Docker学习
Docker学习笔记
文章目录
- Docker学习笔记
- Docker介绍
-
-
- Docker简介
- Docker架构与内部组件
- Docker有什么优点
- 虚拟机与容器区别
- 底层原理
-
- Docker安装
-
-
- 安装Docker
- 阿里云镜像加速
- 设置开机自动启动
- 查看docker服务状态
- 查看docker具体信息
-
- 镜像使用
-
-
- 列出镜像
- 获取镜像
- 查找镜像
- 删除镜像
- 使用某镜像来启动一个容器
- 更新镜像(更新前需要创建一个容器)
- 设置镜像标签
- 镜像的导入导出
- 虚悬镜像
- 利用 commit 理解镜像构成
- 上传本地镜像到共有仓库
- 私有仓库的搭建并上传镜像至私有仓库
-
- 容器的操作
-
-
- 运行容器
- 查看正在运行的容器
- 查看容器日志
- 进入容器的内部
- 复制内容到容器
- 重启&启动&停止&删除容器&退出容器
-
-
- 重新启动容器
- 启动停止运行的容器
- 停止指定的容器(删除容器前,需要先停止容器)
- 停止全部容器
- 删除指定容器
- 强制停止当前容器
- 退出容器
- 删除全部容器
- 导出容器
- 导入容器
-
- 将website1发到nginx的容器中去
-
- docker常用命令
- Docker图形界面管理
-
-
- DockerUI
- Shipyard
-
- 可视化
- Docker镜像加载原理
-
-
- UnionFS(联合文件系统)
- Docker镜像加载原理
-
- 分层理解
- 数据卷
-
-
- 创建数据卷
- 查看全部数据卷
- 查看数据卷详情
- 删除数据卷
- Docker数据卷容器
- 容器映射数据卷
- 映射所有接口地址
- 映射到指定地址的指定端口
- 映射到指定地址的任意端口
- 查看映射端口配置
- 具名和匿名挂载
-
-
- 匿名挂载
- 具名挂载
-
-
- Dockerfile自定义镜像
-
-
- 实战一
- 实战二(Tomcat)
- 构建PHP网站环境镜像
- 构建JAVA网站环境镜像
- 构建支持SSH服务的镜像
-
- Docker网络
-
-
- 快速配置指南
- Docker配置DNS
- Docker容器访问控制
- 容器访问外部网络
- 容器之间访问
- 访问所有端口
- 访问指定端口
- Docker端口映射实现
- 容器访问外部实现
- 外部访问容器实现
- 配置docker0网桥
- Docker自定义网桥
- 容器网络访问原理
- --link
- 自定义网络
- 网络连通
-
- Docker安全
-
-
- 内核名字空间
- 控制组
- Docker服务端的防护
- 内核能力机制
- 其它安全特性
- Prometheus监控Docker主机
-
- Prometheus 概述
- Prometheus 部署
- 构建容器监控系统
-
- cAdvisor+InfluxDB+Grafana
-
- 企业级镜像仓库Harbor
-
-
- Harbor概述
- Harbor部署
- 基本使用
-
- Docker-Compose
-
-
- 下载并安装**Docker-Compose**
- 体验
-
-
- 准备工作
- 为项目创建目录
- 在项目目录中创建一个名为app.py文件,内容如下
- 在项目目录中创建一个名为requirements.txt文件,内容如下
- 在项目目录中创建一个名为Dockerfile文件
- 在项目目录中创建一个名为docker-compose.yml文件
- 使用Compose构建和运行应用程序,在项目目录中,通过运行docker-compose up 启动应用程序
- YAML文件格式及编写注意事项
-
- Docker-Compose管理MySQL和Tomcat容器
- 使用docker-compose命令管理容器
-
-
- 基于docker-compose.yml启动管理的容器
- 关闭并删除容器
- 开启|关闭|重启容器
- 查看由docker-compose管理的容器
- 查看日志
-
- docker-compose配合Dockerfile使用(统一在/opt目录下操作)
- docker-compose说明
-
-
- 管理控制容器
- 管理控制镜像(需要Dockerfile文件的支撑)
-
- 开源项目
- Docker Compose项目
-
- 术语
- 场景
- Web 子目录
-
-
- index.py
- index.html
-
- Dockerfile
- haproxy 目录
- docker-compose.yml
- 运行 compose 项目
-
- Docker API
-
-
- 三种API
- 启动Remote API
- 测试Remote API
- 通过API管理Docker容器
- 创建容器:
-
- Consul
-
-
- 安装consul
- 启动服务:consul1
- 获取 consul server1 的 ip 地址
- 启动服务:consul2
- 启动服务:consul3
- 第四第五略
- 访问
-
- Rancher
-
-
- 安装Rancher
- 启动容器
- 查看ip地址
- 访问
- 案例:博客部署
-
- Swarm
-
-
- Swarm介绍
- 集群部署及节点管理
-
- 阿里云购买四台服务器
- 4台机器安装docker
- 工作模式
- 搭建集群
-
- Docker swarm项目
-
-
- 概念学习
- Docker Swarm项目安装
- Docker Swarm项目使用
- 使用 DockerHub 提供的服务发现功能
- 创建集群 token
- 加入集群
- 启动swarm manager
- 使用文件
- Docker Swarm项目调度器
- spread 策略
- binpack 策略
- Docker Swarm项目过滤器
- Constraint Filter
- Affinity Filter
- Port Filter
-
- 实战Redis
- 构建持续集成环境
Docker介绍
Docker简介
Docker简介以及Docker历史
http://c.biancheng.net/view/3118.html
docker官网
https://www.docker.com/
Docker是一个开源的应用容器引擎,基于LXC(Linux Container)内核虚拟化技术实现,提供一系列更强的功能,比如镜像、 Dockerfile等;
Docker理念是将应用及依赖包打包到一个可移植的容器中,可发布到任意Linux发行版Docker引擎上。使用沙箱机制运行程序, 程序之间相互隔离; Docker使用Go语言开发。
Docker架构与内部组件
Docker采用C/S架构,Dcoker daemon作为服务端接受来自客户端请求,并处理这些请求,比如创建、运行容器等。客户端为用 户提供一系列指令与Docker daemon交互。
Docker的架构图

- Docker Client:客户端
- Ddocker Daemon:守护进程
- Docker Images:镜像
- Docker Container:容器
- Docker Registry:镜像仓库
LXC:Linux容器技术,共享内核,容器共享宿主机资源,使用namespace和cgroups对资源限制与隔离。 Cgroups(control groups):Linux内核提供的一种限制单进程或者多进程资源的机制;比如CPU、内存等资源的使用限制。 NameSpace:命名空间,也称名字空间,Linux内核提供的一种限制单进程或者多进程资源隔离机制;一个进程可以属于多个命 名空间。Linux内核提供了六种NameSpace:UTS、IPC、PID、Network、Mount和User。
AUFS(advanced multi layered unification filesystem):高级多层统一文件系统,是UFS的一种,每个branch可以指定readonly(ro 只读)、readwrite(读写)和whiteout-able(wo隐藏)权限;一般情况下,aufs只有最上层的branch才有读写权限,其他branch 均为只读权限。
UFS(UnionFS):联合文件系统,支持将不同位置的目录挂载到同一虚拟文件系统,形成一种分层的模型;成员目录称为虚拟 文件系统的一个分支(branch)。

Docker 包括三个基本概念
- 镜像(Image)
- 容器(Container)
- 仓库(Repository)
理解了这三个概念,就理解了 Docker 的整个生命周期。
镜像( image):
Docker镜像(工mage)就是一个只读的模板。镜像可以用来创建 Docker容器镜像可以创建很多容器。容器从镜像启动的时候,会在镜像的最上层创建一个可写层。就好似]ava中的类和对象,类就是镜像,容器就是对象。
容器( container):
1.Docker利用容器( Container)独立运行的一个或一组应用。容器是用镜像创建的运行实例
2.它可以被启动、开始、停止、除。每个容器都是相互隔高的,保证安全的平台
3.可以把音器看做是一个简易版的Linux环境(色括root用户权限、进程空间、用户空间和网空间等)和运行在具其中的应用程序
4.容器的定义和镜像几手ー模一样,也是一堆层的统一视角,唯一区别在于容器的最上面那一层是可读可写的
仓库( repository):
1.仓库( Repository)是集中存放镜像文件的场所
2.仓库( Repository)和仓库注册服务器( Registry)是有区别的。仓库注册服务器上往往存放着多个仓库,每个仓库中又包含了多个镜像,每个镜像有不同的标签(tag)
3.仓库分为公开仓库(Pub1ic)和私有仓库( Private)两种形式
4.最大的公开仓库是DockerHub(https://hub.docker.com/)存放了数量度大的镜像供用户下载
5.国内的公开仓库包括阿里云、网易云等
*注:Docker 仓库的概念跟 Git 类似,注册服务器可以理解为 GitHub 这样的托管服务。
Docker有什么优点
持续集成
在项目快速迭代情况下,轻量级容器对项目快速构建、环境打包、发布等流程就能提高工作效率。
版本控制
每个镜像就是一个版本,在一个项目多个版本时可以很方便管理。
可移植性
容器可以移动到任意一台Docker主机上,而不需要过多关注底层系统。
标准化
应用程序环境及依赖、操作系统等问题,增加了生产环境故障率,容器保证了所有配置、依赖始终不变。
隔离性与安全
容器之间的进程是相互隔离的,一个容器出现问题不会影响其他容器。
虚拟机与容器区别

以KVM举例,与Docker对比
启动时间
Docker秒级,KVM分钟级。
轻量级
容器镜像大小通常以M为单位,虚拟机以G为单位。 容器资源占用小,要比虚拟机部署更快速。
性能
容器共享宿主机内核,系统级虚拟化,占用资源少,没有Hypervisor层开销,容器性能基本接近物理机; 虚拟机需要Hypervisor层支持,虚拟化一些设备,具有完整的GuestOS,虚拟化开销大,因而降低性能,没有容器性能好。
安全性
由于共享宿主机内核,只是进程级隔离,因此隔离性和稳定性不如虚拟机,容器具有一定权限访问宿主机内核,存在一定安全 隐患。
使用要求
KVM基于硬件的完全虚拟化,需要硬件CPU虚拟化技术支持; 容器共享宿主机内核,可运行在主流的Linux发行版,不用考虑CPU是否支持虚拟化技术。
应用打包与部署自动化
构建标准化的运行环境; 现在大多方案是在物理机和虚拟机上部署运行环境,面临问题是环境杂乱、完整性迁移难度高等问题,容器即开即用。
自动化测试和持续集成/部署
自动化构建镜像和良好的REST API,能够很好的集成到持续集成/部署环境来。
部署与弹性扩展
由于容器是应用级的,资源占用小,弹性扩展部署速度要更快。
微服务
Docker这种容器华隔离技术,正式应对了微服务理念,将业务模块放到容器中运行,容器的可复用性大大增加了业务模块扩展 性。

底层原理
Docker是怎么工作的
Docker是一个Client-Server结构的系统,Docker的守护进程运行在主机上。通过Socket从客户端访问。
DockerServer接受到Docker-Client的指令,就会执行这个命令!

Docker为什么比VM快?
1.Docker有着比虚拟机更少的抽象层
2.Docker利用的是宿主机的内核,vm需要的时Guest OS。

Docker安装
安装Docker
查看Linux版本内核
1.查看Linux版本内核
#uname -a
Docker最低支持CentOS 7,Docker 需要安装在 64 位的平台,并且内核版本不低于 3.10。 CentOS 7 满足最低内核的要求,但由于内核版本比较低,部分功能(如 overlay2 存储层驱动)无法使用,并且部分功能可能不太稳定。
2.yum安装gcc相关环境(确保虚拟机可以上外网)
#yum -y install gcc
安装
1.卸载旧的版本
$sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
2.需要的安装包
$sudo yum install -y yum-utils
3.设置镜像的仓库(官方)
$sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo (官网速度慢)
$sudo yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo(推荐使用,阿里云速度快)
4.更新yum软件包索引
$sudo yum makecache fast
5.安装docker docker-ce 社区版 docker-ee 企业版
$sudo yum install docker-ce docker-ce-cli containerd.io
6.启动docker
$sudo systemctl start docker
7.查看docker是否安装成功
$sudo docker version
卸载Docker
1.卸载依赖
$sudo yum remove docker-ce docker-ce-cli containerd.io
2.删除资源
$sudo rm -rf /var/lib/docker
# /var/lib/docker docker的默认工作路径
阿里云镜像加速
配置镜像加速器
$sudo mkdir -p /etc/docker
$sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://f2k3b83v.mirror.aliyuncs.com"]
}
EOF
$sudo systemctl daemon-reload
$sudo systemctl restart docker
设置开机自动启动
#systemctl enable docker
查看docker服务状态
#systemctl status docker
查看docker具体信息
#docker info
镜像使用
列出镜像
#docker images
- REPOSITORY**:表示镜像的仓库源
- TAG****:**镜像的标签
- IMAGE ID**:**镜像ID
- CREATED**:**镜像创建时间
- SIZE**:**镜像大小
- 只显示镜像ID
#docker images –q
- 直接列出镜像结果,并且只包含镜像ID和仓库名
#docker images --format "{
{.ID}}: {
{.Repository}}"
获取镜像
#docker pull REPOSITORY:TAG
查找镜像
#docker search REPOSITORY:TAG
- NAME: 镜像仓库源的名称
- DESCRIPTION: 镜像的描述
- OFFICIAL: 是否 docker 官方发布
- stars: 类似 Github 里面的 star,表示点赞、喜欢的意思。
- AUTOMATED: 自动构建。
删除镜像
#docker rmi REPOSITORY
使用某镜像来启动一个容器
#docker run -t -i REPOSITORY:TAG /bin/bash
-
-i: 交互式操作
-
-t: 终端。
-
/bin/bash:放在镜像名后的是命令,这里我们希望有个交互式 Shell,因此用的是 /bin/bash。
如果你不指定一个镜像的版本标签,docker 将默认使用 REPOSITORY:latest 镜像。
更新镜像(更新前需要创建一个容器)
-
在运行的容器内使用 apt-get update 命令进行更新。
-
在完成操作之后,输入 exit 命令来退出这个容器。
-
通过commit命令来提交(将容器保存为镜像)
#docker commit -m="描述信息" -a="镜像作者" 容器名/容器ID REPOSITORY:创建的目标镜像名
设置镜像标签
#docker tag 镜像ID REPOSITORY:新的标签名
镜像的导入导出
-
如果因为网络原因可以通过硬盘的方式传输镜像,虽然不规范,但是有效,但是这种方式导出的镜像名称和版本都是null,需要手动修改
-
将本地的镜像导出
#docker save -o 导出的路径 镜像id -
加载本地的镜像文件
#docker load -i 镜像文件
虚悬镜像
镜像既没有仓库名,也没有标签,均为 :这类无标签镜像也被称为虚悬镜像(dangling image),可以用下面的命令专门显示这类镜像:
#docker images -f dangling=true
可以用下面的命令删除
#docker rmi $(docker images -q -f dangling=true)
利用 commit 理解镜像构成
现在以定制一个 Web 服务器为例子,来讲解镜像是如何构建的。
#docker run --name webserver -d -p 80:80 nginx
这条命令会用 nginx 镜像启动一个容器,命名为 webserver,并且映射了 80 端口,这样可以用浏览器去访问这个 nginx 服务器。直接用浏览器访问的话,会看到默认的 Nginx 欢迎页面。

