知识图谱(六)——关系抽取
如何从结构化或非结构化文本中识别出实体之间的关系是知识图谱构建的核心任务之一。
文章目录
- 一、任务概述
-
- 1、任务定义
- 2、任务分类
- 3、任务难点
- 4、相关测评
- 二、限定域关系抽取
-
- 1、基于模板的关系抽取方法
-
- 1)人工模板
- 2)学习方法
- 2、基于机器学习的关系抽取方法
-
- 1)有监督的关系抽取方法
-
- (1)基于特征工程的方法
- (2)基于核函数的方法
- (3)基于神经网络的方法
-
- a、示例
- 2)弱监督的关系抽取方法
- 三、开放域关系抽取
-
- 1、TextRunner
-
- (1)语料的自动生成和分类器训练
- (2)大规模关系三元组的抽取
- (3)关系三元组可信度计算
一、任务概述
1、任务定义
关系抽取:自动识别实体之间具有的某种语义关系。
- 根据参与实体的数量可分为二元关系抽取和多元关系抽取。
- 二元关系抽取是其他关系抽取研究的基础,所以本文关注二元关系抽取(两个实体之间的语义关系),得到
(arg1,relation,arg2)三元组。eg:(中国,首都,北京)
2、任务分类
根据数据源的不同,可分为:
- 面向结构化文本的关系抽取
- 结构化文本包括:表格数据、XML文档和数据库数据等
- 易于抽取,可通过编写特定模板进行抽取,准确率比较高
- 面向非结构化文本的关系抽取
- 非结构化文本:纯文本。准确率相对较低
- 面向半结构化文本的关系抽取
- 半结构化文本:介于上述两者之间,数据的分布或布局具有一定的规律。
- 通常利用对模板进行自动学习来抽取关系,也达到较高的准确率
根据抽取文本的范围不同,关系抽取可分为
- 句子级关系抽取(句子级关系分类):从一个句子中判断两个实体间是何种语义关系。
- 语料(篇)级关系抽取:判断两个实体之间是否具有某种语义关系,而不必限定在两个目标实体所出现的上下文.
根据抽取领域的划分,可分为:
- 限定域关系抽取:在一个或多个限定的领域内对实体间的语义关系进行抽取。
- 通常情况下,由于限定域,语义关系也是预先设好的有限个类别。 常采用监督学习或弱监督学习方法
- 开放域关系抽取:依据模型对自然语言句子理解的结果从开放式抽取实体关系三元组。
3、任务难点
- 同一个关系可以具有多种不同的词汇表示方法。
- eg:
“姚明出生于上海”和“姚明的出生地是上海”都表达姚明和上海具有出生地关系。
- eg:
- 同一个短语或词可能表示不同的关系。
- eg:
“李梅是我的姑娘。”中的姑娘可以指女儿,也可以指女朋友。
- eg:
- 同一对实体之间可能存在不止一种关系。
- eg:姚明的出生地是上海,姚明的居住地也是上海。
- 关系抽取不仅涉及两个或两个以上的实体单元,还涉及实体周围的上下文,需要利用文本王那种的一些结构化的信息,使得问题复杂度成指数级增长。
“三国时期,蜀国多维能征善战的将军,他们分别是:关羽、张飞、赵云、黄忠和马忠。”
- 关系有时在文本中找不到任何明确的标识,关系隐含在文本中。
“蒂姆·库克与中国移动董事长奚国华会面商谈“合作事宜”,透露出了他将带领苹果公司进一步开拓中国市场的讯号。”==》推断:蒂姆·库克是苹果公司的首席执行官(CEO)
- 关系抽取一般依赖于词法、语句分析等基本NLP工具,但实际中,工具性能并不高并会影响关系抽取的性能。
4、相关测评
MUC(消息理解会议)、ACE(自动内容抽取)和TAC(文本分析会议)三大国际测评会议 和 语义测评会议(SemEval)
二、限定域关系抽取
限定域关系抽取:在一个或多个限定的领域内判别文本中所出现的实体指称之间是何种语义关系,且待判别的语义关系是预定义的。
可看作 ==》文本分类任务
1、基于模板的关系抽取方法
基本思想:通过人工编辑或学习得到的模板对文本中的实体关系进行抽取和判别。
1)人工模板
例如:假设X和Y表示公司类型,可使用如下模板表示收购(ACQUISITION)关系。当满足下述模板,则表示两个实体指称在这个句子中具有收购(ACQUISITION)关系。
X i s a c q u i r e d b y Y X i s p u r c h a s e d b y Y X i s b o u g h t b y Y X\ is\ acquired\ by\ Y \\ X\ is\ purchased\ by\ Y \\ X\ is\ bought\ by\ Y X is acquired by YX is purchased by YX is bought by Y
2)学习方法
由于人工定义模板的方法不能针对多类关系穷举所有的模板,则需采用自动的方法学习抽取模板。
==》① 如何学习用于抽取关系的模板?② 如何将学习到的模板进行聚类?
