着较大的差异,其中男性吸烟者占比125/ (125 + 127) = 49.6%,女性吸烟者占比18.4%,两组相比差异显著(P<0.001,见下图分析了吸烟与否和性别的关系)。那么性别可能为一个混杂因素,影响了初步分析时吸烟对该疾病的整体效应,因此这里把性别作为一个分层因素,采用分层卡方检验,来分析不同性别分层下,吸烟因素对于该疾病发生风险的影响。
在SPSS中执行分层卡方检验:
- 在【交叉表】菜单中,将患病与否选入【列】 ,将吸烟与否选入【行】 ,将分层变量性别选入【层】。 如果需要同时控制多个分层因素,可以点击下一个,将下一个分层因素选入框中, SPSS允许最多设置8层。
- 点击【统计】 ,勾选卡方(Chi-square)、风险(Risk)和柯克兰和曼特尔-亨塞尔统计(Cochran’s and Mantel -Haenszel statistics)

输出结果如下,第一个表格为三者的交叉表,了解基本的信息

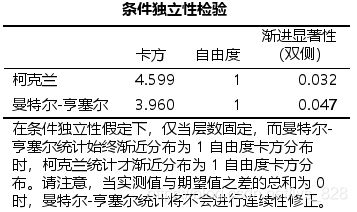
第二个表就是分层卡方检验的结果,注意d的注释,这里就需要查看连续性修正的结果

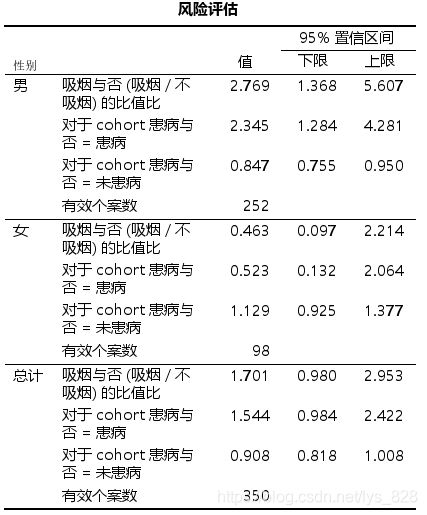
第三个表就是风险评估
第四个表就是比值比齐性检验
比值比齐性检验(Test of Homogeneity of Odds Ratio)表对不同分层下OR值是否一致进行检验。表格中输出了两种同质性检验方法的统计量及其检验结果, Breslow-Day法x2= 4.624, P=0.032,塔罗内(Tarone’s )法 χ 2 \chi^{2} χ2 =4.617, P= 0.032,两种方法P都小于0.05,说明按照性别分层后,层间的OR值存在异质性。

第五个表就是条件独立性检验
条件独立性检验(Tests of Conditional Independence)表为分层卡方检验的结果,表格中输出了两种方法的统计量,柯克兰(Cochran’s)法 χ 2 \chi^{2} χ2 =4.599, P-0.032,曼特尔-亨塞尔(Mantel-Haenszel)法 χ 2 \chi^{2} χ2=3.960, P-0.047。两种方法都显示P<0.05,说明在考虑了性别这一分层因素影响后,吸烟因素与该疾病的发生风险有关。
(4)结果分析
在卡方检验(Chi-square Tests)的表中,分别给出了男性、女性和总体人群卡方检验的结果。
- 对于男性, χ 2 \chi^{2} χ2=8.433, P=0.004, OR=2.769, 95%置信区间为1.368-5.607,提示在男性中,吸烟是该疾病的一个危险因素。
- 对于女性, χ 2 \chi^{2} χ2=0.427, P=0.514, OR=0.463, 95%置信区间为0.097-2.214,提示在女性中,吸烟对该疾病的发生没有影响。
最后整理汇总成为三线表,如下。前面的内容就是简单的交叉表,往后就是整体的卡方检验(没有考虑性别),然后就是考虑性别的分层卡方检验,最后就是对于分层卡方检验的检验(比值比齐性检验)

综合汇报:比值比齐性检验结果显示P<0.05,说明层间的OR值具有异质性,此时不宜合并OR值。因此按照性别进行分层的结果是有意义的
- 在男性中,吸烟是该疾病发生的一危险因素, OR=2.769,95%置信区间为1.368-5.607, P-0.004,即男性吸烟者该疾病的发生风险为男性非吸烟者的2.769倍;
- 在女性中,吸烟对该疾病的发生没有影响, OR=0.463, 95%置信区间为0.097-2.214, P=0.514
4.4 配对卡方检验(麦克尼马尔检验)
(1)是什么
常用于医学领域,检验两种评价方法结果的一致性,如采用两种诊断方法对同一批人进行诊断,判断其诊断结果是否一致。对于配对设计的列联表,其行和列的类别是配对的,不能使用一般的卡方检验进行分析,要使用配对卡方检验(MCNemar检验)和Карра—致性分析。
(2)使用要求
两种检测方法 + 类别变量 + 数值
(3)怎么使用
案例18
有两种方法可用于诊断某种癌症, A方法简单易行,成本低,患者更容易接受, B方法结果可靠,但操作繁琐,患者配合困难。某研究人员选择了53例待诊断的门诊患者,每个患者分别用A和B两种方法进行诊断,诊断结果如表1所示,尝试根据数据判断两种方法诊断癌症有无差别, A方法是否可以代替B方法?

SPSS中实现配对卡方检验:
- 方式一: 【分析】 → 【描述统计】 →【交叉表】
- 方式二: 【分析】→【非参数检验】-【相关样本】
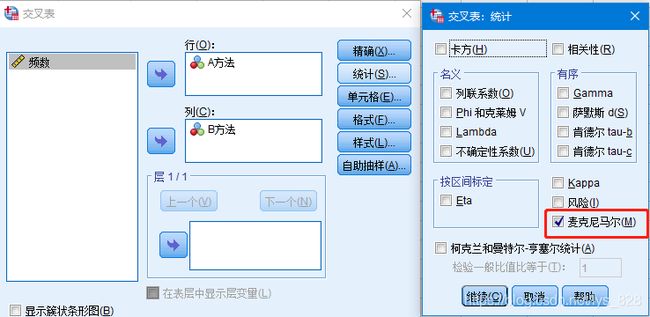
输出结果如下

如果使用的是第二种方法,现在字段选项中添加两个要检验的变量,然后在设置中选择麦克尼马尔检验

输出结果如下,和第一种方法获得的结果是一致。

(4)结果分析
2×2配对列联表的卡方检验使用的是麦克尼马尔检验(McNemar Test),根据SPSS给出的McNemer检验结果:P=0.092 > 0.05,说明A,B两种方法诊断结果一致。
如果是R*C列联表,配对卡方检验使用的是麦克尼马尔·鲍克检验(McNemar-Bowker Test),比如使用两种方法分别测量心脏室壁收缩运动情况,结果如表2所示。试分析两种方法测量的结果之间是否有显著差异。
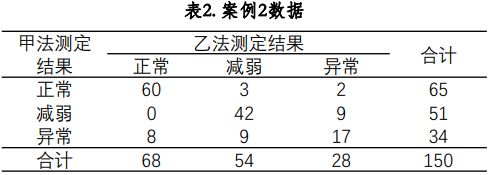
得到的配对卡方检验的结果如下,输出的P值=0.086>0.05,说明甲、乙两种方法的测定结果一致。

将上面的内容整理成三线表(2x2),如下
R*C列联表整理成为三线表如下

4.5 Kappa一致性分析
上面的两个配对卡方检验可以发现最后面都添加了Kappa一致性分析,就是因为它们两个通常是在一块使用
(1)是什么
配对卡方检验和Kappa-致性分析的区别:
- Kappa检验旨在评价两种方法是否存在一致性,而配对卡方检验主要确定两种方法诊断结果是否有差别。
- Kappa检验会利用列联表的全部数据,而配对卡方检验只利用“不一致“数据。
- Kappa检验可计算Kappa值用于评价一致性大小,而配对卡方检验只能给出两种方法差别是否具有统计学意义的判断。
(2)使用要求
和配对卡方检验一致
Kappa值判断标准:
- Kappa>=0.75,说明两种方法诊断结果一致性较好;
- 0.4<=Kappa<0.75,说明两种方法诊断结果—致性一般;
- Kapp
(3)怎么使用
案例19
在执行配对卡方检验的基础上,勾选【统计】设置中的【kappa】选项。
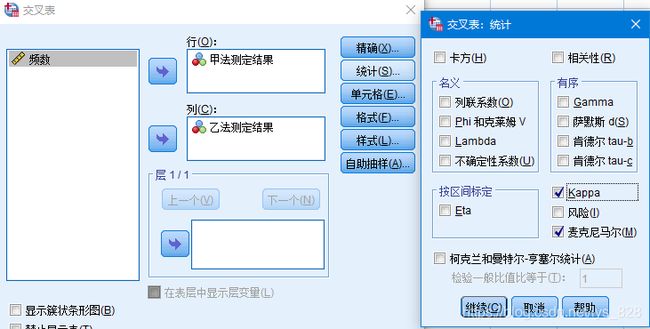
输出结果如下,麦克尼马尔检验结果不变,多出一个对称测量的表格
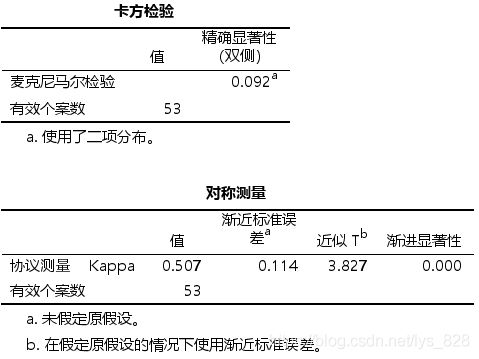
(4)结果分析
最后Kappa会得到一个值和渐进显著性,先看p值,这里是小于0.05说明有统计学意义的,然后对比一下Kappa的取值,说明两种方法诊断结果—致性一般。具体三线表的展示形式见上面的配对卡方检验
5 非参数检验
前面的章节中,我们学习过单因素方差分析,如果想要检验3个正态总体的均值是否相同,做单因素方差分析即可。单因素方差分析是一个典型的参数检验方法,需要注意的是,单因素方差分析等参数检验方法对数据的分布形态是有要求的,对于单因素方差分析而言,其要求残差满足均值为0的正态分布,并且组间方差要满足齐性。但在实际的应用中,有些数据是不满足这些参数检验的前提条件的,如果不顾这些前提条件,强行使用这些参数检验方法,那么得到的结果可能很反常。
非参数检验对总体分布几乎没有什么假定,几乎任何分布形态、任何类型的数据都能够进行非参数检验顾名思义,非参数检验不关注总体参数的比较,其进行统计推断的方法也和总体分布无关,它们进行的不再是参数间的比较,而是分布位置、分布形态之间的比较,研究目标总体与理论总体分布之间的比较,或者各样本所在总体的分布位置之间的比较等,因此不受总体分布的限定。不过,非参数检验依然遵循于假设检验的基本思想和基本准则,在缺乏总体分布信息的支撑下,利用假设检验的基本思想、数学方法和技巧构造出相应的统计量进行假设检验,拓宽了分析的领域。和参数方法相比,非参数检验方法的优势如下:-
- 稳健性,不至于因为前提条件过分理想化而无法切合实际情况,不至于对个别偏离较大的数据太敏感。
- 对数据的测量尺度无约束,对数据的要求也不严格,什么数据类型都可以做。
- 适用于小样本、总体分布未知的样本、数据污染样本、混杂样本等。
相比参数检验,非参数检验也有缺点:非参数检验方法中用的是数据的等级次序或符号秩,没有利用实际数值,会损失部分信息,检验效率较低,对于适合参数检验的数据资料,应该首选参数检验,只有当参数检验的条件不满足时,才选择非参数检验。
非参数检验中的常见概念
秩(rank) :对于样数据 X 1 , X 2 , . . . , X n X_{1},X_{2},...,X_{n} X1,X2,...,Xn,小到大的顺序排成一列,排在第一的数据其秩为1,排最后的数据其秩为n,其它数据的秩分别为它们所占位置的序号。考试成绩的排名就是一个简单的秩,只是倒了过来,最大的被排在了第一位,而这里所讲的秩应当对应着倒数的名次,倒数第一的秩为1。下面的表格中展示了一组数据以及它们的秩:

结(tie) :在许多情况下,数据中会有相同的值出现,此时如果排秩就会出现同秩的现象,就像考试排名中的并列第5、并列第7。这·种情况称为数据中的结,结中数值的秩为它们按从小到大的顺序排列后所处位置的平均值。结的修正与否将影响到检验的结果,但SPSS等统计软件会自动完成结的修正,用户无需担心。下表中展示了包含结(tie)的一组数据以及它们的秩。

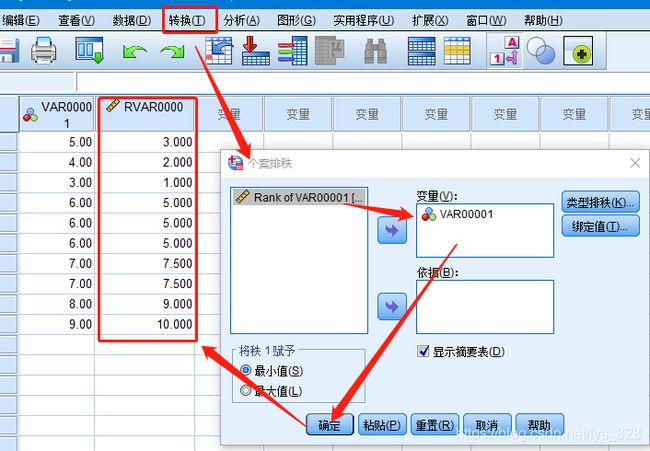
SPSS进行排秩,操作如下。在转换选项中选择个案排秩,然后选择要排秩的变量后确认,就会在数据中生成好一列排好秩的数据
5.1 单样本wilcoxon检验
(1)是什么
对应于单样本T检验
(2)使用要求
小样本且样本数据不服从正态分布
(3)怎么使用
案例20
一家制药公司的药剂师想要确定一种新研发的抗酸药的平均反应时间是否不超过12分钟。该药剂师测量了16个抗酸药样本的反应时间,数据如下表所示。

