YOLOv3详解
YOLOv3详解
- 1. 什么是YOLO
- 2. 一个全卷积神经网络——Darknet-53
- 3. 输出
- 4. 锚框和预测
-
- 中心坐标
- 5.边界框维度
- 6. 物体分数和类置信度
- 7. 不同尺度的预测
- 8. 输出处理(在类分数上阈值处理)
- 附录
- 参考
1. 什么是YOLO
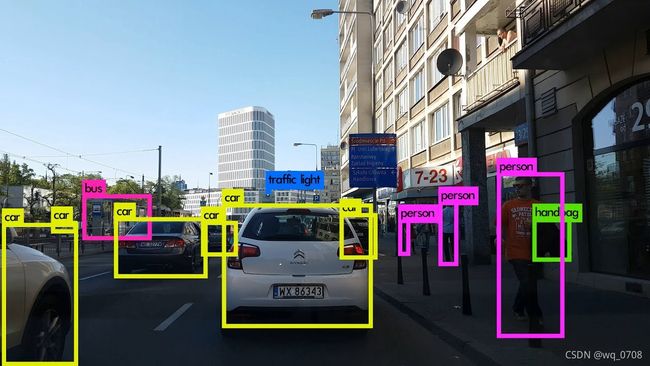
YOLO是“You Only Look Once”的简称,它虽然不是最精确的算法,但在精确度和速度之间选择的折中,效果也是相当不错。YOLOv3借鉴了YOLOv1和YOLOv2,虽然没有太多的创新点,但在保持YOLO家族速度的优势的同时,提升了检测精度,尤其对于小物体的检测能力。YOLOv3算法使用一个单独神经网络作用在图像上,将图像划分多个区域并且预测边界框和每个区域的概率。
2. 一个全卷积神经网络——Darknet-53
YOLOv3仅使用卷积层,使其成为一个全卷积网络(FCN)。文章中,作者提出一个新的特征提取网络,Darknet-53。正如其名,它包含53个卷积层,每个后面跟随着batch normalization层和leaky ReLU层。没有池化层,使用步幅为2的卷积层替代池化层进行特征图的降采样过程,这样可以有效阻止由于池化层导致的低层级特征的损失。Darknet-53网络如下图左边所示。

3. 输出
输入是(m,416,416,3)。输出是带有识别类的边界框列表,每个边界框由(pc, bx, by, bh, bw, c)六个参数表示。如果c表示80个类别,那么每个边界框由85个数字表示。
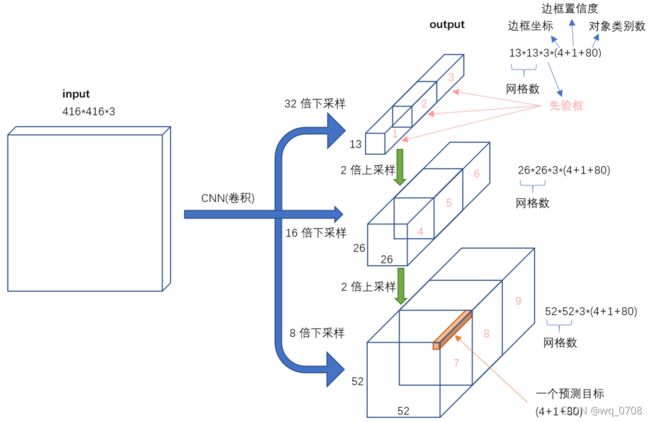
在YOLO中,预测过程使用一个1 × 1卷积,所以输入是一个特征图。由于使用1 × 1卷积,因此预测图正好是特征图大小(1 × 1卷积只是用于改变通道数)。在YOLOv3中,此预测图是每个cell预测固定数量的边界框。
如图2所示,预测图的深度为75,假设预测图深度为B×(5+C),表示每个cell可以预测的边界框数量。这B个边界框可以指定检测到一个物体。每个边界框有5+C个特征,分别描述中心点坐标和宽高(4)和物体分数(1)以及C个类置信度(图2中C=20)。YOLOv3每个cell预测三个边界框。
如果对象的中心(GT框中心)落在该cell感受野范围内,我们希望预测图的每个单元格都能通过其中一个边界框预测对象。其中只有一个边界框负责检测物体,首先我们需要确定此边界框属于哪个cell。
