纯纯的爬虫知识,python scrapy 下载中间件知多少
这篇博客咱们聊聊 scrapy 中的 Downloader Middleware ,即下载中间件相关知识。
Downloader Middlerware
首先看一下中间件在 scrapy 数据流中的位置,下图黑色箭头即下载中间件。

结合上图就能看出来, Requests 和 Response 都会通过 Downloader Middlerware,所以在后续代码编写的时候需要注意该点。
中间件的开启非常简单,只需要在 settings.py 文件中去除下述代码的注释即可。
DOWNLOADER_MIDDLEWARES = {
'mid_test.middlewares.MidTestDownloaderMiddleware': 543,
}
其实 settings.py 文件仅仅是一个 scrapy 项目基础配置,除此之外,在 scrapy 框架中还存在一个 default_settings.py 文件,里面的 DOWNLOADER_MIDDLEWARES_BASE 包含更多下载中间件,而且它们是 scrapy 项目启动之后默认加载的,具体如下图所示。
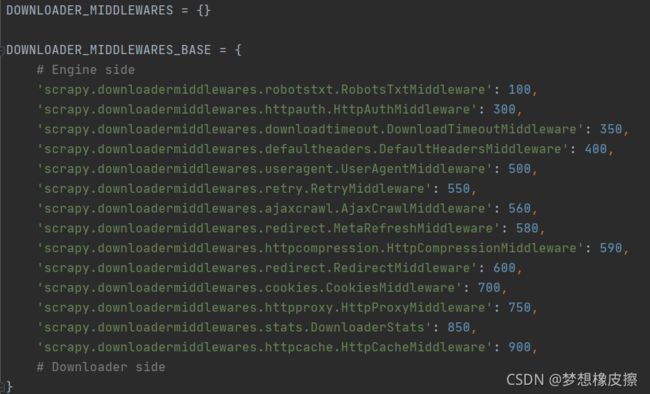 我们在设置
我们在设置 DOWNLOADER_MIDDLEWARES 的时候,需要注意优先级的问题,其原因是在后续编写自定义下载中间件时,存在 1 个 process_request() 方法和 1 个 process_response() 方法,它们会按照优先级对中间件进行排序,并按照顺序进行中间的调用。
还有一点要注意的是,如果你想要屏蔽掉 DOWNLOADER_MIDDLEWARES_BASE 中设置的中间件,需要在 DOWNLOADER_MIDDLEWARES 中给其赋值为 None 才可以,例如下述代码将屏蔽 RobotsTxtMiddleware 中间件。
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': None,
}
自定义下载中间件的相关知识
本次案例编写使用的网站是 http://httpbin.org ,该站点可以直接返回请求头相关参数,测试起来非常方便。
正式编写代码前在 settings.py 文件中增加添加一个新的字段,便于输出打印日志(屏蔽了一些调试日志的输出)。
LOG_LEVEL = 'WARNING'
编写自己的下载中间件
默认请求代码如下所示,返回数据在代码下方。
import scrapy
class HbinSpider(scrapy.Spider):
name = 'hbin'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/get']
def parse(self, response):
print(response.text)
请求目标站点之后,得到的返回数据如下所示:
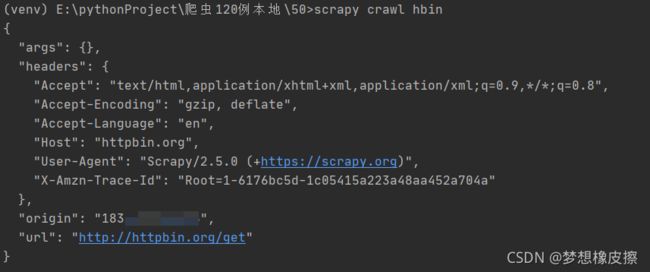
接下来启用中间件,然后将请求相关参数进行修改,主要操作的文件是 middlewares.py,并且要实现其中的 process_request(),process_response(),process_exception(),spider_opened() 方法(可以仅实现一部分)。
process_request(request, spider)
通过下载中间件的每个请求,都会调用该方法。
本方法返回值必须是 None,Response 对象,Request 对象或者 IgnoreRequest 错误。
- 返回
None:没啥影响,其它的请求继续处理完毕; - 返回
Response:直接去调用process_response()方法去; - 返回
Request:将新的 Request 加入调度队列; - 返回
IgnoreRequest:process_exception()方法被执行。
下面编写一个 UserAgentMiddlerware 中间件,替换默认中间件的同时实现自己的代理设置。
在 middlewares.py 文件中添加如下代码
class UserAgentMiddleware(object):
def process_request(self, request, spider):
request.headers.setdefault('User-Agent',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36')
return None
在 settings.py 文件中添加如下代码
DOWNLOADER_MIDDLEWARES = {
'mid_test.middlewares.UserAgentMiddleware': 543, # 配置自己的中间件,可以修改名称为 MyUserAgentMiddleware