注意这里的样本量小于30,且不服从正态分布,因此就可以使用单样本wilcoxon检验(但是需要注意一点:该检验检验的是中位数,题目要求的是平均值)
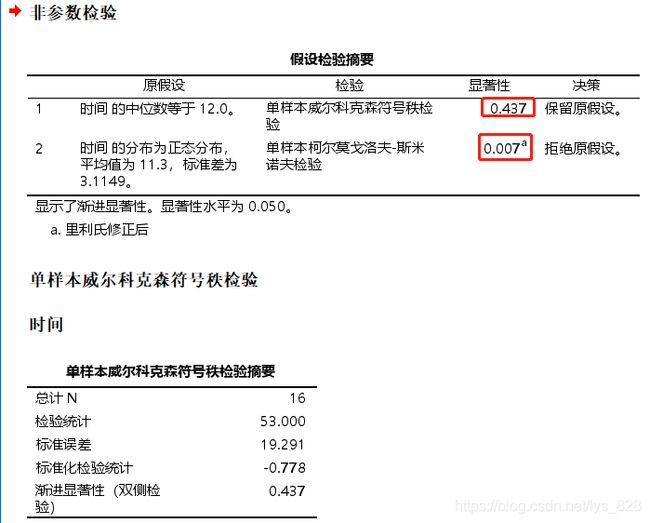
SPSS操作:【分析】 →【非参数检验】 → 【单样本】 ,同时执行单样本的中位数检验和正态性检验。

结果分析: 下图显示了单样本Wilcoxon检验和单样本正态性检验的结果。正态性检验显示P值=0.007<0.05,表明数据不满足正态分布;wilcoxon检验的P值=0.437>0.05,没有拒绝原假设,表示样本所来自的总体中位数没有不同于12
(4)结果分析
整理成为论文中三线表形式就如下,要注意,这里中位数就是代替均值,四分位距就代替之前的标准误差

5.2 配对样本wilcoxon符号秩检验
(1)是什么
对应配对样本T检验,检查是够有差异
(2)使用要求
不满足配对样本T检验的条件
(3)怎么使用
案例21
某企业在公司内推行改革,人力资源部门分别对部分员工改革前的业绩和改革后的业绩进行了调查,数据如下表所示,试分析改革是否有助于员工提升业绩?
![]()
SPSS软件操作:
- 方法一: 【分析】 →【非参数检验】→ 【相关样本】→ 【字段】 → 【设置】
- 方法二:【分析】 →【非参数检验】→ 【旧对话框】 →【两个相关样本】→【相关样本】
采用方法一进行

输出结果如下
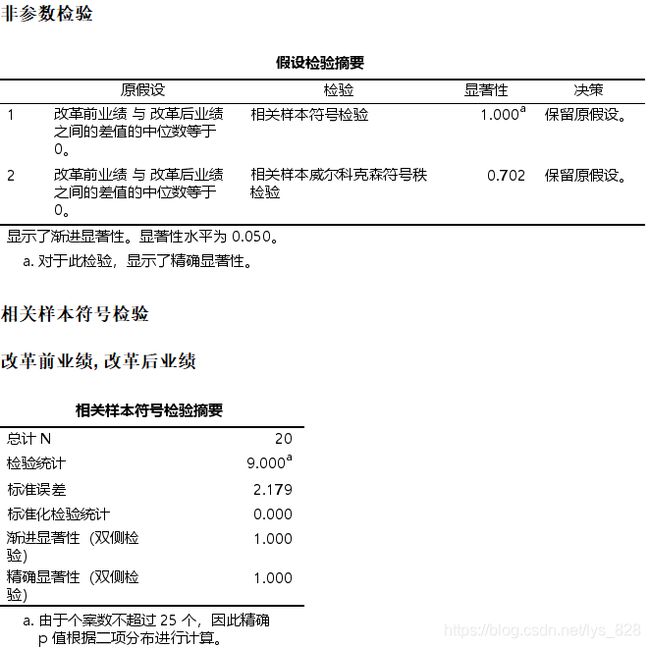
检验的结果,统计量和p值
采用第二中方法,操作如下,注意勾选下面的选项
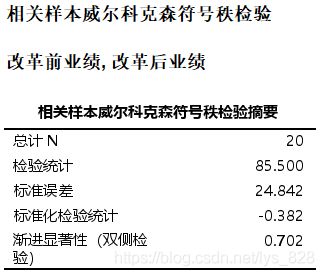
输出结果如下,先给出的符号秩检验
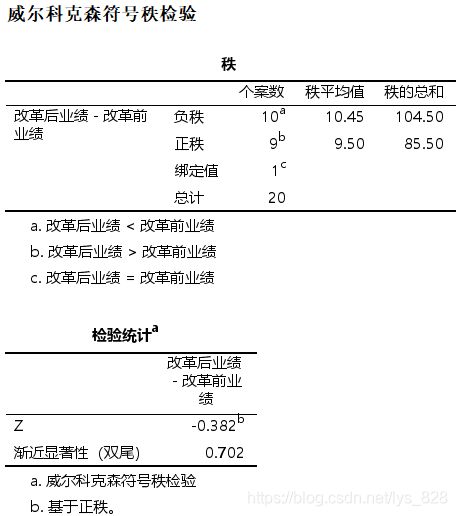
然后给出的是符号检验,最后检验的显著性为1,说明也接受了原假设,改革前后没有区别

(4)结果分析
这里的中位数和四分距可以通过定制表的方式获得,后面的统计量和p值,注意是就对话框里面的选项(新的相关样本里面也有)

结果说明改革前业绩和改革后业绩的差值为0不能被拒绝,也就是改革前后没有明显区别。
5.3 Kendall协同系数检验
(1)是什么
对应配对样本T检验,检查是够有一致性
对不同评价方法的一致性进行检验,比如常见的专家打分,就可以使用Kendall进行专家打分的一致性进行检验
(2)使用要求
两个类别变量(评价的方法放在行,被评价的对象放在列) + 数值
(3)怎么使用
案例22
有5种方法可用来评估农用载具的乘坐舒适性,现使用这5种方法对8种农用载具进行评价,每种方法都给出8种载具的舒适性排名,具体结果如下表所示,请根据数据评估5种排名方法的一致性。

SPSS软件操作:
- 方法一: 【分析】 →【非参数检验】→ 【相关样本】→ 【字段】 → 【设置】
- 方法二:【分析】 →【非参数检验】→ 【旧对话框】 →【k个相关样本】
和上面的一样只是要勾选的内容不同,使用方法一,勾选内容如下

输出结果如下:

使用方法二进行操作,勾选情况如下
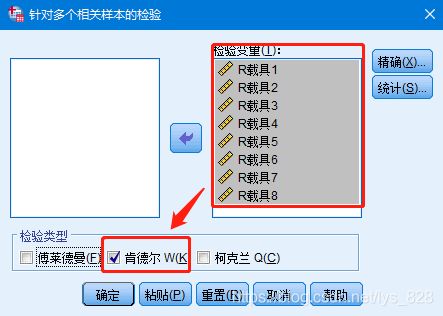
输出结果如下,和上面的内容一致,但是新版的内容还会输出很多详细的对比图

(4)结果分析
Kendal协同系数检验得到肯德尔系数W=0.834, P<0.001,说明肯德尔协同系数有统计学意义。Kendall的w的范围从0(完全不一致)到1 (完全一致) ,此处的肯德尔协同系数值为0.834,说明一致性很好
5.4 两独立样本Mann-Whitney 检验
(1)是什么
对应着两独立样本T检验
(2)使用要求
小样本数据且不满足正态分布
当因变量是等级变量时,不能使用参数检验的方法,也得使用非参数检验的方法
(3)怎么使用
案例23
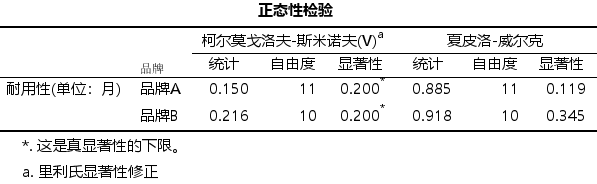
某个州的公路管理部门使用两种品牌的油漆喷涂公路标线。公路管理部门的官员想了解两种品牌的油漆的耐用性是否存在差异。对于每种油漆,这位官员记录了油漆在高速公路上保留的月数。

案例分析:本案例的数据为来自两个独立总体的小样本数据(样本量分别为11, 10) 。需判断两组数据的分布形态是否基本满足正态分布,如满足,则可使用两独立样本T检验,如严重偏态,则需要使用非参数检验的方法。
上述的数据经过检验,发现满足两样本满足正态分布
再进一步测试是否满足方差齐性,输出结果发现这个数据是完全满足两样本独立T检验的要求,因此可以使用两独立样本T检验

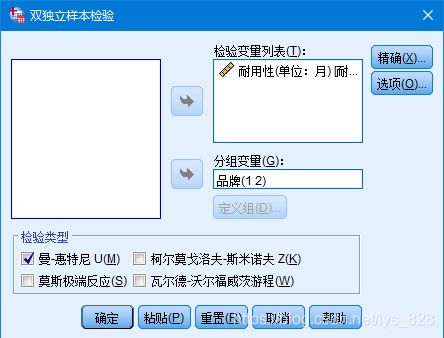
当然这里也可以尝试使用非参数检验的方式进行,在满足参数检验的前提尽量使用参数检验,不是说非参数不能用,作为无法满足参数检验的时候问题解决的方式,这里也可以用非参数检验,看一看最后的结果如何
SPSS操作步骤:【分析】 →【非参数检验】→ 【旧对话框】 →【2个独立样本】
输出结果如下,
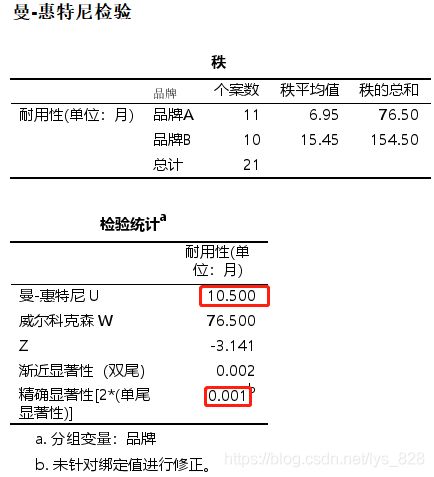
使用非参数检验的结果也是p值小于0.05,拒绝原假设,说明没有足够的证据证明两个油漆的耐用性是相同的(也就是两种油漆的耐用性是有差异的)
(4)结果分析
将非参数检验的结果梳理成论文的三线表形式就如下,前面的描述性统计的部分可以用定制表的功能输出,后面的部分就是上面输出的内容。Mann-Whitney检验所得U统计量=10.5, P=0.001<0.05,拒绝零假设(不同品牌的油漆耐用月数的中位数相同) ,说明不同品牌的油漆耐用性之间存在显著差异,品牌A油漆的耐用性显著低于品牌B。

如果是对于汇总数据,参数检验里面有一个摘要独立样本T检验,这里非参数检验也可以,方法和上面的一样,只是进行前要进行个案加权就可以了
5.5 多独立样本Kruskal-Wallis 检验
(1)是什么
单因素方差分析的非参数检验
(2)使用要求
一个多类别变量 + 数值
(3)怎么使用
案例24
一位卫生行政人员想要比较同一个城市中三家医院的空病床位数。这位行政人员从每家医院的记录中随机选择了不相同的11天的记录,并输入了每天的空病床数。

先检验是不是满足单因素方差的条件,一个是方差齐性,还有一个就是残差的正态性
先检查方差齐性,发现不满足,而且方差分析的结果是不显著
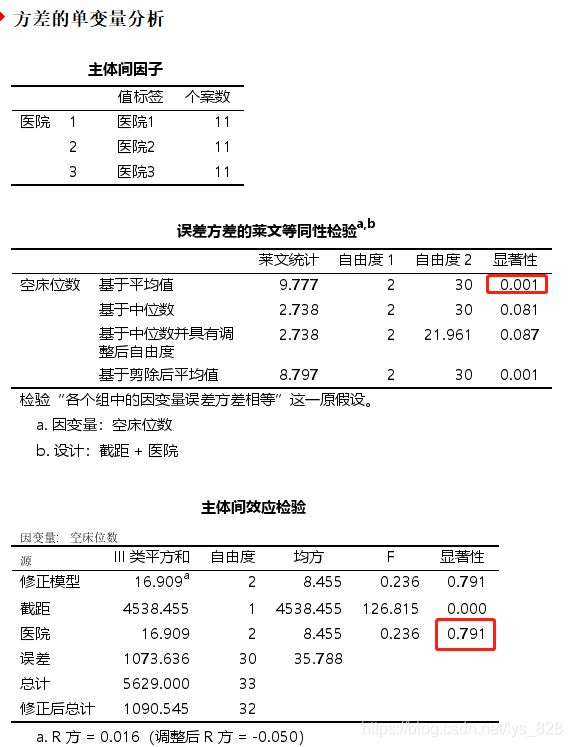
第二步是看一残差是否满足正态分布(其实上面不符合这里也不用看了,不管是否服从正态分布,只能用非参数检验了),结果显示是服从的,当然这一步是要有的,因为有的数据满足第一步,但是第二步不满足,这里把该走的流程走完

那么就是进行非参数检验了,步骤如下

输出结果如下

(4)结果分析
将结果整理为论文使用的三线表形式,如下。根据统计量及其对应的p值,可以说明无法拒绝原假设,可以认为在不同的类别医院中,空床位数的分布相同。

5.6 多独立样本非参数检验与多重比较(Kruskal-Wallis 检验)
(1)是什么
对应着单因素方差分析 (进一步探究组件两两比较)
(2)使用要求
一个类别变量(多总体) + 数值
(3)怎么使用
案例25
案例:为了调查不同等级学校的学生对自己大学的教育质量的满意程度,现分别从国家985、国家211、普通一本、二本院校、三本院校高校随机抽取一部分学生,请他们对自己大学教育质量感知情况进行评分,并对所得数据进行比较。
数据总共有190条,分为5组
案例分析:本案例数据来自于人文社科领域,该领域很多数据一般都呈现出偏态分布,对于本案例数据,可以看作是来自于5个不同总体(5个不同等级的学校) ,因变量为数值类型,分析发现,如果采用单因子方差分析,残差的正态性和组间方差齐性均无法满足故需要使用非参数检验对数据进行分析。由于本案例中,存在多个组,如果检验出组间差异显著,那么还需要执行组间两两比较。
先检验样本符不符合参数检验的要求,第一步方差齐性,如下输出结果可知,已经不满足方差齐性了,显著p值小于0.05也就没有意义了
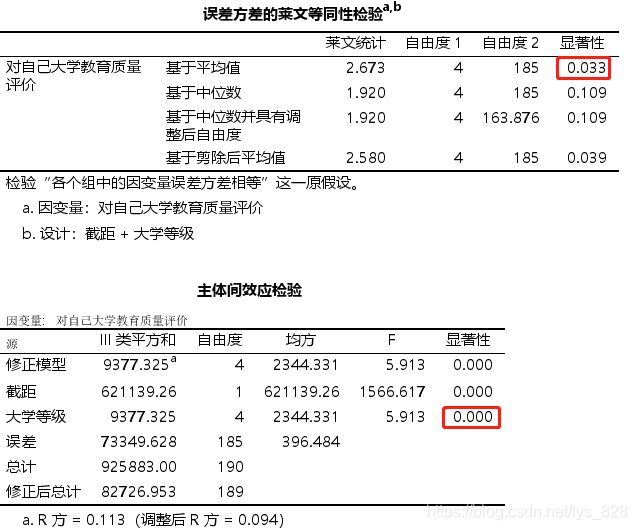
第二步还是进行残差正态性检验,输出结果中发现残差也不符合正态分布

