1. Quartz
Quartz是由OpenSymphony提供的强大的开源任务调度框架,用来执行定时任务。比如每天凌晨三点钟需要从数据库导出数据,这时候就需要一个任务调度框架,帮我们自动去执行这些程序。那Quartz是怎样实现的呢?
1)首先我们需要定义一个运行业务逻辑的接口,即Job,我们的类继承这个接口来实现业务逻辑,比如凌晨三点读取数据库并且导出数据。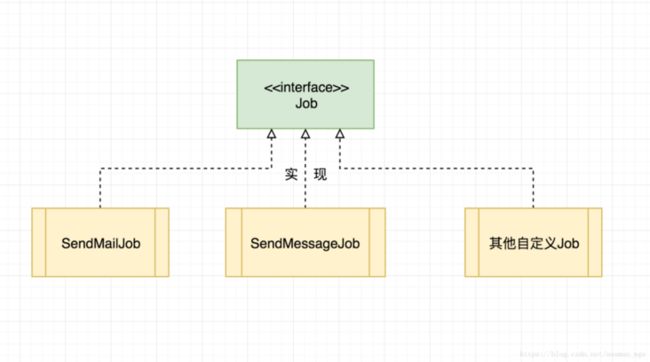
2)有了Job之后需要按时执行这个Job,这就需要一个触发器Trigger,触发器Trigger就是按照我们的要求在每天凌晨三点执行我们定义的Job。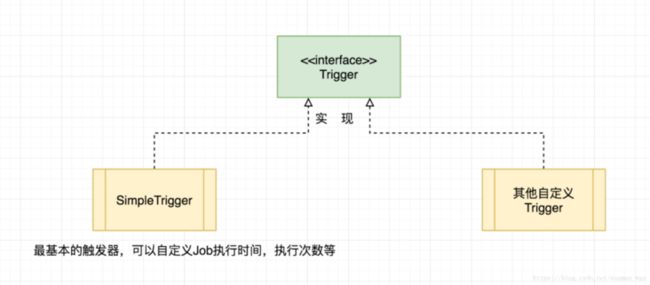
3)有了任务Job和触发器Trigger后,就需要把它们结合起来,让触发器Trigger在规定的时间调用Job,这时需要一个Schedule来实现这个功能。
所以,Quartz主要有三个部分组成:
调度器:Scheduler
任务:JobDetail
触发器:Trigger,包括SimpleTrigger和CronTrigger
创建一个Quartz任务的流程如下:
//定义一个作业类,实现用户的业务逻辑
public class HelloJob implements Job {
......
实现业务逻辑
}
//根据作业类得到JobDetail
JobDetail jobDetail = JobBuilder.newJob(HelloJob.class)
//定义一个触发器,按照规定的时间调度作业
Trigger trigger = TriggerBuilder.newTrigger("每隔1分钟执行一次")
//根据作业类和触发器创建调度器
Scheduler scheduler = scheduler.scheduleJob(jobDetail,trigger);
//启动调度器,开始执行任务
scheduler .start()2. Elastic-Job的基本原理
2.1 分片
Elastic-Job为了提高任务的并发能力,引入了分片的概念,即将一个任务划分成多个分片,然后由多个执行的机器分别领取这些分片来执行。比如一个数据库中有1亿条数据,需要将这些数据读取出来并计算,然后再写入到数据库中。就可以将这1亿条数据划分成10个分片,每一个分片读取其中的1千万条数据,然后计算后写入数据库。这10个分片编号为0,1,2...9,如果有三台机器执行,A机器分到分片(0,1,2,9),B机器分到分片(3,4,5),C机器分到分片(6,7,8) 。
2.2 作业调度与执行
Elastic-Job是去中心化的任务调度框架,当多个节点运行时,会先选择一个主节点,当到达执行时间后,每个实例开始执行任务,主节点负责分片的划分,其它节点等待划分完成,主节点将划分后的结果存放到zookeeper中,然后每个节点再从zookeeper中获取划分好的分片项,将分片信息作为参数,传入到本地的任务函数中,从而执行任务。
2.3 作业的类型
elastic-job支持三种类型的作业任务处理!