现在,假设非常不喜欢这个欢迎页面,希望改成欢迎 Docker 的文字,可以使用 docker exec命令进入容器,修改其内容。
#docker exec -it webserver bash
#cd /usr/share/nginx/html/
#echo 'Hello, Docker!
' >index.html
上传本地镜像到共有仓库
-
在 https://hub.docker.com 免费注册一个 Docker 账号。
-
登录
启动 docker 服务
#systemctl start docker#docker login #docker logout(退出) -
查看本地镜像
通过docker push 命令将自己的镜像推送到Docker HuB
使用tag标记镜像需要上传到的仓库
#docker tag hello-world:latest username/hello-world:latest使用push 上传镜像
#docker push username/hello-world:latest登陆hub.docker.com 查看上传结果
私有仓库的搭建并上传镜像至私有仓库
-
查找并下载 私有仓库的镜像 registry
#docker search registry #docker pull registry -
创建镜像的容器
#docker run -d -v /opt/registry:/var/lib/registry -p 5000:5000 --name myregistry registry:2Registry服务默认会将上传的镜像保存在容器的/var/lib/registry,我们将主机的/opt/registry目录挂载到该目录,即可实现将镜像保存到主机的/opt/registry目录了。
-
浏览器访问http://127.0.0.1:5000/v2,出现下面情况说明registry运行正常。
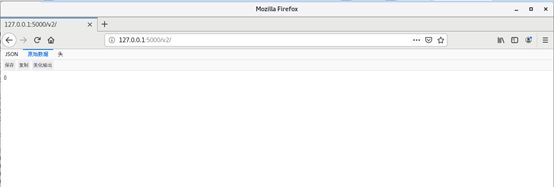
-
上传镜像至私有仓库
要通过docker tag将该镜像标志为要推送到私有仓库:
#docker tag nginx:latest localhost:5000/nginx:latest通过 docker push 命令将 nginx 镜像 push到私有仓库中:
#docker push localhost:5000/nginx:latest -
访问 http://127.0.0.1:5000/v2/_catalog 查看私有仓库目录,可以看到刚上传的镜像了:
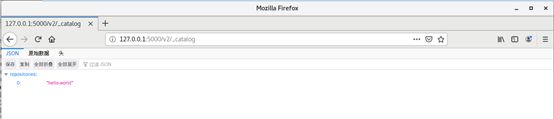
可能出现的异常
received unexpected HTTP status:500 Internal Server Error
解决方案:设置防火墙的权限
#setenforce 0
#getenforce
Permissive
容器的操作

运行容器
-
运行容器需要定制具体镜像,如果镜像不存在,会直接下载
-
命令
#docker run -d -p 宿主机端口:容器端口 --name 容器名称 镜像的标识|镜像名称[:tag]当利用 docker run 来创建容器时,Docker 在后台运行的标准操作包括:
- 检查本地是否存在指定的镜像,不存在就从公有仓库下载
- 利用镜像创建并启动一个容器
- 分配一个文件系统,并在只读的镜像层外面挂载一层可读写层
- 从宿主主机配置的网桥接口中桥接一个虚拟接口到容器中去
- 从地址池配置一个 ip 地址给容器
- 执行用户指定的应用程序
- 执行完毕后容器被终止
-
常用的参数
-
-d:代表后台运行容器
-
-it 使用交互方式运行,进入容器查看内容
-
-p 宿主机端口:容器端口:为了映射当前Linux的端口和容器的端口
-
–name 容器名称:指定容器的名称
我们也可以使用 -p 标识来指定容器端口绑定到主机端口。
两种方式的区别是:
-
-P :是容器内部端口随机映射到主机的高端口。
-
-p : 是容器内部端口绑定到指定的主机端口。
-
查看正在运行的容器
查看全部正在运行的容器信息
#docker ps [-qa]
-
-a 查看全部的容器,包括没有运行
-
-q 只查看容器的标识
查看容器日志
查看容器日志,以查看容器运行的信息
#docker logs -f 容器id
- -f:可以滚动查看日志的最后几行
- –tail number 要显示日志条数
进入容器的内部
可以进入容器的内部进行操作
#docker exec -it 容器id /bin/bash
复制内容到容器
将宿主机的文件复制到容器内部的指定目录
#docker cp 文件名称 容器id:容器内部路径
重启&启动&停止&删除容器&退出容器
重新启动容器
#docker restart 容器id
启动停止运行的容器
#docker start/run 容器id
- -d 后台运行
- -i 交换式运行
- –name 添加名字
- -t 添加标签
- -v 添加数据卷
- -rm 容器删除后清除缓存
停止指定的容器(删除容器前,需要先停止容器)
#docker stop 容器id
停止全部容器
#docker stop $(docker ps -qa)
删除指定容器
#docker rm 容器id
强制停止当前容器
#docker kill 容器id
退出容器
#exit #直接容器停止并退出
Ctrl +P + Q #容器不停止退出
删除全部容器
#docker rm $(docker ps -qa)
导出容器
#docker export 容器ID > 存储路径
导入容器
#docker import 容器快照/指定URL/某个目录
*注:用户既可以使用 docker load 来导入镜像存储文件到本地镜像库,也可以使用 docker import 来导入一个容器快照到本地镜像库。这两者的区别在于容器快照文件将丢弃所有的历史记录和元数据信息(即仅保存容器当时的快照状态),而镜像存储文件将保存完整记录,体积也要大。此外,从容器快照文件导入时可以重新指定标签等元数据信息。
将website1发到nginx的容器中去
#docker volume create 卷名
#docker run -d -p 5000:80 -v 卷名:/usr/share/nginx/html --name 容器名 docker.io/nginx:latest
#cd /var/lib/docker/volumes/卷名/_data/
#vi index.html
web访问ip:5000
docker常用命令


Docker图形界面管理
DockerUI
DockerUI是一个基于Docker API提供图形化页面简单的容器管理系统,支持容器管理、镜像管理。
docker run \
-d \
-p 9000:9000 \
-v /var/run/docker.sock:/docker.sock \
--name dockerui abh1nav/dockerui:latest \
-e="/docker.sock"
也可以通过Rest API管理:
docker run \
-d \
-p 9000:9000 \
--name dockerui \
-e "http://:2375"
abh1nav/dockerui:latest
http://<dockerd host ip>:9000
Shipyard
Shipyard也是基于Docker API实现的容器图形管理系统,支持container、images、engine、cluster等功能,可满足我 们基本的容器部署需求。 Shipyard分为手动部署和自动部署。

官方部署文档:https://www.shipyard-project.com/docs/deploy/
可视化
http://www.yunweipai.com/34991.html
Docker镜像加载原理
UnionFS(联合文件系统)
我们下载的时候看到的一层层就是这个!
UnionFS(联合文件系统):Union文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统得修改,作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。Union文件系统是Docker镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
特性:一次同时加载多个文件系统,但从外面看来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统对包含所有底层的文件和目录。
Docker镜像加载原理
docker的镜像实际上由一层一层的文件系统组成,这种层次的文件系统UnionFS。
boots(boot file system)主要包含bootloader和kernel,bootloader主要是引导加载kernel,Linux刚启动时加载bootfs文件系统,在Docker镜像的最底层是bootfs。这一层与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时系统也会加载bootfs。
rootfs(root file system),在bootfs之上。包含的就是典型Linux系统中的/dev/,/proc,/bin,/etc等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,Centos等等。

分层理解
所有的 Docker镜像都起始于一个基础镜像层,当进行修改或增加新的内容时,就会在当前镜像层之上,创建新的镜像层。
举一个简单的例子,假如基于 Ubuntu Linux16.04创建一个新的镜像,这就是新镜像的第一层;如果在该镜像中添加 Python’包,就会在基础镜像层之上创建第二个镜像层;如果继续添加一个安补丁,就会创建第三个镜像层该镜像当前已经包含3个镜像层,如下图所示(这只是一个用于演示的很简单的例子)。

在添加额外的镜像层的同时,镜像始终保持是当前所有镜像的组合,理解这一点非常重要。下图中举了一个简单的例子,每个镜像层包含3个文件,而镜像包含了来自两个镜像层的6个文件。

上图中的镜像层跟之前图中的略有区别,主要目的是便于展示文件。下图中展示了一个稍微复杂的三层镜像,在外部看来整个镜像只有6个文件,这是因为最上层中的文件7是文件5的一个更新版本
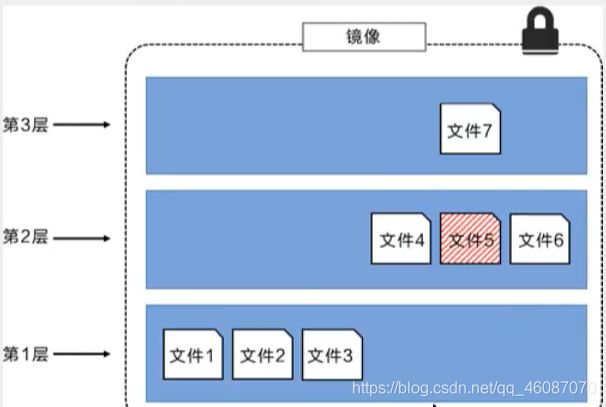
这种情况下,上层镜像层中的文件覆盖了底层镜像层中的文件。这样就使得文件的更新版本作为—个新镜像层添加到镜像当中。Docker通过存储引擎(新版本采用快照机制)的方式来实现镜像层堆栈,并保证多镜像层对外展示为统-的文件系统。
Linux上可用的存储引擎有AUFS、 Overlay2、 Device Mapper、Bts以及zFS。顾名思义,每种存储引擎都基于 Linux中对应的又仵系统或者块设备技术,并且每种存储引擎都有其独有的性能特点。
Docker在 Windows上仅支持 windowsfilter—种存储引擎,该引擎基于NTFS文件系统之上实现了分层和CoW[1]。下图展示了与系统显示相同的三层镜像。所有镜像层堆并合并,对外提供统-的视图.
特点:
Docker镜像都是只读的,当容器启动时,—个新的可写层被加载到镜像的顶部这一层就是我们通常说的容器层,容器之下的都叫镜像层!


数据卷
数据卷是一个可供一个或多个容器使用的特殊目录,它绕过 UFS,可以提供很多有用的特性:
- 数据卷可以在容器之间共享和重用
- 对数据卷的修改会立马生效
- 对数据卷的更新,不会影响镜像
- 卷会一直存在,直到没有容器使用
*数据卷的使用,类似于 Linux 下对目录或文件进行 mount。
创建数据卷
创建数据卷后,默认会存放在一个目录下/var/lib/docker/volumes/数据卷名称/_data
#docker volume create 数据卷名称
查看全部数据卷
查看全部数据卷信息
#docker volume ls
查看数据卷详情
查看数据卷的详细信息,可以查询到存放的路径,创建时间等等
#docker volume inspect 数据卷名称
删除数据卷
删除指定的数据卷
#docker volume rm 数据卷名称
Docker数据卷容器
如果你有一些持续更新的数据需要在容器之间共享,最好创建数据卷容器。
数据卷容器,其实就是一个正常的容器,专门用来提供数据卷供其它容器挂载的。
首先,创建一个命名的数据卷容器 dbdata:
$sudo docker run -d -v /数据卷容器名称 --name 数据卷容器名称 镜像的标识|镜像名称[:tag]
然后,在其他容器中使用 --volumes-from 来挂载 dbdata 容器中的数据卷。
$sudo docker run -d --volumes-from 数据卷容器名称 --name db1
$sudo docker run -d --volumes-from 数据卷容器名称 --name db2
还可以使用多个 --volumes-from 参数来从多个容器挂载多个数据卷。
也可以从其他已经挂载了数据卷的容器来挂载数据卷。
$sudo docker run -d --name db3 --volumes-from db1
*注意:使用 --volumes-from 参数所挂载数据卷的容器自己并不需要保持在运行状态。
如果删除了挂载的容器(包括 dbdata、db1 和 db2),数据卷并不会被自动删除。如果要删除一个数据卷,必须在删除最后一个还挂载着它的容器时使用 docker rm -v 命令来指定同时删除关联的容器。
容器映射数据卷
通过数据卷名称映射,如果数据卷不存在。Docker会帮你自动创建,会将容器内部自带的文件,存储在默认的存放路径中。
#docker run -d -p 8080:8080 --name tomcat -v 数据卷名称:容器内部的路径 镜像id
通过路径映射数据卷,直接指定一个路径作为数据卷的存放位置。但是这个路径下是空的。
#docker run -d -p 8080:8080 --name tomcat -v 路径(/root/自己创建的文件夹):容器内部的路径 镜像id