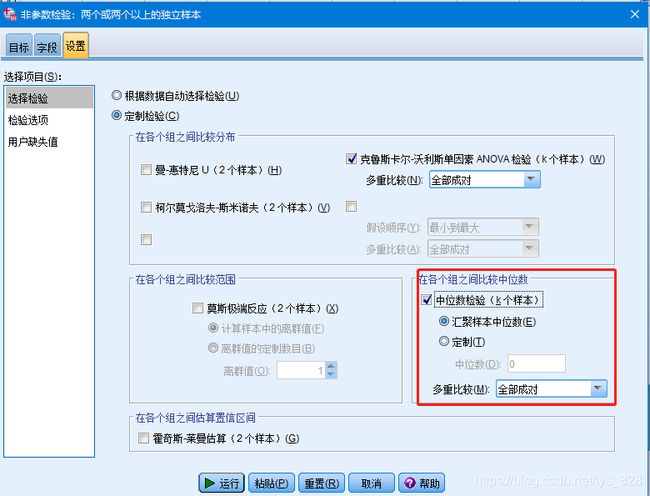
故数据只能使用非参数检验进行,操作如下,这里要用到各组之间的两两比较,因此可以勾选下面框中的比较中位数的检验
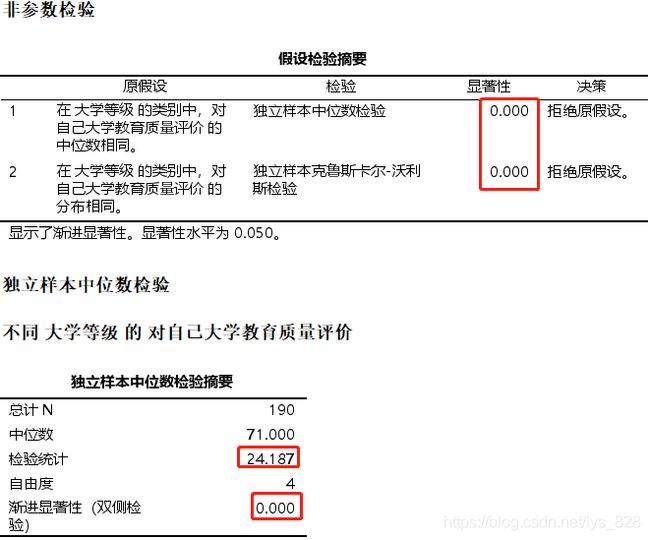
输出结果如下
分组之间的两两比较,很友好,但是注意在论文写好用的哪一种方法

最后一个就是使用Kruskal-Wallis 检验的统计量和对应的p值
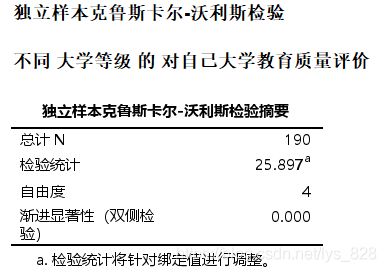
还有Kruskal-Wallis 检验得到的分组比较

(4)结果分析
将上面的结果进行整理输出三线表样式结果如下。一定要注意前面得到的结果是两种方式,第一种是基于中位数检验结果,第二个是基于Kruskal-Wallis 检验的结果,最后两两比较的结果中后者国家211-国家985是显著的,但是在前者这两个就是不显著的,因此在写进三线表的时候应该明确表明使用的哪个方式
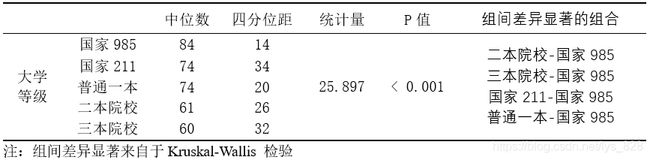
Kruskal-Wallis检验所得统计量=25.987, P<0.001,拒绝零假设,说明不同等级学校的学生对自己所在学校教育质量感知存,在显著差异,具体而言985院校学生对自己学校教育质量评价最高,显著高于另外4个等级的院校。而另外4个等级院校的学生对自己学校的教育质量感知之间没有显著差异。
6 相关分析与回归模型
关于相关分析和偏相关分析,一般就是输出回归模型创建前的准备步骤,这里就介绍一下核心内容及操作
6.1 相关分析
解决四个问题
- ①变量之间是否存在关系? (通过散点图观察变量之间是否存在相关关系)
- ②如果存在关系,它们之间是什么关系? (通过散点图观察变量之间是何种相关关系)
- ③关系强度如何? (通过相关系数来衡量相关关系的强弱与方向)
- ④相关系数是否有统计学意义? (要对相关系数进行假设检验)
有一个核心的误区:两个变量具有相关关系并不能说明了它们之间存在着因果关系,这个不是等价的(因果关系的判断往往需要我们专业知识的介入)
核心要点:
- Pearson相关系数:适用于数值型变量,是运用最广的一种度量相关程度统计量;
- Spearman等级相关:适用于度量有序分类变量之间的相关程度;
- Kendall tua-b等级相关:它也是用来度量有序分类变量之间的线性相关关系。

SPSS相关分析操作:【分析】→ 【相关】 → 【双变量】
案例26
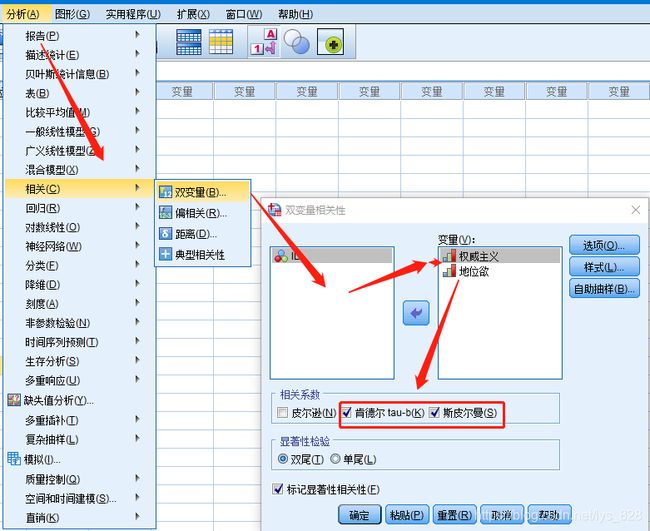
在某社会学调查中,通过10级量表测量了12个被调查者的权威主义、地位欲。数据如下表所示,请尝试分析权威主义、地位欲之间的相关性。

录入数据,值标签编码后,进行如下操作,由于都是有序类别数据,因此可以勾选连 Spearman和Kendall tua-b
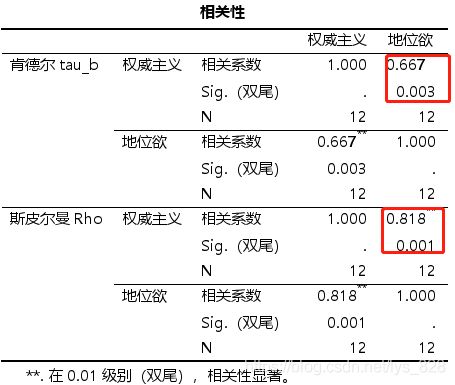
输出结果如下,两种检验方法都显示显著相关
6.2 偏相关分析
在多变量的情况下,变量之间的相关关系是很复杂的,如:商品的需求与价格关系,受收入水平的影响。此时需要对其它变量的影响,进行控制的条件下,分析多个变量中某两个变量之间的线性相关的程度,计算偏相关系数。
案例27
下表所示的数据为某大学统计系的学生5个科目考试成绩,尝试对成绩数据进行分析:
- ①vectors和algebra分数之间相关系数;
- ②控制statistics分数时, vectors和algebra分数之间的相关系数;
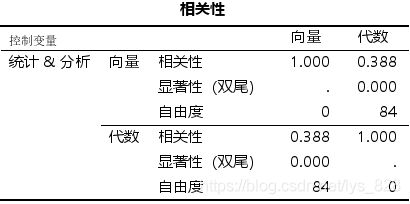
- ③控制analysis和statistics分数时,vectors和algebra分数之间的相关系数;
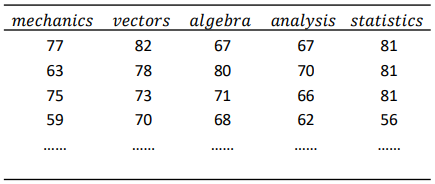
第一问,还是和上面的操作一样,只不过检验的方法改为Pearson相关系数,可以发现这两个变量是显著相关。
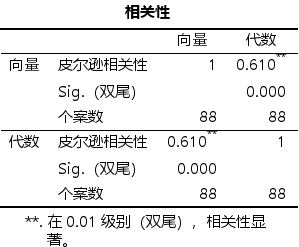
第二步中就是进行偏相关分析,操作如下,就是将要控制的变量加到下面的框中,点击确认就行
输出结果如下,可以发现在控制因素下,相关性系数有所下降,但还是显著的

第三问,还是一样,只不过是在控制中继续加入一个变量,输出结果如下,这次的相关性系数就更低了
有时候需要查看两两变量的相关性,操作如下
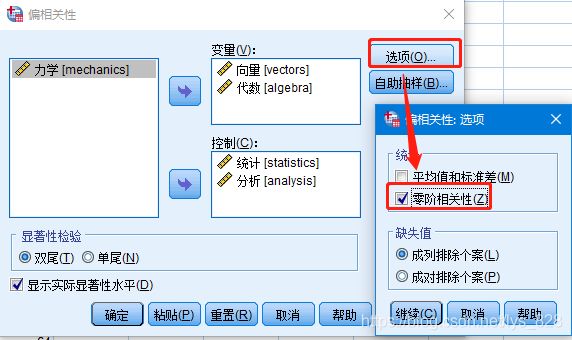
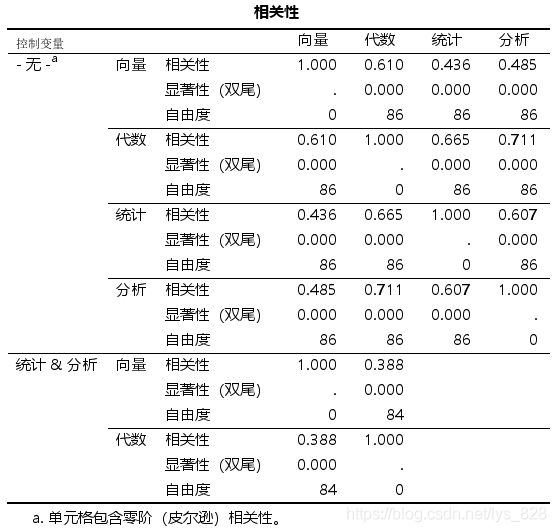
输出结果如下,上面是两两比较的结果,下面是偏相关的分析结果
6.3 一元线性回归
先理清一下区别和联系(相关分析与线性回归模型):
- 相关分析的目的是测量变量之间的关系强度,使用的工具为相关系数。线性回归分析研究一个连续性变量(因变量)的取值随着其它变量(自变量)的数值变化而变化的趋势,通过回归方程解释变量之间的关系显的更为精确,可以计算出自变量改变一个单位时因变量平均改变的单位数量,这是相关分析无法做到的。除了描述变量之间的关系以外,通过回归方程还可以进行预测和控制。
- 相关分析中变量x和y处于平等的地位(不过通常将因变量放在列,自变量放在行),回归分析中,变量y称为因变量,处在被解释的地位, x称为自变量,用于预测因变量的变化。相关分析中所涉及的变量x和y都是随机变量,回归分析中,因变量y是随机变量,自变量x是非随机变量。
回归模型中的基本概念:
因变量(dependent variable) :被预测或者被解释的变量,在一个回归模型中,因变量只有一个
自变量(independent variable):用来解释或者预测因变量的变量,在一个回归模型中,可以有一个或者多个自变量。只有1个自变量的线性回归模型称为一元线性回归模型,有2个或2个以上自变量的线性回归模型称为多元线性回归模型。
(1)是什么
一元线性回归模型的通用表达式为: y = β 0 + β 1 x + ε y=\beta_{0}+\beta_{1}x+\varepsilon y=β0+β1x+ε,其中x和y分别表示自变量和因变量, β 0 \beta_{0} β0表示的是截距, β 1 \beta_{1} β1表示斜率, ε \varepsilon ε表示随机误差或残差,模型中包括线性部分和随机误差两个部分
(2)使用要求
- ①因变量与自变量之间具有线性关系;
- ②自变量x是非随机的,而因变量y是随机的;
- ③误差项是一个期望为0且满足正态分布的随机变量。
(3)怎么使用
案例28
某电子消费品公司想根据历史数据找出广告投入和销售收入之间的关系,从而根据广告投入估计今后的销售收入。过去几年的广告支出和销售收入数据如下表所示。

分析步骤:
- ①首先通过散点图观察两个变量之间是否有线性关系;
- ②如果有相关关系则进行回归分析,计算出回归方程的参数并进行假设检验,同时保存残差;
- ③检验残差是否满足均值为0的正态分布;
- ④如果数据满足线性回归的条件,那么就可使用得到的回归方程进行预测或控制。
第一步,绘制散点图,可以发现是满足线性关系