Simple 类型作业:Simple 类型用于一般任务的处理,只需实现SimpleJob接口。该接口仅提供单一方法用于覆盖,此方法将定时执行,与Quartz原生接口相似。
Dataflow 类型作业:Dataflow 类型用于处理数据流,需实现DataflowJob接口。该接口提供2个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数据。
Script类型作业:Script 类型作业意为脚本类型作业,支持 shell,python,perl等所有类型脚本。只需通过控制台或代码配置 scriptCommandLine 即可,无需编码。执行脚本路径可包含参数,参数传递完毕后,作业框架会自动追加最后一个参数为作业运行时信息。
3. Elastic-Job的执行原理
3.1 Elastic-Job的启动流程
下面以一个SimpleJob类型的任务来说明elastic-job的启动流程
public class MyElasticJob implements SimpleJob {
public void execute(ShardingContext context) {
//实现业务逻辑
......
}
// 对zookeeper进行设置,作为分布式任务的注册中心
private static CoordinatorRegistryCenter createRegistryCenter() {
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(new ZookeeperConfiguration("xxxx"));
regCenter.init();
return regCenter;
}
//设置任务的执行频率、执行的类
private static LiteJobConfiguration createJobConfiguration() {
JobCoreConfiguration simpleCoreConfig = JobCoreConfiguration.newBuilder("demoSimpleJob", "0/15 * * * * ?", 10).build();
// 定义SIMPLE类型配置
SimpleJobConfiguration simpleJobConfig = new SimpleJobConfiguration(simpleCoreConfig, MyElasticJob.class.getCanonicalName());
// 定义Lite作业根配置
LiteJobConfiguration simpleJobRootConfig = LiteJobConfiguration.newBuilder(simpleJobConfig).build();
return simpleJobRootConfig;
}
//主函数
public static void main(String[] args) {
new JobScheduler(createRegistryCenter(), createJobConfiguration()).init();
}
}创建一个Elastic-Job的任务并执行,步骤如下:
1)需要先设置zookeeper的基本信息,Elastic-Job使用zookeeper来进行分布式管理,如选主、元数据存储与读取、分布式监听机制等。
2)创建一个执行任务的Job类,以Simple 类型作业为例,创建一个继承SimpleJob的类,在这个类中实现execute函数。
3)设置作业的基本信息,在JobCoreConfiguration 中设置作业的名称(jobName),作业执行的时间表达式(cron),总的分片数(shardingTotalCount);然后在SimpleJobConfiguration 中设置执行作业的Job类,最后定义Lite作业根配置。
4)创建JobScheduler(作业调度器)实例,然后JobScheduler的init()方法中执行作业的初始化,这样作业就开始运行了。
Elastic-Job的作业调度在JobScheduler中完成,下面详细介绍JobScheduler方法。JobScheduler的定义如下:
public class JobScheduler {
public static final String ELASTIC_JOB_DATA_MAP_KEY = "elasticJob";
private static final String JOB_FACADE_DATA_MAP_KEY = "jobFacade";
//作业配置
private final LiteJobConfiguration liteJobConfig;
//注册中心
private final CoordinatorRegistryCenter regCenter;
//调度器门面
private final SchedulerFacade schedulerFacade;
//作业门面
private final JobFacade jobFacade;
private JobScheduler(final CoordinatorRegistryCenter regCenter, final LiteJobConfiguration liteJobConfig, final JobEventBus jobEventBus, final ElasticJobListener... elasticJobListeners) {
JobRegistry.getInstance().addJobInstance(liteJobConfig.getJobName(), new JobInstance());
this.liteJobConfig = liteJobConfig;
this.regCenter = regCenter;
List elasticJobListenerList = Arrays.asList(elasticJobListeners);
setGuaranteeServiceForElasticJobListeners(regCenter, elasticJobListenerList);
schedulerFacade = new SchedulerFacade(regCenter, liteJobConfig.getJobName(), elasticJobListenerList);
jobFacade = new LiteJobFacade(regCenter, liteJobConfig.getJobName(), Arrays.asList(elasticJobListeners), jobEventBus);
} 如上,在JobScheduler的构造方法中,设置好作业配置信息liteJobConfig、注册中心regCenter、一系列监听器elasticJobListenerList ,调度器门面,作业门面。
在创建好JobScheduler实例后,就进行作业的初始化操作,如下:
/**
* 初始化作业.