映射所有接口地址
使用 hostPort:containerPort 格式本地的 5000 端口映射到容器的 5000 端口,可以执行
$ sudo docker run -d -p 5000:5000 镜像的标识|镜像名称
此时默认会绑定本地所有接口上的所有地址。
映射到指定地址的指定端口
可以使用 ip:hostPort:containerPort 格式指定映射使用一个特定地址,比如 localhost 地址 127.0.0.1
$ sudo docker run -d -p 127.0.0.1:5000:5000 镜像的标识|镜像名称
映射到指定地址的任意端口
使用 ip::containerPort 绑定 localhost 的任意端口到容器的 5000 端口,本地主机会自动分配一个端口。
$ sudo docker run -d -p 127.0.0.1::5000 镜像的标识|镜像名称
还可以使用 udp 标记来指定 udp 端口
$ sudo docker run -d -p 127.0.0.1:5000:5000/udp 镜像的标识|镜像名称
查看映射端口配置
使用 docker port 来查看当前映射的端口配置,也可以查看到绑定的地址
$ docker port nostalgic_morse 5000
127.0.0.1:49155.
注意:
容器有自己的内部网络和 ip 地址(使用 docker inspect 可以获取所有的变量,Docker 还可以有一个可变的网络配置。)
-p 标记可以多次使用来绑定多个端口
例如
$ sudo docker run -d -p 5000:5000 -p 3000:80 镜像的标识|镜像名称
具名和匿名挂载
-
匿名挂载
#docker run -d -P --name 容器名 -v 容器内路径 镜像名 -
具名挂载
#docker run -d -P --name 容器名 -v 卷名:容器内路径 镜像名所有的docker容器内的卷,没有指定目录的情况下都是在/var/lib/docker/volumes/xxx/_data
#如何确定是具名挂载还是匿名挂载,还是指定路径挂载 -v 容器内路径 #匿名挂载 -v 卷名:容器内路径 #具名挂载 -v /宿主机路径::容器内路径 #指定路径挂载#通过 -v 容器内路径,ro rw 改变读写权限 ro readonly #只读 rw readwrite #可读可写 docker run -d -p --name nginx2 -v mynginx:/etc/nginx:ro nginx
将数据从宿主机挂载到容器中的三种方式
Docker提供三种方式将数据从宿主机挂载到容器中:
• volumes:Docker管理宿主机文件系统的一部分(/var/lib/docker/volumes)。保存数据的最佳方式。
• bind mounts-:将宿主机上的任意位置的文件或者目录挂载到容器中。
• tmpfs:挂载存储在主机系统的内存中,而不会写入主机的文件系统。如果不希望将数据持久存储在任何位置,可以使用 tmpfs,同时避免写入容器可写层提高性能。

Volume特点:
• 多个运行容器之间共享数据,多个容器可以同时挂载相同的卷。
• 当容器停止或被移除时,该卷依然存在。
• 当明确删除卷时,卷才会被删除。
• 将容器的数据存储在远程主机或其他存储上(间接)
• 将数据从一台Docker主机迁移到另一台时,先停止容器,然后备份卷的目录(/var/lib/docker/volumes/)
Bind Mounts特点:
• 从主机共享配置文件到容器。默认情况下,挂载主机/etc/resolv.conf到每个容器,提供DNS解析。
• 在Docker主机上的开发环境和容器之间共享源代码。例如,可以将Maven target目录挂载到容器中,每次在Docker主机 上构建Maven项目时,容器都可以访问构建的项目包。
• 当Docker主机的文件或目录结构保证与容器所需的绑定挂载一致时
Dockerfile自定义镜像
实战一
#创建一个dockerfile文件,名字可以随机 建议Dockerfile
#文件中的内容 指令(大写) 参数
FROM centos
VOLUME ["volume01","volume02"]
CMD echo "---end---"
CMD /bin/bash
#FROM:指定当前自定义镜像依赖的环境
#MAINTAINER:镜像作者 姓名+邮箱
#COPY:将相对路径下的内容复制到自定义镜像中
#WORKDIR:声明镜像的默认工作目录
#VOLUME:挂载的目录
#EXPOSE:保留端口配置
#RUN:执行的命令,可以编写多个
#CMD:指定这个容器启动的时候要运行的命令,只有最后一个会生效,可被替代
类似于 RUN 指令,用于运行程序,但二者运行的时间点不同:
CMD 在docker run 时运行。
RUN 是在 docker build。
#ENTRYPOINT:指定这个容器启动的时候要运行的命令,可以追加命令
#ONBUILD:当构建一个被继承Dockerfile 这个时候就会运行ONBUILD的指令,触发指令
#ENV:构建的时候设置环境变量
#docker build -f 文件存储路径 -t 容器名[:TAG]
FROM centos
MAINTAINER zzz<[email protected]>
ENV MYPATH /usr/local
WORKDIR $MYPATH
RUN yum -y install vim
RUN yum -y install net-tools
EXPOSE 80
CMD echo $MYPATH
CMD echo "----end----"
CMD echo /bin/bash
实战二(Tomcat)
-
准备镜像文件tomcat压缩包,jdk的压缩包
-
编写dockerfile文件,官方命名Dockerfile,build会自动寻找这个文件,就不需要-f 制定了!
FROM centos MAINTAINER zzz<[email protected]> COPY readme.txt /usr/Local/readme.txt ADD jdk-8u11-linux-x64.tar.gz /usr/local/ ADD apache-tomcat-9.0.22.tar.gz /usr/Local/ RUN yum-y install vim ENV MYPATH /usr/Local WORKDIR $MYPATH ENV JAVA_HOME /usr/Local/idk.8.0_11 ENV CLASSPATH $JAVA_HOME/Lib/dt.jar:$JAVA_HOME/Lib/tools.jar ENV CATALINA_HOME /usr/Local/apache-tomcat-9.0.22 ENV CATALINA_BASH /usr/Local/apache-tomcat-9.0.22 ENV PATH $PATH: $JAVA_HOME/bin:$CATALINA_HOME/Lib:$CATALINA_HOME/bin EXPOSE 8080 CMD /usr/Local/apache-tomcat-90.22/bin/startup.sh && tail -F /usr/Local/apache-tomcat-9022/bin/logs/catalina.out -
构建镜像
#docker build -t diytomcat . . 是上下文路径 上下文路径,是指 docker 在构建镜像,有时候想要使用到本机的文件(比如复制),docker build 命令得知这个路径后,会将路径下的所有内容打包。 由于 docker 的运行模式是 C/S。我们本机是 C,docker 引擎是 S。实际的构建过程是在 docker 引擎下完成的,所以这个时候无法用到我们本机的文件。这就需要把我们本机的指定目录下的文件一起打包提供给 docker 引擎使用。 如果未说明最后一个参数,那么默认上下文路径就是 Dockerfile 所在的位置。 -
启动镜像
#docker run -d 9090:8080 --name zzzcomcat -v 本地目录路径:容器内部目录路径 本地目录路径:容器内部目录路径(日志挂载)镜像名 #-d 后台运行 #-p 指定端口 -
访问测试
-
发布项目
出现资源拒绝访问,解决办法,增加一个tag

构建PHP网站环境镜像
FROM centos:6
MAINTAINER zzz
RUN yum install -y httpd php php-gd php-mysql mysql mysql-server
ENV MYSQL_ROOT_PASSWORD 123456
RUN echo "" > /var/www/html/index.php
ADD start.sh /start.sh
RUN chmod +x /start.sh
ADD https://cn.wordpress.org/wordpress-4.7.4-zh_CN.tar.gz /var/www/html
COPY wp-config.php /var/www/html/wordpress
VOLUME ["/var/lib/mysql"]
CMD /start.sh
EXPOSE 80 3306
# cat start.sh
service httpd start
service mysqld start
mysqladmin -uroot password $MYSQL_ROOT_PASSWORD
tail -f
构建JAVA网站环境镜像
FROM centos:6
MAINTAINER zzz
ADD jdk-8u45-linux-x64.tar.gz /usr/local
ENV JAVA_HOME /usr/local/jdk1.8.0_45
ADD http://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-8/v8.0.45/bin/apachetomcat-8.0.45.tar.gz /usr/local
WORKDIR /usr/local/apache-tomcat-8.0.45
ENTRYPOINT ["bin/catalina.sh", "run"]
EXPOSE 8080
构建支持SSH服务的镜像
FROM centos:6
MAINTAINER zzz
ENV ROOT_PASSWORD 123456
RUN yum install -y openssh-server
RUN echo $ROOT_PASSWORD |passwd --stdin root
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
CMD ["/usr/sbin/sshd", "-D"]
EXPOSE 22
Docker网络
当 Docker 启动时,会自动在主机上创建一个 docker0 虚拟网桥,实际上是 Linux 的一个 bridge,可以理解为一个软件交换机。它会在挂载到它的网口之间进行转发。
同时,Docker 随机分配一个本地未占用的私有网段(在 RFC1918 中定义)中的一个地址给 docker0 接口。比如典型的 172.17.42.1,掩码为 255.255.0.0。此后启动的容器内的网口也会自动分配一个同一网段(172.17.0.0/16)的地址。
当创建一个 Docker 容器的时候,同时会创建了一对 veth pair 接口(当数据包发送到一个接口时,另外一个接口也可以收到相同的数据包)。这对接口一端在容器内,即 eth0;另一端在本地并被挂载到 docker0 网桥,名称以 veth 开头(例如 vethAQI2QT)。通过这种方式,主机可以跟容器通信,容器之间也可以相互通信。Docker 就创建了在主机和所有容器之间一个虚拟共享网络。

接下来的部分将介绍在一些场景中,Docker 所有的网络定制配置。以及通过 Linux 命令来调整、补充、甚至替换 Docker 默认的网络配置。
快速配置指南
下面是一个跟 Docker 网络相关的命令列表。
其中有些命令选项只有在 Docker 服务启动的时候才能配置,而且不能马上生效。
- -b BRIDGE or --bridge=BRIDGE —指定容器挂载的网桥
- –bip=CIDR —定制 docker0 的掩码
- -H SOCKET… or --host=SOCKET… —Docker 服务端接收命令的通道
- –icc=true|false —是否支持容器之间进行通信
- –ip-forward=true|false —请看下文容器之间的通信
- –iptables=true|false —禁止 Docker 添加 iptables 规则
- –mtu=BYTES —容器网络中的 MTU
下面2个命令选项既可以在启动服务时指定,也可以 Docker 容器启动(docker run)时候指定。在 Docker 服务启动的时候指定则会成为默认值,后面执行 docker run 时可以覆盖设置的默认值。
- –dns=IP_ADDRESS… —使用指定的DNS服务器
- –dns-search=DOMAIN… —指定DNS搜索域
最后这些选项只有在 docker run 执行时使用,因为它是针对容器的特性内容。
- -h HOSTNAME or --hostname=HOSTNAME —配置容器主机名
- –link=CONTAINER_NAME:ALIAS —添加到另一个容器的连接
- –net=bridge|none|container:NAME_or_ID|host —配置容器的桥接模式
- -p SPEC or --publish=SPEC —映射容器端口到宿主主机
- -P or --publish-all=true|false —映射容器所有端口到宿主主机
Docker配置DNS
Docker 没有为每个容器专门定制镜像,那么怎么自定义配置容器的主机名和 DNS 配置呢?
秘诀就是它利用虚拟文件来挂载到来容器的 3 个相关配置文件。
在容器中使用 mount 命令可以看到挂载信息:
$ mount
...
/dev/disk/by-uuid/1fec...ebdf on /etc/hostname type ext4 ...
/dev/disk/by-uuid/1fec...ebdf on /etc/hosts type ext4 ...
tmpfs on /etc/resolv.conf type tmpfs ...
...
这种机制可以让宿主主机 DNS 信息发生更新后,所有 Docker 容器的 dns 配置通过 /etc/resolv.conf 文件立刻得到更新。
如果用户想要手动指定容器的配置,可以利用下面的选项。
-h HOSTNAME or --hostname=HOSTNAME
设定容器的主机名,它会被写到容器内的 /etc/hostname 和 /etc/hosts。但它在容器外部看不到,既不会在 docker ps 中显示,也不会在其他的容器的 /etc/hosts 看到。
–link=CONTAINER_NAME:ALIAS
选项会在创建容器的时候,添加一个其他容器的主机名到 /etc/hosts 文件中,让新容器的进程可以使用主机名 ALIAS 就可以连接它。
–dns=IP_ADDRESS
添加 DNS 服务器到容器的 /etc/resolv.conf 中,让容器用这个服务器来解析所有不在 /etc/hosts 中的主机名。
–dns-search=DOMAIN
设定容器的搜索域,当设定搜索域为 .example.com 时,在搜索一个名为 host 的主机时,DNS 不仅搜索host,还会搜索 host.example.com。
注意:如果没有上述最后 2 个选项,Docker 会默认用主机上的 /etc/resolv.conf 来配置容器。
Docker容器访问控制
容器的访问控制,主要通过 Linux 上的 iptables 防火墙来进行管理和实现。iptables 是 Linux 上默认的防火墙软件,在大部分发行版中都自带。
容器访问外部网络
容器要想访问外部网络,需要本地系统的转发支持。在Linux 系统中,检查转发是否打开。
$sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 1
如果为 0,说明没有开启转发,则需要手动打开。
$sysctl -w net.ipv4.ip_forward=1
如果在启动 Docker 服务的时候设定 --ip-forward=true, Docker 就会自动设定系统的 ip_forward 参数为 1。
容器之间访问
容器之间相互访问,需要两方面的支持。
容器的网络拓扑是否已经互联。默认情况下,所有容器都会被连接到 docker0 网桥上。
本地系统的防火墙软件 — iptables 是否允许通过。
访问所有端口
当启动 Docker 服务时候,默认会添加一条转发策略到 iptables 的 FORWARD 链上。策略为通过(ACCEPT)还是禁止(DROP)取决于配置–icc=true(缺省值)还是 --icc=false。当然,如果手动指定 --iptables=false 则不会添加 iptables 规则。
可见,默认情况下,不同容器之间是允许网络互通的。如果为了安全考虑,可以在 /etc/default/docker 文件中配置 DOCKER_OPTS=–icc=false 来禁止它。
访问指定端口
在通过 -icc=false 关闭网络访问后,还可以通过 --link=CONTAINER_NAME:ALIAS 选项来访问容器的开放端口。
例如,在启动 Docker 服务时,可以同时使用 icc=false --iptables=true 参数来关闭允许相互的网络访问,并让 Docker 可以修改系统中的 iptables 规则。
此时,系统中的 iptables 规则可能是类似
$ sudo iptables -nL
...
Chain FORWARD (policy ACCEPT)
target prot opt source destination
DROP all -- 0.0.0.0/0 0.0.0.0/0
...
之后,启动容器(docker run)时使用 --link=CONTAINER_NAME:ALIAS 选项。Docker 会在 iptable 中为 两个容器分别添加一条 ACCEPT 规则,允许相互访问开放的端口(取决于 Dockerfile 中的 EXPOSE 行)。
当添加了 --link=CONTAINER_NAME:ALIAS 选项后,添加了 iptables 规则。
$ sudo iptables -nL
...
Chain FORWARD (policy ACCEPT)
target prot opt source destination
ACCEPT tcp -- 172.17.0.2 172.17.0.3 tcp spt:80
ACCEPT tcp -- 172.17.0.3 172.17.0.2 tcp dpt:80
DROP all -- 0.0.0.0/0 0.0.0.0/0
注意:–link=CONTAINER_NAME:ALIAS 中的 CONTAINER_NAME 目前必须是 Docker 分配的名字,或使用 --name 参数指定的名字。主机名则不会被识别。
Docker端口映射实现
默认情况下,容器可以主动访问到外部网络的连接,但是外部网络无法访问到容器。
容器访问外部实现
容器所有到外部网络的连接,源地址都会被NAT成本地系统的IP地址。这是使用 iptables 的源地址伪装操作实现的。
查看主机的 NAT 规则。
$ sudo iptables -t nat -nL
...
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 172.17.0.0/16 !172.17.0.0/16
...
其中,上述规则将所有源地址在 172.17.0.0/16 网段,目标地址为其他网段(外部网络)的流量动态伪装为从系统网卡发出。MASQUERADE 跟传统 SNAT 的好处是它能动态从网卡获取地址。
外部访问容器实现
容器允许外部访问,可以在 docker run 时候通过 -p 或 -P 参数来启用。
不管用那种办法,其实也是在本地的 iptable 的 nat 表中添加相应的规则。
使用 -P 时:
$ iptables -t nat -nL
...
Chain DOCKER (2 references)
target prot opt source destination
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:49153 to:172.17.0.2:80
使用 -p 80:80 时:
$ iptables -t nat -nL
Chain DOCKER (2 references)
target prot opt source destination
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80 to:172.17.0.2:80
注意:
- 这里的规则映射了 0.0.0.0,意味着将接受主机来自所有接口的流量。用户可以通过 -p IP:host_port:container_port 或 -p IP::port 来指定允许访问容器的主机上的 IP、接口等,以制定更严格的规则。
- 如果希望永久绑定到某个固定的 IP 地址,可以在 Docker 配置文件 /etc/default/docker 中指定 DOCKER_OPTS="–ip=IP_ADDRESS",之后重启 Docker 服务即可生效。
配置docker0网桥
Docker 服务默认会创建一个 docker0 网桥(其上有一个 docker0 内部接口),它在内核层连通了其他的物理或虚拟网卡,这就将所有容器和本地主机都放到同一个物理网络。
Docker 默认指定了 docker0 接口 的 IP 地址和子网掩码,让主机和容器之间可以通过网桥相互通信,它还给出了 MTU(接口允许接收的最大传输单元),通常是 1500 Bytes,或宿主主机网络路由上支持的默认值。这些值都可以在服务启动的时候进行配置。
- –bip=CIDR — IP 地址加掩码格式,例如 192.168.1.5/24
- –mtu=BYTES — 覆盖默认的 Docker mtu 配置
也可以在配置文件中配置 DOCKER_OPTS,然后重启服务。
由于目前 Docker 网桥是 Linux 网桥,用户可以使用 brctl show 来查看网桥和端口连接信息。
$ sudo brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.3a1d7362b4ee no veth65f9
vethdda6
*注:brctl 命令在 Debian、Ubuntu 中可以使用 sudo apt-get install bridge-utils 来安装。
每次创建一个新容器的时候,Docker 从可用的地址段中选择一个空闲的 IP 地址分配给容器的 eth0 端口。使用本地主机上 docker0 接口的 IP 作为所有容器的默认网关。
$ sudo docker run -i -t --rm base /bin/bash
$ ip addr show eth0
24: eth0: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 32:6f:e0:35:57:91 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.3/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::306f:e0ff:fe35:5791/64 scope link
valid_lft forever preferred_lft forever
$ ip route
default via 172.17.42.1 dev eth0
172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.3
$ exit
Docker自定义网桥
除了默认的 docker0 网桥,用户也可以指定网桥来连接各个容器。
在启动 Docker 服务的时候,使用 -b BRIDGE或–bridge=BRIDGE 来指定使用的网桥。
如果服务已经运行,那需要先停止服务,并删除旧的网桥。
$ sudo service docker stop
$ sudo ip link set dev docker0 down
$ sudo brctl delbr docker0
然后创建一个网桥 bridge0。
$ sudo brctl addbr bridge0
$ sudo ip addr add 192.168.5.1/24 dev bridge0
$ sudo ip link set dev bridge0 up
查看确认网桥创建并启动。
$ ip addr show bridge0
4: bridge0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state UP group default
link/ether 66:38:d0:0d:76:18 brd ff:ff:ff:ff:ff:ff
inet 192.168.5.1/24 scope global bridge0
valid_lft forever preferred_lft forever
配置 Docker 服务,默认桥接到创建的网桥上。
$ echo 'DOCKER_OPTS="-b=bridge0"' >> /etc/default/docker
$ sudo service docker start
启动 Docker 服务。
新建一个容器,可以看到它已经桥接到了 bridge0 上。
可以继续用 brctl show 命令查看桥接的信息。另外,在容器中可以使用 ip addr 和 ip route 命令来查看 IP 地址配置和路由信息。
容器网络访问原理


