项目中想使用git diff的文件变更比对功能,但git diff返回的格式是纯文本且未解析的。网上找了相关的库,像是parse-git-patch,使用的是git format-patch命令生成的补丁文件,无法直接接收命令行中返回的文本格式,找了几个都是这样,所以干脆就自己动手实现一个。
普通处理常见文本一般都是用正则,但这里是大段的文本,用正则即使写出来也很难以维护。网上有篇文章就是讲述JavaScript实现的逻辑,但用JavaScript处理字符串又比较繁琐。这里选用语法分析生成器来实现。
网上的文章经常能看到抽象语法树(AST)这个词,将人类编写的文本转换成计算机可初步读懂的数据结构称之为AST,而在AST之前需要先对文本做词法分析和语法分析,像是平日天天用的Babel里的词法和语法分析器就是Babylon。
语法分析器比较繁琐且枯燥,所以又出现语法分析器的生成器。一切能用JavaScripts写的终将用JavaScript写,前端自然也有相应可用的库,比较出名的有PEGjs与Jison两个库。有了生成器我们能做什么呢?小到替代正则,大到实现自己的领域特定语言(DSL)。像是曾一度最有希望替代JavaScript的CoffeeScript,他的V2版本就是用Jison库做自己的语法分析器。
PEGjs语法规则很容易上手,这里使用PEGjs来实现解析器。(PEGjs已经没有维护者了,在使用的过程中意外发现有人另外建了一个分支版本在维护PEGgy,可以无缝过渡)
PEGGY
peggy可以在浏览器中使用,也可以引入项目中使用。又或是编写好规则,使用命令生成解析器提供使用。
简单的规则可以直接使用在线版的调试 https://peggyjs.org/online.html。
安装
npm install peggy网页使用的话可以直接引入peggy.min.js。
使用
const PEG = require("peggy");
// 导入规则 生成解析器
const parser = PEG.generate(RULE, {
trace: true,
});
// 使用解析器
const result = parser.parse(TEST_DATA, {
tracer: true,
});generate函数和parse函数都可以传入参数。
generate函数参数,网上有向南已翻译了我这里就摘录过来
allowedStartRules: 指定parser开始的rule. (默认是文法中第一个rule.)cache: 如果设置为true, parser会将parse的结果缓存起来, 可以避免在极端情况下过长的解析时间, 但同时它带来的副作用是会使得parser变慢(默认false).dependencies: 设置parser的依赖, 其值是一个对象, 其key为访问依赖的变量, 而value为需要加载的依赖module id.只有当format参数被设置为"amd","commonjs","umd"该参数才生效. (默认为{})exportVar: Name of a global variable into which the parser object is assigned to when no module loader is detected; valid only when format is set to "globals" or "umd" (default: null).format: 生成的parser格式, 可选值为("amd","bare","commonjs","globals", or"umd"). 只有output设置为source, 该参数才生效optimize: 为生成的parser选择一个优化方案, 可选值为"speed"或者"size". (默认"speed")output: 设置generate()方法返回格式. 如果值为"parser", 则返回生成的parser对象. 如果设置为"source", 则返回parser source字符串plugins: 要使用的插件trace: 追踪parser的执行过程(默认是false).
