【学习笔记2】深度学习框架TensorFlow及MNIST应用
一.TensorFlow框架介绍
1.TensorFlow输入张量
TensorFlow,Tensor(张量)表示N维数组,Flow(流)表示基于数据流图的计算。我通过MNIST机器学习来解释预测数字模型。
首先,有一个MNIST数据集,每一个MNIST数据单元有一张手写数字的图片和一个对应的标签(特征),将图片设为“xs”,标签设为“ys”。MNIST数据集拥有60 000行训练数据集(mnist.train)【训练模型用】和10 000行的测试数据集(mnist.test)【测试模型用】。

每张图片包含28*28像素点,通过一个数字数组来表示这张图片:把这个数组展开成一个向量,长度是784。在MNIST训练数据集中,mnist.train.images(训练数集中的图片)是一个[60000 , 784]的张量(前数量 后像素),排列后形成这样的情况↓

第一个维度的数字用来对应每张图片,第二个维度数字用来索引每张图片的像素点,在此张量里的每一个元素,都表示为某张图片里的每个像素的介于0和1之间的强度值。
对应的标签是0到9的数字,用来描述给定图片里表示的数字,每个数字对应相应位置1,如标签0表示为[1,0,0,0,0,0,0,0,0,0],因此mnist.train.labels是一个[60000,10]的数字矩阵。
上述的两个数组都是二维数组,也是Tensorflow的张量数据,这些数据以流的形式进入数据运算的各个节点。
2.TensorFlow代码框架
tf能够运行在个人计算机或服务器的单个或多个CPU和GPU上,移动设备也可以(只要算力支持)。还是从MNIST机器学习来分析tf的框架。
首先,要构建一个计算的过程,MNIST用到的核心算法是softmax回归算法,通过对已知训练数据同个标签的像素加权平均,来构建出每个标签在不同像素点上的权值。
若这个像素点具有有利的证据说明这张图品不属于这类,那么相应的权值为负数,若属于,权值为正。
因为输入会有一些无关的干扰量,于是加入一个额外的偏置量(bias),因此对于给定的输入图片 x 是数字 i 的证据,可以表示为:

Wij表示权值矩阵,Xj为给定图片的像素点,bi代表数字 i 类的偏置量。
这里可以得到一个计算出一个图片对应每个标签的概率大小的计算方式。
建立好一个算法模型之后,为了适应所有的图片输入,权重和偏置值不通过不断学习修改变量值。
TensorFlow 在这一步就是在后台给描述计算的那张图里面增添一系列新的计算操作单元用来实现反向传播算法和梯度下降算法。它返回一个单一的操作,当运行这个操作时,可以用梯度下降算法来训练模型,微调变量,不断减少成本,从而建立好一个基本模型。
之后,创建一个会话(Session),循环1000次,每次批处理100个数据训练。
TensorFlow 通过数据输入( Feeds) 将张量数据输入至模型中,而张量 Tensor 就像数据流一样流过每个计算节点,微调变量,使得模型更加准确。
因此,框架结构大致:
①.对于输入的计算过程在后台设计计算逻辑
②.创建会话提交计算图
③.用Feed输入训练的张量数据
④.tf在后台增加计算操作单元用于训练模型并微调
⑤.完成模型并测试
二.TensorFlow基本使用
1.打印输出
#tf2.0版本
import tensorflow.compat.v1 as tf
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
hello = tf.constant('Hello, TensorFlow!')
sess= tf.compat.v1.Session() # 建立一个session
print (sess.run(hello)) # 通过session里面的run来运行结果
sess.close()
# 打印出 Hello tensorflow tf1.0版本
#import tensorflow as tf
#hello = tf.constant('Hello, TensorFlow!')
