11.提取图像内容区域
目录
1 项目介绍
2 代码实现
2.1 导入库
2.2 添加参数
2.3 定义四个方法
2.3.1 order_points
2.3.2 four_point_transform
2.3.3 resize
2.3.4 cv_show
2.4 提取图片小票轮廓
2.4.1 把图读进来
2.4.2 改变图像大小
2.4.3 图像灰度处理
2.4.4 高斯滤波
2.4.5 边缘检测
2.4.6 轮廓检测
2.4.7 轮廓排序
2.4.8 近似轮廓
2.4.9 画出轮廓
2.5 摆正图像
2.5.1 order_points()
2.5.2 four_point_transform
2.6 灰度处理
2.7 二值处理
2.8 保存图片
1 项目介绍
我现在有这样一张小票,效果是这样的


我们可以对这样一张图进行OCR,视频中用的是tesseract,如果使用tesseract3英文效果还可以,中文的效果太差了,最新版的tesseract5我没有办法下载中文的语言包而且搞tesseract要搞很多变量且只支持windows,所以干脆后面的OCR就不做了,如果想做的话还是用人工智能算法搞,或者调用个API这样还方便些
2 代码实现
2.1 导入库

2.2 添加参数
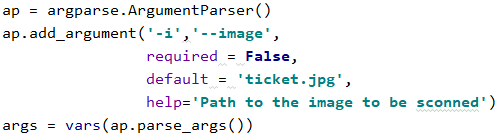
这个在上一个项目讲过,如果要在外面控制台用的话,我们最好在项目完成后把required改成True
2.3 定义四个方法
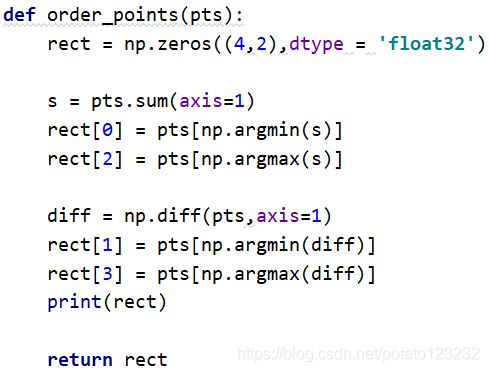
2.3.1 order_points
作用是排好我们给的点,下面用的时候会讲到
- 视频中的方法
我看了一下,感觉没有什么道理,为什么坐标相加最大的就是右下角点,最小就是左上角点,为什么坐标相减最小就是右上角点,最大就是左下角点

- 我写的方法

2.3.2 four_point_transform
下面用的时候会讲到

2.3.3 resize
重置图片大小的函数,与 10.银行卡号识别 的resize函数相似,都是给定宽或者高,还是根据原本的宽高比改变另一条边

2.3.4 cv_show
展示图片的函数

2.4 提取图片小票轮廓
2.4.1 把图读进来
![]()
2.4.2 改变图像大小
我们要把图像resize成高为500的图像,保持原来的宽高比,首先我们计算出宽高比,然后复制我们上面的图像
![]()
- image.shape[0]是原图像的高
然后使用上面定义的resize改变尺寸
![]()
2.4.3 图像灰度处理
![]()
2.4.4 高斯滤波
目的是去除图像的噪音点
![]()
2.4.5 边缘检测
![]()
我们显示出来看一下

我们现在就要最外部的四个边框
2.4.6 轮廓检测
![]()
2.4.7 轮廓排序
我们要的最外部的四个边框,这四个边框是面积最大的,所以我们按照面积排序,我们选择轮廓列表中买诺记最大的5个
![]()
- reverse = True是反向,这样它就会从大到小排列
- [:5]相当于[0:5]选择序列中的前5个
选前5个的原因是在一张图中有可能有五个小票,如果更多我们可以多选几个轮廓
2.4.8 近似轮廓
我们小票拍出来不一定是一个四边形,像我们上面的这个图就不是一个四边形

所以我们现在对轮廓进行近似

遍历我们获取的前5个轮廓,之后计算各自周长,然后对轮廓进行近似,如果approx中有四个点(如果近似后结果是四边形),则将approx赋值给screenCnt
2.4.9 画出轮廓
我们把刚刚过滤包的轮廓画出来,然后展示出来
![]()

发现screenCnt列表中只有一个轮廓且这个轮廓是我们想要的
我们再看一下screenCnt中有什么,以及screen的shape
![]()

2.5 摆正图像
现在我们的小票是歪的,我们给它摆正
它的原理是这样的,我原图中获取的A,B,C,D四个点的小票轮廓,我现在要轮廓提出来变成一张图片,那么我们就要E,F,G,H四个点,这四个点是我想要的新图像的新点,原图与结果之间通过矩阵M进行运算