为了实现上面的想法,我们将原始图像分割为最后预测图维度大小的网格。如下图所示,输入图像维度为416×416,步幅为32(最后的预测图降采样32倍),最后预测图维度为13×13,所以我们将原始图像划分为13×13的网格。
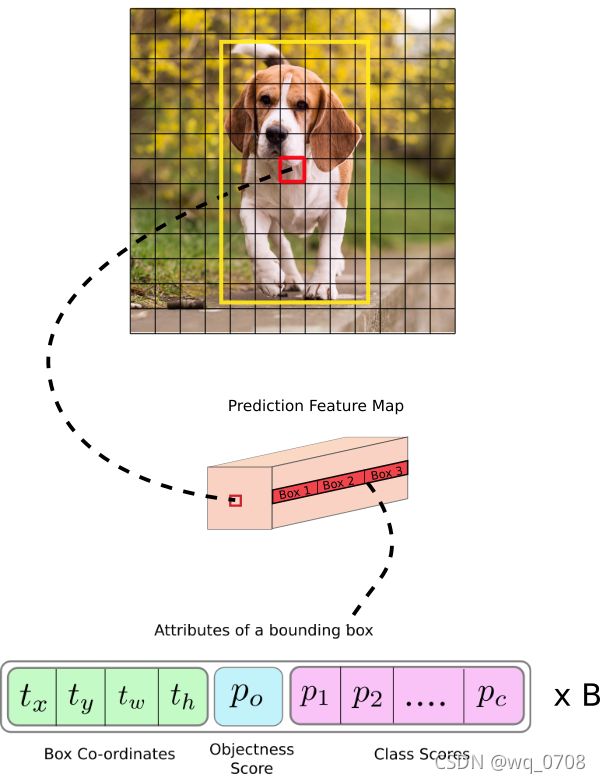
cell(输入图像中)包含了目标物体GT边界框中心被选择为对预测物体进行负责。如上图所示,红色的框包含了狗的边界框(黄色框)的中心,因此红色cell对预测狗进行负责。
如上图,红色框在第7行第7列的网格,预测特征图是中间的粉黄色长方体,其中的第7行第7列红色的对原图红色方格负责。也就是预测特征图中每个对相对应的原图中的cell负责。
每个cell可以预测三个边界框(这些边界框都是通过K-means方法聚类得到的长宽,不一定能完整包含物体,后期还会调整边界框范围),那么哪一个边界框会对物体负责呢(被赋为狗的GT标签)?简单介绍下,这里B是每个cell预测的边界框数,这里5是4+1,4个数字表示边界框,1个是边界框类是否有物体的得分,c表示需要预测的物体的数目。
下面我们使用另一个例子详细描述(注意这里是YOLOv2例子,每个cell给出5个边界框)。
现在我们使用五个边界框。YOLO框架如下:image Deep CNN Encoding 。19是608/32。
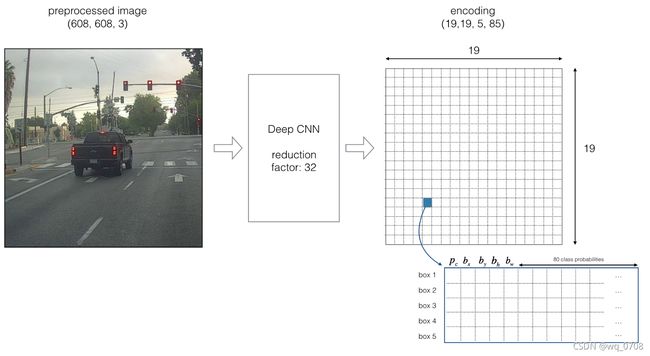
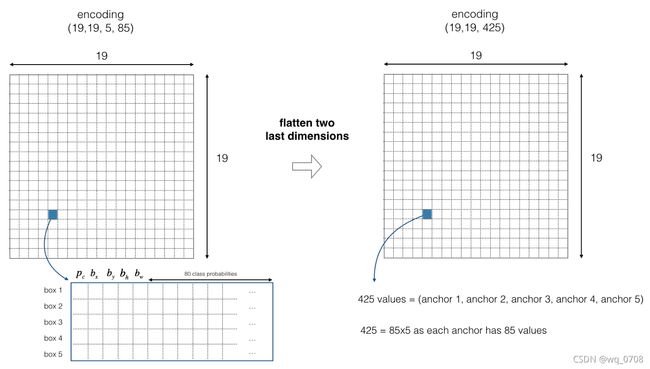
上图是YOLOv2的结果,输出预测特征图,每个cell有五个边界框进行预测,85分别表示是否为物体的分数(1个数字),边界框的表示(4个数字)和类概率(80个类)。如果物体的中心落在某个cell中,那么这个cell对预测物体负责(即使用相对应的预测图中的)。为了简便,我们将的最后两个进行铺平得到。如下图所示:
现在,对于每个cell的每个锚框我们计算下面的元素级乘法并且得到锚框包含一个物体类的概率,如下图:
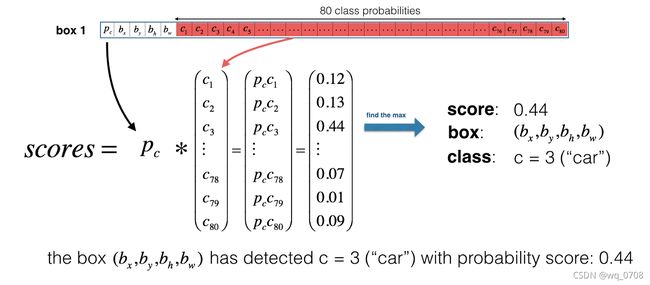
下面是YOLO在一张图像上的预测视觉化体现:对于每个表格cell,找到最大的概率分数(在5个锚框和不同类别中获取最大值);每个颜色表示表格cell中认为最可能的类。
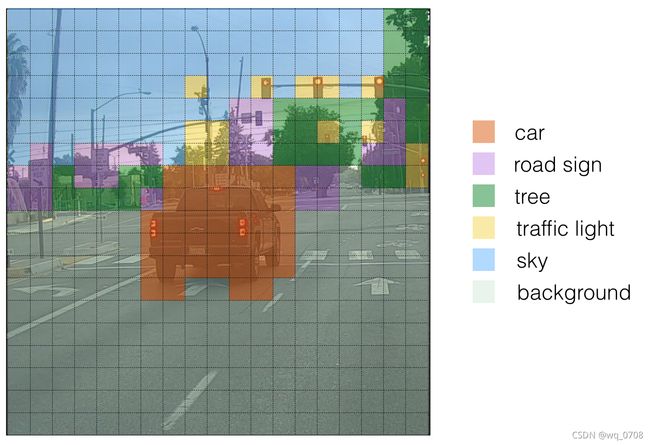
上面的图仅仅是直观上的表现,不是YOLO算法的重点。另一个方法是画出预测的边界框:

上面绘制的框的数量还是太多了,为了减少预测框的数量,我们使用NMS(非极大值抑制)去除多余的边界框。