Docker 网络模式
Docker支持五种网络模式
bridge
默认网络,Docker启动后创建一个docker0网桥,默认创建的容器也是添加到这个网桥中;IP地址段是172.17.0.1/16
host
容器不会获得一个独立的network namespace,而是与宿主机共用一个。
none
获取独立的network namespace,但不为容器进行任何网络配置。
container
与指定的容器使用同一个network namespace,网卡配置也都是相同的。
自定义
自定义网桥,默认与bridge网络一样。
–link
通过容器名来实现互ping
#docker exec -it 容器名2 --link 容器名1 容器名
#docker exec -it 容器名2 ping 容器名1
反过来,容器1 ping不通容器2。 其实这个容器2就是在本地配置了容器1的配置。
#查看hosts配置,
#docker exec -it 容器2 cat /etc/hosts
本质探究:–link就是在hosts配置中增加了一个地址
自定义网络,不适用docker0
docker问题:不支持容器名连接访问
自定义网络
查看所有的网络
#docker network ls
网络模式
bridge:桥接docker(默认)
none:不配置网络
host:和宿主机共享网络
container:容器网络连通(用的少,局限很大)
自定义一个网络
#docker network create --driver bridge --subnet 子网 --gateway 网关 网络名
网络连通
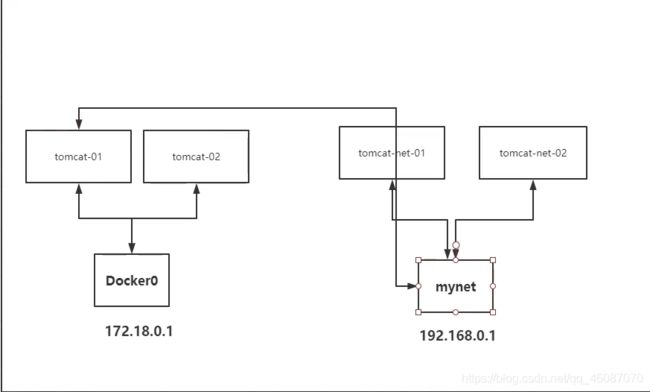
实现tomcat-01 连接tomcat-net-01
#docker network connect 网络名 容器名
Docker安全
评估 Docker 的安全性时,主要考虑三个方面:
- 由内核的名字空间和控制组机制提供的容器内在安全
- Docker程序(特别是服务端)本身的抗攻击性
- 内核安全性的加强机制对容器安全性的影响
内核名字空间
Docker 容器和 LXC 容器很相似,所提供的安全特性也差不多。当用 docker run 启动一个容器时,在后台 Docker 为容器创建了一个独立的名字空间和控制组集合。
名字空间提供了最基础也是最直接的隔离,在容器中运行的进程不会被运行在主机上的进程和其它容器发现和作用。
每个容器都有自己独有的网络栈,意味着它们不能访问其他容器的 sockets 或接口。不过,如果主机系统上做了相应的设置,容器可以像跟主机交互一样的和其他容器交互。当指定公共端口或使用 links 来连接 2 个容器时,容器就可以相互通信了(可以根据配置来限制通信的策略)。
从网络架构的角度来看,所有的容器通过本地主机的网桥接口相互通信,就像物理机器通过物理交换机通信一样。
那么,内核中实现名字空间和私有网络的代码是否足够成熟?
内核名字空间从 2.6.15 版本(2008 年 7 月发布)之后被引入,数年间,这些机制的可靠性在诸多大型生产系统中被实践验证。
实际上,名字空间的想法和设计提出的时间要更早,最初是为了在内核中引入一种机制来实现 OpenVZ 的特性。
而 OpenVZ 项目早在 2005 年就发布了,其设计和实现都已经十分成熟。
控制组
控制组是 Linux 容器机制的另外一个关键组件,负责实现资源的审计和限制。
它提供了很多有用的特性;以及确保各个容器可以公平地分享主机的内存、CPU、磁盘 IO 等资源;当然,更重要的是,控制组确保了当容器内的资源使用产生压力时不会连累主机系统。
尽管控制组不负责隔离容器之间相互访问、处理数据和进程,它在防止拒绝服务(DDOS)攻击方面是必不可少的。尤其是在多用户的平台(比如公有或私有的 PaaS)上,控制组十分重要。例如,当某些应用程序表现异常的时候,可以保证一致地正常运行和性能。
控制组机制始于 2006 年,内核从 2.6.24 版本开始被引入。
Docker服务端的防护
运行一个容器或应用程序的核心是通过 Docker 服务端。Docker 服务的运行目前需要 root 权限,因此其安全性十分关键。
首先,确保只有可信的用户才可以访问 Docker 服务。Docker 允许用户在主机和容器间共享文件夹,同时不需要限制容器的访问权限,这就容易让容器突破资源限制。例如,恶意用户启动容器的时候将主机的根目录/映射到容器的 /host 目录中,那么容器理论上就可以对主机的文件系统进行任意修改了。这听起来很疯狂?但是事实上几乎所有虚拟化系统都允许类似的资源共享,而没法禁止用户共享主机根文件系统到虚拟机系统。
这将会造成很严重的安全后果。因此,当提供容器创建服务时(例如通过一个 web 服务器),要更加注意进行参数的安全检查,防止恶意的用户用特定参数来创建一些破坏性的容器
为了加强对服务端的保护,Docker 的 REST API(客户端用来跟服务端通信)在 0.5.2 之后使用本地的 Unix 套接字机制替代了原先绑定在 127.0.0.1 上的 TCP 套接字,因为后者容易遭受跨站脚本攻击。现在用户使用 Unix 权限检查来加强套接字的访问安全。
用户仍可以利用 HTTP 提供 REST API 访问。建议使用安全机制,确保只有可信的网络或 VPN,或证书保护机制(例如受保护的 stunnel 和 ssl 认证)下的访问可以进行。此外,还可以使用 HTTPS 和证书来加强保护。
最近改进的 Linux 名字空间机制将可以实现使用非 root 用户来运行全功能的容器。这将从根本上解决了容器和主机之间共享文件系统而引起的安全问题。
终极目标是改进 2 个重要的安全特性:
- 将容器的 root 用户映射到本地主机上的非 root 用户,减轻容器和主机之间因权限提升而引起的安全问题;
- 允许 Docker 服务端在非 root 权限下运行,利用安全可靠的子进程来代理执行需要特权权限的操作。这些子进程将只允许在限定范围内进行操作,例如仅仅负责虚拟网络设定或文件系统管理、配置操作等。
最后,建议采用专用的服务器来运行 Docker 和相关的管理服务(例如管理服务比如 ssh 监控和进程监控、管理工具 nrpe、collectd 等)。其它的业务服务都放到容器中去运行。
内核能力机制
能力机制(Capability)是 Linux 内核一个强大的特性,可以提供细粒度的权限访问控制。
Linux 内核自 2.2 版本起就支持能力机制,它将权限划分为更加细粒度的操作能力,既可以作用在进程上,也可以作用在文件上。
例如,一个 Web 服务进程只需要绑定一个低于 1024 的端口的权限,并不需要 root 权限。那么它只需要被授权 net_bind_service 能力即可。此外,还有很多其他的类似能力来避免进程获取 root 权限。
默认情况下,Docker 启动的容器被严格限制只允许使用内核的一部分能力。
使用能力机制对加强 Docker 容器的安全有很多好处。通常,在服务器上会运行一堆需要特权权限的进程,包括有 ssh、cron、syslogd、硬件管理工具模块(例如负载模块)、网络配置工具等等。容器跟这些进程是不同的,因为几乎所有的特权进程都由容器以外的支持系统来进行管理。
- ssh 访问被主机上ssh服务来管理;
- cron 通常应该作为用户进程执行,权限交给使用它服务的应用来处理;
- 日志系统可由 Docker 或第三方服务管理;
- 硬件管理无关紧要,容器中也就无需执行 udevd 以及类似服务;
- 网络管理也都在主机上设置,除非特殊需求,容器不需要对网络进行配置。
从上面的例子可以看出,大部分情况下,容器并不需要“真正的” root 权限,容器只需要少数的能力即可。为了加强安全,容器可以禁用一些没必要的权限。
- 完全禁止任何 mount 操作;
- 禁止直接访问本地主机的套接字;
- 禁止访问一些文件系统的操作,比如创建新的设备、修改文件属性等;
- 禁止模块加载。
这样,就算攻击者在容器中取得了 root 权限,也不能获得本地主机的较高权限,能进行的破坏也有限。
默认情况下,Docker采用 白名单 机制,禁用 必需功能 之外的其它权限。
当然,用户也可以根据自身需求来为 Docker 容器启用额外的权限。
其它安全特性
除了能力机制之外,还可以利用一些现有的安全机制来增强使用 Docker 的安全性,例如 TOMOYO, AppArmor, SELinux, GRSEC 等。
Docker 当前默认只启用了能力机制。用户可以采用多种方案来加强 Docker 主机的安全,例如:
- 在内核中启用 GRSEC 和 PAX,这将增加很多编译和运行时的安全检查;通过地址随机化避免恶意探测等。并且,启用该特性不需要 Docker 进行任何配置。
- 使用一些有增强安全特性的容器模板,比如带 AppArmor 的模板和 Redhat 带 SELinux 策略的模板。这些模板提供了额外的安全特性。
- 用户可以自定义访问控制机制来定制安全策略。
跟其它添加到 Docker 容器的第三方工具一样(比如网络拓扑和文件系统共享),有很多类似的机制,在不改变 Docker 内核情况下就可以加固现有的容器。
总体来看,Docker 容器还是十分安全的,特别是在容器内不使用 root 权限来运行进程的话。
另外,用户可以使用现有工具,比如 Apparmor, SELinux, GRSEC 来增强安全性;甚至自己在内核中实现更复杂的安全机制。
Prometheus监控Docker主机
Prometheus 概述
Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。自2012年成为社区 开源项目,拥有非常活跃的开发人员和用户社区。为强调开源及独立维护,Prometheus于2016 年加入云原生云计算基金会(CNCF),成为继Kubernetes之后的第二个托管项目。
https://prometheus.io
https://github.com/prometheus
Prometheus 特点:
• 多维数据模型:由度量名称和键值对标识的时间序列数据
• PromQL:一种灵活的查询语言,可以利用多维数据完成复杂的查询
• 不依赖分布式存储,单个服务器节点可直接工作
• 基于HTTP的pull方式采集时间序列数据
• 推送时间序列数据通过PushGateway组件支持
• 通过服务发现或静态配置发现目标
• 多种图形模式及仪表盘支持(grafana)
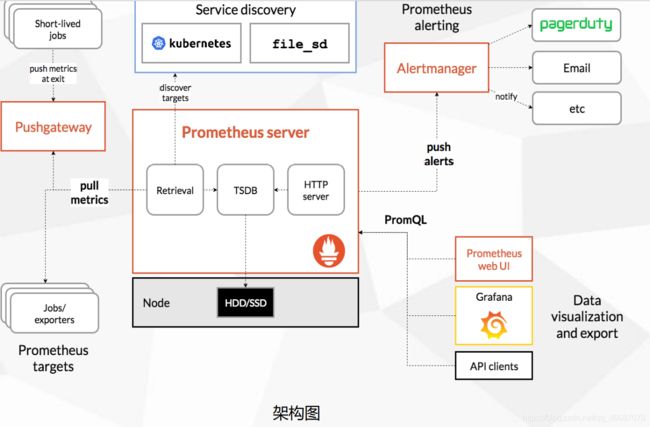
•Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
• ClientLibrary:客户端库
• Push Gateway:短期存储指标数据。主要用于临时性的任务
• Exporters:采集已有的第三方服务监控指标并暴露metrics
• Alertmanager:告警
• Web UI:简单的Web控制台
Prometheus 部署
Docker部署:https://prometheus.io/docs/prometheus/latest/installation/
docker run -d \
--name=prometheus \
-p 9090:9090 \
-v /tmp/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus
构建容器监控系统
cAdvisor+InfluxDB+Grafana
cAdvisor:Google开源的工具,用于监控Docker主机和容器系统资源,通过图形页面实时显示数据,但不存储;它通过 宿主机/proc、/sys、/var/lib/docker等目录下文件获取宿主机和容器运行信息。 InfluxDB:是一个分布式的时间序列数据库,用来存储cAdvisor收集的系统资源数据。 Grafana:可视化展示平台,可做仪表盘,并图表页面操作很方面,数据源支持zabbix、Graphite、InfluxDB、 OpenTSDB、Elasticsearch等
它们之间关系: cAdvisor容器数据采集->InfluxDB容器数据存储->Grafana可视化展示
部署
influxdb
docker run \
-d \
-p 8083:8083 \
-p 8086:8086 \
--name influxdb tutum/influxdb
cadvisor
docker run -d \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:rw \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--link influxdb:influxdb \
-p 8081:8080 \
--name=cadvisor \
google/cadvisor:latest \
-storage_driver=influxdb \
-storage_driver_db=cadvisor \
-storage_driver_host=influxdb:8086
grafana
docker run -d \
-p 3000:3000 \
-e INFLUXDB_HOST=influxdb \
-e INFLUXDB_PORT=8086 \
-e INFLUXDB_NAME=cadvisor \
-e INFLUXDB_USER=cadvisor \
-e INFLUXDB_PASS=cadvisor \
--link influxdb:influxsrv \
--name grafana \
grafana/grafana
企业级镜像仓库Harbor
Harbor概述
Habor是由VMWare公司开源的容器镜像仓库。事实上,Habor是在Docker Registry上进行了相应的 企业级扩展,从而获得了更加广泛的应用,这些新的企业级特性包括:管理用户界面,基于角色的访 问控制 ,AD/LDAP集成以及审计日志等,足以满足基本企业需求。 官方地址:https://vmware.github.io/harbor/cn/