*/
public void init() {
JobRegistry.getInstance().setCurrentShardingTotalCount(liteJobConfig.getJobName(), liteJobConfig.getTypeConfig().getCoreConfig().getShardingTotalCount());
JobScheduleController jobScheduleController = new JobScheduleController(createScheduler(), createJobDetail(liteJobConfig.getTypeConfig().getJobClass()), liteJobConfig.getJobName());
JobRegistry.getInstance().registerJob(liteJobConfig.getJobName(), jobScheduleController, regCenter);
schedulerFacade.registerStartUpInfo(liteJobConfig);
jobScheduleController.scheduleJob(liteJobConfig.getTypeConfig().getCoreConfig().getCron());
}如上,
1)JobRegistry是作业注册表,以单例的形式存储作业的元数据,在JobRegistry中设置好分片总数等信息。
2)jobScheduleController是作业调度控制器,在jobScheduleController中可以执行:调度作业、重新调度作业、暂停作业、恢复作业、立刻恢复作业。所以作业的开始、暂停、恢复都是在jobScheduleController中执行的。
3)在作业注册表JobRegistry中设置作业名称、作业调度器、注册中心。
4)执行调度器门面schedulerFacade的registerStartUpInfo方法,在这个方法中注册作业启动信息,代码如下:
/**
* 注册作业启动信息.
*
* @param liteJobConfig 作业配置
*/
public void registerStartUpInfo(final LiteJobConfiguration liteJobConfig) {
regCenter.addCacheData("/" + liteJobConfig.getJobName());
// 开启所有监听器
listenerManager.startAllListeners();
// 选举主节点
leaderService.electLeader();
//持久化job的配置信息
configService.persist(liteJobConfig);
LiteJobConfiguration liteJobConfigFromZk = configService.load(false);
// 持久化作业服务器上线信息
serverService.persistOnline(!liteJobConfigFromZk.isDisabled());
// 持久化作业运行实例上线相关信息,将服务实例注册到zk
instanceService.persistOnline();
// 设置 需要重新分片的标记
shardingService.setReshardingFlag();
// 初始化 作业监听服务
monitorService.listen();
// 初始化 调解作业不一致状态服务
if (!reconcileService.isRunning()) {
reconcileService.startAsync();
}
}如上,
1)开启所有的监听器,利用zookeeper的watch机制来监听系统中各种元数据的变化,从而执行相应的操作
2)选举主节点,利用zookeeper的分布式锁来选择一个主节点,主节点主要进行分片的划分。
3)持久化各种元数据到zookeeper,如作业的配置信息,每个服务实例的信息等
4)设置需要分片的标志,在第一次执行任务或者系统中服务实例增减时都需要重新分片。
在作业启动信息注册好以后,就调用jobScheduleController的scheduleJob方法,进行作业的调度,这样作业就开始执行了。scheduleJob方法的代码如下:
/**
* 调度作业.
*
* @param cron CRON表达式
*/
public void scheduleJob(final String cron) {
try {
if (!scheduler.checkExists(jobDetail.getKey())) {
scheduler.scheduleJob(jobDetail, createTrigger(cron));
}
scheduler.start();
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
}通过前面Quartz的讲解可知,scheduler通过将jobDetail和触发器Trigger结合,再调用scheduler.start(),这样就开始了作业调用。
通过上面的代码分析可知。作业的启动流程如下:
3.2 Elastic-Job的执行流程
通过前面Quartz的讲解可知,任务的执行实际是运行JobDetail中定义的业务逻辑,我们只需要看jobDetail里面的内容,就能知道作业执行的过程
private JobDetail createJobDetail(final String jobClass) {
JobDetail result = JobBuilder.newJob(LiteJob.class).withIdentity(liteJobConfig.getJobName()).build();
//忽略其它代码
}通过上面的代码可知,执行的任务就是LiteJob这个类的内容
public final class LiteJob implements Job {
@Setter
private ElasticJob elasticJob;
@Setter
private JobFacade jobFacade;
@Override
public void execute(final JobExecutionContext context) throws JobExecutionException {
JobExecutorFactory.getJobExecutor(elasticJob, jobFacade).execute();
}
}LiteJob 通过 JobExecutorFactory 获得到作业执行器( AbstractElasticJobExecutor ),并进行执行:
public final class JobExecutorFactory {
/**
* 获取作业执行器.