parse函数参数
startRule:起始解析的rule名称tracer:展示parser执行rule的过程...(任意其他参数):使用options变量接收参数,可以在parse函数中传入自定义参数,可以给解析规则提供一些配置功能
规则
规则很简单,会举一个例子说说,描述的会比较繁琐,快速理解可以直接看官方文档,一共没几条规则。
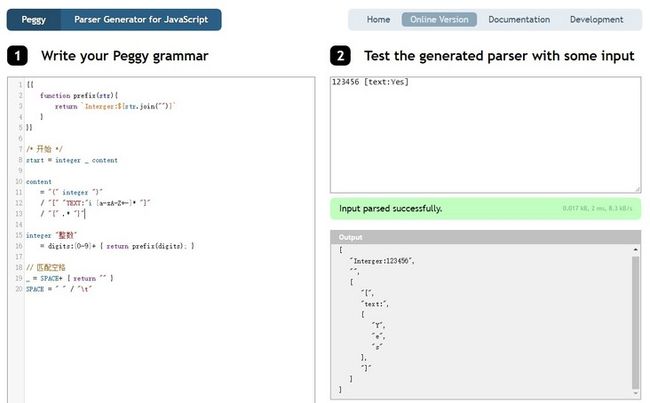
整体样子大概是这样:
在VSCode里可以安装
Peggy Language插件,能提供语法高亮、跳转、错误提示等功能。
{{
function prefix(str){
return `Interger:${str.join("")}`
}
}}
/* 开始 */
start = integer _ content
content
= "(" integer ")"
/ "[" "TEXT:"i [a-zA-Z+-]* "]"
/ "{" .* "}"
integer "整数"
= digits:[0-9]+ { return prefix(digits); }
// 匹配空格
_ = SPACE+ { return "" }
SPACE = " " / "\t"可以使用在线版,输入123456 (00)或是123456 [text:Yes]类似格式需要解析的字符串,可以看到匹配出的数据。
这个简短的规则把常用的规则都罗列进去了,来解释一下。
{{
function prefix(str){
return `Interger:${str.join("")}`
}
}}{{}}初始化器
最顶部的花括号的区域称之为初始化器,用一个{}两个{{}}括号定义都可以,前后括号数匹配的起来就行。在这里可以自定义一些JavaScript代码。
可以通过options拿到传参做预处理,也可以定义一些工具函数供后续的规则使用。
接下来遇到第一个规则:
/* 开始 */
start = integer _ content/**/与//注释
与其他编程语言一样支持/**/与//的注释。
start规则名
start是规则名称,可以任意拟定,只需要符合JavaScript起名规范即可。
integer _ content解析表达式
=等号后面是解析的表达式,这里的表达式是integer _ content。
是不是看不懂这些代表什么意思?这就说明其中的表达式很可能是另一个规则名,所以可以继续往下看:
content
= "(" integer ")"
/ "[" "TEXT:"i [a-zA-Z+-]* "]"
/ "{" .* "}"这里看到上面解析表达式中的其中一个规则content。
空白符
会发现这里定义格式不太一样,等号可以换到第二行去。
pegpy在解析规则时,词法分析先会把文本分割成一个个token(像是=、"、/、字符串、注释等),不同于JavaScript,空白符不作为token,所以在之间我们可以任意换行或者插入空格。
/符号
/符号类似于或的意思,代表了符号前后是两个规则,先匹配前面的规则,当不匹配时继续匹配后面的。可以有任意多个规则连接,直到所有的规则匹配不成功,抛出异常。
""引号
先来看第一个表达式"(" integer ")",文本数据我们用引号引起,所以前后是匹配两个括号。
中间的依然不认识,说明是另一个规则名。所以可以推测这段是解析两个括号之间的某些字符,根据名称是匹配两个括号之间的数字。
再来看下一条:
"[" "TEXT:"i [a-zA-Z+-]* "]",这里一样,但更复杂一些,匹配方括号之间的值,但这里没有引用其他规则,而是写了明确的匹配信息。
“”i忽略大小写
"TEXT:"i一样,引号中间是文本,所以匹配的是TEXT:,后面的i是做什么的?这跟正则一样,加i是忽略字符串的大小写,所以也可以匹配text等形式。
[]从集合中匹配
[a-zA-Z+-]*看的是不是很像正则?这里就跟正则一样,匹配a到z即所有的英文字母,A-Z是大写的英文字母,同时还有+、-两个符号。
*+匹配次数控制
[]方括号表示只会匹配其中所列的一个,所以在最后的*表示匹配次数,零次或多次。
同样,还有+号,代表一次或多次。
?匹配失败返回null
有时在其他解析表达式里还能看到?符号,?不是像正则那样代表零次到一次,而是表示匹配成功就返回结果,不成功返回null。
同时也没有{}表达额外的重复次数功能,只有*、+两个符号,相对于正则功能没那么丰富。
"[" "TEXT:"i [a-zA-Z+-]* "]",所以这一段就是匹配方括号中以TEXT:开头,后面的所有大小写字母及加减号字符。
第三条规则: "{" .* "}"。
.任意一个字符
按之前学到的,这是匹配花括号中的内容,*代表匹配次数,那.呢?.在这里代表匹配任意一个字符,包括空格之类的字符。所以这句实际上是匹配花括号中的所有内容。
到这里其实已经把基础规则学完了,说的比较啰嗦,实际上很简单,没几个规则,上面的连起来是这样的:
匹配圆括号中的符合integer规则的信息,如果有不符合的,则换到下一个规则,匹配方括号以TEXT:不分大小写开头的内容,其中内容只能是大小写字母及加减号字符这些字符,如果有其他字符则匹配不成功,跳到最后一个规则,匹配花括号中的所有字符。再不成功,则弹出错误信息。
再往下看,就能看到一直被提及的integer规则:
integer "整数"