Harbor部署
Harbor安装有3种方式:
• 在线安装:从Docker Hub下载Harbor相关镜像,因此安装软件包非常小
• 离线安装:安装包包含部署的相关镜像,因此安装包比较大
• OVA安装程序:当用户具有vCenter环境时,使用此安装程序,在部署OVA后启动Harbor
# tar zxvf harbor-offline-installer-v1.6.1.tgz
# cd harbor
# vi harbor.cfg
hostname = 10.206.240.188
ui_url_protocol = http
harbor_admin_password = 123456
# ./prepare
# ./install.sh
基本使用
1、配置http镜像仓库可信任
# vi /etc/docker/daemon.json
{
"insecure-registries":["reg.ctnrs.com"]}
# systemctl restart docker
2、打标签
# docker tag centos:6 reg.ctnrs.com/library/centos:6
3、上传
# docker push reg.ctnrs.com/library/centos:6
4、下载
# docker pull reg.ctnrs.com/library/centos:6
Docker-Compose
Docker-compose是用于定义和运行多容器 Docker 应用程序的工具。使用"Docker-compose",您可以使用 YAML 文件来配置应用程序的服务。然后,通过单个命令,从配置创建和启动所有服务。
在所有环境中Docker-compose作品:生产、暂存、开发、测试以及 CI 工作流。
使用Docker-compose基本上是一个三步过程:
- 使用 定义应用的环境,以便可以在任何地方复制。
Dockerfile - 定义在中管理应用的服务,以便它们可以在隔离环境中一起运行。
docker-compose.yml - 运行和Docker-compose启动并运行整个应用。
docker-compose up
下载并安装Docker-Compose
1. 官方下载(下载很慢)
#curl -L "https://github.com/docker/compose/releases/download/1.27.4/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
2.快速下载
#curl -L https://get.daocloud.io/docker/compose/releases/download/1.25.5/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
3.Docke-compose设置权文件的权限
#chmod +x /usr/local/bin/docker-compose
4。测试
#docker-compose version
5.配置环境变量(可以省略)
方便后期操作,配置一个环境变量
将docker-compose文件移动到了/usr/local/bin,修改了/etc/profile文件,给/usr/local/bin配置到了PATH中
#mv docker-compose /usr/local/bin
#vi /etc/profile
添加内容:export PATH=$JAVA_HOME:/usr/local/bin:$PATH
#source /etc/profile
6.卸载
#rm /usr/local/bin/docker-compose
体验
python应用:计数器。
1.应用app.py
2.Dockerfile应用打包为镜像
3.Docker-compose yaml文件(定义整个服务依赖的环境,web,redis,完整的上线服务)
4.启动compose项目
-
准备工作
#yum install python-pip #pip是python包管理工具 #yum install epel-release #报错的话执行 -
为项目创建目录
#mkdir composetest #cd composetest -
在项目目录中创建一个名为app.py文件,内容如下
import time import redis from flask import Flask app = Flask(__name__) cache = redis.Redis(host='redis', port=6379) def get_hit_count(): retries = 5 while True: try: return cache.incr('hits') except redis.exceptions.ConnectionError as exc: if retries == 0: raise exc retries -= 1 time.sleep(0.5) @app.route('/') def hello(): count = get_hit_count() return 'Hello World! I have been seen {} times.\n'.format(count) -
在项目目录中创建一个名为requirements.txt文件,内容如下
flask redis -
在项目目录中创建一个名为Dockerfile文件
FROM python:3.6-alpine ADD . /code WORKDIR /code RUN pip install -r requirements.txt CMD ["python", "app.py"] #这告诉docker # 从Python 3.6镜像开始构建镜像。 # 将当前目录添加. 到/code镜像中的路径中。 # 将工作目录设置为/code # 安装Python依赖项 # 将容器的默认命令设置为python app.py. -
在项目目录中创建一个名为docker-compose.yml文件
version: "3.8" services: web: build: . ports: - "5000:5000" volumes: - .:/code redis: image: "redis:alpine" #此Compose文件定义了俩个服务,web和redis。 #使用从Dockerfile当前目录中构建的图像 #将容器上的公共端口5000转发到主机上的端口5000。我们使用Flask Web服务器的默认端口5000 #该redis服务使用从Docker Hub注册表中提取的公共 Redis镜像 -
使用Compose构建和运行应用程序,在项目目录中,通过运行docker-compose up 启动应用程序
-
YAML文件格式及编写注意事项
YAML是一种标记语言很直观的数据序列化格式,可读性高。类似于XML数据描述语言,语法比XML简单的很多。 YAML数据结构通过缩进来表示,连续的项目通过减号来表示,键值对用冒号分隔,数组用中括号括起来,hash用花括号括起 来。
YAML文件格式注意事项:
- 不支持制表符tab键缩进,需要使用空格缩进
- 通常开头缩进2个空格
- 字符后缩进1个空格,如冒号、逗号、横杆
- 用井号注释
- 如果包含特殊字符用单引号引起来
- 布尔值(true、false、yes、no、on、off)必须用引号括起来,这样分析器会将他们解释为字符串。
Docker-Compose管理MySQL和Tomcat容器
yaml文件编辑
官方案例(https://docs.docker.com/compose/compose-file/#compose-file-structure-and-examples)
yml文件以key:value方式来指定配置信息
多个配置信息以换行+缩进的方式来区分
在docker-compose.yml文件中,不要使用制表符
version: '3.1'
services:
mysql: # 服务的名称
restart: always # 代表只要docker启动,那么这个容器就跟着一起启动
image: daocloud.io/library/mysql:5.7.4 # 指定镜像路径
container_name: mysql # 指定容器名称
ports:
- 3306:3306 # 指定端口号的映射
environment:
MYSQL_ROOT_PASSWORD: root # 指定MySQL的ROOT用户登录密码
TZ: Asia/Shanghai # 指定时区
volumes:
- /opt/docker_mysql_tomcat/mysql_data:/var/lib/mysql # 映射数据卷
tomcat:
restart: always
image: daocloud.io/library/tomcat:8.5.15-jre8
container_name: tomcat
ports:
- 8080:8080
environment:
TZ: Asia/Shanghai
volumes:
- /opt/docker_mysql_tomcat/tomcat_webapps:/usr/local/tomcat/webapps
- /opt/docker_mysql_tomcat/tomcat_logs:/usr/local/tomcat/logs
使用docker-compose命令管理容器
在使用docker-compose的命令时,默认会在当前目录下找docker-compose.yml文件
-
基于docker-compose.yml启动管理的容器
#docker-compose up -d -
关闭并删除容器
#docker-compose down -
开启|关闭|重启容器
#docker-compose start|stop|restart -
查看由docker-compose管理的容器
#docker-compose ps -
查看日志
#docker-compose logs -f
docker-compose配合Dockerfile使用(统一在/opt目录下操作)
使用docker-compose.yml文件以及Dockerfile文件在生成自定义镜像的同时启动当前镜像,并且由docker-compose去管理容器
1.首先生成一个文件夹,在其内编写docker-compose.yml文件
version: '3.1'
services:
ssm:
restart: always
build: # 构建自定义镜像
context: ../ # 指定dockerfile文件的所在路径
dockerfile: Dockerfile # 指定Dockerfile文件名称
image: ssm:1.0.1
container_name: ssm
ports:
- 8081:8080
environment:
TZ: Asia/Shanghai
2.编写Dockerfile文件
from docker.io/nginx:latest
copy index.html /usr/share/nginx/html
3.编写index.html(随意编写一个静态网页文件)
4.运行
docker-compose up -d
docker-compose说明
管理控制容器或是镜像的工具
-
管理控制容器
直接使用docker-compose.yml文件 文件的结构 version:版本 services: 服务内容(可以同时存在多个服务) servicesname: 服务名称,下级放的是服务相关的属性和设置(如 myweb) restart: 服务启动的时机 image: 创建容器时使用的镜像 container_name:创建后容器的名称 ports: 服务涉及到端口(不能和系统中的端口冲突) - 宿主机端口:容器端口 volumes:指定容器挂载的数据卷 - 宿主机路径:容器内的路径 -
管理控制镜像(需要Dockerfile文件的支撑)
1 创建 Dockerfile文件 from:指定当前自定义镜像依赖的环境 copy:将相对路径下的内容复制到自定义镜像中 workdir:声明镜像的默认工作目录 run:执行的命令,可以编写多个 cmd:需要执行的命令(在workdir下执行的,cmd可以写多个,只以最后一个为准) 2 创建Docker-compose.yml文件去调用Dockerfile生成镜像 version:'3.1' 版本 services: 服务 ssm: 服务名称 restart: 启动时机 build: # 构建自定义镜像时使用 context:../# 指定dockerfile文件的所在路径(相对) dockerfile:Dockerfile# 指定Dockerfile文件名称 image: ssm:1.0.1 #生成后自定义镜像的名称 container_name:ssm #容器名称 ports: -8081:8080 environment: #系统环境 (语言,时区等的设置) TZ:Asia/Shanghai
开源项目
搭建博客(https://docs.docker.com/compose/wordpress/)
Docker Compose项目
术语
首先介绍几个术语。
服务(service):一个应用容器,实际上可以运行多个相同镜像的实例。
项目(project):由一组关联的应用容器组成的一个完整业务单元。
可见,一个项目可以由多个服务(容器)关联而成,Compose 面向项目进行管理。
场景
下面,我们创建一个经典的 Web 项目:一个 Haproxy,挂载三个 Web 容器。
创建一个 compose-haproxy-web 目录,作为项目工作目录,并在其中分别创建两个子目录:haproxy 和 web。
Web 子目录
这里用 Python 程序来提供一个简单的 HTTP 服务,打印出访问者的 IP 和 实际的本地 IP。
index.py
编写一个 index.py 作为服务器文件,代码为
#!/usr/bin/python
#authors: yeasy.github.com
#date: 2013-07-05
import sys
import BaseHTTPServer
from SimpleHTTPServer import SimpleHTTPRequestHandler
import socket
import fcntl
import struct
import pickle
from datetime import datetime
from collections import OrderedDict
class HandlerClass(SimpleHTTPRequestHandler):
def get_ip_address(self,ifname):
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
return socket.inet_ntoa(fcntl.ioctl(
s.fileno(),
0x8915, # SIOCGIFADDR
struct.pack('256s', ifname[:15])
)[20:24])
def log_message(self, format, *args):
if len(args) < 3 or "200" not in args[1]:
return
try:
request = pickle.load(open("pickle_data.txt","r"))
except:
request=OrderedDict()
time_now = datetime.now()
ts = time_now.strftime('%Y-%m-%d %H:%M:%S')
server = self.get_ip_address('eth0')
host=self.address_string()
addr_pair = (host,server)
if addr_pair not in request:
request[addr_pair]=[1,ts]
else:
num = request[addr_pair][0]+1
del request[addr_pair]
request[addr_pair]=[num,ts]
file=open("index.html", "w")
file.write(" HA Webpage Visit Results
#"
+ str(request[pair][1]) +": "+str(request[pair][0])+ " requests " + "from <"+guest+"> to WebServer <"+pair[1]+">")
else:
file.write("#"
+ str(request[pair][1]) +": "+str(request[pair][0])+ " requests " + "from <"+guest+"> to WebServer <"+pair[1]+">")
file.write(" ");
file.close()
pickle.dump(request,open("pickle_data.txt","w"))
if __name__ == '__main__':
try:
ServerClass = BaseHTTPServer.HTTPServer
Protocol = "HTTP/1.0"
addr = len(sys.argv) < 2 and "0.0.0.0" or sys.argv[1]
port = len(sys.argv) < 3 and 80 or int(sys.argv[2])
HandlerClass.protocol_version = Protocol
httpd = ServerClass((addr, port), HandlerClass)
sa = httpd.socket.getsockname()
print "Serving HTTP on", sa[0], "port", sa[1], "..."
httpd.serve_forever()
except:
exit()
index.html
生成一个临时的 index.html 文件,其内容会被 index.py 更新。
$ touch index.html
Dockerfile
生成一个 Dockerfile,内容为
FROM python:2.7
WORKDIR /code
ADD . /code
EXPOSE 80
CMD python index.py
haproxy 目录
在其中生成一个 haproxy.cfg 文件,内容为
global
log 127.0.0.1 local0
log 127.0.0.1 local1 notice
defaults
log global
mode http
option httplog
option dontlognull
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
listen stats :70
stats enable
stats uri /
frontend balancer
bind 0.0.0.0:80
mode http
default_backend web_backends
backend web_backends
mode http
option forwardfor
balance roundrobin
server weba weba:80 check
server webb webb:80 check
server webc webc:80 check
option httpchk GET /
http-check expect status 200
docker-compose.yml
编写 docker-compose.yml 文件,这个是 Compose 使用的主模板文件。内容十分简单,指定 3 个 web 容器,以及 1 个 haproxy 容器。
weba:
build: ./web
expose:
- 80
webb:
build: ./web
expose:
- 80
webc:
build: ./web
expose:
- 80
haproxy:
image: haproxy:latest
volumes:
- haproxy:/haproxy-override
- haproxy/haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg:ro
links:
- weba
- webb
- webc
ports:
- "80:80"
- "70:70"
expose:
- "80"
- "70"
运行 compose 项目
现在 compose-haproxy-web 目录长成下面的样子。
compose-haproxy-web
├── docker-compose.yml
├── haproxy
│ └── haproxy.cfg
└── web
├── Dockerfile
├── index.html
└── index.py
在该目录下执行 docker-compose up 命令,会整合输出所有容器的输出。
$sudo docker-compose up
Recreating composehaproxyweb_webb_1...
Recreating composehaproxyweb_webc_1...
Recreating composehaproxyweb_weba_1...
Recreating composehaproxyweb_haproxy_1...
Attaching to composehaproxyweb_webb_1, composehaproxyweb_webc_1, composehaproxyweb_weba_1, composehaproxyweb_haproxy_1
此时访问本地的 80 端口,会经过 haproxy 自动转发到后端的某个 web 容器上,刷新页面,可以观察到访问的容器地址的变化。
访问本地 70 端口,可以查看到 haproxy 的统计信息。
当然,还可以使用 consul、etcd 等实现服务发现,这样就可以避免手动指定后端的 web 容器了,更为灵活。
Docker API
三种API
在Docker的生态系统中,存在下列三种API:
Reistry API:与存储Docker镜像的Registry相关的功能。
Docker Hub API:与Docker Hub相关的功能
Docker Remote API:与Docker守护进程相关的功能。
其中,Docker Remote API是使用最为频繁的API类型
启动Remote API
Remote API主要用于远程访问Docker守护进程从而下达指令的。
因此,我们在启动Docker守护进程时,需要添加-H参数并指定开启的访问端口。
通常,我们可以通过编辑守护进程的配置文件来实现。
不过对于不同操作系统而言,守护进程启动的配置文件也不尽相同:
Ubuntu系统:/etc/default/docker文件
Centos系统:/etc/sysconfig/docker文件
在该配置文件最后,添加内容如下:
OPTIONS='-H=tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock'
修改完成后执行如下命令,重启Docker守护进程:
#systemctl restart docker
测试Remote API
#docker -H 127.0.0.1:2375 info