4. 锚框和预测
直接预测框的宽高会导致训练时不稳定的梯度问题,因此,现在的很多目标检测方法使用log空间转换或者简单的偏移(offset)到称为锚框的预定义默认边界框。然后将这些变换应用到锚框以获得预测,YOLOv3具有三个锚框,可以预测每个单元格三个边界框。
锚框是边界框的先验,是使用k均值聚类在COCO数据集上计算的。我们将预测框的宽度和高度,以表示距聚类质心的偏移量。
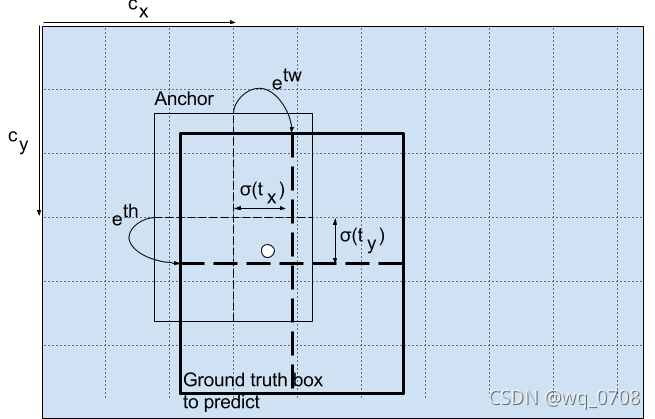
以下公式描述了如何转换网络输出以获得边界框预测:
b x = σ ( t x ) + c x , b y = σ ( t y ) + c y b_x=σ(t_x)+c_x, b_y=σ(t_y)+c_y bx=σ(tx)+cx,by=σ(ty)+cy
b w = p w e t w , b h = p h e t h b_w=p_we^{t_w}, b_h=p_he^{t_h} bw=pwetw,bh=pheth
这里bx,by,bw,bh分别是我们预测的中心坐标、宽度和高度。tx,ty,tw,th是网络的输出。cx,cy是网格从顶左部的坐标。pw,ph是锚框的维度(见下图)。
中心坐标
通过sigmoid函数进行中心坐标预测,强制将值限制在0和1之间。YOLO不是预测边界框中心的绝对坐标,它预测的是偏移量:相对于预测对象的网格单元的左上角;通过特征图cell归一化维度。
例如,考虑上面狗的图像。如果预测中心坐标是(0.4,0.7),意味着中心在(6.4,6.7)(因为红色框左上角坐标是(6,6))。但是如果预测的坐标大于1,例如(1.2,0.7),意味着中心在(7.2,6.7),现在中心在红色框右边,但是我们只能使用红色框对对象预测负责,所以我们添加一个sidmoid函数强制限制在0和1之间。
5.边界框维度
通过对输出应用对数空间转换,然后与锚框相乘,可以预测边界框的尺寸(如上面的计算公式)。
这里预测通过图像高度和宽度标准化。因此,如果对于包含狗的边界框的预测为,则特征图上实际宽度和高度为。
6. 物体分数和类置信度
物体分数表示一个边界框包含一个物体的概率,对于红色框和其周围的框几乎都为1,但边角的框可能几乎都为0。物体分数也通过一个sigmoid函数,表示概率值。
类置信度表示检测到的物体属于一个具体类的概率值,以前的YOLO版本使用softmax将类分数转化为类概率。在YOLOv3中作者决定使用sigmoid函数取代,原因是softmax假设类之间都是互斥的,例如属于Person就不能表示属于Woman,然而很多情况是这个物体既是Person也是Woman。