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':None # 覆盖配置
}
如果没有覆盖原配置,会发现我们编写的中间件优先级不如 UserAgentMiddleware 高,即下图加载顺序。
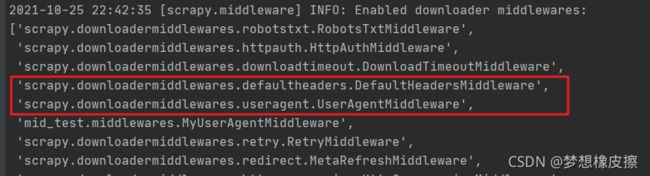
process_response(request, response, spider)
该方法可下载中间件在返回响应数据时,进行一些数据处理,它默认返回的是 response 对象,也可以返回 request 对象,逻辑与 process_request() 方法基本一致。
class MyUserAgentMiddleware(object):
def process_request(self, request, spider):
request.headers.setdefault('User-Agent',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36')
return None
def process_response(self, request, response, spider):
print(response) # 单纯输出一下 response
return response
process_exception(request, exception, spider)
用于处理异常,默认返回 None,也可以返回 Response 对象和 Request 对象。
一般场景都是返回 Request 对象,当出现异常时,可以重新发起请求。
内置的下载中间件
通过 scrapy 命令行可以查看所有的内置中间件。
> scrapy settings --get DOWNLOADER_MIDDLEWARES_BASE
按照优先级依次为大家介绍一下。
RobotsTxtMiddleware
查看该中间件源码了解到,当 settings.py 文件中的 ROBOTSTXT_OBEY 被设置为 True 时,尊重 robots.txt 协议。
HttpAuthMiddleware
HTTP 认证,核心逻辑如下所示:
def spider_opened(self, spider):
usr = getattr(spider, 'http_user', '')
pwd = getattr(spider, 'http_pass', '')
if usr or pwd:
self.auth = basic_auth_header(usr, pwd)
def process_request(self, request, spider):
auth = getattr(self, 'auth', None)
if auth and b'Authorization' not in request.headers:
request.headers[b'Authorization'] = auth
DownloadTimeoutMiddleware
设置请求的超时时间,需要配置 settings.py 文件中的 DOWNLOAD_TIMEOUT 值,然后手动给 meta 中 download_timeout 参数赋值。
def process_request(self, request, spider):
if self._timeout:
request.meta.setdefault('download_timeout', self._timeout)
DefaultHeadersMiddleware
设置 DEFAULT_REQUEST_HEADERS 指定的默认请求头。
UserAgentMiddleware
请求的用户代理设置。
RetryMiddleware
请求重试次数。
MetaRefreshMiddleware 与 RedirectMiddleware
以上 2 个中间件都继承自 BaseRedirectMiddleware,都与重定向有关系。
HttpCompressionMiddleware
提供了对压缩(gzip, deflate)数据的支持。
CookiesMiddleware
Cookie 相关能力的支持。
HttpProxyMiddleware
代理相关设置。
DownloaderStats
下载中间件的统计信息。
HttpCacheMiddleware
为所有 HTTP 请求和响应提供低级缓存。
本篇博客内容属于 scrapy 知识铺垫,并且部分知识点在后续博客中会反复用到,请掌握。
写在后面
今天是持续写作的第 253 / 365 天。
期待 关注,点赞、评论、收藏。
更多精彩
《爬虫 100 例,专栏销售中,买完就能学会系列专栏》