= digits:[0-9]+ { return prefix(digits); }规则别名
这里在规则后面等号前面又多了一个带引号字符串"整数",这是规则的别名,调试时使用,也可以同前面其他规则一样省略掉。
digits:[0-9]+解析表达式标签
在解析表达式中可以看到除了前面已知的部分[0-9]+,还多了 一个冒号的语法,这是给解析结果起一个名称,方便后面的action调用。
{ return prefix(digits); }解析表达式的action
相对于其他规则,这个规则我们在末尾定义了类似函数的东西,这就是JavaScript函数。我们可以在解析表达式之后增加花括号,其中写JavaScript代码。像是这句,就是调用了我们在初始化器中定义的函数,将获取到的文本处理一下再返回。
这个就是peggy自由的地方,当本身语法解析能力不够的时候,或者解析出来的文本比较零碎(字符串常常会被分割成一个个存到数组中),这时候我们就需要用到action。
这里结合起来integer规则是匹配一到多个数字字符,并且处理成连续的字符串(处理前匹配出来的数据是[1,2,3,4,5]这样的,为了方便阅读与使用,往往需要处理成12345),并且加上Interger:的前缀。
最后一段是解析空格的规则:
// 匹配空格
_ = SPACE+ { return "" }
SPACE = " " / "\t"之前有提到,在token之间的空白符会忽略,所以如果文本中有空格,也需要单独匹配。
用冒号即可" ",如果需要匹配制表符之类的也可以直接写"\t"。
为了不影响解析表达式的阅读,命名为_方便识别。同时将匹配到的结果用一个action转换为空,方便后续将数据处理掉。
运行起来匹配文本返回的数据大概是这样,有需要的话可以再加action将数据处理成指定格式:
git diff 的数据格式
说了这么多,现在才可以开始进入到我们要做的需求中。要解析git diff返回数据,自然先要知道格式规范。
返回数据大概长这样:
diff --git a/package.json b/package.json
index cb2f4bc..35455a2 100644
--- a/package.json
+++ b/package.json
@@ -1,13 +1,14 @@
{
"name": "peg-git-diff-parser",
- "version": "0.0.0",
+ "version": "1.0.0",
"description": "git diff 文本解析器",
- "main": "index.js",
+ "main": "src/index.js",
"scripts": {
"build": "peggy -o dist/gitDiffParser.js src/gitDiffParser.peggy",
"test": "node src/index.js"
},
"author": "LnnCoCo",
+ "new": "new",
"license": "ISC",
"dependencies": {
"peggy": "^1.2.0"我们一行一行来说明。
diff --git a/package.json b/package.jsondiff --git是固定字符,a和b表示变动前与变动后的文件。
index cb2f4bc..35455a2 100644..是分隔符,表示index区域hash为cb2f4bc的对象,与工作区hash为35455a2的对象。100644为对象的模式,100代表普通文件,644代表权限信息。
--- a/package.json
+++ b/package.json比较的文件名信息,---变动前,+++变动后。
@@ -1,13 +1,14 @@
{
"name": "peg-git-diff-parser",
- "version": "0.0.0",
+ "version": "1.0.0",
"description": "git diff 文本解析器",
- "main": "index.js",
+ "main": "src/index.js",
"scripts": {
"build": "peggy -o dist/gitDiffParser.js src/gitDiffParser.peggy",
"test": "node src/index.js"
},
"author": "LnnCoCo",
+ "new": "new",
"license": "ISC",
"dependencies": {
"peggy": "^1.2.0"从这里开始就是每个变动的信息块。以@@...@@起头,有多个块就有多个@@...@@,这里目前只有一个。
-1,13 +1,14,-代表变动前、+代表变动后,1,13,代表从第一行开始展示之后的十三行。1,14同理,因为有一行是新增,所以变动后会多一行。
然后接下去的是文本,这里容易看见的是两个符号,实际上是有三个:+、-、空格。这个对解析很重要,所有行都是以这三个起始。-是变动前,+是变动后,空格是未变更内容。
未变更内容展示逻辑是,以变化行为中心,展示上下最多三行内容。
这样整个git diff输出格式就清晰了。
在查资料的时候发现实际还有新增、已删除、重命名,文件还有分二进制非二进制的情况,但在单纯的命令行git diff情况下,这些是无法输出数据的,所以而且当前需求也没用到,就忽略了这些其他情况。
