近日,百度强化学习团队发布了四足机器人控制上的最新研究进展,采用自进化的步态生成器与强化学习联合训练,从零开始学习并掌握多种运动步态,一套算法解决包括独木桥、跳隔板、钻洞穴等多种场景控制难题。百度已开源全部仿真环境和训练代码,并公开相关论文。
 .mp4)
.mp4)
▲ 完整仿真效果和真机视频
足式机器人的控制一直是机器人控制领域的研究热点,因为相比于常见的轮式机器人,足式机器人可以像人类一样灵活地跨越障碍,极大地扩展机器人的活动边界。波士顿动力(Boston Dynamics)此前对外发布了其商用的第一款四足机器人 Spot,但是相关的控制算法一直没有对外披露。而市面上商业产品采用的控制算法,大部分基于麻省理工学院(MIT)开源的第三代的四足控制算法,需要依赖大量专家经验。
近日,百度强化学习团队联合小度机器人团队,基于飞桨机器人控制算法框架 PaddleRobotics,发布了四足机器人控制的最新进展。该算法首次提出基于自进化的步态生成器来引导强化学习训练,通过自主学习,机器人能探索出合理的步态并穿越各种各样的高难度场景。
这个算法到底有多厉害,先来一睹为快。
\
▲ 图一、四足机器人步态展示
注:演示真机为宇树四足机器人产品
我们可以看到,图中四足机器人无论是走独木桥,还是上下楼梯,都走的十分稳健。特别是在独木板场景,机器人学会了先把双腿步距缩小,以小碎步的方式平稳地穿过了独木板。这些步态都是基于强化学习自主学习得到,并没有通过任何的领域内专家知识进行引导。那么这些行走步态是如何训练出来的呢?
在解读之前,我们先回顾下当下三种主流的四足控制算法。
第一个方向是开环的步态生成器,即提前规划好每条腿的行走轨迹,然后周期性地输出控制信号以驱动机器人行走起来。这种方式可以让专家根据经验以及实际环境去设计四足机器人的行走方式,但是缺点是往往需要大量的调试时间以及领域内的专家知识。
第二个方向是基于模型预测的控制算法(MPC),这类方法也是 MIT 之前开源的主要算法。算法对环境进行建模后,在每个时间步求解优化问题以找到最优的控制信号。这类方法的问题是其效果依赖于环境模型的建模准确度,并且在实际部署过程中需要耗费比较大的算力去求解最优的控制信号。
第三个方向是基于学习的控制算法。前面提到的方法都是提前设计好控制器直接部署到机器人上的,并没有体现出机器人自主学习的过程。这个方向的大部分工作是基于机器自主学习,通过收集机器人在环境中的表现数据,调整机器学习模型中的参数,以更好地控制四足机器人完成任务。
百度这次发布的工作是基于强化学习的控制算法。强化学习应用在四足机器人领域并不是新的技术,但是之前发表的强化学习工作大部分都只能穿越一些比较简单的场景,在高难度的场景,比如通过独木板、跳隔板中,表现并不好。主要的原因是四足机器人中复杂的非线性控制系统使得强化学习探索起来十分困难,机器人经常还没走几步就摔倒了,很难从零开始学习到有效的步态。为了解决强化学习在四足控制上遇到的问题,百度团队首次提出基于自进化步态生成器的强化学习框架。
 \
\
▲ 图二、ETG-RL 架构
该框架的概览图如上图,算法的控制信号由两部分组成:一个开环的步态生成器以及基于强化学习的神经网络。步态生成器可以提供步态先验来引导强化学习进行训练。以往的工作一般采用一个固定的步态生成器,这种方式只能生成一种固定的步态,没法针对环境进行特定的适配。特别是当预置的生成器并不适合环境的情况下,反而会影响强化学习部分的学习效果。
