深度学习之掌纹识别(DeepLearning Palmprint)
深度学习之掌纹识别(Update)
本次我们还是基于Gabor滤波器去提取出掌纹特征,嘻嘻,这次打算复现一下今年五月份的那篇进口论文!《Deep Distillation Hashing for Unconstrained
Palmprint Recognition》
Translate:《深度散列蒸馏算法在掌纹识别中的应用》
论文的贡献
1.提供了由五台手机采集的掌纹数据集XJTU-UP
2.根据KD模型,重构KD_Unconstrained_loss(以减小教师网络和轻学生网络的特征分布差异)
3.该方法在处理掌纹识别和验证时比现有的方法更具有鲁棒性和有效性,DDH的掌纹识别准确率提高了11.37%,掌纹验证的等错误率(EER)降低了3.11%。
提示:以下是本篇文章正文内容
一、Teacher network and Student network
在论文中,heavy(Teacher)network具有更多的参数和更强的特征提取能力,用于保证准确性。light(Student)以较少的参数保证了实时性要求。同时,在老师的指导下也可以获得更高的准确性。
Teacher network:
VGG-16 深度哈希网络(DHN)
Student network:
FN(两层卷积层,三层全连接层)
二、使用步骤
1.引入库
代码如下(示例):
import torch
from torchvision import datasets, models, transforms
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import numpy as np
import matplotlib.pyplot as plt
import os
import re
import cv2
import tensorflow as tf
from skimage import filters
tf.compat.v1.enable_eager_execution()
2.搭建vgg16模型
代码如下(示例):
class vgg16(img):
def __init__(self, img):
# 定义权重
self.paramerters = []
#共享参数
self.img = img
self.convlayers()
self.fc_layers()
self.probs = tf.nn.softmax(self.fc8)
def saver(self):
return tf.train.Saver()
def maxpooling(self, name, input_data):
# 最大池化层
out = tf.nn.max_pooling(input_data, [1, 3, 3, 1], [1, 3, 3, 1], padding='SAME', name=name)
return out
def conv(self, name, input_data, out_channel, trainable=False):
in_channel = input_data.get_shape()[-1]
with tf.variable_scope(name):
kernel = tf.get_variable("wetghts", [3, 3, in_channel, out_channel], dtype=tf.float32, trainable=False)
biases = tf.get_variable("biases", [out_channel], dtype=tf.float32, trainable=False)
conv_res = tf.nn.conv2d(input_data, kernel, [1, 1, 1, 1], padding='SAME')
res = tf.nn.bias_add(conv_res, biases)
out = tf.nn.relu(res, name=name)
self.paramerters += [kernel, biases] # 将卷积层定义的参数(kernel,biases)加入列表
return out
def fc(self, name, input_data, out_channel, trainable=True):
shape = input_data.get_shape().as_list() # 获得各个维度的维数
if len(shape) == 4: # 获得维度,为数据展开做准备
size = shape[-1] * shape[-2] * shape[-3] # 拉成向量后,向量的长度
else:
size = shape[1]
input_data_flat = tf.reshape(input_data, [-1, size]) # 对数据展开操作,拉成一维向量
with tf.variable_scope(name):
weights = tf.get_variable(name="weight", shape=[size, out_channel], dtype=tf.float32, trainable=trainable)
biases = tf.get_variable(name="biases", shape=[out_channel], dtype=tf.float32, trainable=trainable)
res = tf.matmul(input_data_flat, weights)
out = tf.nn.relu(tf.nn.bias_add(res, biases))
self.paramerters += [weights, biases] # 将全连接层定义的参数(weights,biases)加入列表
return out
def convlayers(self):