实现解析规则
新建一个项目,然后安装peggy。
新建一个gitDiffParser.peggy文件来编写规则,其他读取测试数据传入插件之类测试性代码可以自己补充。
完整的项目地址:peg-git-diff-parser
在VSCode中可以安装
Peggy Language插件,能提供高亮语法和错误提示之类的。
先定义一些公共的规则
/**
* 公共定义
*/
// 路径文件名
filePath = hit:[A-Za-z0-9\\\/\._\-@$()*&^+!]+ { return hit.join("") }
// 换行
LINE_END = "\r\n" / "\n"
// 空白符
__ = SPACE* { return "" }
_ = SPACE+ { return "" }
SPACE = " " / "\t"然后开始吧。
diff --git a/package.json b/package.json这里变化的内容就只有文件名,所以其他部分都可以写死,大概是这样。
header = "diff --git" _ filePath _ filePath LINE_END很简单吧,只需要把变动的部分规则匹配起来就行了。
这里为了上层方便识别,所以增加了标签,包成了对象返回了。
/**
* 首行
**/
header
= "diff"i _ "--git"i _ 'a'beforePath:filePath _ 'b'afterPath:filePath LINE_END
{
return {
beforePath,
afterPath
}
}接下来都差不多。直接来看看比较麻烦的变动块的数据解析。
先解析头部
@@ -1,13 +1,14 @@很容易,从@@开始定位,到@@结束。
changeHeader
= "@@" _ beforeChangeLine:changeLineInfo _ afterChangeLine:changeLineInfo _ "@@" LINE_END
{
return {
changeHeader: `@@ ${beforeChangeLine.text} ${afterChangeLine.text} @@`,
beforeChangeLine,
afterChangeLine
}
}
// 变动行信息 第N行开始,一共N行 1,6 第一行开始,一共6行(变化的-+两行算一行)
changeLineInfo
= type:([-|+]) line:([0-9]+","[0-9]+)
{
const lineFormatText = formatLine(line);
return {
text: `${type}${lineFormatText}`,
type,
line: lineFormatText
}
}由于行信息写在一起比较麻烦,所以另外写了个formatLine函数处理。
然后就是麻烦的地方,之后的数据是不定长的。而且+、-、空格符号在其余部分也会出现,所以只能限定开头的部分匹配到这三个分别进入三个不同的规则中。
但这里没有像是正则一样的开头标识符,所以换个角度想,每一行的开始,在上一行必然有一个换行符,所以可以这样定义LINE_END "-"或LINE_END "+".
之后的内容需要全部匹配,直接.*肯定是不行的,会将之后的所有信息一起匹配进去。好在文档中还写到有[]可以配合^符号用来反向匹配,比如[^ABC]就是匹配除了A、B、C的任意字符。
比较遗憾的是无法直接将规则配合^符号,不然可以写出较为复杂的匹配逻辑。所以目前信息已经可以解决了,变动块的数据必然是一行的,所以我们只要识别到换行符就停止匹配即可。
规则如下:
changeBeforeContent = LINE_END "-" hit:[^\r\n]+ {
return {
type: "-",
text: hit.join("")
}
}
changeAfterContent = LINE_END "+" hit:[^\r\n]+ {
return {
type: "+",
text: hit.join("")
}
}但我们变化数据是在中间,其前后还有上下文相关的背景数据,这些数据是以空格开头的,或者是当开头不是+、-符号的时候,就全作为上下文相关内容处理。所以规则很简单
changeContext = . {
return null
}然后我们将规则组合一下,这样四种情况就能包括所有文本了。
changeChunk
= line:changeHeader
/ beforeContent:changeBeforeContent
/ afterContent:changeAfterContent
/ changeContext但这样只能匹配一行内容,所以我们还需要加上次数信息和将上下文内容返回的空数据过滤了。
changeChunk
= hit:(
line:changeHeader
/ beforeContent:changeBeforeContent
/ afterContent:changeAfterContent
/ changeContext
)*
{
return hit.filter(item => item)
}再入口处将所需要的信息格式整理一下,就能返回我们预期的格式化后的diff数据了。

具体的细节可以到这里查看:peg-git-diff-parser