spring源码4--AnnotationConfigApplicationContext.refresh()
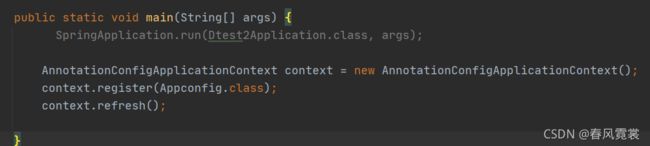
下面我们进入refresh()方法里面去:debug到
this.invokeBeanFactoryPostProcessors(beanFactory);
这个时发现加入了大量类

那我们继续往下(注意我们的注意力在beanfactory里面(一般在this和refistry里面都是同一个传递的类或者有继承关系)):
找到这个方法:
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry, beanFactory.getApplicationStartup());


postProcessor.postProcessBeanDefinitionRegistry(registry);
与上面一样,进入这个方法:

parser.parse(candidates);
发现了这个方法添加了

这个扫描包下的所有类:
那必须进去看看:
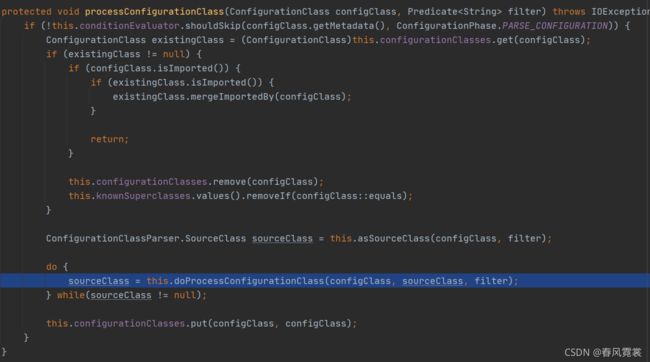
进入这个方法:
sourceClass = this.doProcessConfigurationClass(configClass, sourceClass, filter);

Set scannedBeanDefinitions = this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
再进入这个方法:
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, final String declaringClass) {
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry, componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = BeanNameGenerator.class == generatorClass;
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator : (BeanNameGenerator)BeanUtils.instantiateClass(generatorClass));
ScopedProxyMode scopedProxyMode = (ScopedProxyMode)componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
} else {
Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver((ScopeMetadataResolver)BeanUtils.instantiateClass(resolverClass));
}
scanner.setResourcePattern(componentScan.getString("resourcePattern"));
AnnotationAttributes[] var15 = componentScan.getAnnotationArray("includeFilters");
int var8 = var15.length;
int var9;
AnnotationAttributes filter;
Iterator var11;
TypeFilter typeFilter;
for(var9 = 0; var9 < var8; ++var9) {
filter = var15[var9];
var11 = this.typeFiltersFor(filter).iterator();
while(var11.hasNext()) {
typeFilter = (TypeFilter)var11.next();
scanner.addIncludeFilter(typeFilter);
}
}
var15 = componentScan.getAnnotationArray("excludeFilters");
var8 = var15.length;
for(var9 = 0; var9 < var8; ++var9) {
filter = var15[var9];
var11 = this.typeFiltersFor(filter).iterator();
while(var11.hasNext()) {
typeFilter = (TypeFilter)var11.next();
scanner.addExcludeFilter(typeFilter);
}
}
boolean lazyInit = componentScan.getBoolean("lazyInit");
if (lazyInit) {
scanner.getBeanDefinitionDefaults().setLazyInit(true);
}
Set<String> basePackages = new LinkedHashSet();
String[] basePackagesArray = componentScan.getStringArray("basePackages");
String[] var19 = basePackagesArray;
int var21 = basePackagesArray.length;
int var22;
for(var22 = 0; var22 < var21; ++var22) {
String pkg = var19[var22];
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg), ",; \t\n");
Collections.addAll(basePackages, tokenized);
}
Class[] var20 = componentScan.getClassArray("basePackageClasses");
var21 = var20.length;
for(var22 = 0; var22 < var21; ++var22) {
Class<?> clazz = var20[var22];
basePackages.add(ClassUtils.getPackageName(clazz));
}
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
return scanner.doScan(StringUtils.toStringArray(basePackages));
}
这里注意这个类:basePackages