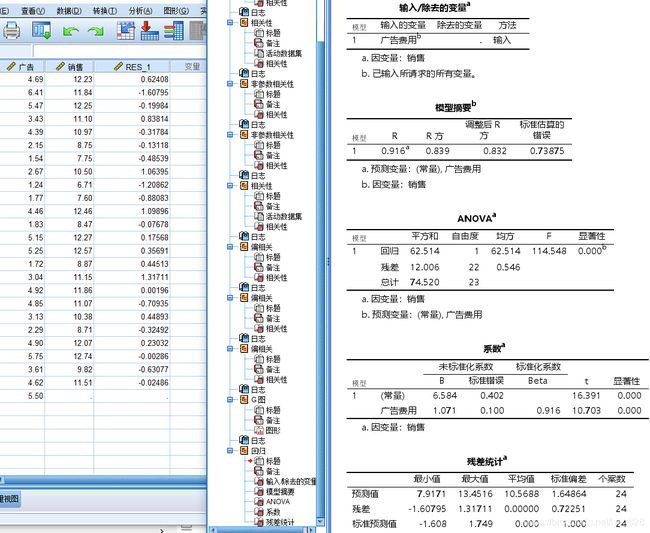
第二步,进行线性回归并保存残差

输出结果如下
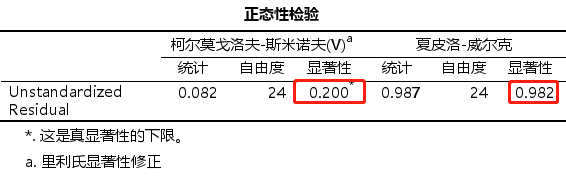
第三步检验残差的正态性,两种方式均满足
第四步,可以利用回归的结果进行预测或控制
(4)结果分析
整理成三线表的样式如下
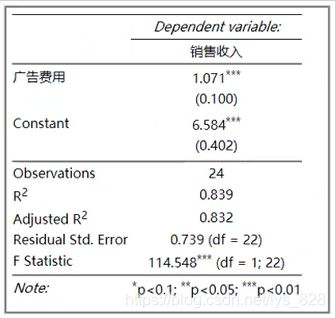
生成的回归方程为:销售收入 = 1.071 * 广告费用 + 6.584
模型解释:当广告投入每增加一个单位,销售收入增加1.071个单位,常数项6.584表示广告投入为0时的销售收入。
预测:给定广告支出=5.5时,预测销售额为12.48, 95%置信区间为(11.99, 12.96) 。
控制:期望销售收入达到12,则广告投入应该控制在(22-6.584)/1.071 = 5.06以上
6.4 多元线性回归
(1)是什么
在许多实际问题中,影响因变量的因素往往有多个,这种自变量有多个,因变量只有一个的回归模型称为多元回归模型。当因变量与各自变量之间为线性关系时,称为多元线性回归模型。可以用如下表达式来表示多元线性回归模型,其中 β 0 \beta_{0} β0为常数项, β 1 , β 2 , . . . , β k \beta_{1},\beta_{2},...,\beta_{k} β1,β2,...,βk为变量 x 1 , x 2 , . . , x k x_{1}, x_{2}, .., x_{k} x1,x2,..,xk前面的系数, ε \varepsilon ε表示模型的残差项。 y = β 0 + β 1 x 1 + β 2 x 2 + . . . + β k x k + ε y = \beta_{0} + \beta_{1}x_{1}+\beta_{2}x_{2}+...+\beta_{k}x_{k}+\varepsilon y=β0+β1x1+β2x2+...+βkxk+ε
(2)使用要求
- 第一步:首先明确要研究的因变量y,然后再结合专业知识、相关系数以及散点图共同确定影响因变量的k个自变量。
- 第二步:建立y与k个自变量之间的线性关系模型。
- 第三步:对模型进行评估、检验和诊断,具体包括查看各变量系数的统计显著性,是否存在共线性问题,残差是否满足等方差、均值为0、正态性的要求,以及专业上该模型是否合理。
- 第四步:如果确定数据满足建立多元线性回归模型的条件,则可使用得到的多元线性回归模型进行预测或者用以解释这些自变量如何影响模型中的因变量。
(3)怎么使用
案例29
数据集记录了美国50个州的一些基本情况(下图中例举部分数据),其中包括如下5个变量:人口(Population),平均收入(Income),文盲率(lliteracy),谋杀率(Murder),高中毕业生百分比(HS Grad),请尝试建立多元线性回归模型研究不同因素对谋杀率的影响。

第一步,确定自变量,通关相关分析,筛选与因变量有显著关系的自变量,这样建模完成之后才有可能使用自变量来解释因变量,分析结果如下。输出的表格分为两个部分,一部分就是第一行,用于确定自变量与因变量之间有没有显著的线性关系,第二部分是三角区域,用于确认自变量之间是够存在共线性的问题
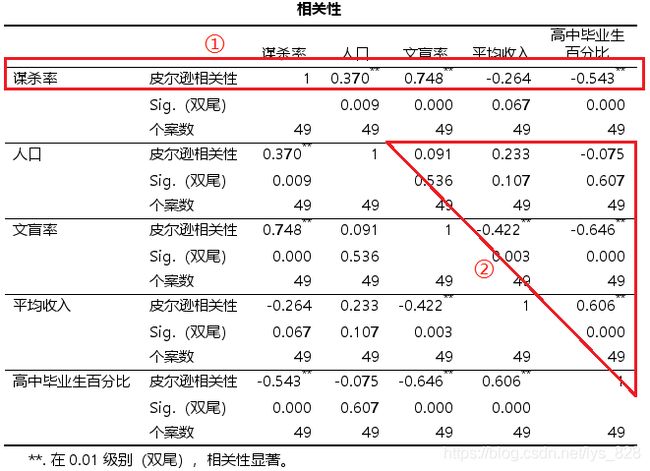
通过上面的输出可以发现,自变量平均收入与因变量谋杀率之间并没有显著相关,然后共线性这里spss中采用逐步回归的方式会帮我们清理掉部分变量,然后进行第二步建模,操作结果如下
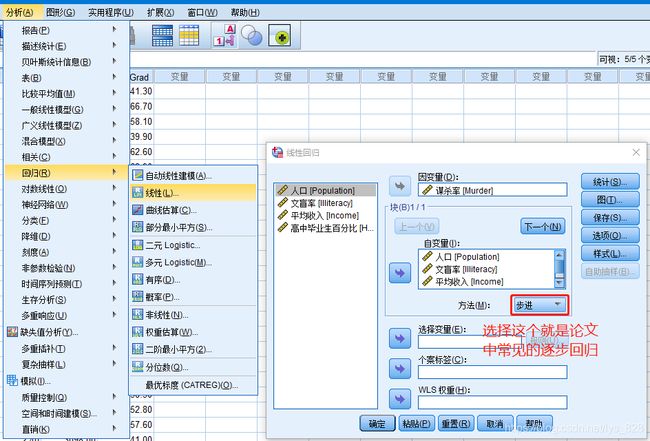
输出结果如下,结果会进行逐步的调整,所以会有很多个模型,要看最后一个,也就是调整R方得分最大的那个,最后保留的就是文盲率和人口。需要特别留意对于线性模型的检验,也就是第二个ANOVA表中F统计量和显著性,如果此处的显著性值大于0.05,那么建立的模型无效,无需看下面的内容,需要重新构建回归模型
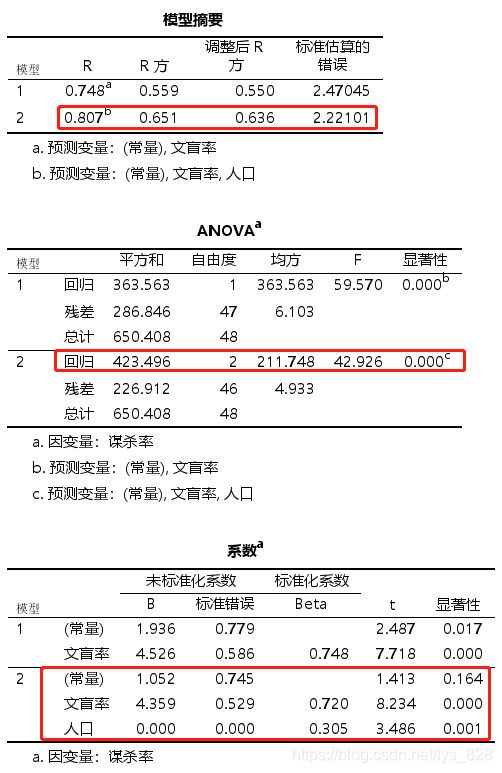
最后排除的变量也会进行说明,如下
第三步,进行模型诊断。其实上面F统计量已经给出了,是满足的。除了F检验外还可以使用残差分析,用来判断所建的模型是否合适
残差:是因变量 y i y_{i} yi的观测值与根据估计的回归方程求出的预测值 y i ^ \hat{y_{i}} yi^之差,用 e e e表示,它反映了用估计的回归方程预测而引起的误差。第i个观测值的残差可以写为: e = y i − y i ^ e=y_{i}-\hat{y_{i}} e=yi−yi^
标准化残差:残差除以它的标准差后的结果称为标准化残差(standardized residual),也称为Pearson残差或半学生化残差(semi-studentized residuals),用 z e z_{e} ze表示。第i个观测值的标准化残差可以表示为: z e = y i − y i ^ s e z_{e}=\frac{y_{i}-\hat{y_{i}}}{s _{e}} ze=seyi−yi^
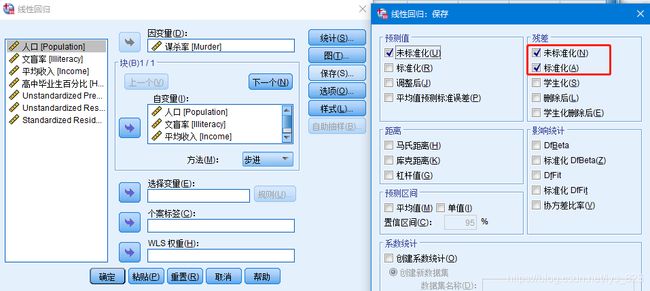
在SPSS中操作就是,“保存”按钮中勾选“未标准化”和“标准化”,分别为RES(未标准化残差) 和 ZRE(标准化残差),顺带也可以够选预测值,操作如下
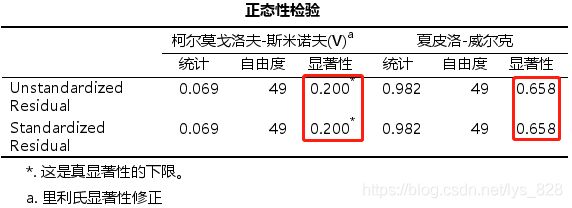
然后对残差进行正态性检验,输出如下。发现未标准化与标准化的结果是一致的,说明这两种只需要检验一个就行了,最后就是均满足正态分布
(4)结果分析
结果整理为三线表如下,这里只是示例,自变量较少的时候可以这么写,如果来个50-60个之间,就不适合了,可以直接写最后筛选完后的模型。一般在自变量中没有加括号是系数,加括号的表示标准误差。(下面的图只是给个示例,因为数据量不同,最后的模型参数有所不同)

生成的回归方程:Murder = 0.0002 x Population + 4.081 x lliteracy + 1.652
模型解释和预测可以参考上面一元线性回归的结果
★★★★★补充重点知识:(数据转换、共线性问题和虚拟变量)
多元线性回归模型中,两个或者两个以上的自变量彼此高度相关时,此回归模型中将存在严重的多重共线性。如果一个多元线性回归模型中有如下现象,说明此模型中存在多重共线性问题。
- ①各自变量之间显著相关(使用散点图矩阵和相关系数矩阵可以识别出该问题)
- ②)线性关系检验显著(F检验显著) ,各自变量系数却大多数不显著。
- ③模型中变量前的回归系数正负号与预期相反。
- ④容忍度(tolerance)小于0.1或者方差扩大因子(MF)大于10,认为存在严重共线性。
多重共线性会导致:
- ①整个模型的线性关系显著,但大部分回归系数却不显著;
- ②回归系数的符号与理论或者预期不符合。进而导致得到的回归模型无法用于解释自变量如何影响因变量,也无法将得到的模型用于预测。
多重共线性问题的处理:
- 删除相关性很强的两个自变量中的一个,或者删除多个相关性很强的自变量中的几个变量。(逐步回归的方式)
- 通过主成分分析或者因子分析提取公因子或主成分,将多个相关性很强的变量浓缩到一个变量中。
案例30
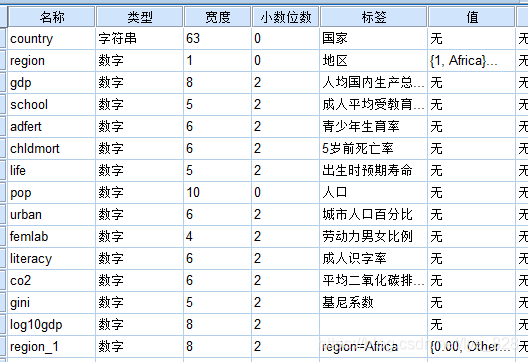
数据集录入的是世界范围内194个国家的经济,教育,文化等数据。要建立一个多元线性回归模型,其中因变量为life, 自变量为gdp,school, adfert, chldmorto
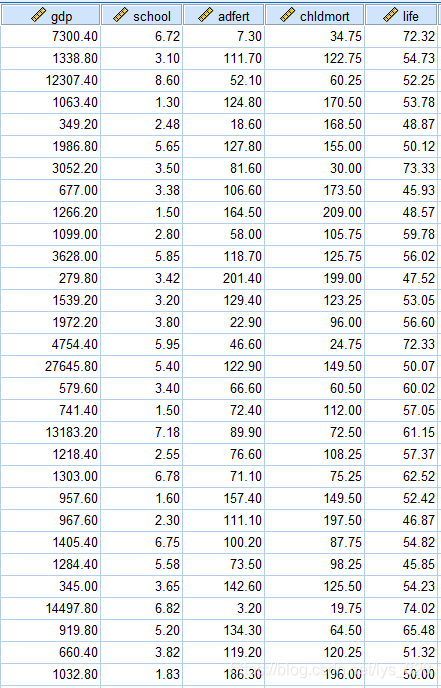
如果上来啥都不管直接进行建模看看输出的结果如何,模型的调整后的R方位-、884,F检验显著,school和adfert变量应该剔除。

那么接下来严格按照回归的步骤进行,对比一下两者的结果,第一步查看变量与因变量之间的关系,还是通过散点,不过自变量多的时候可以通过矩阵散点图,这样省的两个两个的点击

输出结果如下,可以查看最下面一行,也可以查看最右边的一列
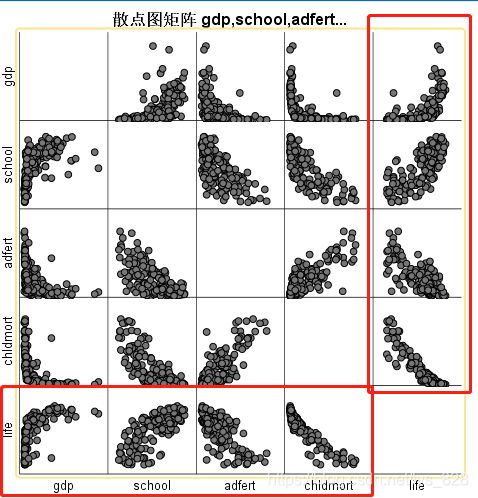
初步可以看出life与gdp之间并不像是线性关系,与其它的变量是呈现线性关系(对于不确定的可以再两两进行比较),这里单独把life和gdp拿出来单独查看线性关系,很明显是满足对数关系