#sess = tf.Session() # 建立一个session
#print (sess.run(hello)) # 通过session里面的run来运行结果
#sess.close()
这里多说几句,下面注释掉的代码是华为沙盒给的代码,但就会出现【AttributeError: module ‘tensorflow’ has no attribute 'Session’错误】,原因是Tensorflow 2.0版本中已经移除了Session这一模块,然而我又懒得降版本,查阅后修改如上。
tf.compat.v1.disable_eager_execution() #新增一行
2.基本运算
#tf2.0版本
import tensorflow.compat.v1 as tf
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
a = tf.constant(3) # 定义常量3
b = tf.constant(4) # 定义常量4
with tf.compat.v1.Session() as sess: # 建立session
print("相加: %i" % sess.run(a + b)) # 计算输出两个变量相加的值
print("相乘: %i" % sess.run(a * b)) # 计算输出两个变量相乘的值
3.定义变量
做到这里,实在背不住装了tf1.14,有机会好好研究下tf2.0去掉会话等模块的原因,降版本方法参考:https://blog.csdn.net/qq_42827473/article/details/106482602
# 定义变量
var1 = tf.Variable(10.0 , name="varname")
var2 = tf.Variable(11.0 , name="varname")
var3 = tf.Variable(12.0 )
var4 = tf.Variable(13.0 )
with tf.variable_scope("test1" ):
var5 = tf.get_variable("varname",shape=[2],dtype=tf.float32)
with tf.variable_scope("test2"):
var6 = tf.get_variable("varname",shape=[2],dtype=tf.float32)
print("var1:",var1.name)
print("var2:",var2.name)
print("var3:",var3.name)
print("var4:",var4.name)
print("var5:",var5.name)
print("var6:",var6.name)
三.基于全连接神经网络的手写数字识别
这里不采用华为沙盒给的代码,原因是里面大量引用了MoX的api,MoXing是华为云深度学习服务提供的网络模型开发API,移植到pycharm比较麻烦。
"""
基于TensorFlow的MNIST手写体数字识别
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# MNIST 数据集相关的常数
INPUT_NODE = 784 # 输入层为28*28的像素
OUTPUT_NODE = 10 # 输出层0~9有10类
# 配置神经网络的参数
LAYER1_NODE = 500 # 隐藏层节点数
BATCH_SIZE = 100 # batch的大小
LEARNING_RATE_BASE = 0.8 # 基础的学习率
LEARNING_RATE_DECAY = 0.99 # 学习率的衰减率
REGULARIZATION_RATE = 0.0001 # 正则化项的系数
TRAINING_STEPS = 30000 # 训练轮数
MOVING_AVERAGE_DECAY = 0.99 # 滑动平均的衰减率
# 定义神经网络的结构
def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2):
# 当没有提供滑动平均类时,直接使用参数当前的值
if avg_class == None:
# 计算隐藏层的前向传播结果,ReLU激活函数
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
# 计算输出层的前向传播结果(计算损失函数时,会一并进行softmax运输,在这里不进行softmax回归)
return tf.matmul(layer1, weights2) + biases2
else:
# 需要先使用滑动平均值计算出参数
layer1 = tf.nn.relu(tf.matmul(input_tensor, avg_class.average(weights1)) + avg_class.average(biases1))
return tf.matmul(layer1, avg_class.average(weights2)) + avg_class.average(biases2)
# 定义训练模型的操作
def train(mnist):
x = tf.placeholder(tf.float32, [None, INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name='y-input')
# 生成隐藏层的参数
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
# 生成输出层的参数
weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
# 定义计算当前参数下,神经网络前向传播的结果。
y = inference(x, None, weights1, biases1, weights2, biases2)
# 定义存储训练轮数的变量
global_step = tf.Variable(0, trainable=False)
# 初始化滑动平均对象
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
# 定义滑动平均的操作
variable_averages_op = variable_averages.apply(tf.trainable_variables())
# 定义计算使用了滑动平均之后的前向传播结果
average_y = inference(x, variable_averages, weights1, biases1, weights2, biases2)