==》多采用 提升(BootStrapping)策略,对于实体和模板进行联合迭代式地交替抽取和学习。
基本出发点:一种语义关系可采用对偶的方式进行表示,可以利用实体对在文本中获取的模板信息,再利用获得的模板抽取更多的实体对。
- 外延性(Extensionally)表示:使用所有包含该种关系的实体对表示该关系。
- 用符号 R R R 表示关系, E ( R ) E(R) E(R) 表示所有包含关系 R R R 的实体对。
- eg:表示
收购(ACQUISITION)关系,则可给出实体对(You Tube, Google)、(Powerset, Microsoft)、(Inktomi, YAHOO)等
- 内涵性(Intensionally)表示:使用所有能抽取出这种关系的模板表示该关系。
- 用符号 R R R 表示关系,使用所有能抽取这种关系的模板 P ( R ) P(R) P(R) 。
- eg:X和Y表示两个公司,用 X i s a c q u i r e d b y Y , X i s p u r c h a s e d b y Y 或 X i s b o u g h t b y Y X\ is\ acquired\ by\ Y,X\ is\ purchased\ by\ Y 或 X\ is\ bought\ by\ Y X is acquired by Y,X is purchased by Y或X is bought by Y 等表示ACQUISITION关系。
关键步骤:抽取句子中的实体对之间的表达关系的模板。 模板是基于词汇的,也可以是基于句法或语义的。
步骤:
- 该过程中需要NLP技术,包括:句子边界探测(将给定的文本语料分割为句子)、词性标注(获得单词的词性)、名词词组块识别(探测句子中实体)、命名实体识别(提取合适的名词词组块和实体)等
- 然后在此基础上,分别抽取词汇级关系模板 和 句法级关系模板。
- 对习得的模板进行聚类,将表示同一语义关系的模板聚类到一起。
示例:
- 句子:The crime took place in View Royal on Vancouver Island.
- 词性标注:DT NN VBD NN IN NNP NNP IN NNP NNP .
- 实体或词组块:The crime took place in [View Royal] on [Vancouver Island].
- 变量替换: View Royal=X Vancouver Island=Y
- 字面形式:The crime took place in X on Y.
- 词性序列:DT NN VBD NN IN X IN Y .
- 词汇模式:X on Y,X,Y
- 语法模式:X in Y,X,Y
缺点:受限于模板的质量和覆盖度,可扩展性不强。
2、基于机器学习的关系抽取方法
将关系抽取看成一个分类问题,应用机器学习的方法解决该问题,可以分为:有监督的关系抽取方法 和 弱监督的关系抽取方法
1)有监督的关系抽取方法
主要工作:何如抽取出表征实体指称项间语义关系的有效特征。
常分为:基于特征工程的方法、基于核函数的方法、基于神经网络的方法
(1)基于特征工程的方法
研究重点:如何提取具有区分性的特征。
步骤:
- 特征提取:提取词汇、句法和语义等特征,然后有效地集成起来,来描述关系实例的各种局部特征和全局特征。
- 模型训练:训练分类器
- 关系抽取:对新非结构化文本进行分类,完成关系抽取。
常见的关系抽取特征如下:
- 词汇特征。包括:实体本身的词语或名词性词组块、两个实体(词组块)之间的词语和两个实体(词组块)两端的词语。
- 实体属性特征。包括:实体或名词性词组块的类型特征,eg:人物(Person)、组织(Organization)、位置(Location)、设施(Facility)和地缘政治实体(Geo-Political Entity)等。
- 重叠特征。包括:两个实体或词组块之间词语的个数、它们之间部分包含其他实体或词组块的个数、两个实体或词组块是否在同一个名词短语、动词短语或介词短语之中。
- 依存句法特征。包括:两个实体(名词性词组块)的依存句法分析树中的依存标签和依存路径。
- 句法树特征。包括:连接两个实体(名词性词组块)的句法路径,不包含重复的节点,并且将路径使用头词(head words)标注。
示例:"Jobs was the co-founder of Apple."