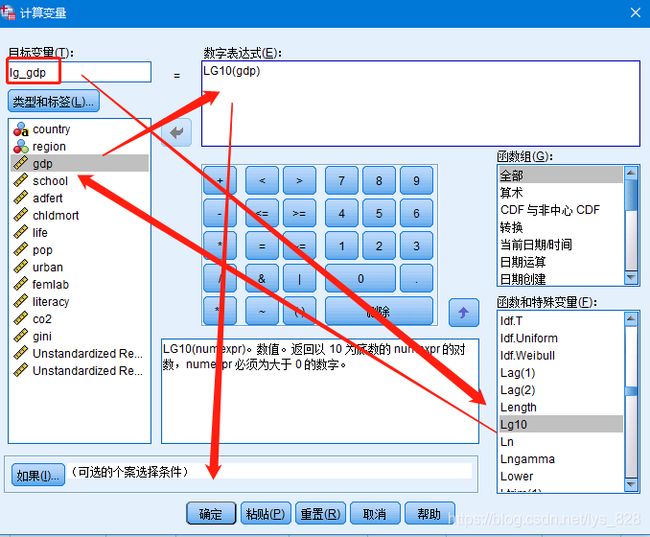
所以需要进行对数转换然后再判别线性关系
得到转化后的结果后绘制散点图如下,完美转化为线性关系了
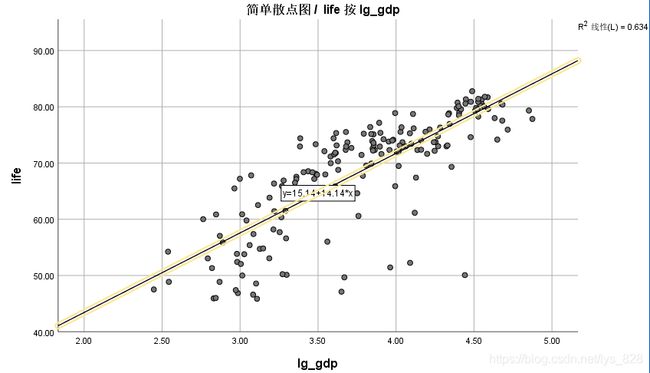
如果要表现出自变量与因变量之间的相关关系也可以输出一下
输出结果如下,不仅自变量与因变量之间存在着很强的相关性,而且自变量之间也存在着很强的相关性

最后就是采用逐步回归的方式来解决共线性的问题,输出结果如下。
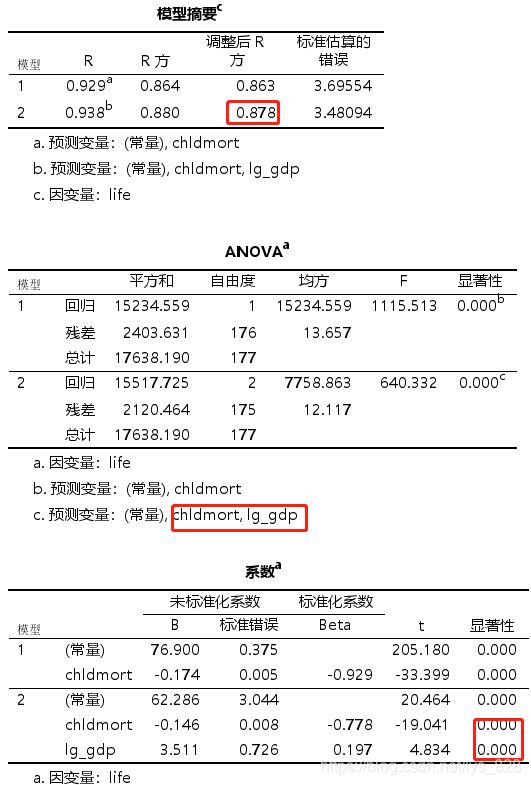
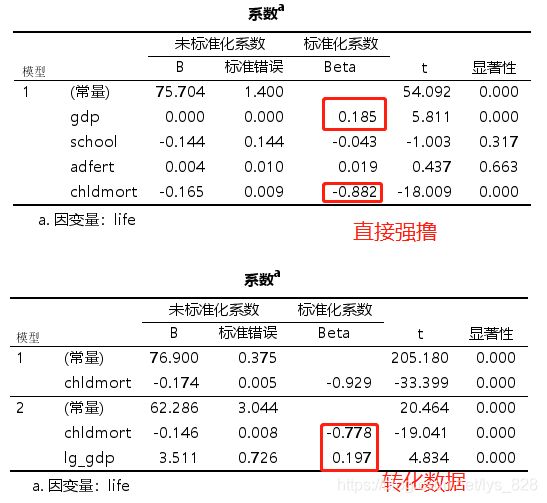
模型保留的也是两个变量,模型得分比什么都不处理来的还低一点,但是最重要的需要注意就是这里的标准化系数,用来解释自变量如何影响因变量的,差别还是存在的。(下面就是对比最后保留的结果和标准化系数)
最后一步就是进行模型诊断了,这里诊断出来残差是不符合正态性分布的,具体后续处理过程可以看后面层次回顾中的讲解
模型整理和之前的类似,这里就不再赘述了。
案例31
分类变量添加到线性回归模型中,比如要添加一个国家所处的洲,进行值编码,如下
如果直接进行线性回归,输出结果如下,模型得分只有0.347

对分类数据做哑变量处理再传入变量中,操作及结果如下
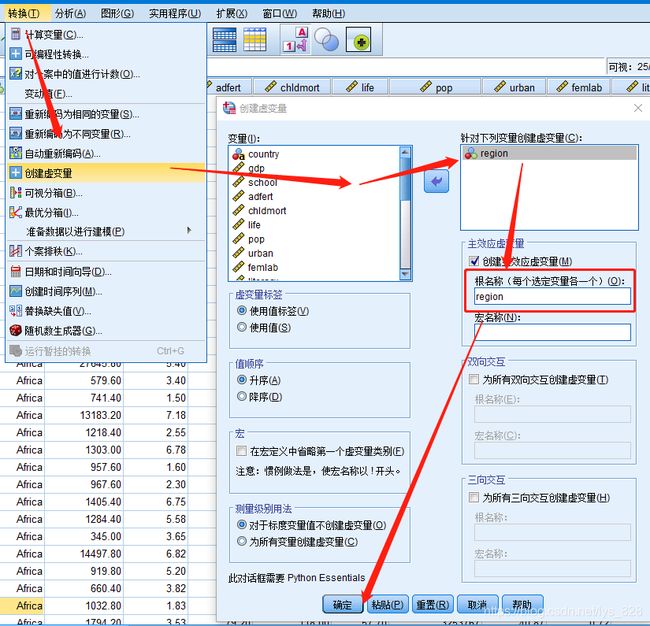
输出结果如下,对于哑变量,可以不删除一个,让系统进行逐步回归会自动筛选出想要的变量,也可以发现模型得分达到了0.593

然后再添加之前的四个变量进行回归分析,看一下模型效果,最后得分为0.89
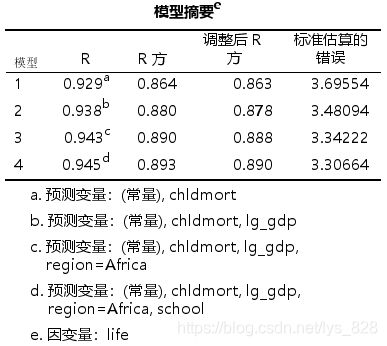
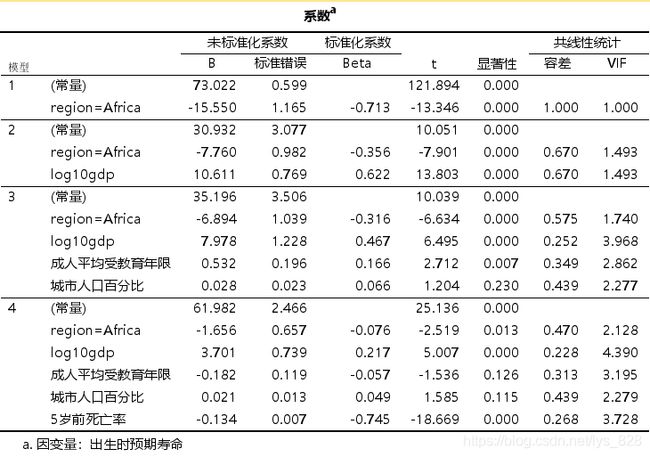
最后保留的变量为chldmort,lg_gdp,region=Africa和school,但是注意这里的school的p值为0.03,且标准化系数绝对值还没有超过0.1,说明即便是对因变量有影响也是有限的,况且是在临界值的边缘(如果删除这个变量,模型最后的得分为0.888,影响很小)

由上可知对于类别变量在传入模型之前一定要进行哑变量处理
6.5 曲线回归分析
就是对线性回归的补充,有些结果明显不是符合线性,因此就有了曲线回归分析的需求
案例32
对天猫双十一2009年-2019年的销售额进行回归分析
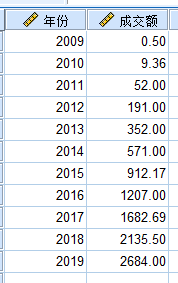
第一步就是查看散点图,看关系,可以明确不是线性关系了

SPSS进行曲线回归:【分析】→ 【回归】→ 【曲线估算】
如果变量是时间可以点选时间,下面的模型如果不确定数据会是什么样子,可以全部勾选(logistic需要指定一个上限)
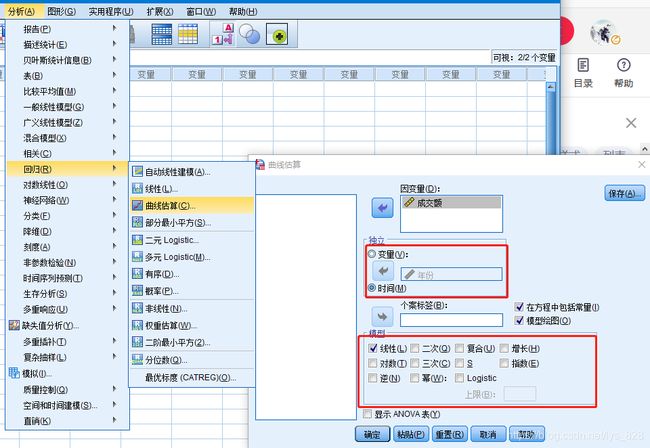
输出结果如下,可以发现二次和三次模型的拟合能力最好,并不是说是100%,这里保留的三位小数进行四舍五入了。
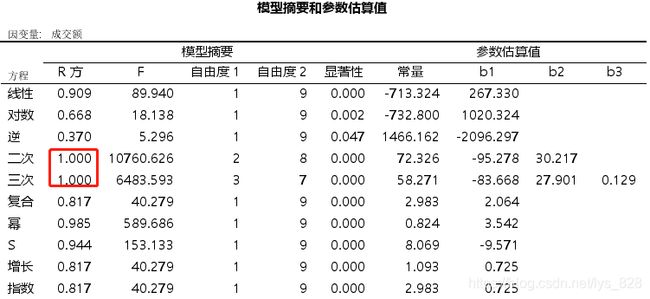
拟合曲线如下,可以发现当选定为“时间”后,x轴的标签就变成序列了

如果是时间变量反而不勾选“时间”,模型最后的得分会大幅度下降,而且拟合曲线也很奇怪,最后的结果输出如下
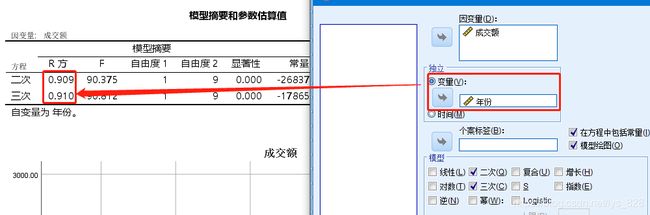
拟合曲线如下,时间变量标签会显示在x轴,但是拟合效果很差
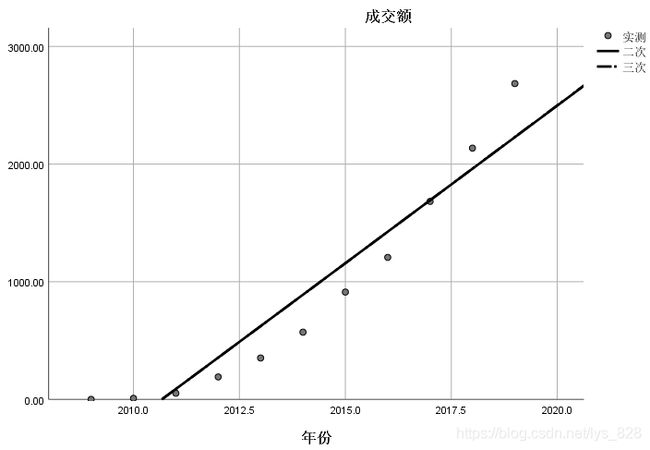
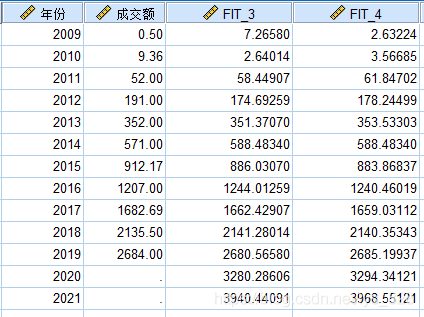
模型预测,选择最好的模型进行结果预测,比如预测2020和2021年双十一的交易额,注意对于时间变量要勾选“时间”,然后在“保存”里面勾选“预测值”,如果想要预测20和21年的,在预测范围那里可以手动输入数值,比如2009-2019是11年,预测范围可以输入13就可以了
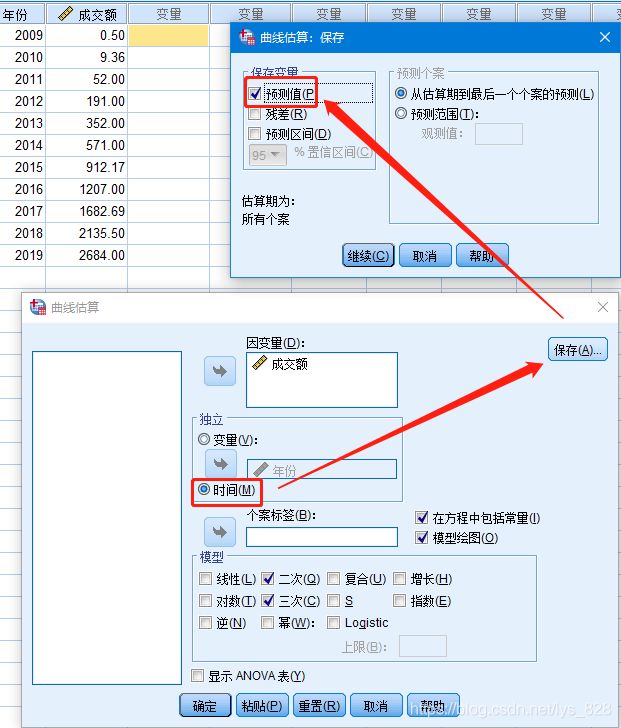
输出结果如下,这样就完成了曲线回归模型的创建和预测
6.6 层级回归分析
(1)是什么
分层回归也称层级回归、层次回归,首先要明确的是分层回归不是按照变量的水平分割后再进行回归,分层回归是对若干个自变量x进行分群组分析,主要用于模型的比较,或者说对变量重要性进行判定。分层回归可对两个或多个回归模型进行比较。可以根据两个模型所解释的变异量的差异来比较所建立的两个模型。一个模型解释了越多的变异,则它对数据的拟合就越好。假如在其它条件相等的情况下,一个模型比另一个模型解释了更多的变异,则这个模型是一个更好的模·型。两个模型所解释的变异量之间的差异可以用统计显著性来估计和检验。
(2)使用要求
模型比较可以用来评估预测变量对因变量的影响是否显著,检验一个预测变量是否显著的方法是比较两个模型,其中第一个模型不包含这个预测变量,而第二个模型包括该变量。假如该预测变量解释了显著的额外变异,那第二个模型就显著地解释了比第一个模型更多的变异。分层回归作为一种特殊的多元线性回归模型,进行分层回归时,仍然需要满足多元线性回归分析的假设条件(即需要进行回归诊断)
(3)怎么使用
案例33
还是以数据集记录的是世界范围内194个国家的经济,教育,文化等数据为例。要建立一个分层线性回归模型,其中因变量为life,自量4,第一层: region_1;第二层: log10gdp;第=层: urban, school, literacy;第四层: chldmort
之前已经分析过因变量与自变量之间的线性关系了,这里就直接开始整了,操作如下,在添加自变量框中依次添加各层自变量,添加完毕后点击“统计”,勾选下图所示框选内容,为了方便后面进行模型诊断,在“保存”按钮里面勾选“未标准化”残差
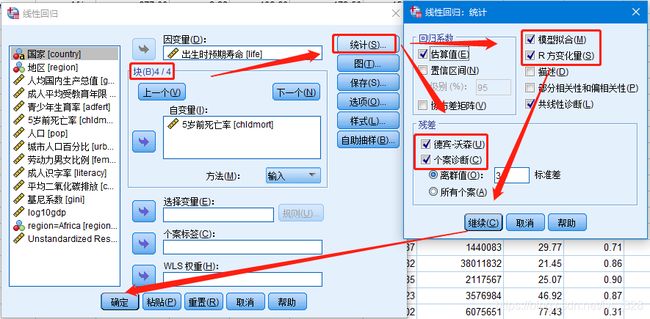
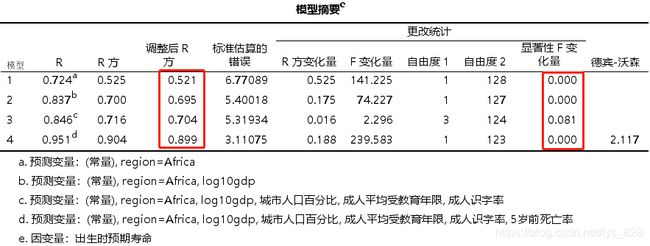
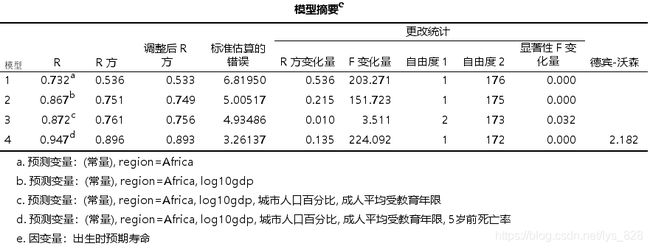
输出结果如下,按照四层,最后模型也就对应四个,这里要看一下调整后的R方,最后的p值也是来说明这每一层模型加入自变量对因变量的影响是否显著,由此可看第三个模型中加入的三个参数是不显著的,其余的模型均显著
然后就是各变量之间的标准化系数和共线性问题,由下表中可以看出有三个变量是不显著的,但是共线性统计中的容差都大于0.1且VIF都小于5,说明没有很强的共线性

