基于文字情感的民族音乐智能生成项目Bert+Magenta【音乐生成部分】(一)
magenta环境配置与应用
- 环境配置
-
- 1.安装pycharm
- 2.安装pip
- 3.安装conda
- 4.创建conda虚拟环境
- magenta安装
- magenta的使用
-
- 1.数据集准备
- 2. 数据转换
- 3. 将NoteSequences文件中的旋律提取出来
- 4.训练和验证过程
-
- i. 训练过程
- ii. 验证过程
- 5. 音乐生成
项目源码及数据集:
https://github.com/DreamShibei/ChineseMusicGenerator
其他模块:
基于文字情感的民族音乐智能生成项目Bert+Magenta----文本情感部分
基于文字情感的民族音乐智能生成项目Bert+Magenta【音乐生成部分】(二)
环境配置
使用ubuntu18.04系统
1.安装pycharm
参考Ubuntu 18.04 安装 PyCharm
2.安装pip
sudo apt install python-pip
出现报错E: Unable to locate package python-pip
解决方法:更新软件源
在更改配置文件时保存报错
"/etc/apt/sources.list" E212: Can't open file for writing
解决方法:w !sudo tee % > /dev/null
3.安装conda
参考Ubuntu 16.04系统下conda的安装与使用
wget -c https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
chmod 777 Miniconda3-latest-Linux-x86_64.sh
sh Miniconda3-latest-Linux-x86_64.sh
4.创建conda虚拟环境
创建环境
conda create -n magenta python=3.6
激活环境
source activate magenta
magenta安装
在github官网上下载magenta全部代码,使用pycharm打开
创建conda虚拟环境
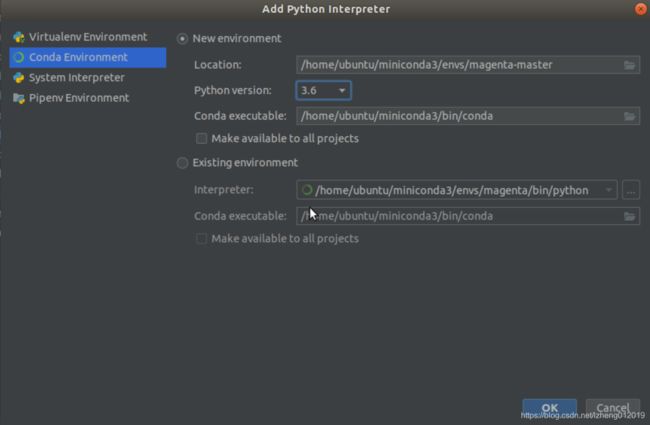
根据提示安装配置库
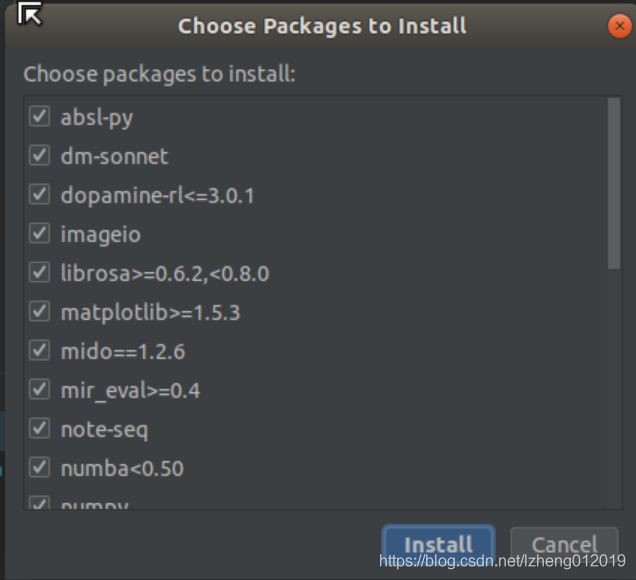
在安装时出现报错

不知道为啥在pycharm里安不上
那就去命令行里安吧
pip install magenta
又有奇怪的报错
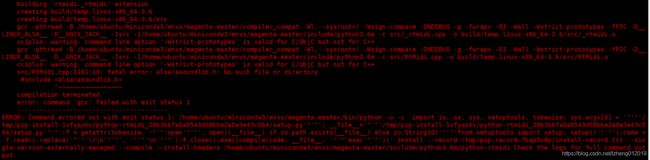
需要安装配置库
sudo apt-get install build-essential libasound2-dev libjack-dev
sudo apt-get update
再重新输入pip install magenta
就好了

magenta的使用
1.数据集准备
数据集使用midi格式

2. 数据转换
将包含MIDI音乐集的文件夹转化成NoteSequences。该音乐序列文件保存为TFRecord格式。
convert_dir_to_note_sequences.py \
--input_dir= home/ubuntu/Downloads/1-1 \
--output_file=/home/ubuntu/melody/notesequences.tfrecord \
--recursive


3. 将NoteSequences文件中的旋律提取出来
调用melody_rnn_pipeline.py中的get_pipeline(config, transposition_range=(0,), eval_ratio=0.0)函数返回pipeline实例,通过pipeline进行数据集之间的转换,将一个tfrecord文件划分为训练集和评估集。
melody_rnn_create_dataset \
--config=attention_rnn \
--input=/home/ubuntu/melody/notesequences.tfrecord \
--output_dir=/home/ubuntu/melody/sequence_examples \
--eval_ratio=0.10

提取旋律后所生成的文件

4.训练和验证过程
i. 训练过程
melody_rnn_train.py \
--config=attention_rnn \
--run_dir=/ home/ubuntu/melody /logdir/run1 \
--sequence_example_file=/ home/ubuntu/melody /sequence_examples/training_melodies.tfrecord \
--hparams="batch_size=64,rnn_layer_sizes=[64,64]" \
--num_training_steps=20000
开始训练

训练到一半被系统kill了 可能是由于虚拟机内存不够,最好在初始创建时选择大一点的虚拟机

ii. 验证过程
也使用melody_rnn_train.py。不同的是,在运行验证程序时,我们需要把eval写为True,bool格式;同时,sequence_example_file为验证集,即eval_melodies.tfrecord的路径
melody_rnn_train.py \
--config=attention_rnn \
--run_dir=/ home/ubuntu/melody/logdir/run1 \
--sequence_example_file=/ home/ubuntu/melody /sequence_examples/eval_melodies.tfrecord \
--hparams="batch_size=64,rnn_layer_sizes=[64,64]" \
--num_training_steps=20000 \
--eval
在验证过程中有奇怪的报错还没解决

5. 音乐生成
melody_rnn_generate.py \
--config=attention_rnn \
--run_dir=/home/ubuntu/melody /logdir/run1 \
--output_dir=/home/ubuntu/melody /generated \
--num_outputs=10 \
--num_steps=128 \
--hparams="batch_size=64,rnn_layer_sizes=[64,64]" \
--primer_melody="[60]"
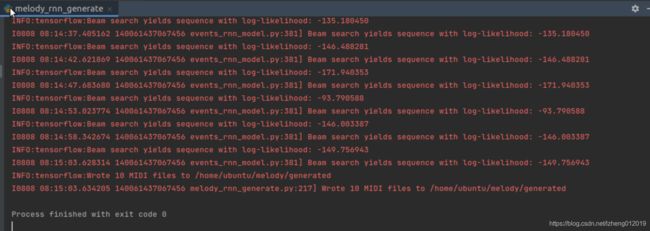
虽然只训练了一半,但生成部分还是可以顺利运行,生成midi音乐如下图所示,可以调整num_steps来控制生成的音乐片段长度(训练未完成可能导致生成的音乐不大好听)