self.conv1_1 = self.conv("conv1_1", self.imgs, 64, trainable=False)
self.conv1_2 = self.conv("conv1_2", self.conv1_1, 64, trainable=False)
self.pool1 = self.maxpool("pool1", self.conv1_2)
self.conv2_1 = self.conv("conv2_1", self.pool1, 128, trainable=False)
self.conv2_1 = self.conv("conv2_1", self.imgs, 128, trainable=False)
self.conv2_2 = self.conv("conv2_2", self.conv2_1, 128, trainable=False)
self.pool2 = self.maxpool("pool2", self.conv2_2)
self.conv3_1 = self.conv("conv3_1", self.pool2, 256, trainable=False)
self.conv3_2 = self.conv("conv3_2", self.conv3_1, 256, trainable=False)
self.conv3_3 = self.conv("conv3_3", self.conv3_2, 256, trainable=False)
self.pool3 = self.maxpool("pool3", self.conv3_3)
self.conv4_1 = self.conv("conv4_1", self.pool3, 512, trainable=False)
self.conv4_2 = self.conv("conv4_2", self.conv4_1, 512, trainable=False)
self.conv4_3 = self.conv("conv4_3", self.conv4_2, 512, trainable=False)
self.pool4 = self.maxpool("pool4", self.conv4_3)
self.conv5_1 = self.conv("conv5_1", self.pool4, 512, trainable=False)
self.conv5_2 = self.conv("conv5_2", self.conv5_1, 512, trainable=False)
self.conv5_3 = self.conv("conv5_3", self.conv5_2, 512, trainable=False)
self.pool5 = self.maxpool("pool5", self.conv5_3)
def fc_layers(self):
self.fc6 = self.fc("f1", self.pool5, 4096, trainable=False)
self.fc7 = self.fc("fc2", self.fc6, 4096, trainable=False)
self.fc8 = self.fc("fc3", self.fc7, 4, trainable=True) # 2表示需要分类的类别的数量
def load_weights(self, weight_file, sess): # 这个函数将获取的权重载入VGG模型中
weights = np.load(weight_file)
keys = sorted(weights.keys())
for i, k in enumerate(keys):
if i not in [30, 31]: # 剔除fc8和softmax层的参数
sess.run(self.paramerters[i].assign(weights[k]))
print("----------weights loads------------")
model =vgg16(Img)
model.cuda("0")
vgg16作为teacher_network
作为light网络需要保证自身的轻量性,故论文中提到双层卷积,三层全连接层,具体代码emmm,要脸,跑完之后acc才0.56,等攻城狮把网络修好再说,或者有大神帮忙指教指教,嘻嘻嘻!
用resnet152网络去填坑
resnet152= models.resnet152(pretrained=True)
#加载预训练模型
for param in resnet152.parameters():
param.requires_grad = False
fc_inputs = resnet152.fc.in_features
resnet18.fc = nn.Sequential(
nn.Linear(fc_inputs, 256),
nn.ReLU(),
nn.Dropout(0.8),
nn.Linear(256, 386),
nn.LogSoftmax(dim=1)
)
# 用GPU进行训练
resnet152= resnet152.to('cuda:0')
# 定义损失函数和优化器
loss_func = nn.NLLLoss()
optimizer = optim.Adam(resnet152.parameters())
效果嘛!也就这样!
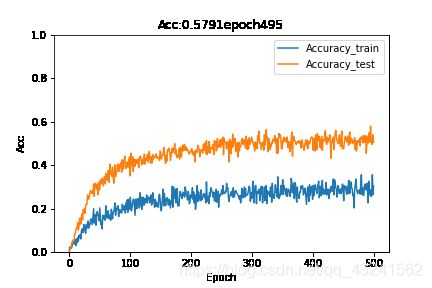
训练效果图
下面是自己优化后的结果:
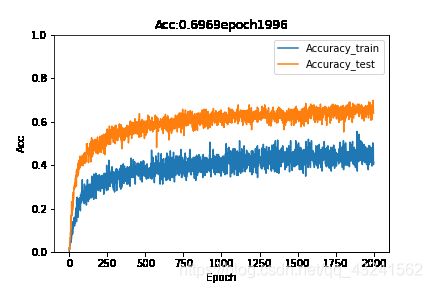
补充一句哈!这个只是ResNet的网络训练效果图,Resnet内部被我改了,我个人分析认为时图片做训练时由于随机旋转角度造成的这个效果,详细问题也在排查中。。
希望走过路过的大佬可以多多交流,我还有一个最优的模型acc高达83.5%,等我下篇文章出产更加优秀模型吧!