可以尝试着去掉一下最高VIF或者最小容差对应的变量然后看一下最后模型的结果,也就是去掉成人识字率这个变量。首先发现第三个模型显著了,说明第三个模型中存在着共线性问题(成人识字率和成人平均受教育年龄是相关的)
然后就是看一下各变量的共线性情况如何,结果很惊讶,去掉一个共线性最强的变量后其余所有的变量均显著,说明对于共线性问题,剔除变量需要一个一个的来,不要全部剔除最开始不满足的三个变量

接着就是看一下个案诊断了,提示有四条数据是异常的

如果不进行处理,直接看一下残差的正态性(这里选用的是300条数据,属于小样本,看右边的结果,可以发现残差是不满足正态分布的)

然后看一下对应的QQ图,发现有四个点很突兀
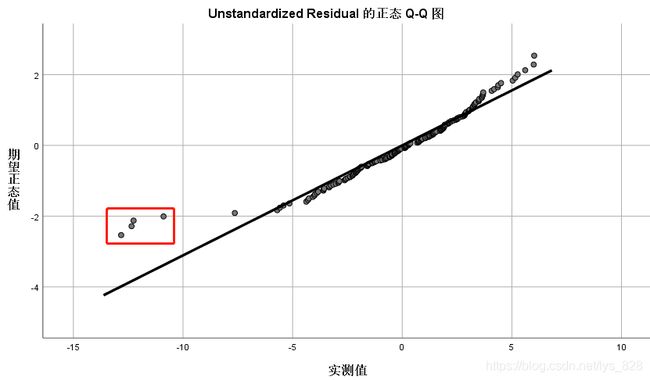
因此将异常点进行删除,也就是删除个案诊断里面提示的那四行数据(注意删除的时候要从后往前),然后重新生成模型,发现模型提高了不少,因此异常值的处理很重要

接着就是重新残差进行正态性检验,发现很完美的符合正态分布
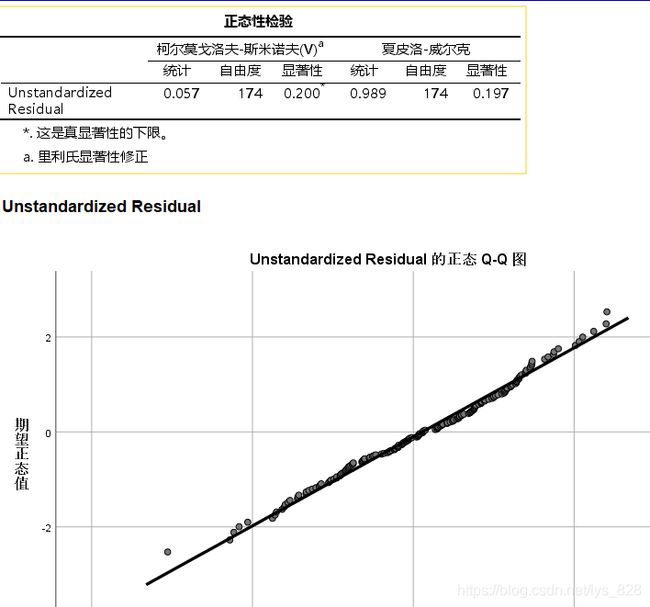
至此整个分层回归也就整理完毕,顺带解决了前面多元线性回归遗留的问题,输出模型对应的变量结果
(4)结果分析
将上面得到的结果整理成三线表,输出如下
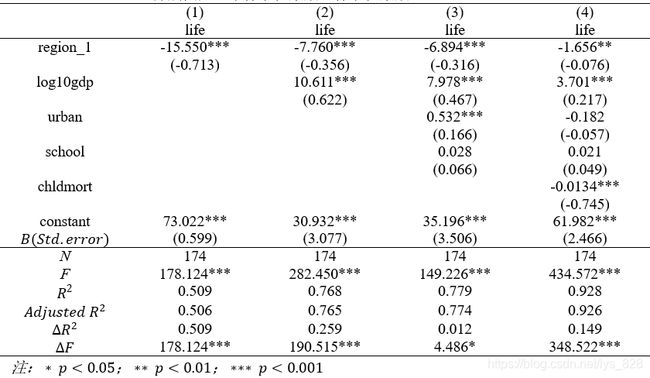
分层回归中的每个模型都相当于一个强制纳入变量的多重线性回归模型。
- R 2 R^{2} R2是多层回归的重要指标,反映自变量解释因变量变异的程度。右表中模型(1)-(4)的R2逐渐增加,分别是0.506, 0.768,0.779和0.928,提示各模型对因变量的预测能力逐渐加强。但是分层模型主要是检验增加的自变量是否具有统计学意义,如模型(2)增加了log10gdp变量是否具有统计学意义呢?
- △ R 2 △R^{2} △R2表示的是该模型与上一个模型 R 2 R^{2} R2的差值,结合 △ F △F △F及其统计检验的结果可以判断新增变量对回归模型是否有显著影响。如上表所示,模型(2)在模型(1)的基础上增加了变量log10gdp, △ R 2 = 0.259 △R^{2}=0.259 △R2=0.259,对应的 F = 190.515 F=190.515 F=190.515,且对应p < 0.001,说明log10gdp对因变量life有显著影响。
补充点:分层回归和逐步回归的区别和联系
- 两者都使用SPSS的【线性回归】菜单来完成分析。
- 逐步回归是让软件按照自变量重要性顺序,选择变量构建回归模型,如果软件一共发现3个有意义的自变量,则会构建3个模型,分别为 y ≈ x 1 , y ≈ x 1 + x 2 , y ≈ x 1 + x 2 + x 3 y≈x_{1}, y≈x_{1}+x_{2}, y≈x_{1}+x_{2}+x_{3} y≈x1,y≈x1+x2,y≈x1+x2+x3,其中变量重要性 x 1 > x 2 > x 3 x_{1}>x_{2}>x_{3} x1>x2>x3.
- 分层回归模型更需要理论和专业知识的指导,通常将专业上认为重,要的变量放在最后一层,以确定在控制其他变量之后,该自变量对因变量的影响大小。
- 逐步回归和分层回归都可以计算 △ R 2 △R^{2} △R2,逐步回归按照变量个数递增,建模并计算 △ R 2 △R^{2} △R2;而分层回归是按照层的数目递增建模并计算 △ R 2 △R^{2} △R2。
- 逐步回归更依赖软件,分层回归更依赖专业知识。逐步回归先重要变量后次要变量,分层回归先放入控制变量,后放入要研究的变量。
6.7 二分类逻辑回归
(1)是什么
二分类逻辑回归模型中因变量是二分类变量,自变量至少有1个,自变量可以是连续变量,也可以是分类变量。
(2)使用要求
二分类 + 数值/类别
(3)怎么使用
案例34
案例:数据集中存储了某银行850位客户的贷款信息,前700个案例是以前给予贷款的客户,这些客户的违约情况是已知的使用这700位客户的数据创建二项逻辑回归模型,希望借助二项逻辑回归模型找到那些可能贷款违约的人的特征,并使用这些特征来识别不良的贷款。同时借助得到的模型预测另外150名正在申请贷款的客户可能的违约情况。
二分类逻辑回归的统计学原理(通过案例说明)。
设银行贷款客户违约的概率为P, odds表示是违约发生的概率与不发生概率之比,即: o d d s = P 1 − P ( 1 ) odds =\frac{P}{1-P} \space\space\space\space(1) odds=1−PP (1)将公式(1)两边同时取对数 I n ( o d d s ) = I n ( P 1 − P ) = l o g i t ( P ) ( 2 ) In(odds) =In (\frac{P}{1-P})= logit(P) \space\space\space\space (2) In(odds)=In(1−PP)=logit(P) (2) 然后将 l o g i t ( P ) logit(P) logit(P)作为因变量,其它变量作为自变量,建立线性回归模型 l o g i t ( P ) = β 0 + β 1 x 1 + β 2 x 2 + . . + β k x k ( 3 ) logit(P) =\beta_{0}+\beta_{1}x_{1}+\beta_{2}x_{2} +..+\beta_{k}x_{k} \space\space\space\space (3) logit(P)=β0+β1x1+β2x2+..+βkxk (3)在得到模型(3)之后,我们将自变量的值带入到下方公式,可以得到违约的概率P P = e l o g i t ( P ) 1 + e l o g i t ( P ) = e β 0 + β 1 x 1 + β 2 x 2 + . . + β k x k 1 + e β 0 + β 1 x 1 + β 2 x 2 + . . + β k x k P = \frac{e^{logit(P)}}{1+e^{logit(P)}} = \frac{e^{\beta_{0}+\beta_{1}x_{1}+\beta_{2}x_{2} +..+\beta_{k}x_{k}}}{1+e^{\beta_{0}+\beta_{1}x_{1}+\beta_{2}x_{2} +..+\beta_{k}x_{k}}} P=1+elogit(P)elogit(P)=1+eβ0+β1x1+β2x2+..+βkxkeβ0+β1x1+β2x2+..+βkxk得到违约概率P之后,根据一个界限,比如将界限设置为0.5,如果P<0.5,表示该用户不会违约, P>0.5,则该用户会违约。
注意,此处的P和假设检验中的P值不是一个含义,注意区分。
通过上述的变换,将不能够直接建立模型的二分类因变量转换成连续变量就可以建立模型了,最后再通过变换,得到二分类的预测结果。
第一步因变量的确定(这个往往很容易确定,基本上就是研究目的),然后就是自变量的确定,这里需要花费一点时间
- 建立二分类Logistic回归模型之前,如果样本量不多而变量较多,应先通过单变量分析(检验、卡方检验等)考察所有自变量与因变量之间的关系,筛掉一些统计不显著的变量。
- 即使样本足够大,也不建议直接把所有的变量放入模型,要先弄清楚各自变量与因变量之间的相互关系,确定自变量进入方程的形式,这样才能有效的进行分析。
- 注意:二分类Logistic回归模型最小样本量要求为自变量数目的15倍,但一些研究者认为样本量应达到自变量数目的50倍。
- 建立二分类Logistic回归模型时建议纳入的变量:①单因素分析差异有统计学意义的变量(此时,最好将P值放宽一些,比如0.1或0.15等,避免漏掉一些重要因素) ;②单因素分析时,没有发现差异有统计学意义,但是专业上认为与因变量关系密切的自变量。
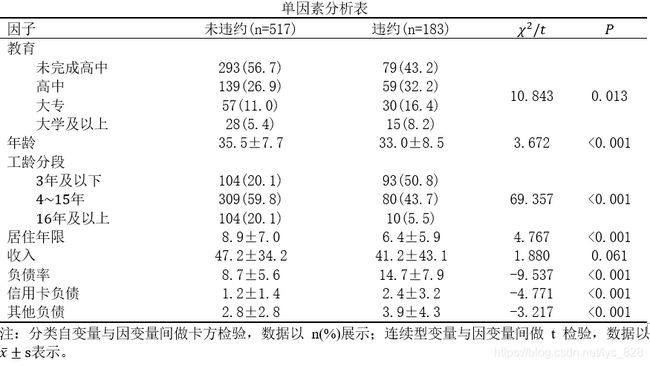
那么先进行数值变量和因变量之间独立样本T检验,输出结果如下

