yolo
目标检测:一类基于Region Proposal的R-CNN系算法(R-CNN,Fast R-CNN,Faster R-CNN),它们是two-stage的,需要先使用启发式方法(selective search)或者CNN网络(RPN)产生Region Proposal,然后再在Region Proposal上做分类与回归。另一类是Yolo,SSD这类one-stage算法,其仅仅使用一个CNN网络直接预测不同目标的类别与位置。第一类方法是准确度高一些,但是速度慢,但是第二类算法是速度快,但是准确性要低一些。
参考yoloV1
Yolo算法的特点:You Only Look Once说的是只需要一次CNN运算,Unified指的是一个统一的框架,提供end-to-end的预测,而Real-Time体现是Yolo算法速度快。
滑动窗口与CNN
滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,实现对整张图片的检测。致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和比例的窗口去滑动,而且还要选取合适的步长。
这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。解决思路之一就是减少要分类的子区域,这就是R-CNN的一个改进策略,其采用了selective search方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率
如果你使用的是CNN分类器,那么滑动窗口是非常耗时的,结合卷积运算的特点,我们可以使用CNN实现更高效的滑动窗口方法。这里要介绍的是一种全卷积的方法,简单来说就是网络中用卷积层代替了全连接层,输入图片大小是16x16,经过一系列卷积操作,提取了2x2的特征图,但是这个2x2的图上每个元素都是和原图是一一对应的,如图上蓝色的格子对应蓝色的区域,这不就是相当于在原图上做大小为14x14的窗口滑动,且步长为2,共产生4个字区域。最终输出的通道数为4,可以看成4个类别的预测概率值,这样一次CNN计算就可以实现窗口滑动的所有子区域的分类预测。

使用卷积运算,将16*16*3的图像,得到2*2*4的特征图(包含信息一样),实现滑动窗口的所有子区域的分类预测。
上面尽管可以减少滑动窗口的计算量,但是只是针对一个固定大小与步长的窗口,这是远远不够的。Yolo算法很好的解决了这个问题,它不再是窗口滑动了,而是直接将原始图片分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图,基于上面的分析,可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来可以预测那些中心点在该小方格内的目标。
YOLOv1
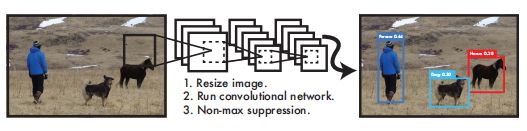
YOLO算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统如下图所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。
- Resize image 2、Run convolutional network 3、Non-max suppression
YOLO的CNN网络将输入的图片分割成,其中前4个表征边界框的大小与位置,而最后一个值是置信度。
输入图片被划分为7*7个单元格,每个单元格独立做检测。
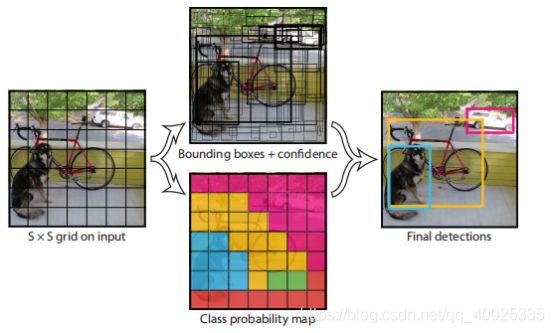
YOLO解决的问题是怎么定位目标、怎么对目标进行分类?
对于每一个单元格其还要给出预测出。边界框 类别 置信度 表征的是该边界框中目标属于各个类别的可能性大小以及边界框匹配目标的好坏。后面会说,一般会根据类别置信度来过滤网络的预测框。
每个单元格需要预测大小的张量。在下面的网络结构中我们会详细讲述每个单元格的预测值的分布位置。
每个网络预测值的依据是什么,或者它根据什么来预测。CNN之后得到图像的特征信息,怎么根据特征信息去定位、分类?
网络设计
YOLO采用卷积网络来提取特征,然后使用全连接层(fully connected layer)得到预测值。
全连接层(fully connected layer):卷积取的是局部特征,全连接就是把以前的局部特征重新通过权值矩阵组装成完整的图。
因为用到了所有的局部特征,所以叫全连接。
BatchNormalization layer:批量归一化
https://blog.csdn.net/myarrow/article/details/51848285
网络结构参考GooLeNet模型,包含24个卷积层和2个全连接层,如图8所示。对于卷积层,主要使用1x1卷积来做channle reduction,然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数:。但是最后一层却采用线性激活函数。除了上面这个结构,文章还提出了一个轻量级版本Fast Yolo,其仅使用9个卷积层,并且卷积层中使用更少的卷积核。
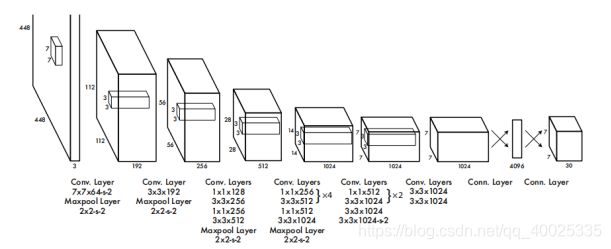
可以看到网络的最后输出为边界框的预测结果,这样提取每个部分是非常方便的,这方面的训练集预测时的计算。Yolov1输出7*7*30的张量,7*7位图像所分的格子数30为 20个类别的概率,box1、box2的置信度,boundingbox(x,y,w,h)。
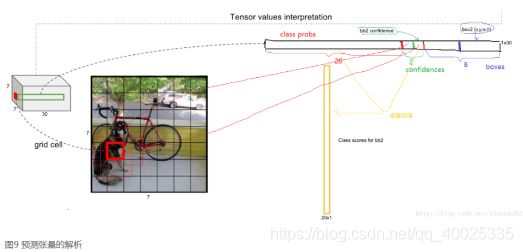
Faster R-CNN那种two-stage复杂的网络结构而言,YOLOv1结构相对简单,基本思想:预测框的位置,大小和物体分类都通过CNN暴力预测、输出7*7*30的张量,代表能预测2个框的5个参数和20个种类。S*S(B*5+C)。深度只有30,意味着每个单元格只能预测两个框(而且只认识20类物体),这对于密集型目标检测和小物体都不能很好适用。
每个小格子怎么判断出该物体呢?换句话说该小格子的特征,怎么能代表整个物体的特征?