# 损失函数
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(y_, 1), logits=y)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# L2
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
regularization = regularizer(weights1) + regularizer(weights2)
loss = cross_entropy_mean + regularization
# 学习率
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step, mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY)
# 优化算法
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# 训练的操作
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
# 检验 准确度
correct_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
tf.global_variables_initializer().run()
# 准备数据
validate_feed = {
x: mnist.validation.images, y_: mnist.validation.labels}
test_feed = {
x: mnist.test.images, y_: mnist.test.labels}
# 迭代的训练神经网络
for i in range(TRAINING_STEPS):
# 每1000轮,使用验证数据测试一次
if i % 1000 == 0:
validate_acc = sess.run(accuracy, feed_dict=validate_feed)
print("After %d training step(s), validation accuracy "
"using average model is %g " % (i, validate_acc))
# 训练的数据
xs, ys = mnist.train.next_batch(BATCH_SIZE)
sess.run(train_op, feed_dict={
x: xs, y_: ys})
# 测试最终的准确率
test_acc = sess.run(accuracy, feed_dict=test_feed)
print("After %d training step(s), test accuracy using average model is %g " % (TRAINING_STEPS, test_acc))
# 主程序入口
def main(argv=None):
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()
对代码进行拆解分析。
BATCH_SIZE = 100 # batch的大小
Batch_Size(批尺寸) 是机器学习中一 个重要参数,Batch的选择,首先决定的是下降的方向,如果数据集表较小,可以选择全数据集的形式( Full Batch Learning )。
这样做至少有两个好处:①.由全数据集确定的方向能够更好代表样本总体,从而更准确地朝向极值所在的方向;②.由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。
更大的数据集不建议采取全数据集的形式,内存不足以支持一次性载入所有数据。
同样有在线学习(Online Learning),就是每次只训练一个样本,即 Batch_Size = 1,线性神经元在均方误差代价函数的错误面是一个抛物面,使用在线学习会使得每次修正方向以各自样本的梯度方向修正,难以收敛。
于是,一般采用批梯度下降法(Mini-batches Learning),如果数据集足够充分,那么用一半(甚至更少)的数据训练算出来的梯度与用全部数据训练出来的梯度几乎一样。
因此,要通过不断尝试,找到Batch_Size的最优值,达到最终收敛精度上的最优。
LEARNING_RATE_BASE = 0.8 # 基础的学习率
LEARNING_RATE_DECAY = 0.99 # 学习率的衰减率
REGULARIZATION_RATE = 0.0001 # 正则化项的系数
TRAINING_STEPS = 30000 # 训练轮数
MOVING_AVERAGE_DECAY = 0.99 # 滑动平均的衰减率
学习率: 在梯度下降的过程中更新权重时的超参数。学习率越低,损失函数的变化速度就越慢,容易过拟合,虽然使用低学习率可以确保我们不会错过任何局部极小值,但也意味着我们将花费更长的时间来进行收敛,特别是在被困在局部最优点的时候,学习率过高容易发生梯度爆炸,Loss振动幅度较大,模型难以收敛。
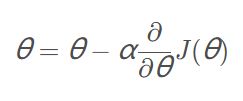
一般情况下,我们会选择0.01-0.1,但在本实验中,学习率在0.8-0.9时识别率会达到最高。
学习率的衰减率: 随时间慢慢减少学习率来加快学习算法,减少学习率的本质在于,学习初期能够有足够样本训练,当开始收敛时,学一些的学习率能有助于收敛。
正则项系数(regularization parameter, λ): 正则化是一种为了减小测试误差的行为(有时候会增加训练误差)。我们在构造机器学习模型时,最终目的是让模型在面对新数据的时候,可以有很好的表现。当你用比较复杂的模型比如神经网络,去拟合数据时,很容易出现过拟合现象(训练集表现很好,测试集表现较差),这会导致模型的泛化能力下降,这时候,我们就需要使用正则化,降低模型的复杂度。
至于怎么定值纯属玄学,有个博主有一段话,可以参考。
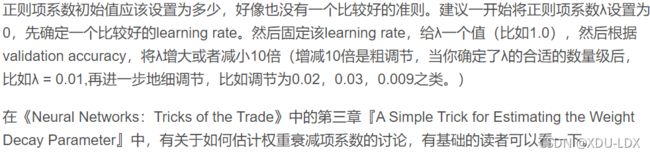
资料参考:
https://www.zhihu.com/question/32673260
https://www.jianshu.com/p/569efedf6985
https://blog.csdn.net/u012162613/article/details/44265967