我们可以看到这里装的就是我们要扫描包的路径了!!!!
然后我们进入这个方法:
![]()
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet();
String[] var3 = basePackages;
int var4 = basePackages.length;
for(int var5 = 0; var5 < var4; ++var5) {
String basePackage = var3[var5];
Set<BeanDefinition> candidates = this.findCandidateComponents(basePackage);
Iterator var8 = candidates.iterator();
while(var8.hasNext()) {
BeanDefinition candidate = (BeanDefinition)var8.next();
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
this.postProcessBeanDefinition((AbstractBeanDefinition)candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition)candidate);
}
if (this.checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
this.registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
![]()
这里看到了这个方法,将路径名变成了类:
Set<BeanDefinition> candidates = this.findCandidateComponents(basePackage);
进去看看:

debug:再进去看:
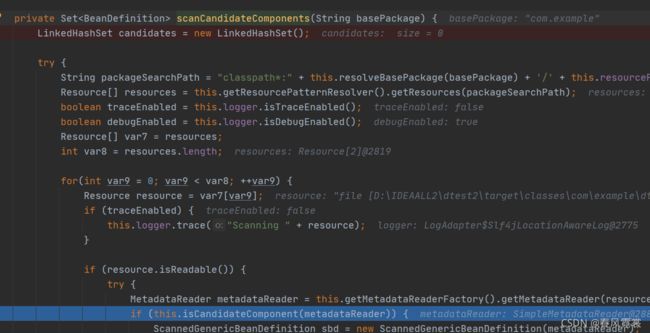
进入了scanCandidateComponents(String basePackage)方法:
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
LinkedHashSet candidates = new LinkedHashSet();
try {
String packageSearchPath = "classpath*:" + this.resolveBasePackage(basePackage) + '/' + this.resourcePattern;
Resource[] resources = this.getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = this.logger.isTraceEnabled();
boolean debugEnabled = this.logger.isDebugEnabled();
Resource[] var7 = resources;
int var8 = resources.length;
for(int var9 = 0; var9 < var8; ++var9) {
Resource resource = var7[var9];
if (traceEnabled) {
this.logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
MetadataReader metadataReader = this.getMetadataReaderFactory().getMetadataReader(resource);
if (this.isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (this.isCandidateComponent((AnnotatedBeanDefinition)sbd)) {
if (debugEnabled) {
this.logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
} else if (debugEnabled) {
this.logger.debug("Ignored because not a concrete top-level class: " + resource);
}
} else if (traceEnabled) {
this.logger.trace("Ignored because not matching any filter: " + resource);
}
} catch (Throwable var13) {
throw new BeanDefinitionStoreException("Failed to read candidate component class: " + resource, var13);
}
} else if (traceEnabled) {
this.logger.trace("Ignored because not readable: " + resource);
}
}
return candidates;
} catch (IOException var14) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", var14);
}
}
String packageSearchPath = "classpath*:" + this.resolveBasePackage(basePackage) + '/' + this.resourcePattern;
路径最后变成了:
![]()
Resource[] resources = this.getResourcePatternResolver().getResources(packageSearchPath);
看到通过resources()方法最终得到的resources:

MetadataReader metadataReader = this.getMetadataReaderFactory().getMetadataReader(resource);
通过getMetadaReader(resource)最后得到了类;

最后放在candidates里面返回回去。
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
this.registerBeanDefinition(definitionHolder, this.registry);
看到这最后四句,是不是好熟悉,没错就是和前面一样的包装,将类放在beanfactory里面;
这里获得了阶段性的成果了,已经知道了包的类怎么扫描到spring的工厂里了!!!!!!!!
除了这个类,一共有40多个spring自己加载的,有兴趣可以自己debug看看怎么来的!!!
总结:spring直接包扫描流程我们现在已经知道了,那@import和@Component呢?
续:spring源码5–@import和@Compone