然后就是类别变量与因变量之间的关系,通过卡方检验
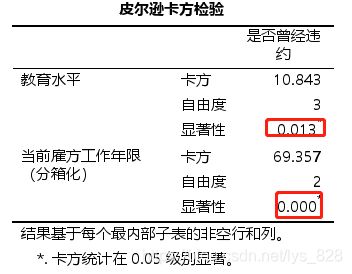
将变量筛选的情况以表格的形式展示,可以发现收入这个变量是统计不显著的,在建模的时候可以将其移除(不过这个p值接近0.05,也可以放入,最后通过逐步回归自动筛选)
第二步创建二元回归模型,操作如下。注意点有:
- 已经对工龄进行分箱了,那数值变量就不用田间了
- 这里方面向前:LR(就是逐步回归方法)
- 要点击“分类”按钮进行分类变量的转化,要指定一下是以最后一个还是第一个,会自动进行哑变量处理,处理完了之后会在变量的后面多一个(Cat)的标识
- “选项”按钮中调出模型的拟合优度和OR值
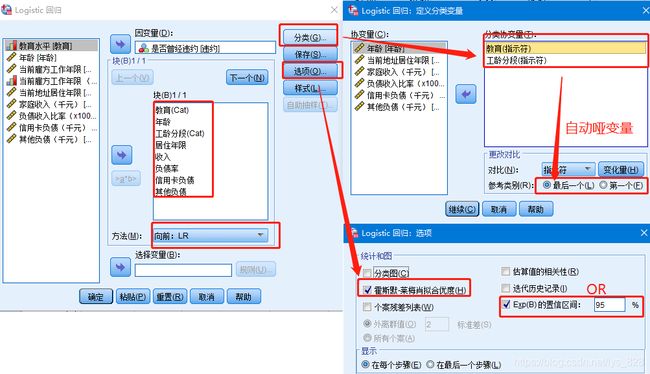
输出结果如下
-
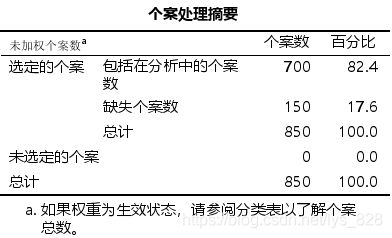
表格【个案处理摘要】展现了缺失值检查的结果。
-
表格【因变量编码】给出的因变量的编码情况。

-
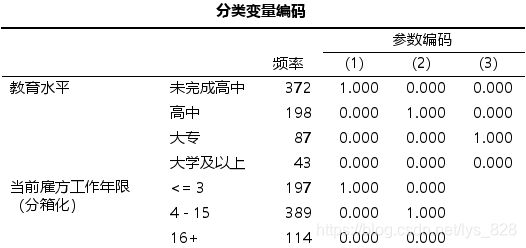
表格【分类变量编码】给出的是自变量中分类变量的编码情况。要注意观察分类自变量是否存在某一类观测数过少的情况,如果某项分类较少,可能不利于二项Logistic回归分析。
-
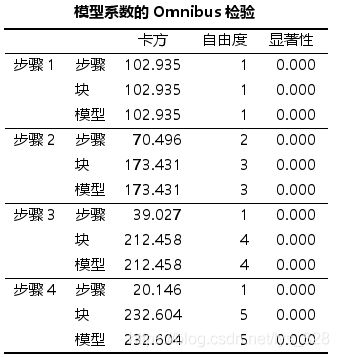
表格【模型系数的Omnibus检验】是模型系数的综合检验。其中模型一行输出了Logistic回归模型中所有参数是否均为0的似然比检·验结果。如果P< 0.05,则表示本次拟合的模型中,纳入模型的变量中至少有一个变量的OR值有统计学意义,即模型总体有意义。
-
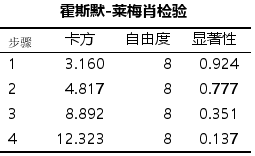
表格【霍斯默-莱梅肖检验】是模型拟合优度的检验结果。当P>0.05时,认为当前数据中的信息已经被充分提取,模型拟合优度较高。
-
表格【模型摘要】提供了因变量的变异能够被拟合的模型解释的比例。该表格包含Cox & Snell R Square和Nagelkerke R Square,这两种 R 2 R^{2} R2有时被称为伪 R 2 R^{2} R2 ,在Logistic回归中意义不大。

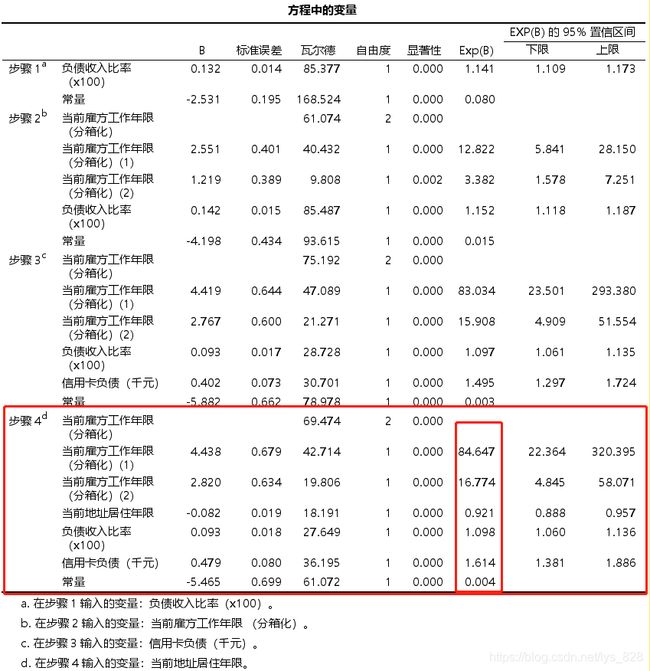
表格【方程中的变量】列出了所有自变量及其参数估计结果。本案例中筛选变量的方式是向前: LR法,
- 显著性一列表示相应自变量在模型中的P值。
- Exp(B)一列表示相应变量的OR值。
- ① 对于多分类变量工龄分段,本案例中设置以"3"组作为参照,则得到的结果是"1"组、"2"组分别对应于“3"组的OR值。OR值的含义为:相对于参照组,当前组对象发生结局的风险是多少倍。在Logistic回归中,设置过哑变量的多分类变量是同进同出的,即只要有一哑变量有统计学意义,则该变量的全部分组均纳入模型。.
- ②对于连续变量, OR值的含义为:自变量每增加一个单位发生结局的风险增加的倍数。
- ③注意,对于编码为0/1形式的二分类变量而言, OR值的含义为:相对于赋值较低的研究对象,赋值较高的研究对象发生违约的风险为是多少。
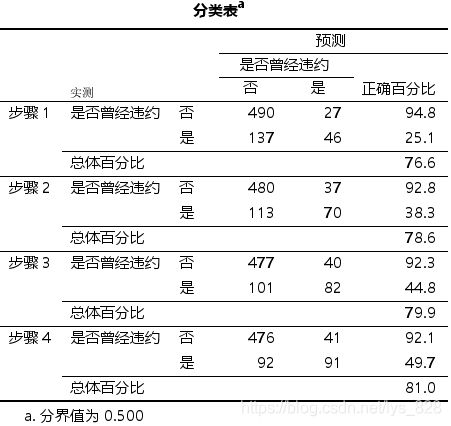
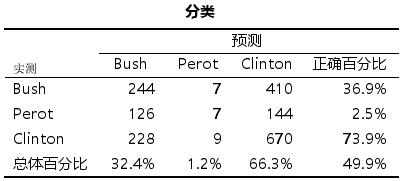
表格【分类表】给出Logistic回归模型的预测结果,这种表格也被成为混淆矩阵,可基于该分类表计算出如下几个评估分类模型分类性能的指标。
- 正确率=正确预测的正反例数/总数
- 误分类率=错误预测的正反例数/总数
- 覆盖率(Sensitivity)=正确预测到的正例数/实际正例总数
- 负例的覆盖率(Specificity)=正确预测到的负例个数/实际负例总数
- 命中率=正确预测到的正例数/预测正例总数
- 负例的命中率=正确预测到的负例个数/预测负例总数
(4)结果分析
将结果整理成三线表的形式输出如下,对于分类变量注意给出对比的基准,比如这里当时选择的是最后一个变量,也就是16年及以上
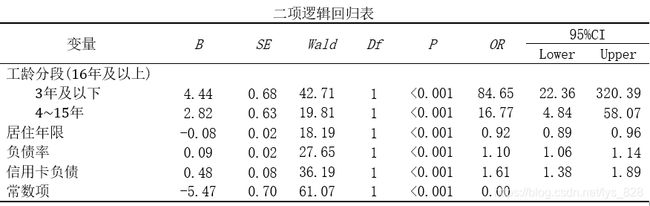
工龄在3年及一下贷款的风险工龄在16年及以上的84.65倍,而工年在4-15年工龄的这一数值是在16.77倍
居住年限每增加一个单位,增加违约的风险就增减0.92倍,相当于随着居住年限的增加,违约的概率就越低
负责率每增加一个单位,违约增加的风险就是原来的1.10倍,也就是负责率越高,违约的概率越大
对于二分类的变量这里的解释,可以认为相较于编码为0的研究对象,编码为1的研究对象发生违约的风险是xxx
核心重点:ROC曲线
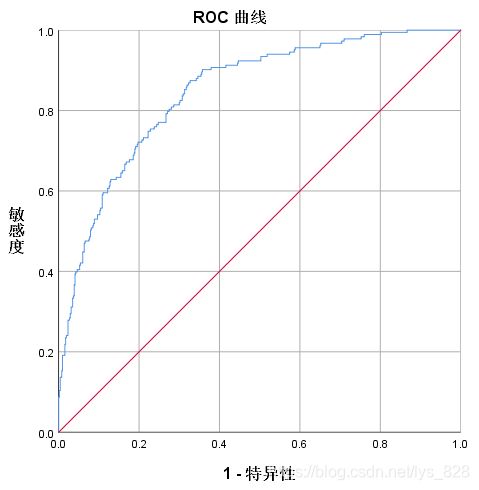
- Receiver Operating Characteristic Curve,中文叫“接受者操作特性曲线”。横轴是1-Specificity,纵轴是Sensitivity,随着分类的概率阈值的减小(更多的客户就会被归为正例,标签为1) , Sensitivity和1-Specificity也相应增加(也即Specificity相应减少) ,所以ROC呈递增态势, 45度线作为参照(baseline model) ,就是说, ROC的好坏,乃是跟45度线相比的。
- ROC曲线是根据与45度线的偏离来判断模型好坏。图示的好处是直观,不足就是不够精确。到底好在哪里,好了多少?这就要涉及另一个术语, AUC(Area Under the ROC Curve, ROC曲线下的面积), AUC是ROC的一个派生。
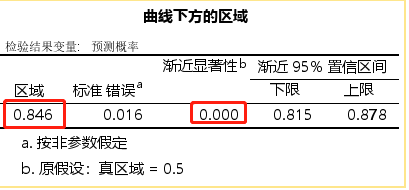
- ROC曲线图。45度线下的面积是0.5, ROC曲线与它偏离越大, ROC曲线就越向左上方靠拢,它下面的面积(AUC)也就应该越大。我们就可以根据AUC的值与0.5相比,来评估一个分类模型的预测效果。一般AUC大于0.8,模型效果较好。
在SPSS中操作如下:【求解概率】→ 【分析】→ 【分类】→ 【ROC曲线】
首先求解概率,这里就是基于上面的过程,在保存的时候可以勾选一下预测值和组成员,最后会输出两列,一列就是对应的概率值,另一列就是根据这个概率划分的结果
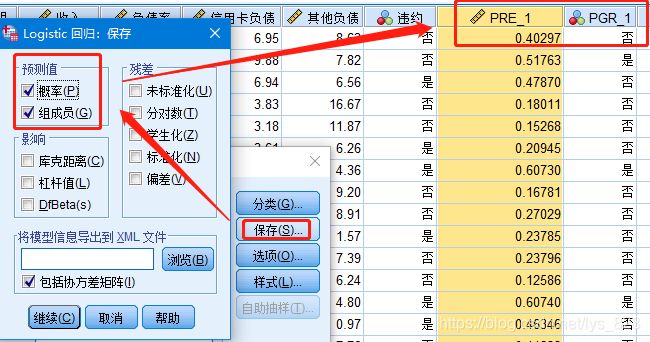
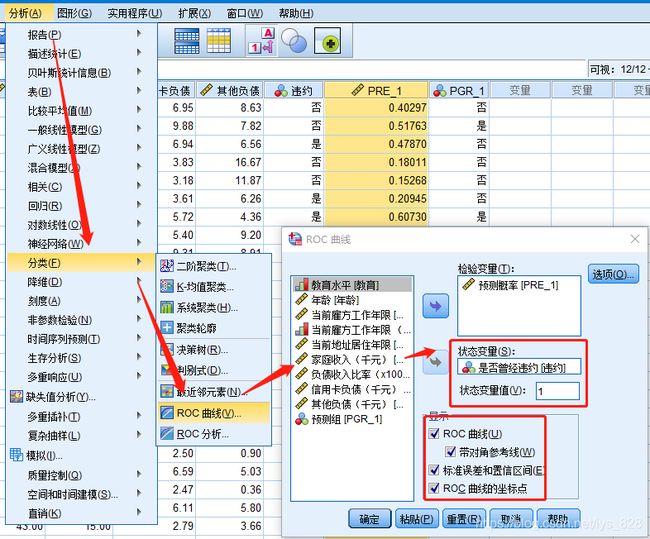
有了预测的概率值后就可以进行ROC曲线的绘制,操作如下,将因变量放在状态变量的选框中,然后下面的状态变量值一般写1(代表着事件发生),然后下面的都可以勾选
ROC曲线输出结果如下
对应曲线的面积
6.8 无序多分类逻辑回归
(1)是什么
无序多分类的Logistic回归模型用于分析因变量为无序多分类的情况;除此之外,如果因变量为有序分类,但平行线检验P<0.05,也应该用无序多分类的Logistic回归分析。
(2)使用要求
类别变量(无序) + 数值/类别
(3)怎么使用
案例35
数据集记录的是美国总统大选中对民众投票倾向的抽样调查结果。总统候选人(pres92)共有3位:Perot. Clinton, Bush,数据集中记录的其它变量包括age.agecat, educ. degree, sex,请根据数据建立以pres92为因变量,其它对候选人选择有影响的变量为自变量的多项逻辑回归模型。
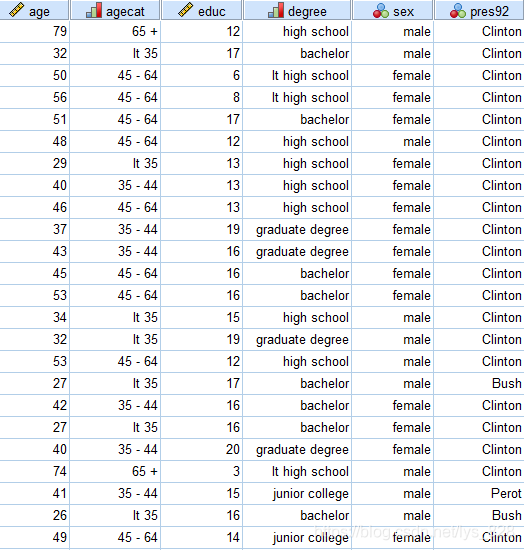
分析步骤:
- 先进行单因素分析初步筛选变量
- 然后再建立多项逻辑回归模型,并优化模型
- 最后使用所得到的模型进行预测,或解释自变量如何影响对因变量。
第一步筛选变量,还是先看数值变量和因变量之间的关系,由于因变量是多分类,这里应该选择单因素方差分析,可以发现和受教育年龄之间的关系不显著