上面的试验中,我们已经确认了与Docker守护进程之间的连通性。
下面,我们来使用一些Remote API。
#curl http://127.0.0.1:2375/info
从返回结果看,我们可以得到类似的docker info时的JSON格式的数据。

通过API管理Docker镜像
调用/images/json接口可以获取镜像列表:
#curl http://127.0.0.1:2375/images/json | python -mjson.tool

Ps:通过python -mjson.tool可以将JSON数据格式化显示。
通过API管理Docker容器
调用/containers/json接口可以获取正在运行中的容器列表:
#curl http://127.0.0.1:2375/containers/json | python -mjson.tool

如果想要查询全部的容器(包含不是正在运行的容器)时,可以调用如下接口:
#curl http://127.0.0.1:2375/containers/json?all=1 | python -mjson.tool

此外,我们还可以使用/containers/create以及/containers/start来创建和启动容器,从而实现docker run的功能。
创建容器:
#curl -X POST -H "Content-Type:application/json" http://127.0.0.1:2375/containers/create -d '{"Image": "docker.io/nginx"}'

Consul
安装consul
docker pull consul
启动服务:consul1
docker run --name consul1 -d -p 8500:8500 -p 8300:8300 -p 8301:8301 -p 8302:8302 -p 8600:8600 consul agent -server -bootstrap-expect 2 -ui -bind=0.0.0.0 -client=0.0.0.0
8500 http 端口,用于 http 接口和 web ui
8300 server rpc 端口,同一数据中心 consul server 之间通过该端口通信
8301 serf lan 端口,同一数据中心 consul client 通过该端口通信
8302 serf wan 端口,不同数据中心 consul server 通过该端口通信
8600 dns 端口,用于服务发现
-bbostrap-expect 2: 集群至少两台服务器,才能选举集群leader
-ui:运行 web 控制台
-bind: 监听网口,0.0.0.0 表示所有网口,如果不指定默认未127.0.0.1,则无法和容器通信
-client : 限制某些网口可以访问
获取 consul server1 的 ip 地址
docker inspect --format ='{
{ .NetworkSettings.IPAddress }}' consul1
启动服务:consul2
docker run --name consul2 -d -p 8501:8500 consul agent -server -ui -bind=0.0.0.0 -client=0.0.0.0 -join 172.17.0.2
启动服务:consul3
docker run --name consul3 -d -p 8502:8500 consul agent -server -ui -bind=0.0.0.0 -client=0.0.0.0 -join 172.17.0.2
第四第五略
访问
宿主机浏览器访问:http://localhost:8500 或者 http://localhost:8501 或者 http://localhost:8502


提升
创建test.json文件,以脚本形式注册服务到consul:
test.json文件内容如下:
{
"ID": "test-service1",
"Name": "test-service1",
"Tags": [
"test",
"v1"
],
"Address": "127.0.0.1",
"Port": 8000,
"Meta": {
"X-TAG": "testtag"
},
"EnableTagOverride": false,
"Check": {
"DeregisterCriticalServiceAfter": "90m",
"HTTP": "http://zhihu.com",
"Interval": "10s"
}
}
通过 http 接口注册服务(端口可以是8500. 8501, 8502等能够正常访问consul的就行):
curl -X PUT --data @test.json http://localhost:8500/v1/agent/service/register
控制台如下所示:

宿主机浏览器访问以下链接可以看到所有通过健康检查的可用test-service1服务列表
(任意正常启动consul的端口皆可):
http://localhost:8501/v1/health/service/test-service1?passing
输出json格式的内容,如下所示:

其它应用程序可以通过这种方式轮询获取服务列表,这就是微服务能够动态知道其依赖微服务可用列表的原理。
解绑定:
curl -i -X PUT http://127.0.0.1:8501/v1/agent/service/deregister/test-service1
集群方式需要至少启动两个consul server,本机调试web应用时,为了方便可以用 -dev 参数方式仅启动一个consul server
docker run --name consul0 -d -p 8500:8500 -p 8300:8300 -p 8301:8301 -p 8302:8302 -p 8600:8600 consul:1.2.2 agent -dev -bind=0.0.0.0 -client=0.0.0.0
Rancher
安装Rancher
docker search rancher
docker pull docker.io/rancher/server
docker pull docker.io/rancher/rancher
docker pull docker.io/rancher/agent
启动容器
sudo docker run -d --restart=always -p 8080:8080 rancher/server
查看ip地址
ip a
访问
ip:8080
登录到rancher官网,为安全起见,设置管理账户

然后进行添加主机操作,根据网站指引操作,生成一条命令,在docker中运行
docker run -e CATTLE_AGENT_IP="192.168.200.131" --rm --privileged -v /var/run/docker.sock:/var/run/docker.sock -v /var/lib/rancher:/var/lib/rancher rancher/agent:v1.2.11 http://192.168.200.131:8080/v1/scripts/6A5FD96A5C2385D994EF:1577750400000:HeMhHq8vWHgMCIHBJoFHGh8U
当在宿主机中运行完成后,网站中会显示成功添加主机

Environment在Rancher中被定义为主要用于容器编排和管理的环境,比如Dev或者TEST或者PROD环境等等。
目前Rancher支持如下四种:Cattle/Kubernetes/Mesos/Swarm, Cattle是Rancher自己内置的缺省的编排环境,缺省的Default的即为Cattle类型的。
案例:博客部署
(1)在rancher平台导航栏中,点击应用商店按钮,找到wordpress应用,点击查看详情,示例如图15所示:

(2)更改WordPress应用的端口号为8088,然后点击页面下方的启动按钮,示例如图16所示:

(3)等待一段时间后出现Active即创建成功,创建成功如图17所示,创建成功后,点击端口8088直接访问WordPress应用,如图18所示:

Swarm
Swarm介绍
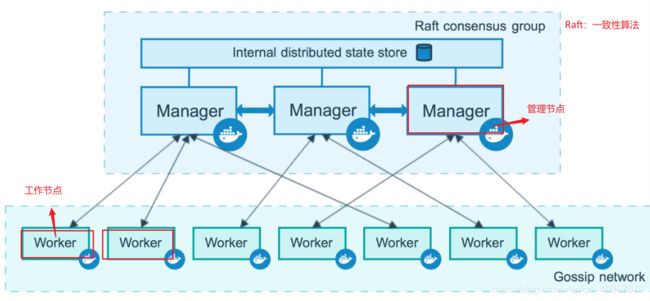
Swarm是什么? Swarm是Docker公司自研发的容器集群管理系统,Swarm在早期是作为一个独立服务存在,在Docker Engine v1.12中集成了 Swarm的集群管理和编排功能。可以通过初始化Swarm或加入现有Swarm来启用Docker引擎的Swarm模式。 Docker Engine CLI和API包括了管理Swarm节点命令,比如添加、删除节点,以及在Swarm中部署和编排服务。 也增加了服务栈(Stack)、服务(Service)、任务(Task)概念。
Swarm两种角色: Manager:接收客户端服务定义,将任务发送到worker节点;维护集群期望状态和集群管理功能及Leader选举。默认情况下 manager节点也会运行任务,也可以配置只做管理任务。 Worker:接收并执行从管理节点分配的任务,并报告任务当前状态,以便管理节点维护每个服务期望状态。

Swarm特点:
- Docker Engine集成集群管理 使用Docker Engine CLI 创建一个Docker Engine的Swarm模式,在集群中部署应用程序服务。
- 去中心化设计 Swarm角色分为Manager和Worker节点,Manager节点故障不影响应用使用。
- 扩容缩容 可以声明每个服务运行的容器数量,通过添加或删除容器数自动调整期望的状态。
- 期望状态协调 Swarm Manager节点不断监视集群状态,并调整当前状态与期望状态之间的差异。例如,设置一个服务运行10个副本容器,如果两个副本的服 务器节点崩溃,Manager将创建两个新的副本替代崩溃的副本。并将新的副本分配到可用的worker节点。
- 多主机网络 可以为服务指定overlay网络。当初始化或更新应用程序时,Swarm manager会自动为overlay网络上的容器分配IP地址。
- 服务发现 Swarm manager节点为集群中的每个服务分配唯一的DNS记录和负载均衡VIP。可以通过Swarm内置的DNS服务器查询集群中每个运行的容器。
- 负载均衡 实现服务副本负载均衡,提供入口访问。也可以将服务入口暴露给外部负载均衡器再次负载均衡。
- 安全传输 Swarm中的每个节点使用TLS相互验证和加密,确保安全的其他节点通信。
- 滚动更新 升级时,逐步将应用服务更新到节点,如果出现问题,可以将任务回滚到先前版本。
集群部署及节点管理
阿里云购买四台服务器

4台机器安装docker
工作模式
搭建集群

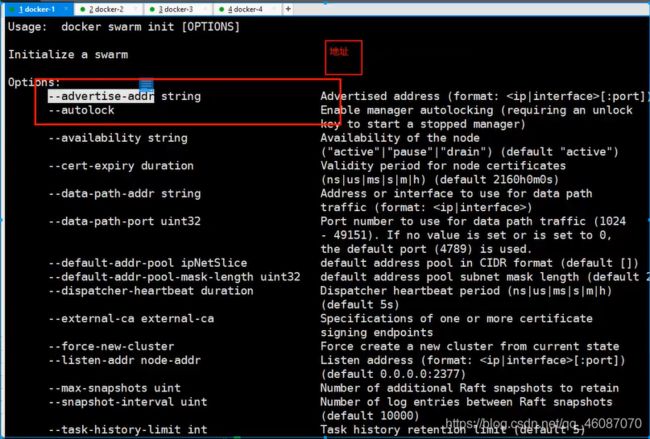

初始化docker swarm init
docker swarm join 加入一个节点
#获取令牌
#docker swarm join-token manager
#docker swarm join-token worker