*
* @param elasticJob 分布式弹性作业
* @param jobFacade 作业内部服务门面服务
* @return 作业执行器
*/
@SuppressWarnings("unchecked")
public static AbstractElasticJobExecutor getJobExecutor(final ElasticJob elasticJob, final JobFacade jobFacade) {
// ScriptJob
if (null == elasticJob) {
return new ScriptJobExecutor(jobFacade);
}
// SimpleJob
if (elasticJob instanceof SimpleJob) {
return new SimpleJobExecutor((SimpleJob) elasticJob, jobFacade);
}
// DataflowJob
if (elasticJob instanceof DataflowJob) {
return new DataflowJobExecutor((DataflowJob) elasticJob, jobFacade);
}
throw new JobConfigurationException("Cannot support job type '%s'", elasticJob.getClass().getCanonicalName());
}
}可见,作业执行器工厂JobExecutorFactory ,根据不同的作业类型,返回对应的作业执行器,然后执行对应作业执行器的execute()函数。下面看一下execute函数
// AbstractElasticJobExecutor.java
public final void execute() {
// 检查作业执行环境
try {
jobFacade.checkJobExecutionEnvironment();
} catch (final JobExecutionEnvironmentException cause) {
jobExceptionHandler.handleException(jobName, cause);
}
// 获取当前作业服务器的分片上下文
ShardingContexts shardingContexts = jobFacade.getShardingContexts();
// 发布作业状态追踪事件(State.TASK_STAGING)
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(shardingContexts.getTaskId(), State.TASK_STAGING, String.format("Job '%s' execute begin.", jobName));
}
// 跳过存在运行中的被错过作业
if (jobFacade.misfireIfRunning(shardingContexts.getShardingItemParameters().keySet())) {
// 发布作业状态追踪事件(State.TASK_FINISHED)
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(shardingContexts.getTaskId(), State.TASK_FINISHED, String.format(
"Previous job '%s' - shardingItems '%s' is still running, misfired job will start after previous job completed.", jobName,
shardingContexts.getShardingItemParameters().keySet()));
}
return;
}
// 执行作业执行前的方法
try {
jobFacade.beforeJobExecuted(shardingContexts);
//CHECKSTYLE:OFF
} catch (final Throwable cause) {
//CHECKSTYLE:ON
jobExceptionHandler.handleException(jobName, cause);
}
// 执行普通触发的作业
execute(shardingContexts, JobExecutionEvent.ExecutionSource.NORMAL_TRIGGER);
// 执行被跳过触发的作业
while (jobFacade.isExecuteMisfired(shardingContexts.getShardingItemParameters().keySet())) {