然后通过卡方检验测试类别变量,输出结果如下,全部都是显著结果
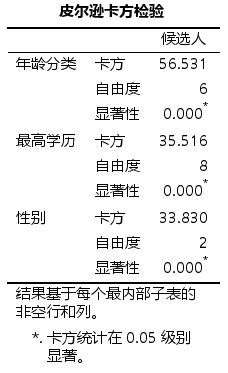
第二步就是进行多元回归模型创建,操作如下。在因变量中可以自己指定参考的值,然后分类变量和连续变量分开放,可以点击“模型”和“统计”按钮进行相关输出的设置

输出结果如下
- 表格【个案处理摘要】:给出的是各分类变量的频数。
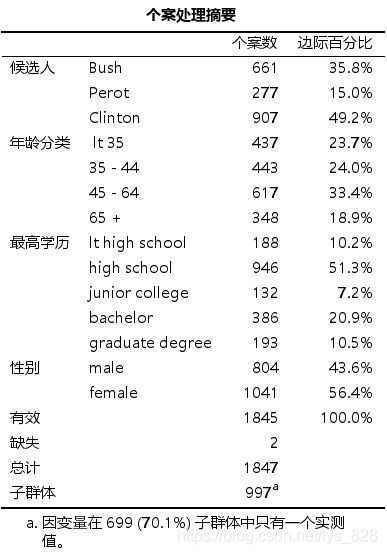
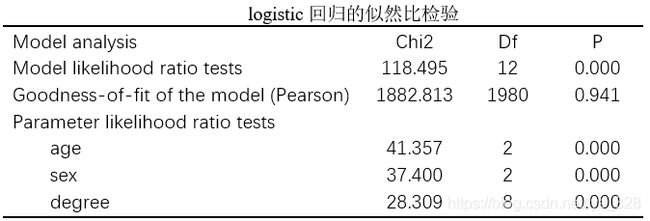
- 表格【模型拟合信息】 :给出的是模型拟合好坏的信息, − 2 L o g L i k e l i h o o d -2Log Likelihood −2LogLikelihood值越小越好,从结果中可以看出加入自变量的模型比只有常数项的模型拟合要好(2600<2718) ,似然比检验(Likelihood Ratio Tests)结果显示这种模型的改善是有统计学意义的(P< 0.001) ,说明模型整体有统计学意义的。
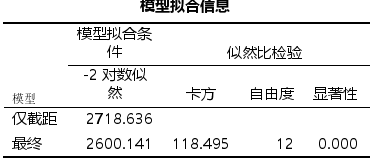
- 表格【拟合优度】 :给出了模型拟合优度检验的结果(原假设:模型与数据完全吻合) 。如果显著性值很小" (P<0.05) ,则认为当前数据中的信息未能被充分提取,模型拟合优度很差。此处P= 0.760 > 0.05,认为当前数据中的信息已经被充分提取,模型拟合优度较高。
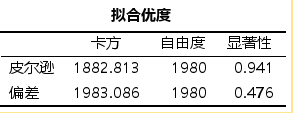
- 表格【伪R方】 :逻辑回归模型中R方值一般都不会太高,不用关注。

- 表格【似然比检验】 :检验了每个效应对模型的贡献。剔除某个效应,对简化模型计算-2Log Likelihood, 卡方统计量是此简化模型与最终模型之间的差异,如果检验的显著性很小(P< 0.05) ,则该效应有助于模型,应当保留在模型中。

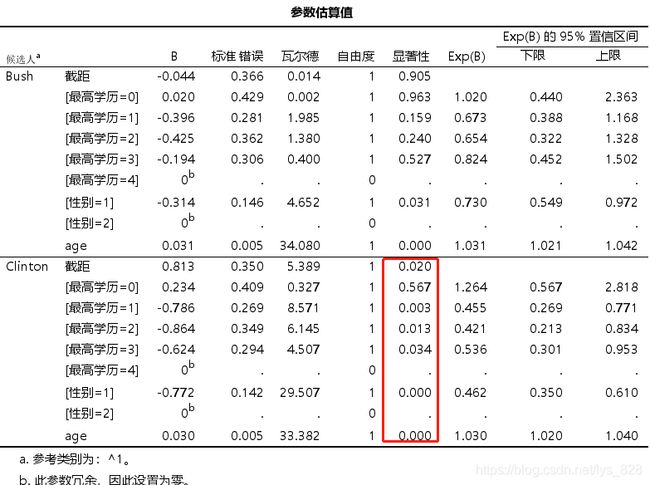
- 表格【参数估算值】给出了参数估计值,系数(B)与其标准误差(SE) 平方的比值等于Wald统计量,如果Wald统计量的显著性水平很小(P<0.05) ,则相应的参数值显著不为0,说明对应的自变量有统计学意义。
- 表格【分类】,对出模型最后预测的百分比交叉表结果
(4)结果分析
将上面的结果整理成三线表的形式如下,先要给出模型整体的检验结果
然后给出对应的变量结果

系数表解析:(具有显著负系数的参数降低了响应类别相对于参考类别的可能性,正系数的参数增加了响应分类的可能性)
- 连续变量:age每增加一个单位,其投票给Clinton的可能性增加1.03倍。
- 二分类变量:sex=1相比于sex=2, Exp(B)为0.462,说明相对于女性(sex=2) ,男性(sex=1)投票给Clinton的可能性为0.462倍,将0.462取倒数即为相对于男性(sex=1)女性(sex=2)投票给Clinton的可能性为1/0.462=2.16倍,对应的P<0.001,说明差异有统计学意义。
- 多分类变量:相对于degree=4的组, degree=1的组对应的Exp(B)为0.455,说明相对于研究生学历(4, graduate degree)的人而言,高中学历(1, high school)的人投票给Clinton的可能性为0.455倍,对应的P= 0.003<0.05,说明差异有统计学意义。
6.9 有序多分类逻辑回归
(1)是什么
研究中会遇到因变量为有序多分类的情况,如城市综合竞争力等级可以划分为高、中、低;人们对某个节目的喜爱程度可粗略划分为·非常不喜欢、不喜欢、一般,喜欢,非常喜欢;某病的治疗效果分为痊愈、有效、好转、无效等等。有序多分类的Logistic回归模型就适用于这种因变量为有序多分类的情况。
注意:这种模型实际上是依次将因变量按不同的取值水平分割成两个等级,对这两个等级建立因变量为二分类的Logistic回归模型。但不管模型中因变量的分割点在什么位置,模型中各自变量的系数都保持不变,所改变的只是常数项a。模型中各自变量的偏回归系数始终保持不变,这是拟合累积Logit模型的前提条件之一。在随后的建模的步骤中,会对整个模型进行**【平行线检验】** ,以确定是否满足该条件。如果该条件不满足,则应该拟合无序多分类逻辑回归模型
(2)使用要求
多分类变量(有序) + 数值/类别
(3)怎么使用
案例36
调查大学生群体对【大学学到的知识对我的未来很有价值】这一描述的认同程度,可能的影响因素有性别、就读大学类型、文理科、自我评价、对自己大学教育质量评价、对国内大学整体水平评价这样6个变量。尝试建立有序多分类逻辑回归模型对该数据进行分析。

第一步还是老一样,进行因变量和自变量之间的关系探究,数值型变量探究如下,结果均显著(这里不管是否呈现正态分布,只是探究一下是否显著影响)
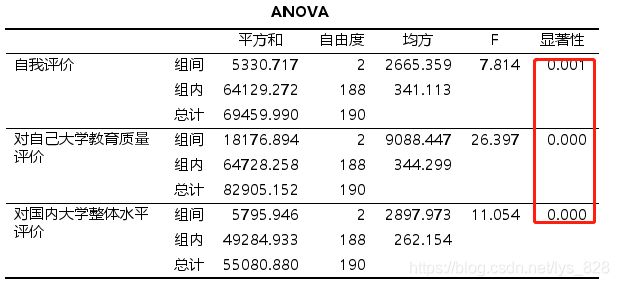
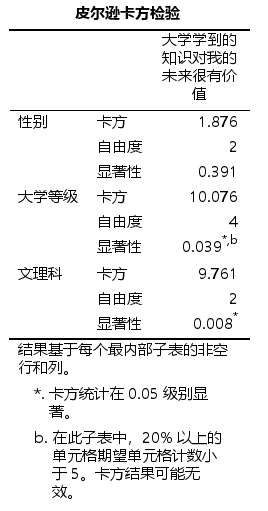
然后看一下类别变量卡方检验,结果也都是统计显著的
第二步就是进行有序回归模型的创建了,基本上和前面的无序多分类的创建过程一致,这里主要注意要勾选平行线检验

输出结果如下
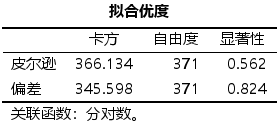
- 表格【平行线检验】给出的是平行线检验的结果,该检验的原假设是: 2个二元Logistic回归模型自变量系数相等,此处P= 0.634,不拒绝原假设,可以认为原假设成立,可以使用多重有序Logistic回归。如果此处P<0.05,则应该建立无序多分类多级回归模型。

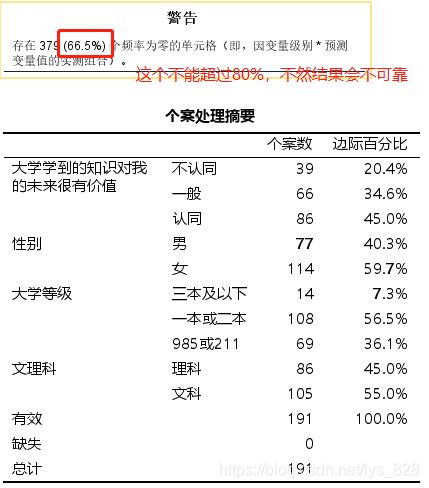
- 表格【个案处理摘要】给出的是参与建模的分类变量的频数。
- 表格【模型拟合信息】给出了整个模型似然比检验结果。该检验的原假设是:纳入的所有自变量系数为0,此处P<0.001,拒绝原假设,说明至少一个变量系数不为0,具有统计学显著性,也就是模型整体有意义。

- 表格【拟合优度】给出了拟合优度检验的结果,如果P<0.05,则认为当前数据中的信息未能被充分提取,模型拟合优度很差。此处p= 0.724 > 0.05 (Pearson) ,认为当前数据中的信息已经被充分提取,模型拟合优度较高。
- 表格【伪R方】给出是模型的R方。

- 表格【参数估算值】给出的是参数估计的结果。
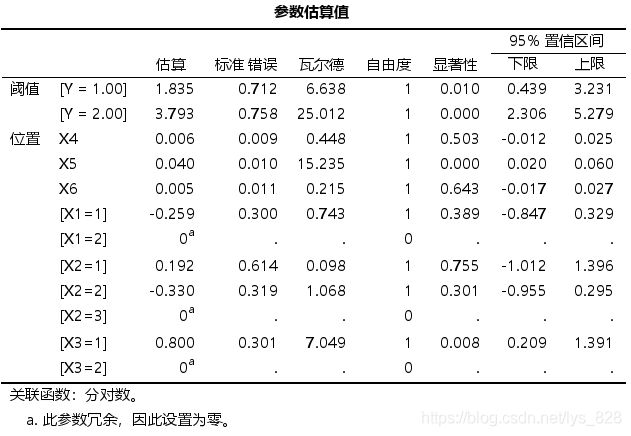
- 阈值(Threshold) 中, Y=1和2对应的两个估计值分别是这个有序逻辑回归模型中拆分出的两个二元Logistic回归模型的常数项。
- 位置(Location) 中 X 5 X_{5} X5和 X 3 = 1 X_{3}=1 X3=1对应估计值为自变量的系数估计值。其中X3为二分类变量,在分析中被拆分成了2个哑变量( X 3 X_{3} X3取值1、2, X 3 X_{3} X3=2作为比较基准) 。
- 有序多分类Logistic回归模型假定拆分的多个二元逻辑回归模型中自变量系数均相等,因此结果只给出了一组自变量系数。
- X 5 X_{5} X5的系数估计值为0.040意味着在保持其它变量不变的情况下, X 5 X_{5} X5的数值每提高一个单位, Y取值至少高一个等级的可能性是exp(0.040) = 1.04倍(转化为OR值)。
- X 3 = 1 X_{3} = 1 X3=1的系数估计值为0.800意味着在保持其它变量不变的情况下,相比于 X 3 = 2 X_{3} = 2 X3=2(文科)的组, X 3 = 1 X_{3} = 1 X3=1(理科)的组的Y取值至少高一个等级可能性是exp(0.800) =2.23倍。
(4)结果分析
将上面的结果梳理成为三线表形式如下,先给出模型整体的检验结果

再给出最后的参数估算表,分析上面已经完成了,这里就不再赘述了

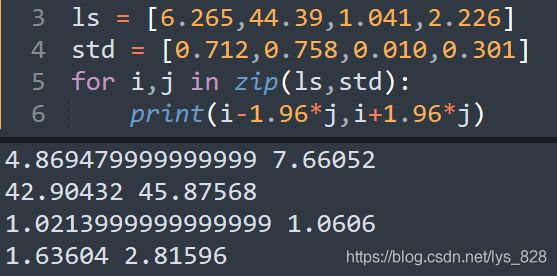
最后的输出结果是没有OR值的因此,需要自己计算,公式为 O R ± 1.96 × s e OR±1.96×se OR±1.96×se,变个小程序运行一下,结果就出来了,如下。至此全部梳理完毕
终于完结了,撒花✿✿ヽ(°▽°)ノ✿,以上内容作为SPSS内容学习的梳理,如果发现有问题,欢迎大家批评指正只有自己亲自都运行一遍,才发现对这些知识的了解又近了一步,而且感觉离发文章也越来越近了,加油~~~
最后的最后,纪念一下和这个时刻,从来没有写过这么多字,这一次梳理知识点竟达到了9w5+字,肝到深夜,望付出总有收获,啦啦啦~~~
![]()