使用的是four_point_transform()这个方法,这个方法是在前面定义的方法
![]()
第一个参数是要转换的原始图像,我们现在看一下第二个参数
screenCnt,reshape是改变一下的形式,转换之后是这样的
![]()

由于我们之前resize过图像,所以我们对每个点再乘图像改变的比例
![]()

- 数值后面的点代表元素是是个浮点类型的值,不影响运算
现在我们回到four_point_transform()这个方法

第一步,调用order_points这个方法,这个也在之前定义过
2.5.1 order_points()
2.5.1.1 视频中的方法
视频中的方法在逻辑上是没有道理的,我们如果要看正确的,可以往下翻看我写的正确的,不过在这里介绍了sum与diff的方法,可以看一下

首先定义一个(4,2)的全零数组rect
之后使用了numpy中的sum方法,我们先看一下不加axis的结果
- 使用sum之前

- 使用之后
![]()
![]()
3442是把上面矩阵中所有元素加到了一起
3442 = 456+162+20+546+296+820+692+450
现在我们设置axis为0
- 使用sum之前

- 使用sum之后
![]()
![]()
发现他会把矩阵的每一列都相加
1464 = 456+20+296+692
1978 = 162+546+820+450
我们现在把axis设置为1
- 使用sum之前

- 使用sum之后
![]()
![]()
这个是把矩阵的每一行相加
618 = 456 + 162
566 = 20 + 546
1116 = 296 + 820
1142 = 692 + 450
我们回到我们的order_points()函数
我们我们定义轮廓的点横向相加,现在的s是这样的
![]()
然后我们设置 rect的0号为是s的最小的一组,也就是566这一组,是[20,546],
然后设置rect的2号位是s的最大值,也就是1142这一组,是[692,450]
sum操作的目的是找到 坐标和最小的点作为左上角点,找到 坐标和最大的点 作为右下角点
后面我们使用了np.diff这个方法,我做个例子


B这个结果是这样的出来的
| 结 | 果 | |
|---|---|---|
| 3-2=1 | 4-3=1 | 5-4=1 |
| 8-6=2 | 8-8=0 | 9-8=1 |
| 11-10=1 | 12-11=1 | 13-12=1 |
现在是没加axis,下面我们看一下axis=0的情况


C这个结果是这样的出来的
| 结 | 果 | ||
|---|---|---|---|
| 6-2=4 | 8-3=5 | 8-4=4 | 9-5=4 |
| 10-6=4 | 11-8=3 | 12-8=4 | 13-9=4 |
axis = 1的计算方式与不加axis的计算方式相同


然后我们再回到order_points

首先对pts矩阵横向相减
- pts

- 结果
162 - 456 = -264
546 - 20 = 526
820 - 296 = 524
450 - 692 = -242
[-264]
[526]
[524]
[-242]

rect的1号位取diff的最小的一组,也就是-242这一组,也就是[456,162]
rect的3号位取diff的最大值,也就是526这一组,也就是[20,546]
刚刚我们找到了左上角点和右下角点,现在我们还差右上角点与左下角点,右上角点定义为 坐标差(纵坐标-横坐标)最小的点,左下角点定义为 坐标差最大的点
我们现在的rect是这个样子的


- order_points这个方法找出四个角点是毫无道理的,我们换一种写法
2.5.1.2 我写的方法
我的思路是这样的,我们先判定左边的点,我们定义x值最小的两个点为左侧的点,反之为右侧的点


现在我们有了两组点,我们定义y值最小的点为上侧点,反之为下侧点

然后我们把四个点赋值为rect,顺序是左上,右上,右下,左下


当然我们根据情况的不同,这四个点的位置也可以随之变化
2.5.2 four_point_transform
之后我们再返回four_point_transform

我们分解rect成四个值,tl(top-left),tr(top-right),br(bottom-right),bl(bottom-left),分别是左上,右上,右下,左下的意思
现在我们使用左下与右下两个点,两个点的x值做差然后平方+两个点的y值做差然后平方 定义为widthA
然后使用左上与右上两个点,两个点的x值做差然后平方+两个点的y值做差然后平方 定义为widthB
之后取widthA与widthB的最大值
这个方法其实是勾股定理求第三边,我们画一个widthA的计算方式

我们下面的这个绿边就是widthA
widthA,widthB,heightA,heightB实际上都是这样得出来的
后面我们定义dst,dst是新图片的新坐标点

(0,0)为左上角点,(maxWidth-1,0)为右上角点,(maxWidth-1,maxHeitht01)为右下角点,(0,maxHeight-1)为左下角点
之后使用cv2,getPerspectiveTransform计算出矩阵M,参数为老坐标与新坐标
![]()

之后再通过cv2,warpPerspective对原图进行转换,然后返回warped

2.6 灰度处理
![]()
2.7 二值处理
![]()
2.8 保存图片
![]()
我们的图片是这样的