针对这些问题,百度首次提出在轨迹空间直接进行搜索的自进化步态生成器优化方式。
相比在参数空间进行搜索的方式,它可以更高效地搜索到合理的轨迹,因为在参数层面进行扰动很可能生成完全不合理的轨迹,并且搜索的参数量也大很多。强化学习部分的训练通过目前主流的 SAC 连续控制算法进行参数更新,在优化过程中,强化学习的策略网络需要输出合理的控制信号去结合开环的控制信号,以获得更高的奖励。需要注意的是,该框架在更新过程中,是采用交替训练的方式,即独立更新步态生成器以及神经网络。这主要的原因是其中一个模块的更新会导致机器人的行为发布发生变化,不利于训练的稳定性。最后,为了提升样本的有效利用率,该框架还复用了进化算法在优化步态生成器的数据,将其添加到强化学习的训练数据中。
 \
\
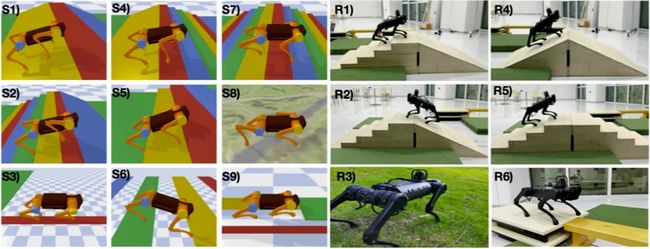
▲ 图三、实验场景(仿真+真机)
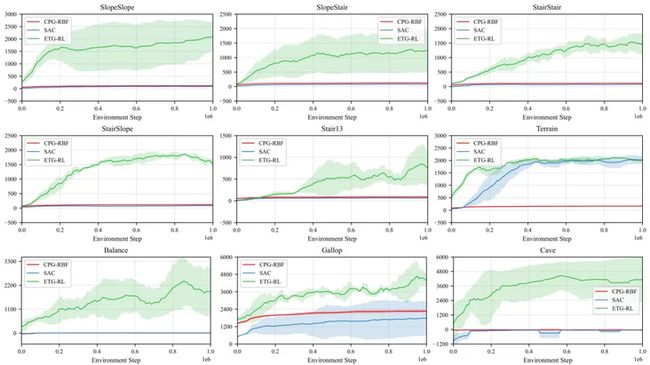
接下来看文章中的实验部分。如上图所示,百度基于开源的 pybullet 构建了9个实验场景,包括了上下楼梯、斜坡、穿越不规整地形、独木板、洞穴、跳跃隔板等场景。其算法效果与经典的开环控制器、强化学习算法相比,提升相当大。可以看到百度提出的框架(绿色曲线)遥遥领先于别的算法,并且是唯一一个能完成所有任务的算法。完整的仿真效果以及真机视频可以参考文章开头。
 \
\
▲ 图四、实验结果
百度的工作展现出,基于自主学习的方法在四足机器人控制上具有完全替代甚至超越经典算法的潜力,有可能成为强化学习和进化学习在复杂非线性系统中开始大规模落地和实用化的契机。
这不是百度在机器人方向上做的第一个强化学习工作,早在18年,他们就尝试将人工干预引入到强化学习中,以推进强化学习应用在在四轴飞行器控制等高风险的硬件场景。未来,相信强化学习会是四足机器人控制领域重要的技术突破口,有效推动足形态机器人走进我们的日常生活中。
该模型和训练方法同步开源于飞桨机器人算法库 PaddleRobotics 和强化学习框架 PARL;其中四足机器人和复杂地形仿真也开放于飞桨强化学习环境集 RLSchool, 以便于更多该领域的专家和工程师对比研究。
论文: https://arxiv.org/abs/2109.06409
强化学习框架 PARL:https://github.com/PaddlePadd...
开源仿真环境 RLSchool:https://github.com/PaddlePadd...
飞桨机器人控制算法框架 PaddleRobotics:https://github.com/PaddlePadd...
点击“此处”,了解更多信息~
百度AI开发者社区https://ai.baidu.com/forum ,为全国各地开发者提供一个交流、分享、答疑解惑的平台,让开发者在研发路上不再“孤军奋战”,通过不断地交流与探讨找出更好的技术解决方案。如果你想尝试各种人工智能技术、开拓应用场景,赶快加入百度AI社区,你对 AI 的所有畅想,在这里都可以实现!