把其他节点也搭建进去
Docker swarm项目
概念学习
swarm
集的管理和编号, docker可以初始化一个 swarm集群,其他节点可以加入。(管理、工作者)
docker
Node就是一个节点。多个节点就组成了一个网路集,(管理、工作者)
Service
任务,可以在管理节点或者工作节点来运行。核心!用户访问。
Task
容器内的命令,细节任务
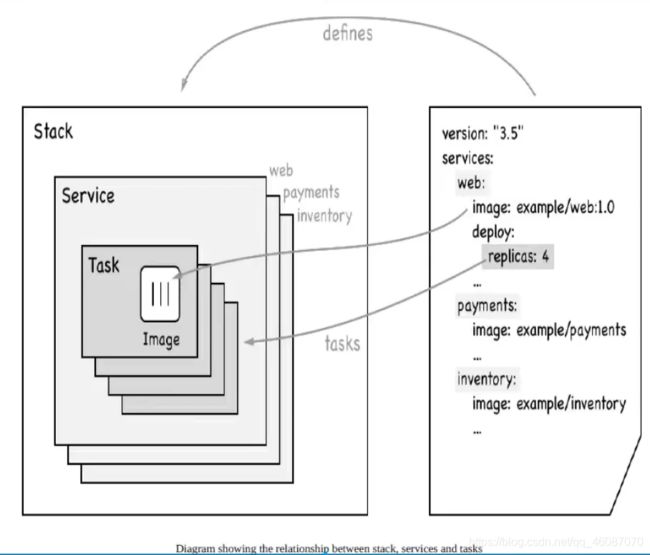
命令->管理->API->调度->工作节点(创建Task容器维护创建)
Docker Swarm项目安装
安装swarm的最简单的方式是使用Docker官方的swarm镜像
$ sudo docker pull swarm
可以使用下面的命令来查看swarm是否成功安装。
$ sudo docker run —rm swarm -v
输出下面的形式则表示成功安装(具体输出根据swarm的版本变化)
swarm version 0.2.0 (48fd993)
Docker Swarm项目使用
在使用 swarm 管理集群前,需要把集群中所有的节点的 docker daemon 的监听方式更改为 0.0.0.0:2375。
可以有两种方式达到这个目的,第一种是在启动docker daemon的时候指定
sudo docker -H 0.0.0.0:2375&
第二种方式是直接修改 Docker 的配置文件(Ubuntu 上是 /etc/default/docker,其他版本的 Linux 上略有不同)
在文件的最后添加下面这句代码:
DOCKER_OPTS="-H 0.0.0.0:2375 -H unix:///var/run/docker.sock"
需要注意的是,一定要在所有希望被 Swarm 管理的节点上进行的。修改之后要重启 Docker
sudo service docker restart
Docker 集群管理需要使用服务发现(Discovery service backend)功能,Swarm支持以下的几种方式:DockerHub 提供的服务发现功能,本地的文件,etcd,counsel,zookeeper 和 IP 列表,本文会详细讲解前两种方式,其他的用法都是大同小异的。
先说一下本次试验的环境,本次试验包括三台机器,IP地址分别为192.168.1.84,192.168.1.83和192.168.1.124.利用这三台机器组成一个docker集群,其中83这台机器同时充当swarm manager节点。
使用 DockerHub 提供的服务发现功能
创建集群 token
在上面三台机器中的任何一台机器上面执行 swarm create 命令来获取一个集群标志。这条命令执行完毕后,Swarm 会前往 DockerHub 上内置的发现服务中获取一个全球唯一的 token,用来标识要管理的集群。
sudo docker run --rm swarm create
我们在84这台机器上执行这条命令,输出如下:
rio@084:~$ sudo docker run --rm swarm create
b7625e5a7a2dc7f8c4faacf2b510078e
可以看到我们返回的 token 是 b7625e5a7a2dc7f8c4faacf2b510078e,每次返回的结果都是不一样的。这个 token 一定要记住,后面的操作都会用到这个 token。
加入集群
在所有要加入集群的节点上面执行 swarm join 命令,表示要把这台机器加入这个集群当中。在本次试验中,就是要在 83、84 和 124 这三台机器上执行下面的这条命令:
sudo docker run --rm swarm join addr=ip_address:2375 token://token_id
其中的 ip_address 换成执行这条命令的机器的 IP,token_id 换成上一步执行 swarm create 返回的 token。
在83这台机器上面的执行结果如下:
rio@083:~$ sudo docker run --rm swarm join --addr=192.168.1.83:2375 token://b7625e5a7a2dc7f8c4faacf2b510078e
time="2015-05-19T11:48:03Z" level=info msg="Registering on the discovery service every 25 seconds..." addr="192.168.1.83:2375" discovery="token://b7625e5a7a2dc7 f8c4faacf2b510078e"
这条命令不会自动返回,要我们自己执行 Ctrl+C 返回。
启动swarm manager
因为我们要使用 83 这台机器充当 swarm 管理节点,所以需要在83这台机器上面执行 swarm manage 命令:
sudo docker run -d -p 2376:2375 swarm manage token://b7625e5a7a2dc7f8c4faacf2b510078e
执行结果如下:
rio@083:~$ sudo docker run -d -p 2376:2375 swarm manage token://b7625e5a7a2dc7f8c4faacf2b510078e
83de3e9149b7a0ef49916d1dbe073e44e8c31c2fcbe98d962a4f85380ef25f76
这条命令如果执行成功会返回已经启动的 Swarm 的容器的 ID,此时整个集群已经启动起来了。
现在通过 docker ps 命令来看下有没有启动成功。
rio@083:~$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
83de3e9149b7 swarm:latest "/swarm manage token 4 minutes ago Up 4 minutes 0.0.0.0:2376->2375/tcp stupefied_stallman
可以看到,Swarm 已经成功启动。
在执行 Swarm manage 这条命令的时候,有几点需要注意的:
- 这条命令需要在充当 swarm 管理者的机器上执行
- Swarm 要以 daemon 的形式执行
- 映射的端口可以使任意的除了 2375 以外的并且是未被占用的端口,但一定不能是 2375 这个端口,因为 2375 已经被 Docker 本身给占用了。
集群启动成功以后,现在我们可以在任何一台节点上使用 swarm list 命令查看集群中的节点了,本实验在 124 这台机器上执行 swarm list 命令:
rio@124:~$ sudo docker run --rm swarm list token://b7625e5a7a2dc7f8c4faacf2b510078e
192.168.1.84:2375
192.168.1.124:2375
192.168.1.83:2375
输出结果列出的IP地址正是我们使用 swarm join 命令加入集群的机器的IP地址。
现在我们可以在任何一台安装了 Docker 的机器上面通过命令(命令中要指明swarm manager机器的IP地址)来在集群中运行container了。
本次试验,我们在 192.168.1.85 这台机器上使用 docker info 命令来查看集群中的节点的信息。
其中 info 也可以换成其他的 Docker 支持的命令。
rio@085:~$ sudo docker -H 192.168.1.83:2376 info
Containers: 8
Strategy: spread
Filters: affinity, health, constraint, port, dependency
Nodes: 2
sclu083: 192.168.1.83:2375
└ Containers: 1
└ Reserved CPUs: 0 / 2
└ Reserved Memory: 0 B / 4.054 GiB
sclu084: 192.168.1.84:2375
└ Containers: 7
└ Reserved CPUs: 0 / 2
└ Reserved Memory: 0 B / 4.053 GiB
结果输出显示这个集群中只有两个节点,IP地址分别是 192.168.1.83 和 192.168.1.84,结果不对呀,我们明明把三台机器加入了这个集群,还有 124 这一台机器呢?
经过排查,发现是忘了修改 124 这台机器上面改 docker daemon 的监听方式,只要按照上面的步骤修改写 docker daemon 的监听方式就可以了。
在使用这个方法的时候,使用swarm create可能会因为网络的原因会出现类似于下面的这个问题:
rio@227:~$ sudo docker run --rm swarm create
[sudo] password for rio:
time="2015-05-19T12:59:26Z" level=fatal msg="Post https://discovery-stage.hub.docker.com/v1/clusters: dial tcp: i/o timeout"
使用文件
第二种方法相对于第一种方法要简单得多,也不会出现类似于上面的问题。
第一步:在 swarm 管理节点上新建一个文件,把要加入集群的机器 IP 地址和端口号写入文件中,本次试验就是要在83这台机器上面操作:
rio@083:~$ echo 192.168.1.83:2375 >> cluster
rio@083:~$ echo 192.168.1.84:2375 >> cluster
rio@083:~$ echo 192.168.1.124:2375 >> cluster
rio@083:~$ cat cluster
192.168.1.83:2375
192.168.1.84:2375
192.168.1.124:2375
第二步:在083这台机器上面执行 swarm manage 这条命令:
rio@083:~$ sudo docker run -d -p 2376:2375 -v $(pwd)/cluster:/tmp/cluster swarm manage file:///tmp/cluster
364af1f25b776f99927b8ae26ca8db5a6fe8ab8cc1e4629a5a68b48951f598ad
使用docker ps来查看有没有启动成功:
rio@083:~$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
364af1f25b77 swarm:latest "/swarm manage file: About a minute ago Up About a minute 0.0.0.0:2376->2375/tcp happy_euclid
可以看到,此时整个集群已经启动成功。
在使用这条命令的时候需要注意的是注意:这里一定要使用-v命令,因为cluster文件是在本机上面,启动的容器默认是访问不到的,所以要通过-v命令共享。
接下来的就可以在任何一台安装了docker的机器上面通过命令使用集群,同样的,在85这台机器上执行docker info命令查看集群的节点信息:
rio@s085:~$ sudo docker -H 192.168.1.83:2376 info
Containers: 9
Strategy: spread
Filters: affinity, health, constraint, port, dependency
Nodes: 3
atsgxxx: 192.168.1.227:2375
└ Containers: 0
└ Reserved CPUs: 0 / 4
└ Reserved Memory: 0 B / 2.052 GiB
sclu083: 192.168.1.83:2375
└ Containers: 2
└ Reserved CPUs: 0 / 2
└ Reserved Memory: 0 B / 4.054 GiB
sclu084: 192.168.1.84:2375
└ Containers: 7
└ Reserved CPUs: 0 / 2
└ Reserved Memory: 0 B / 4.053 GiB
Docker Swarm项目调度器
swarm支持多种调度策略来选择节点。每次在swarm启动container的时候,swarm会根据选择的调度策略来选择节点运行container。目前支持的有:spread,binpack和random。
在执行swarm manage命令启动 swarm 集群的时候可以通过 --strategy 参数来指定,默认的是spread。
spread和binpack策略会根据每台节点的可用CPU,内存以及正在运行的containers的数量来给各个节点分级,而random策略,顾名思义,他不会做任何的计算,只是单纯的随机选择一个节点来启动container。这种策略一般只做调试用。
使用spread策略,swarm会选择一个正在运行的container的数量最少的那个节点来运行container。这种情况会导致启动的container会尽可能的分布在不同的机器上运行,这样的好处就是如果有节点坏掉的时候不会损失太多的container。
binpack 则相反,这种情况下,swarm会尽可能的把所有的容器放在一台节点上面运行。这种策略会避免容器碎片化,因为他会把未使用的机器分配给更大的容器,带来的好处就是swarm会使用最少的节点运行最多的容器。
spread 策略
先来演示下 spread 策略的情况。
rio@083:~$ sudo docker run -d -p 2376:2375 -v $(pwd)/cluster:/tmp/cluster swarm manage --strategy=spread file:///tmp/cluster
7609ac2e463f435c271d17887b7d1db223a5d696bf3f47f86925c781c000cb60
ats@sclu083:~$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7609ac2e463f swarm:latest "/swarm manage --str 6 seconds ago Up 5 seconds 0.0.0.0:2376->2375/tcp focused_babbage
三台机器除了83运行了 Swarm之外,其他的都没有运行任何一个容器,现在在85这台节点上面在swarm集群上启动一个容器
rio@085:~$ sudo docker -H 192.168.1.83:2376 run --name node-1 -d -P redis
2553799f1372b432e9b3311b73e327915d996b6b095a30de3c91a47ff06ce981
rio@085:~$ sudo docker -H 192.168.1.83:2376 ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2553799f1372 redis:latest /entrypoint.sh redis 24 minutes ago Up Less than a second 192.168.1.84:32770->6379/tcp 084/node-1
启动一个 redis 容器,查看结果
rio@085:~$ sudo docker -H 192.168.1.83:2376 run --name node-2 -d -P redis
7965a17fb943dc6404e2c14fb8585967e114addca068f233fcaf60c13bcf2190
rio@085:~$ sudo docker -H 192.168.1.83:2376 ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7965a17fb943 redis:latest /entrypoint.sh redis Less than a second ago Up 1 seconds 192.168.1.124:49154->6379/tcp 124/node-2
2553799f1372 redis:latest /entrypoint.sh redis 29 minutes ago Up 4 minutes 192.168.1.84:32770->6379/tcp 084/node-1
再次启动一个 redis 容器,查看结果
rio@085:~$ sudo docker -H 192.168.1.83:2376 run --name node-3 -d -P redis
65e1ed758b53fbf441433a6cb47d288c51235257cf1bf92e04a63a8079e76bee
rio@085:~$ sudo docker -H 192.168.1.83:2376 ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7965a17fb943 redis:latest /entrypoint.sh redis Less than a second ago Up 4 minutes 192.168.1.227:49154->6379/tcp 124/node-2
65e1ed758b53 redis:latest /entrypoint.sh redis 25 minutes ago Up 17 seconds 192.168.1.83:32770->6379/tcp 083/node-3
2553799f1372 redis:latest /entrypoint.sh redis 33 minutes ago Up 8 minutes 192.168.1.84:32770->6379/tcp 084/node-1
可以看到三个容器都是分布在不同的节点上面的。
binpack 策略
现在来看看binpack策略下的情况。在083上面执行命令:
rio@083:~$ sudo docker run -d -p 2376:2375 -v $(pwd)/cluster:/tmp/cluster swarm manage --strategy=binpack file:///tmp/cluster
f1c9affd5a0567870a45a8eae57fec7c78f3825f3a53fd324157011aa0111ac5
现在在集群中启动三个 redis 容器,查看分布情况:
rio@085:~$ sudo docker -H 192.168.1.83:2376 run --name node-1 -d -P redis
18ceefa5e86f06025cf7c15919fa64a417a9d865c27d97a0ab4c7315118e348c
rio@085:~$ sudo docker -H 192.168.1.83:2376 run --name node-2 -d -P redis
7e778bde1a99c5cbe4701e06935157a6572fb8093fe21517845f5296c1a91bb2
rio@085:~$ sudo docker -H 192.168.1.83:2376 run --name node-3 -d -P redis
2195086965a783f0c2b2f8af65083c770f8bd454d98b7a94d0f670e73eea05f8
rio@085:~$ sudo docker -H 192.168.1.83:2376 ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2195086965a7 redis:latest /entrypoint.sh redis 24 minutes ago Up Less than a second 192.168.1.83:32773->6379/tcp 083/node-3
7e778bde1a99 redis:latest /entrypoint.sh redis 24 minutes ago Up Less than a second 192.168.1.83:32772->6379/tcp 083/node-2
18ceefa5e86f redis:latest /entrypoint.sh redis 25 minutes ago Up 22 seconds 192.168.1.83:32771->6379/tcp 083/node-1
可以看到,所有的容器都是分布在同一个节点上运行的。
Docker Swarm项目过滤器
swarm 的调度器(scheduler)在选择节点运行容器的时候支持几种过滤器 (filter):Constraint,Affinity,Port,Dependency,Health
可以在执行 swarm manage 命令的时候通过 --filter 选项来设置。
Constraint Filter
constraint 是一个跟具体节点相关联的键值对,可以看做是每个节点的标签,这个标签可以在启动docker daemon的时候指定,比如
sudo docker -d --label label_name=label01
也可以写在docker的配置文件里面(在ubuntu上面是 /etc/default/docker)。
在本次试验中,给083添加标签—label label_name=083,084添加标签—label label_name=084,124添加标签—label label_name=084,
以083为例,打开/etc/default/docker文件,修改DOCKER_OPTS:
DOCKER_OPTS="-H 0.0.0.0:2375 -H unix:///var/run/docker.sock --label label_name=083"
在使用docker run命令启动容器的时候使用 -e constarint:key=value 的形式,可以指定container运行的节点。
比如我们想在84上面启动一个 redis 容器。
rio@085:~$ sudo docker -H 192.168.1.83:2376 run --name redis_1 -d -e constraint:label_name==084 redis
fee1b7b9dde13d64690344c1f1a4c3f5556835be46b41b969e4090a083a6382d
注意,是两个等号,不是一个等号,这一点会经常被忽略。
接下来再在084这台机器上启动一个redis 容器。
rio@085:~$ sudo docker -H 192.168.1.83:2376 run --name redis_2 -d -e constraint:label_name==084 redis 4968d617d9cd122fc2e17b3bad2f2c3b5812c0f6f51898024a96c4839fa000e1
然后再在083这台机器上启动另外一个 redis 容器。
rio@085:~$ sudo docker -H 192.168.1.83:2376 run --name redis_3 -d -e constraint:label_name==083 redis 7786300b8d2232c2335ac6161c715de23f9179d30eb5c7e9c4f920a4f1d39570
现在来看下执行情况:
rio@085:~$ sudo docker -H 192.168.1.83:2376 ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7786300b8d22 redis:latest "/entrypoint.sh redi 15 minutes ago Up 53 seconds 6379/tcp 083/redis_3
4968d617d9cd redis:latest "/entrypoint.sh redi 16 minutes ago Up 2 minutes 6379/tcp 084/redis_2
fee1b7b9dde1 redis:latest "/entrypoint.sh redi 19 minutes ago Up 5 minutes 6379/tcp 084/redis_1
可以看到,执行结果跟预期的一样。
但是如果指定一个不存在的标签的话来运行容器会报错。
rio@085:~$ sudo docker -H 192.168.1.83:2376 run --name redis_0 -d -e constraint:label_name==0 redis
FATA[0000] Error response from daemon: unable to find a node that satisfies label_name==0
Affinity Filter
通过使用 Affinity Filter,可以让一个容器紧挨着另一个容器启动,也就是说让两个容器在同一个节点上面启动。
现在其中一台机器上面启动一个 redis 容器。
rio@085:~$ sudo docker -H 192.168.1.83:2376 run -d --name redis redis
ea13eddf667992c5d8296557d3c282dd8484bd262c81e2b5af061cdd6c82158d
rio@085:~$ sudo docker -H 192.168.1.83:2376 ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ea13eddf6679 redis:latest /entrypoint.sh redis 24 minutes ago Up Less than a second 6379/tcp 083/redis
然后再次启动两个 redis 容器。
rio@085:~$ sudo docker -H 192.168.1.83:2376 run -d --name redis_1 -e affinity:container==redis redis
bac50c2e955211047a745008fd1086eaa16d7ae4f33c192f50412e8dcd0a14cd
rio@085:~$ sudo docker -H 192.168.1.83:2376 run -d --name redis_1 -e affinity:container==redis redis
bac50c2e955211047a745008fd1086eaa16d7ae4f33c192f50412e8dcd0a14cd
现在来查看下运行结果,可以看到三个容器都是在一台机器上运行
rio@085:~$ sudo docker -H 192.168.1.83:2376 ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
449ed25ad239 redis:latest /entrypoint.sh redis 24 minutes ago Up Less than a second 6379/tcp 083/redis_2
bac50c2e9552 redis:latest /entrypoint.sh redis 25 minutes ago Up 10 seconds 6379/tcp 083/redis_1
ea13eddf6679 redis:latest /entrypoint.sh redis 28 minutes ago Up 3 minutes 6379/tcp 083/redis
通过 -e affinity:image=image_name 命令可以指定只有已经下载了image_name镜像的机器才运行容器
sudo docker –H 192.168.1.83:2376 run –name redis1 –d –e affinity:image==redis redis
redis1 这个容器只会在已经下载了 redis 镜像的节点上运行。
sudo docker -H 192.168.1.83:2376 run -d --name redis -e affinity:image==~redis redis
这条命令达到的效果是:在有 redis 镜像的节点上面启动一个名字叫做 redis 的容器,如果每个节点上面都没有 redis 容器,就按照默认的策略启动 redis 容器。
Port Filter
Port 也会被认为是一个唯一的资源
sudo docker -H 192.168.1.83:2376 run -d -p 80:80 nginx
执行完这条命令,之后任何使用 80 端口的容器都是启动失败。
实战Redis