- 词汇特征:“Jobs”、“Apple”、“was the co-founder of” 等
- 实体类型:PERSON(“Jobs”)、ORGANIZATION(“Apple”)
- 重叠特征:两个实体之间词语的个数是4、它们之间部分包含其他实体的个数是0、两个实体不属于同一个名词短语、动词短语或介词短语。
- 依存特征:实体“Jobs”依存的单词“co-founder”的词性是NN;实体“Apple”依存单词“of”,其依存单词“of”的词性是IN。
- 句法树特征:NNP-NP-S-VP-NP-PP-NP-NNP
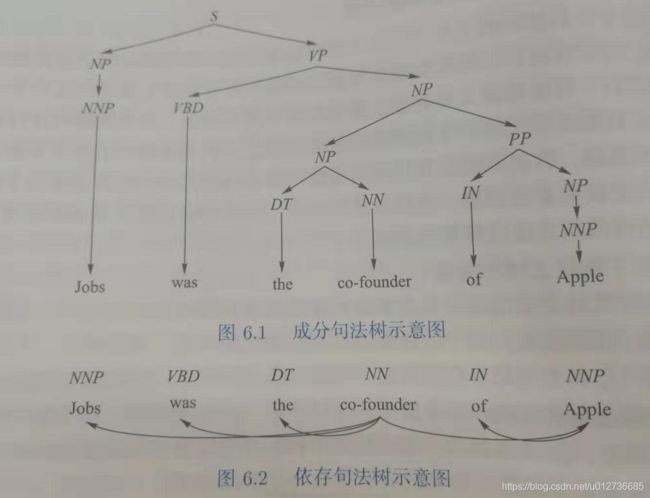
==》句法树特征,受句子以及词在不同上下文环境的影响大,会导致特征空间特别巨大,从而产生 特征稀疏 的问题。
(2)基于核函数的方法
基于核函数的方法直接以结构树为处理对象,在计算关系之间距离时使用核函数。
典型核函数:树核函数、依存树核函数、最短依存树核函数、最短路径包含树核…
(3)基于神经网络的方法
上述两类模板的可扩展性存在很大问题,限制这些方法的应用和推广:
- 人工设计的特征的累计误差;
- 对于小语种,缺乏可用的NLP工具,不能使用上述基于特征工程的关系抽取方法。
步骤:
- 特征表示:纯文本的特征 =》分布式特征(eg:词向量)
- 神经网络构建与高层特征学习:设计搭建神经网络模型并利用上步得到的基本特征自动表示为高层特征
- 模型训练:调参
- 模型分类:对新样本分类,完成关系抽取。
a、示例
2014年,Zeng等提出基于卷积神经网络的关系抽取模型。
- 该模型包括:词表示(Word Representation)、特征抽取(Feature Extraction)和输出(Output)。
- 整个模型的输入是一个句子及给定的两个词(通常为名词、名词短语或实体),输出是两个词在该句子中所属的预定义的语义关系类别.
过程:首先,输入的句子通过词向量表示,转化为向量的形式输入网络。然后,特征抽取部分进一步抽取词汇级别特征和句子级别特征,并拼接起来作为最终的特征进行关系分类。
词向量输入
- 通过word embedding将句子中的每一个词都使用词向量表示。此处使用Word2Veec模型。
- 词向量基于分布式表示,根据词频、词的共现和搭配等语言知识,将文本中的词表示为低维空间中的稠密向量。便于计算词与词之间的关系。
- 主要词向量模型:语言模型、SENNA模型、RNNLM模型和Word2Veec模型等。
词汇级别特征
- 传统方法抽取的词汇特征主要包括:词本身、词性以及待分类的两个词之间的词等,该方法直接使用词向量作为词汇级别特征。
句子级别特征
- 一般根据整个句子的意义来判断两个词之间的关系,该方法使用卷积神经网络通过语义组合的方式自动学习句子级别的特征,框架如下所示:
- 过程:在输入的词被表示为向量后,首先通过开窗处理获得局部特征,然后再通过卷积滤波捕获不同的特征,最后对卷积的结果进行非线性变换得到句子级别特征。
- 特别地,为了让网络知道句子中哪两个词需要给定语义关系,该方法使用位置特征对句子中需要给定语义关系的两个词进行建模。位置特征表示当前词到待分类的两个词之间的相对距离。