YOLO的做法不是把每个单独的网格作为输入feed到模型,在inference的过程中,网络只是物体中心点位置的划分之用,并不是对图片进行切分,不会让网格脱离整个的关系。(中心点为目标定位,而每个小格子会预测两个boudingbox,得到物体的边界框,这就是目标定位问题)
将原始图像分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图。特征图的每个元素也是对应原始图片的一个小方块,然后利用每个元素来预测那些中心点在该小方格内的目标。根据什么特征来预测那个元素是中心点的?预测完中心点后wh即boundingbox怎么预测?
每个cell本身并不知道判断哪个是中心点,而是反过来,根据学习到的特征判断输入网络中图片得到的特征图中哪个元素是 中心点,再根据元素位置找出图像中cell。
边界框怎么预测?物体怎么类别?
网络训练
训练之前,先在ImageNet上进行了预训练,其预训练的分类模型采用图8中前20个卷积层,然后添加一个average-pool层和全连接层。预训练之后,在预训练得到的20层卷积层之上加上随机初始化的4个卷积层和2个全连接层。由于检测任务一般需要更高清的图片,所以将网络的输入从224x224增加到了448x448。
卷积层:采用各种卷积核对输入图片进行卷积处理。(平移不变性)
池化层(average-pool):降采用。(空间不变性)
全连接层:一个神经元在作用于整个slice,即filter的尺寸恰好为一个slice的尺寸。
训练损失函数的分析,Yolo算法将目标检测看成回归问题,所以采用的是均方差损失函数。但是对不同的部分采用了不同的权重值。首先区分定位误差和分类误差。对于定位误差,即边界框坐标预测误差,采用较大的权重。
yolo是端到端训练,对于预测框的位置、size、种类、置信度(score)等信息的预测都通过一个损失函数来训练。
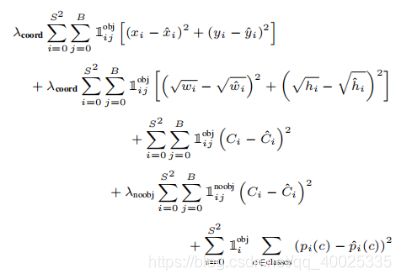
S表示网格数,这里是7*7。B表示每个单元格预测框的个数,这里是2;
第一行总方误差(sum-squared error)来当作位置预测的损失函数,第二行用根号总方误差来当作宽度和高度的损失函数。第三行和第四行对置信度confidence也用SSE作为损失函数。第五行用SSE作类别概率的损失函数。最后将几个损失函数加到一起,当作YOLOv1的损失函数。
由于每个单元格预测多个边界框。但是其对应类别只有一个。那么在训练时,如果该单元格内确实存在目标,那么只选择与ground truth的IOU最大的那个边界框来负责预测该目标,而其它边界框认为不存在目标。这样设置的一个结果将会使一个单元格对应的边界框更加专业化,其可以分别适用不同大小,不同高宽比的目标,从而提升模型性能
如果一个单元格内存在多个目标怎么办,其实这时候Yolo算法就只能选择其中一个来训练,这也是Yolo算法的缺点之一。
要注意的一点时,对于不存在对应目标的边界框,其误差项就是只有置信度,左标项误差是没法计算的。而只有当一个单元格内确实存在目标时,才计算分类误差项,否则该项也是无法计算的。
卷积神经网络相关概念
激活函数
根据一些列的输入值,神经元之间连接的权值以及激励规则,刺激神经元。leaky ReLU,相比普通RelU,leaky并不会让负数直接为0,而是乘以一个很小的系数(恒定),保留负数输出,但衰减负数输出;公式如下:
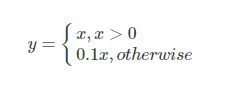
损失函数
在训练阶段,用于评估输出结果和实际值的差异。然后用损失函数的值更新每个神经元之间的权重值。卷积神经网络的训练目的就是最小化损失函数值。
总结
YOLO优点是采用一个CNN网络来实现检测,是单管道策略,其训练与预测都是end-to-end,所以yolo算法比较简单且速度快。第二点yolo是对整个图片做卷积,所以其在检测目标有更大的视野,它不容易对背景误判。全连接层起到attention的作用。另外,YOLO的泛化能力强,在做迁移时,模型鲁棒性高。
YOLO缺点:YOLO各个单元格仅仅预测两个边界框,而且属于一个类别。对于小物体,YOLO表现会不如人意。SSD在这方面做了个改进,采用多尺度单元格。Faster R-CNN,采用anchor boxes。YOLO对于物体在宽高比方面泛化率低,无法定位不寻常比例的物体,其定位不准确也是很大的问题。
图解YOLOv3
图片尺寸:input_shape = [height,width]
Resize 为256*256并除以255进行归一化;
标签预处理:boxes转换 为(x,y,w,h,class)格式得到true_box,x,y,w,h除以图像的input_shape进行归一化;
标签计算:将boxes resize到13*13得到box_output的x,y中心正好落在output的某个grid cell
Box_output中的每个元素box与所有anchors计算IOU,找到IOU最大值对应的anchor。
对每张图偏的每个box