jobFacade.clearMisfire(shardingContexts.getShardingItemParameters().keySet());
execute(shardingContexts, JobExecutionEvent.ExecutionSource.MISFIRE);
}
// 执行作业失效转移
jobFacade.failoverIfNecessary();
// 执行作业执行后的方法
try {
jobFacade.afterJobExecuted(shardingContexts);
//CHECKSTYLE:OFF
} catch (final Throwable cause) {
//CHECKSTYLE:ON
jobExceptionHandler.handleException(jobName, cause);
}
}execute函数的主要流程:
- 检查作业执行环境
- 获取当前作业服务器的分片上下文。即通过函数jobFacade.getShardingContexts()获取当前的分片信息,由主节点根据相应的分片策略来进行分片项的划分,划分好之后将划分结果存入到zookeeper中,其它节点再从zookeeper中获取划分结果。
- 发布作业状态追踪事件
- 跳过正在运行中的被错过执行的作业
- 执行作业执行前的方法
- 执行普通触发的作业
最后,会调用MyElasticJob中的execute方法,从而达到执行用户业务逻辑的目的。
整个Elastic-Job的执行流程如下: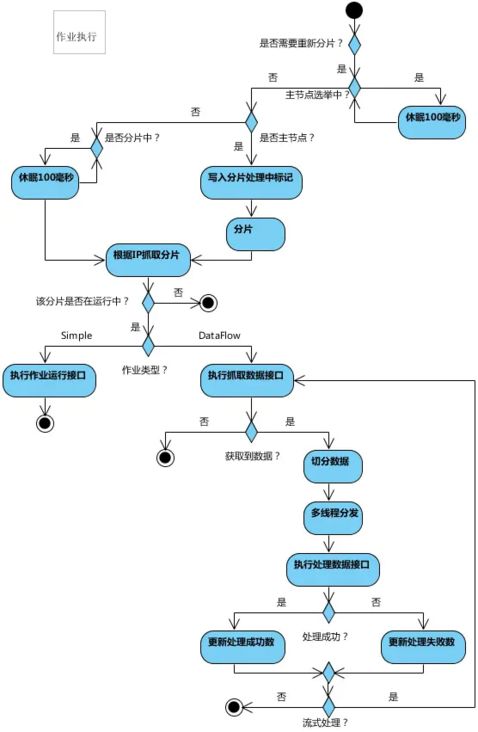
4. Elastic-Job的优化实践
4.1 空转问题
Elastic-Job的作业按照是否有实现类可以分为两种:有实现类的作业和没有实现类的作业。如Simple类型和DataFlow类型的作业需要用户自己定义实现类,继承SimpleJob或者DataFlowJob类;另一种是不需要实现类的作业,如Script类型作业和Http类型作业,对应这种不需要实现类的作业,用户只需要在配置平台填写好相应的配置,我们后台再定时的从配置平台拉取最新注册的任务,然后就可以执行用户最新注册的script或者Http类型的作业。
在生产环境中,执行作业的集群的机器数量很多,但是用户注册的每个作业的分片却很少(大部分只有1个分片),根据前面的分析可知,对应只有一个分片的任务,集群中的所有机器都会参与运行,但是由于只有得到那个分片的机器才会真正运行,其余的都会因为没有分片而空转,这无疑是对计算资源的浪费。
4.2 解决方案
为了解决分片数量少、执行服务器多而出现的空转问题,我们这边的解决方案是用户在配置平台注册任务时,指定好对应的执行服务器,执行服务器的数量M=分片数+1(多出来的机器作为冗余备份)。如用户的作业分片为2, 后台根据每天机器当前的负载排序,选择3台负载最轻的机器作为执行服务器。这样当这些机器定时从配置平台拉取任务时,如果发现自己不属于这个任务的执行服务器,就不运行这个作业,只有属于当前任务的执行服务器才运行。这样既保证了可靠性,又避免了过多机器的空转,提高了效率。
5. OPPO海量作业调度方案
Elastic-Job通过zookeeper来实现弹性分布式的功能,这在任务量很小的时候可以满足用户需求,但是也有以下缺点:
- Elastic-Job的弹性分布式功能强依赖zookeeper,zookeeper容易成为性能瓶颈。
- 任务划分的分片数可能小于执行任务的实例数,导致一些机器空转。
基于Elastic-Job的上述缺点,OPPO中间件团队在处理海量任务调度时,采用了集中式的调度方案,用户的作业不需要通过Quartz来定时触发,而是通过接收服务器的消息来触发本地任务。用户先在注册平台注册任务,服务器定时从注册平台的数据库中扫描最近一个周期(30秒)内需要执行的任务,再根据任务的实际执行时间生成延时消息并写入具有延时功能的消息队列,用户再从消息队列中拉取数据并触发作业的执行。这种集中式的调度方式由中心服务器来触发消息执行,既克服了zookeeper的性能瓶颈,又避免了任务服务器的空转,能够满足海量任务的执行要求。
总结
Elastic-Job使用quartz来进行作业的调度,同时引入zookeeper来实现分布式管理的功能,在高可用方案的基础上增加了弹性扩容和数据分片的思路,以便于更大限度的利用分布式服务器的资源从而实现了分布式任务调度的功能。同时由于分片的思路,也会导致没有得到分片的服务器处于空转的状态,这在实际的生产中可以设法规避。
作者简介
Xinchun OPPO高级后端工程师
目前负责分布式作业调度的研发,关注消息队列、redis数据库、ElasticSearch等中间件技术。
获取更多精彩内容,扫码关注[OPPO数智技术]公众号