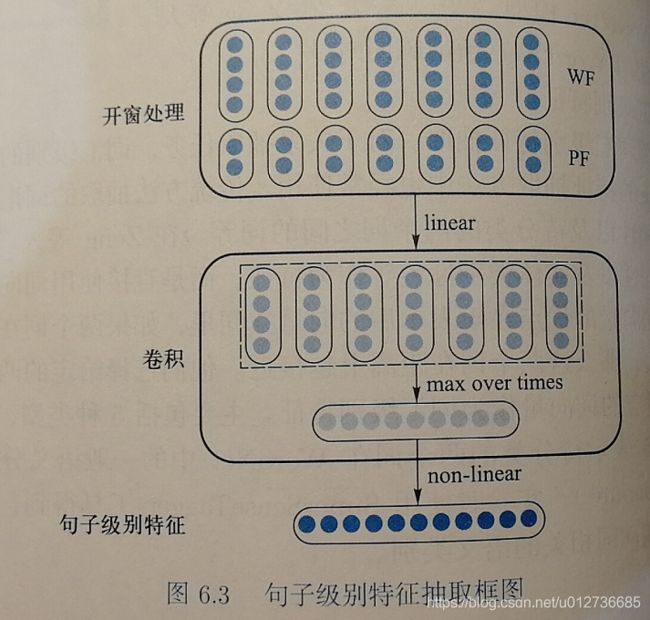
网络输出
最终的特征向量为词汇级别和句子级别特征的拼接,然后输入到Softmax分类器,进行调参。
2)弱监督的关系抽取方法
距离监督(Distant Supervision)利用结构化三元组的形式的数据,让知识图谱自动标注训练样本。
假设:如果两个实体之间存在某种关系,则所有包含这两个实体的句子都表达了这种关系,这些句子的集合被称为一个“包”
Zeng等使用分段卷积神经网络抽取文本的特征。
- 训练数据的产生:通过命名实体识别工具找出给定的非结构化文本中的所有实体,根据弱监督假设,将实体组成对,在知识库中查,有抽出为正样本,无为负样本。
- 任务建模:不知道哪些有用,但只要有1个有用,就给定标签,并不关心是每个示例的标签。
- 分段卷积神经网络:设计了分段最大池化层代替原先的池化层
- 多示例训练:克服噪声的影响。对包的示例预测,选概率最大的为包的标签。但是会忽略包中其他方法的信息,有其他的改进。
典型的弱监督关系抽取系统
- NELL(Never-Ending Language Learner)
- NELL系统的输入包括:一个预定义的实体类别体系以及关系体系;每个实体类别和关系类别的10到15个样例。
- 任务:为各个实体类别和关系类别抽取新的实例;提升系统本身的抽取性能
- Probase
- 可以从海量的Web网页中自动抽取isA关系和概念标签,并用概率值表示抽取的置信度。
- 通过现有知识来理解文本从而获取更多的知识。
三、开放域关系抽取
开放域关系抽取不需要预先定义关系,而是使用实体对上下文中的一些词语来描述实体之间的关系。
典型原型系统:TextRunner、Kylin、WOE、ReVerb等
1、TextRunner
过程:通过一些简单的启发式规则自动从宾州树库里面获取实体关系三元组的正负样本,根据它们的一些浅层句法特征训练一个分类器来判断两个实体间是否存在语义关系;然后将网络文本进行一定的处理后作为候选句子,提取其浅层句法特征,利用分类器来判断所抽取的关系三元组是否可信,最后利用网络数据的冗余信息,对初步认定可信的关系进行评估。对于关系名称的抽取,则是将动词作为关系名称。
主要包含三个模块:语料的自动生成和分类器训练、大规模关系三元组的抽取、关系三元组可信度计算。
(1)语料的自动生成和分类器训练
语料的自动生成:根据依存句法分析结合启发式规则自动生成语料。利用的启发式规则举例如下:
- 两个实体的依存路径长度不能大于指定值。
- 实体不能是代词。
- …
分类器训练:利用朴素贝叶斯分类器进行训练,其使用的特征举例如下:
- 关系指示词的词性、长度
- 实体的类型,是否是专有名词
- 左实体左边词语的词性。。。
(2)大规模关系三元组的抽取
利用上述训练好的关系抽取器,在web文本上抽取并存储
(3)关系三元组可信度计算
- 将存储起来的相似的三元组进行合并,eg:(arg1,married,arg2)和(arg1,marries,arg2)
- 根据网络数据的冗余性,计算合并后关系三元组在网络中出现的次数,进而计算相应关系三元组的可信度。