7. 不同尺度的预测
为了识别更多的物体,尤其小物体,YOLOv3使用三个不同尺度进行预测(不仅仅只使用13×13)。三个不同尺度步幅分别是32、16和8。这意味着,输入416×416图像,检测尺度分别为13×13、26×26和52×52(如下图或者更详细如图2所示)。
YOLOv3为每种下采样尺度设定3个先验框,总共聚类9个不同尺寸先验框。在COCO数据集上9个先验框,9个先验框分配情况如下表:

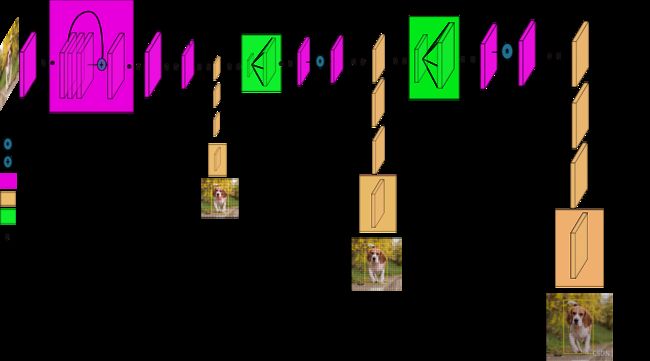
网络降采样输入图像一直到第一个检测层,步幅是32;然后,将此层上采样2倍与上面的同样大小的特征图进行按通道堆叠,第二个检测层按步幅16形成;同样地,相同的上采样过程,最后的检测层步幅为8(详见图2网络步骤)。在每个尺度上,每个cell使用三个锚框预测三个边界框,共9个锚框。所有锚框加起来一共个。

8. 输出处理(在类分数上阈值处理)
我们的网络生成10647个锚框,而图像中只有一个狗,怎么将10647个框减少为1个呢?首先,我们通过物体分数过滤一些锚框,例如低于阈值(假设0.5)的锚框直接舍去;然后,使用NMS(非极大值抑制)解决多个锚框检测一个物体的问题(例如红色框的3个锚框检测一个框或者连续的cell检测相同的物体,产生冗余),NMS用于去除多个检测框。
具体使用以下步骤:抛弃分数低的框(意味着框对于检测一个类信心不大);当多个框重合度高且都检测同一个物体时只选择一个框(NMS)。
为了更方便理解,我们选用上面的汽车图像。首先,我们使用阈值进行过滤一部分锚框。模型有19×19×5×85个数,每个盒子由85个数字描述。将(19,19,5,85)分割为下面的形状:box_confidence:(19×19,5,1)表示19×19个cell,每个cell有5个框,每个框有物体的置信度概率;boxes:(19×19,5,4)表示每个cell的5个框的位置表示;box_class_probs:(19×19,5,80)表示每个cell有5个框,每个框80个类检测概率。
即使通过类分数阈值过滤一部分锚框,还剩下很多重合的框。第二个过程叫NMS,里面有个IoU,如下图所示。
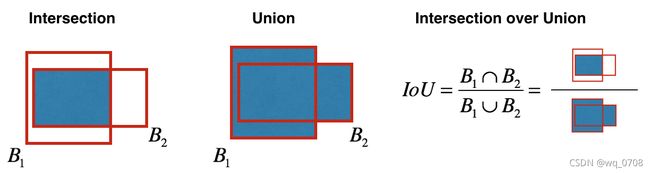
实现非极大值抑制,关键在于:选择一个最高分数的框;计算它和其他框的重合度,去除重合度超过IoU阈值的框;回到步骤1迭代直到没有比当前所选框低的框。

附录
参考
AIR_征服天堂_简书