shell脚本
#创建网卡
#docker network create redis --subnet 172.38.0.0/16
#通过脚本创建六个redis配置
#for port in $(seq 1 6); \
do \
mkdir -p /mydata/redis/node-${port}/conf
touch /mydata/redis/node-${port}/conf/redis.conf
cat << EOF >>/mydata/redis/node-${port}/conf/redis.conf
port 6379
bind 0.0.0.0
Cluster-enabled yes
Cluster-config-file nodes.conf
Cluster-node-timeout 5000
Cluster-announce-ip 172.38.0.1${port}
Cluster-announce-port 6379
Cluster-announce-bus-port 16379
appendonly yes
EOF
done
#docker run -p 637${port}:6379 -p 1637${port}:16379 --name redis -${port} \
-v /mydata/redis/node-${port}/data:/data \
-v /mydata/redis/node-${port}/conf/redis.conf:/etc/redis/redis.conf \
-d --net redis --ip 172.38.0.1${port} redis:5.0.9-alpine3.11 redis-server /etc/redis/redis. conf; \
第一个,在创建5个(6处更改)
#docker run -p 6371:6379 -p 16371:16379 --name redis-1 \
-v /mydata/redis/node-1/data:/data \
-v /mydata/redis/node-1/conf/redis.conf:/etc/redis/redis.conf \
-d --net redis --ip 172.38.0.11 redis:5.0.9-alpine3.11 redis-server /etc/redis/redis.conf
#创建集群
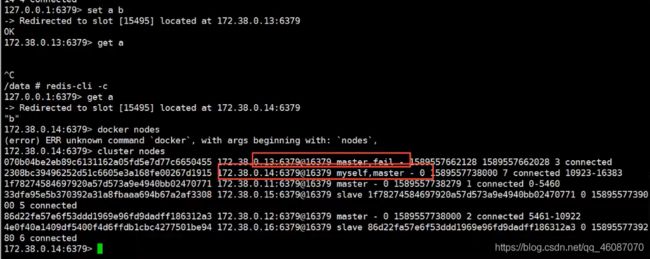
#redis-cli --cluster create 172.38.0.11:6379 172.38.0.12:6379 172.38.0.13:6379 172.38.0.14:6379 172.38.0.15:6379 172.38.0.16:6379 --cluster-replicas 1
#redis-cli -c
#cluster info
#cluster nodes
#get a b
docker 搭建redis集群完成!
构建持续集成环境
docker + jenkins + git + maven****自动化构建与部署
(1)安装本次部署需要的软件
1.清除防火墙规则和配置yum.repo
[root@docke-all yum.repos.d]# iptables -F
[root@docke-all yum.repos.d]# iptables -X
[root@docke-all yum.repos.d]# iptables -Z
[root@docke-all yum.repos.d]# /usr/sbin/iptables-save
\# Generated by iptables-save v1.4.21 on Thu Jan 19 05:46:41 2017
*filter
:INPUT ACCEPT [4:280]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [3:308]
COMMIT
\# Completed on Thu Jan 19 05:46:41 2017
添加yum文件
[root@docke-all yum.repos.d]# vi /etc/yum.repos.d/docker.repo
[dockerrepo]
name=Docker Repository
baseurl=https://yum.dockerproject.org/repo/main/centos/$releasever/
enabled=1
gpgcheck=1
gpgkey=https://yum.dockerproject.org/gpg
"docker.repo" [New] 12L, 172C written
2.安装最新的docker软件包
[root@docke-all yum.repos.d]# sudo yum install docker-engine
Loaded plugins: fastestmirror
dockerrepo | 2.9 kB 00:00:00
dockerrepo/7/primary_db | 28 kB 00:00:00
Installed:
docker-engine.x86_64 0:1.13.0-1.el7.centos
Dependency Installed:
docker-engine-selinux.noarch 0:1.13.0-1.el7.centos libseccomp.x86_64 0:2.3.1-2.el7
libtool-ltdl.x86_64 0:2.4.2-21.el7_2
Complete!
3. docker 分别pull 以下镜像 jenkins:2.0-beta-1 tomcat和mysql
[root@docke-all yum.repos.d]# docker pull jenkins:2.0-beta-1
2.0-beta-1: Pulling from library/jenkins
efd26ecc9548: Pull complete
a3ed95caeb02: Pull complete
bf22465a61c2: Pull complete
。。。。。。
Digest: sha256:e315b7abd7dd86dca7e5307e1deb040b4054daeaf8d9de28749a88cccc9b960f
Status: Downloaded newer image for jenkins:2.0-beta-1
[root@docke-all yum.repos.d]# docker pull tomcat
Using default tag: latest
latest: Pulling from library/tomcat
5040bd298390: Pull complete
1638c7ffa55a: Pull complete
Digest: sha256:c9c5e4d114cf547886a0c0956eebebcfc1d87216f09120e6b77df27f7c8053b0
Status: Downloaded newer image for tomcat:latest
[root@docke-all yum.repos.d]# docker pull mysql
Using default tag: latest
latest: Pulling from library/mysql
5040bd298390: Already exists
55370df68315: Pull complete
fad5195d69cc: Pull complete
Digest: sha256:d433b96443b9584cdfbcc337c7ebd7cef71332c5368aba19f94177953b1fe0f6
Status: Downloaded newer image for mysql:latest
4.下载apache-maven和jdk并解压到指定文件夹下
maven 并解压:
[root@docke-all ~]#mkdir -p /dockerworkspace/maven && tar zxf apache-maven-3.3.9-bin.tar.gz -C /dockerworkspace/maven
下载jdk 并解压:
[root@docke-all ~]#tar -zxvf jdk*.tar.gz -C /dockerworkspace/java/
[root@docke-all ~]# mv /dockerworkspace/java/jdk* /dockerworkspace/java/jdk
5.安装jenkins
[root@docke-all dockerworkspace]# docker run -it --name jenkins -p 8080:8080 -p 50000:50000 -v /dockerworkspace/jenkins:/var/jenkins_home -v /dockerworkspace/maven/apache-maven-3.3.9:/usr/local/maven -v /dockerworkspace/java/jdk:/usr/local/jdk jenkins:latest
touch: cannot touch ‘/var/jenkins_home/copy_reference_file.log’: Permission denied
Can not write to /var/jenkins_home/copy_reference_file.log. Wrong volume permissions?
至此出现一个错误,是因为文件权限问题导致的,具体解释如下:
我们检查一下之前启动方式的"/var/jenkins_home"目录权限,查看Jenkins容器的当前用户: 当前用户是"jenkins"而且"/var/jenkins_home"目录是属于jenkins用户拥有的;而当映射本地数据卷时,/var/jenkins_home目录的拥有者变成了root用户。发现问题之后,相应的解决方法也很简单:把当前目录的拥有者赋值给uid 1000,再启动"jenkins"容器就一切正常了。
[root@docke-all dockerworkspace]# sudo chown -R 1000 jenkins
[root@docke-all dockerworkspace]# docker start jenkins
Jenkins
访问jenkins:8080(jenkins改成服务器地址) ,然后输入以下查看到的密码Unlock Jenkins
[root@docke-all dockerworkspace]# cat /dockerworkspace/jenkins/secrets/initialAdminPassword
554cc3aee41841a49213e6da8507f087

Customize Jenkins步骤时选择左边的Install suggested plugins

Install suggested plugins安装
插件安装完成后界面

配置Jenkins,点击“可选插件”,安装ssh插件。

在过滤栏搜索:ssh plugin

JDK配置和Maven配置:

选择JDK和Maven配置路径
至此持续集成环境部署完成,就可以进行项目部署了。
新建测试项目
本教程中git管理端用的是gogs,创建jenkins中的maven 项目
在jenkins首页点击新建选择构建一个maven项目 填写项目名称test_tomcat
(如果没有这项请安装插件Maven Integration plugin)
源码管理中选择git, 填写项目的git信息(Credentials点新增可以添加git的认证信息,支持帐户名密码,ssh key 等方式. 源码浏览器在构建项目时的修改记录可以直接连接到git平台)

本人系列文章仅用作个人笔记整理,不做商用。其中部分来自网络,部分来自个人所学,难免有疏漏之处,望海涵。